0.1 Modules and Interface
对于任何大型软件系统,如果设计者注意到了该系统的基本抽象和接口,那么对这个系统的理解和实现就要容易得多。
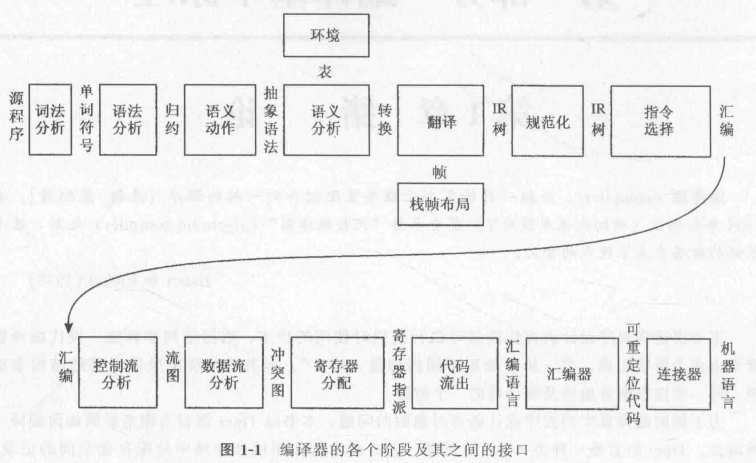
编译器就被分解成不同的部分(分别称为 “阶段” 和 “接口”):
-
词法分析(Lexicon Analysis):将源文件分解为一个独立的单词符号(token);
-
语法分析(Grammar Analysis):分析程序的短语结构;
-
语义动作(Semantic Action):建立每个短语对应的抽象语法树(AST);
-
语义分析(Semantic Analysis):确定每个短语的含义,建立变量和其声明的关联(表),检查表达式的类型,翻译每个短语;
-
栈帧布局(Frame Layout):按机器要求的方式将变量、函数参数等分配于活跃记录(即栈帧)内;
-
翻译(Translation):生成中间表示树(IR Tree);
这是一种与任何特定程序设计语言和目标机体系结构无关的表示;
-
规范化(Normalization):提取表达式中的 side effects,并且整理条件分支,方便下一阶段处理;
-
指令选择(Instruction Selection):将 IR Tree 结点组合成与目标机指令的动作相对应的块;
-
控制流分析(Control Flow Analysis):分析指令的顺序并建立**控制流图**(Control Flow Graph)。此图表示程序执行时可能流经的所有控制流;
控制流分析可以帮助流程优化,例如死代码删除;
-
数据流分析(Data Flow Analysis):收集程序变量的数据流信息。例如,活跃分析(Liveness Analysis),计算每一个变量仍需使用其值�的地点(即它的活跃点);
活跃分析可以帮助变量的优化;
-
寄存器分配(Registers Allocation):为程序中的每一个变量和临时数据选择一个寄存器,不在同一时间活跃的两个变量可以共享同一个寄存器;
在 ICS 中提到,这是编译器需要做的非常重要的事;
-
代码流出(Code Output):用机器寄存器替代每一条机器指令中出现的临时变量名;
这样分解成多个阶段对编译器的好处是,能够尽可能重用它的组件。
例如,想要编译器生成针对于不同平台的 output,只需要更改栈帧布局(Frame Layout)和指令选择(Instruction Selection)这两个部分就行。
再例如,想要编译器编译不同的源语言,则只需要改变 “翻译” 模块以及之前的部分就行。
至于这些接口的用处:
- 抽象语法(Abstract Syntax)、IR 树、汇编(Assem)之类的接口,是以**数据结构**的形式做规约,方便下一阶段的实现;
- 另一些像 翻译接口、单词符号(token),是以**数据类型**的形式做规约;
其中,现代编译器两种最有效的抽象分别是:
- 上下文无关文法(Context-Free Grammar):用在**语法分析,理解为 “形式化描述一个编程语言的语法规则**,不涉及任何具体过程”;
- 正则表达式(Regular Expression):用在**词法分析**,理解为 “形式化描述一个编程语言合法的单词符号(token)”,现在已经被广泛应用到多个领域,例如 Web 前端的输入校验、文字匹配、IDE 高亮和提示等等;