Computer System Engineer
Computer System EngineerChapter 0. ConceptsChapter 1. Distributed System1.1 Concepts1.2 Filesystem Intro: Single-node inode-based Filesystem1.2.1 文件的定义1.2.2 实现文件系统的目标:从 Native FS 开始1.2.3 Block Layer1.2.4 File Layer1.2.5 Inode Number Layer1.2.6 File Name Layer1.2.7 Path Name Layer & Absolute Path Name Layer1.2.Ex Quiz1.2.8 Hard Links1.2.9 Symbolic Link Layer1.3 Implement the File System API1.3.1 OPEN1.3.2 READ1.3.3 CREAT1.3.4 WRITE, APPEND, CLOSE1.3.5 SYNC1.3.6 DELETE1.3.7 RENAME1.4 RPC1.4.1 RPC Message1.4.2 RPC Implementation1.4.3 How does RPC Handle Failures?1.5 Distributed File System1.5.1 NFS: Network File SystemDesignsPerformance & ImprovementsDrawback1.5.3 Case Study: Google File SystemDesign Assumptions: environmentsGFS InterfaceGFS ArchitectureComparison between Improved NFS & GFSGFS Interaction ModelReading a file in GFSWriting a file in GFSNaming in GFSHDFSSummary1.6 KVStore: System with a Simpler APIConceptsDesign Natïve KVSImprovements I: Redesign Implementation & Pack DataImprovements II: In-memory / On-Disk Index For Read & SearchImprovements III: Alleviate Write AmplificationImprovements IV: Large Range Query Supports1.7 Consistency Model1.7.1 Intro1.7.2 DefinitionsStrict ConsistencySequential ConsistencyLinearizability1.7.3 Implementation of Linearizability1.8 Eventual Consistency1.8.1 Definitions1.8.2 Converging State: Update ID & Write Ahead Log1.8.3 Causality Preserving: Lamport Clock & Vector Clock1.8.4 Truncate WAL1.8.5 Conclusion1.9 Consistency Under Single-Machine Faults: All-or-Nothing1.9.1 Shadow Copy for Atomicity1.9.2 Logging for Atomicity1.9.3 Conclusion1.10 Consistency for Isolation: Before-or-after Atomicity1.10.1 Definitions & 2PL1.10.2 Case: Salary System1.10.3 Deadlock1.10.4 OCC: Optimistic Concurrent Control1.10.5 Lock Preliminary:锁如何实现1.10.5 OCC & Hardware Transaction Memory (HTM)1.10.6 MVCC1.10.7 Conclusion1.11 Replications & Multi-site Atomicity1.11.1 2-PC1.11.2 Replication1.11.3 Single-Decree Paxos: Distributed Consensus MechanismPhase 1A: PreparePhase 1B: PreparePhase 2A: AcceptPhase 2B: AcceptPhase 3: Learn1.11.4 Multi-PaxosBasic ApproachImprovements1.11.5 RaftChapter 2. Revisit: Network2.1 Layers2.1.1 Link Layer2.2 Network Layer2.2.1 Control Plane: Routing Algorithm2.2.2 Data Plane: Packet Forwarding2.2.3 NAT: Network Address Translation2.2.4 Ethernet Protocol & ARP2.3 End-to-End Layer2.3.1 At Least Once Delivery2.3.2 At Most Once Delivery2.3.3 Data Integrity2.3.4 Segments and Reassembly of Long Messages2.3.5 Jitter Control2.3.6 Authenticity and Privacy2.3.7 Performance Improvement: Sliding Window2.3.8 TCP Congestion Control2.3.9 Weakness & Summary of TCP2.4 Yet Another Protocol in End-to-End Layer: DNS2.4.1 Definitions2.4.2 Look-up Algorithm2.4.3 Design Pattern of DNS2.5 Naming Scheme2.6 CDN2.7 P2P Network (End-to-End Layer Protocol)Chapter 3. Distributed Computing & Programming3.1 Parallelism on Single Chip Device3.2 Distributed Computing Framework: MapReduce3.2.1 Definitions: Batch Processing3.2.2 Overview3.2.3 Implementation3.2.4 Fault Tolerance3.2.5 Optimization3.2.6 Summary3.3 Computation Graph3.3.1 Definitions3.3.2 Application: Distributed TrainingData ParallelismModel ParallelismAsync vs. Sync executionChapter 4. Security4.1 Authentication (Password)4.2 CFI: Control Flow Intergrity4.3 Example: Buffer Overflow - BROP4.4 Data Flow Protection4.4.1 Taint Tracking4.4.2 Defending Malicious Input4.5 Security Channel4.5.1 对称加密4.5.2 非对称加密4.5.3 Replay Attack & Reflection Attack4.5.4 Diffie-Hellman Key Exchange, RSA & MITM4.5.5 证书4.6 Data Privacy4.6.1 OT: Oblivious Transfer (无感知传输)4.6.2 DP: Differential privacy (差分隐私)4.6.3 Secret Sharing4.6.4 Secure MPC (sMPC): Multi-Party Computing4.6.5 Homomorphic Encryption (同态加密)4.6.6 TEE (Trusted Execution Environment)
Chapter 0. Concepts
System: Interacting set of components with a specified behavior at the interface with its environment;
Course Target: 在学习了一行代码从 C -> ASM -> CPU -> Pipeline 的过程是细节;这门课会从宏观角度(千万行代码执行)讨论系统多出来的特性特征;
14 Properties:
Correctness:以一个 UB 为例:
xxxxxxxxxxchar *buf = <...>;char *buf_end = <...>;unsigned int len = <...>;if (buf + len >= buf_end)return; /* len too large */if (buf + len < buf)return; /* overflow *//* write to buf[0...len-1] */指针加法溢出是一个 Undefined Behaviour,最后两行代码会被删除;
Latency:当今的芯片,光速也是瓶颈;
Throughput / Capability;
Scalability:分工的例子;
Performance Isolation:系统资源隔离,性能是否能隔离开?
Utilization:服务器资源利用最大化;
Energy Efficiency:能源利用率;
Compability: Intel Itanium vs AMD;
Usability: Windows Mobile;
Consistency: 12306 数据库;
Fault Tolerance: Cosmic Radiation;
Security / Privacy;
Trust: Fighting Club;
Conflicts between 14 properties;
M.A.L.H: Modularity、Abstraction、Layering、Hierarchy;
Chapter 1. Distributed System
1.1 Concepts
Distributed System: A distributed system is a collection of independent computers that appears to its users as a single coherent system.
Fault, Error, Failure
Availability: X-nines to downtime;
Metrics: MTTF(平均故障时间)、MTTR(平均修复时间)、MTBF(平均故障间隔);
MTBF = MTTF + MTTR;
如何达到高可用性?
使用 replication(重复备份)handling failures,只要一个能访问就行;
会出现 data consistency 的问题。解决方案:主从备份、重复状态机;
retry(重复)handling failures
对于 stateless app / service 来说是可行的。
stateless 的 应用没有 data consistency 的问题;
某些类型的应用可以容忍 occasional inconsistency(如 Google Search);
LLM 服务不能通过 retry 容忍 inconsistency;
CAP: Consistency、Availability、Partition Tolerance(一致性、可用性、分区容忍)
Consistency:分布式系统所有结点同一时间对某一数据的值是一致的;
Availability:能保证一次请求一定能收到一次关于请求成功或失败的回复;
Partition Tolerance:分布式系统中某个部分出现消息丢失或者错误,系统仍然可以正常运行;
Partition tolerance means that a distributed system can continue to operate even if there is a communication breakdown between nodes. In other words, the system can handle network partitions, where some nodes cannot communicate with others due to network failures or delays. This ensures that the system remains functional and can recover gracefully once the partition is resolved.
CAP Theorem:一个分布式系统中,最多只能满足上述 3 中特性的其中两种。
并不是说满足了两种后,剩下一种完全没有,而是说剩下的一种无法完全保证。
1.2 Filesystem Intro: Single-node inode-based Filesystem
1.2.1 文件的定义
一种存储数据最自然的方法,一种高级别的对于存储的抽象;
两种性质:持久性、具有名称;
系统层使用硬件层的 modules 来构建对于文件的抽象:
OS Kernel 提供:OPEN、READ、WRITE;
Hardware 提供:API 相当复杂,但可以简化为:
Read(block_idx: int)、Write(block_idx: int, data: Sector);无法直接使用 Hardware 的抽象来实现文件,考虑几个问题:
存储一个远大于 Sector 的文件?
文件需要增大、缩小?
1.2.2 实现文件系统的目标:从 Native FS 开始
规定一个文件系统的 API(抽象文件系统的接口):
READ('name', offset, size) -> Array of data;WRITE('name', offset, size, data);
然后 data 需要是一个有限随机大小;
如果我们直接用 Hardware 的 API 做一个 Native File System:
每个 sector index 作为文件名;
写文件要么是 append,要么 reallocate;
问题是:
如何找到空闲空间?(暴力扫描,效率低)
如何扩充一个文件?(可能需要移动大量的 sector 内容,效率低)
meta-data overhead 比例很大:如果每个文件持有的 sector indices 都要保存(离散式),那么相当于每个 sector(大小由硬件厂商决定,4 ~ 256 bytes 不等)就要额外存放 8 bytes(需要能表示 sector 总大小)的数据,这是不能忍受的;
如果想要以字符串作为用户友好的文件名?
如果想对文件施加认证措施?
……
肯定不行。
我们需要借鉴 UNIX File System 的抽象(Naming Layers):
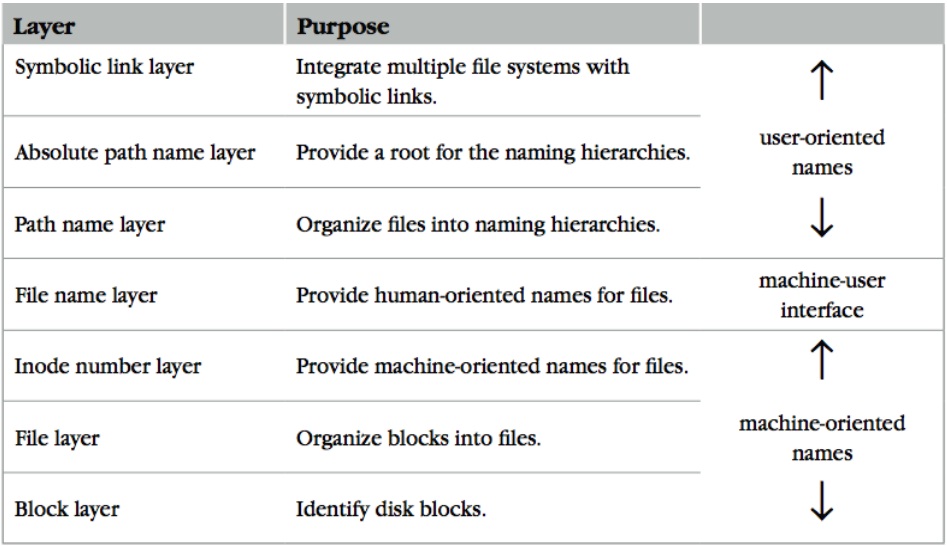
1.2.3 Block Layer
Block:文件系统最基本的数据单元。把多个连续的 sector 看成一个 block;
一般大于磁盘 sector 大小、允许对硬件资源更灵活的管理(因为管理 sector 粒度非常影响性能 以及存储效率);
一个 block 如果等于 4 个连续的 sectors,那么 metadata 的 overhead 就会下降 4 倍;
如何决定一个 block 的大小?它会影响 efficiency & utilization(回想 Memory Allocation);
太小(~ 1 sector)就会遇到和 sector 一样的问题,太大就会出现更多的 internal fragments;
目标:使用方法将 block 和 block number 映射起来:
xxxxxxxxxx// 给定一个 block number 就能访问指定 block 数据procedure BLOCK_NUMBER_TO_BLOCK(int b) -> blockreturn devices[b]存储结构划分(加入 block 思想):
首先,我们将存储空间划分为 n 个 block。
其次,我们需要让系统知道 block 是如何划分的,就需要将 block 的划分大小记录在指定区域内;我们定义这个区域为 Super block:
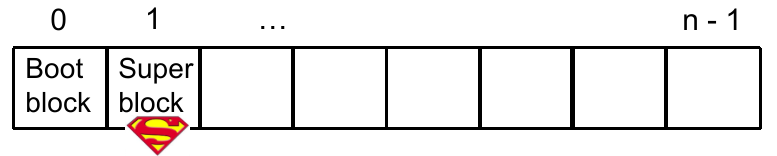
一个文件系统中只有一个 super block,在一个文件系统被 Kernel mount 的时候会去读这个块;
这个 super block 包括:
blocks 划分的大小;
空闲的 block 数;
有哪些空闲的 block(列表形式?);
其他文件系统的元信息(例如 inode 信息,之后讨论);
对于 “有哪些空闲的 block” 的问题,我们可以用 bitmap 的方式存放信息,每个 bit 1/0 来代表空闲情况,每个 bit 的 index 来代表 block 的 index;
这样做的好处是,存放信息紧凑(节省空间),但读取麻烦(遍历),不过在很多场景下表现是不错的;

注:为了方便起见,在今后讨论 block 时默认一个的大小是 4 KB(现实中可以有其他大小);
总结:block layer 把磁盘存储资源抽象成了一个大数组,每个 index 可以访问一个 block;
1.2.4 File Layer
有了 block 的抽象,在其上形成 file 的抽象就合理一些。
目标:我们想要抽象出以下内容:
一个文件是随机长度的线性的 bytes 数组;
文件可以存储大于一个 block 大小的数据;
文件可以自由扩大、缩小;
然后想要抽象文件的思路就很简单了:用 meta-data 声明一个文件所拥有的 block index 的集合。
这个声明 block index 的 meta-data 被称为 index node(inode):
xxxxxxxxxxstruct inode { long block_nums[N]; // 8 bytes 来表示 block number size_t size; // other fields here...};理所当然地,inode 信息也应该持久化,那么它应该放在哪个 block 中由谁指定呢?
也很简单,我们单独指定一些 blocks 来专门存放文件的 inode 信息。那么又有一个问题:文件的数量很大导致 inode 的数量也很多,这样一个 inode 能描述的文件 block 数量很有限。
于是我们借鉴页表的思想,让 inode 越靠后的 blocks 指向越深的 indirect blocks,像这样:
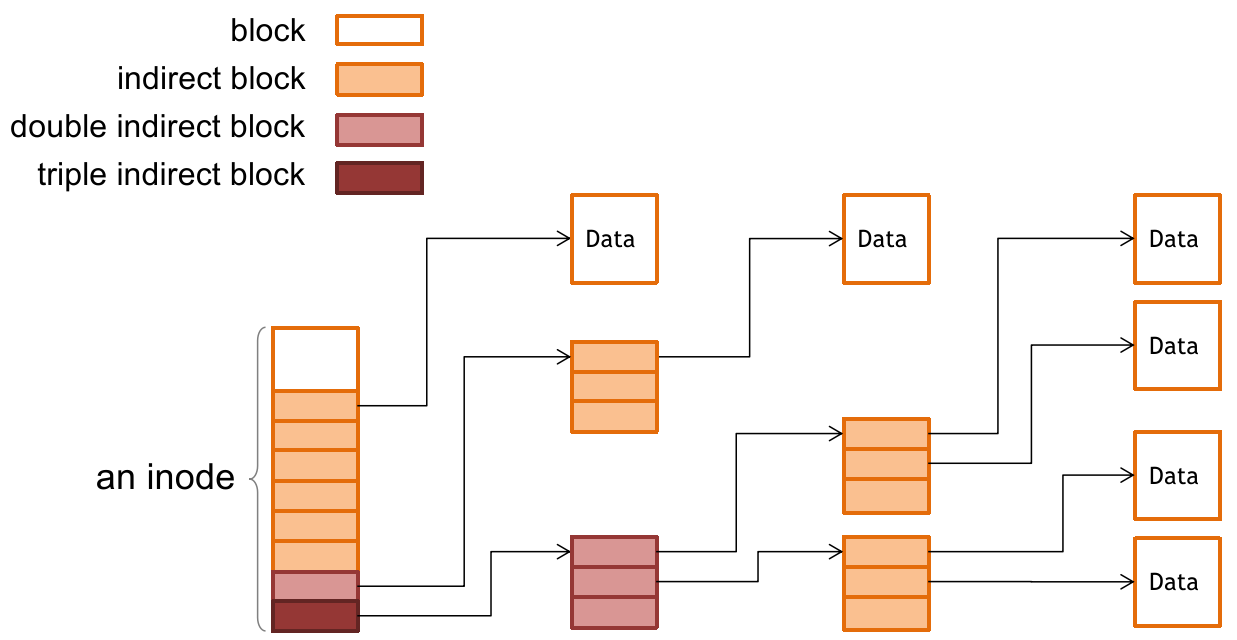
但不直接使用页表的设计。因为考虑索引次数和实际大小:磁盘上索引一次的耗时很长,而且一个文件往往没有一整个 address space 那么大;
这样文件靠前位置的数据能很快索引(靠后的数据也可以先 pre-fetch),性能上获得提升。
另外,一个 indirect block 可以放在 data blocks 中,有些实现也会放到 inode table 中,和具体实现有关。
值得注意的是,一个 inode 的大小取决于文件系统的具体实现。它的大小会反过来限制一个文件最大能承载的容量上限(主要是限制了 block number 数,即便采用了多层 indirect 的方式也有影响)。
通过上面的设计,我们现在能够实现这样的映射关系:
xxxxxxxxxx// 给定一个文件的 inode 和文件内偏移量,就能找到指定位置所在的 blockprocedure INODE_TO_BLOCK(int offset, inode i) -> block o <- offset / BLOCKSIZE b <- INDEX_TO_BLOCK_NUMBER(i, o) return BLOCK_NUMBER_TO_BLOCK(b)
// 给定 inode 内的 block 在列表中的 index 就能找到 block numberprocedure INDEX_TO_BLOCK_NUMBER(inode i, int index) -> int return i.block_nums[index]总结:为了组织很多离散的 block 为一个文件,引入 inode 数据结构。inode.block_num[N] 中记录了文件的第 i 个 4K 内容放在哪个 block 上(block number)。
但是如果文件很大,那么就需要很多 block 来存放,这样 N 会很大(一个 4KB block 需要 8 bytes 描述 block number,那么一个 16GB 文件需要 4M 个 block,也就是 32MB 空间来记忆所有 block number),不现实。
因此我们给 inode block_num 数组靠后的几个 entry 采用多级 indirect 的方式来索引获得 block number,这样能存放更多的 block number;
1.2.5 Inode Number Layer
现在解决了一个文件的抽象。但是要找一个文件的数据首先就找 inode,我们说要单独为它们准备一个地方,这个 inode 存放的专门的位置就称为 inode table,这些 inode 的索引就是寻找 inode 的唯一标识:inode number。我们将这个抽象层称为 inode number layer;

其中 inode table 由一块块 block 组成,每个 entry 的大小就是一个 inode 的大小;
为了节省空间,防止开辟的 inode table 大小过大,我们可以考虑存放 inode table 的 table,让这个 table 的每个 entry 指向下一级 inode table 的起始地址(indirect)。这也是一种方法,不过性能会差点。
Inode Table 的起始地址是固定在 bitmap for free blocks 之后的位置,它可以放在 super block 中;而 inode table 可以指示哪些 inode number(index)是空闲的;
这样我们能实现新的映射关系:
xprocedure INODE_NUMBER_TO_INODE(int num) -> inode return inode_table[num]
// 给定一个文件的 inode number,以及文件内偏移量,就能找到指定位置所在的 blockprocedure INODE_NUMBER_TO_BLOCK(int offset, int inode_num) -> block inode i = INODE_NUMBER_TO_INODE(inode_num) return INODE_TO_BLOCK(offset, i) // 之前实现的到这为止,我们已经实现 “通过一个标识符(inode number)自由访问一个可伸缩文件的内容” 的目标了。但是还有一些需求没有满足:
file 能否有一个 user-friendly 的名字?
考虑到用户态的 application,能否在此基础上包装一层,以便 OS 做权限控制?
总结:指定 inode 就需要让 inode 能够描述。这个时候我们将 inode 单独组织在一片 block 中(inode table),并且用索引来标识它们(所以 inode number 和位置有关);
1.2.6 File Name Layer
现在我们为了实现 user-friendly name,我们再加一层 file name layer,将文件名(字符串)和 inode number 联系起来。这是个表的结构,也需要存起来,它应该存放在哪?答案是一种特殊的文件:目录。
也就是说,这种文件名 - inode number 的映射关系就用名为 “目录” 的特殊文件来保存(目录内也只包含这样的映射,不包含文件内部的任何信息):
| File name | Inode number |
|---|---|
helloworld.txt | 12 |
cse2024.md | 73 |
然后 inode 的结构可以更新为:
xxxxxxxxxxstruct inode { long block_nums[N]; size_t size; int type; // directory or regular file // other fields here...};注:在 EXT4(一个现代的 UNIX FS)中,规定 type:
0x0: Unknown;
0x1: Regular file;
0x2: Directory;
0x3: Character device file;
0x4: Block device file;
0x5: FIFO;
0x6: Socket;
0x7: Symbolic link;
这样我们能建立起新的映射关系:
xxxxxxxxxx// 给定一个文件字符串名,以及它位于的目录文件的 inode number,就能找到文件的 inode number// 就是在目录文件中找映射结果,LOOKUPprocedure NAME_TO_INODE_NUMBER(string filename, int dir) -> int block b inode i = INODE_NUMBER_TO_INODE(dir) if i.type != DIRECTORY then return FAILURE // Not a directory // 遍历 directory 文件的所有 block data 匹配字符串 for (int offset = 0; offset <= i.size - 1; ) do b <- INODE_NUMBER_TO_BLOCK(offset, dir) if STRING_MATCH(filename, b) then return INODE_NUMBER(filename, b) offset <- offset + BLOCKSIZE return FAILURE // Cannot find the filename in dir总结:inode number 是与 inode table 位置相关的标识,直接使用会各种问题,例如文件 inode 用户不友好、不好控制权限等问题。于是我们引入了 “目录” 这种特殊文件,来单独保存这种映射关系。
因此文件名不在文件里、不在文件的 inode 里,而是仅存在于目录文件里。
一般情况下 UNIX 目录没法直接看 directory 文件中的 raw content,需要用
/sbin/debugfs来查看:xxxxxxxxxx$ debugfs <disk device> # enter interactive mode$ dump <file> <output>$ quit$ xxd <output> # or hexdump -C <output>
注意到 2 个问题:
上面的目录是按照 block 查找匹配的,如果文件名跨两个 block,应该怎么办?
两种方法:一种是把算法写复杂一点,考虑边界情况;另一种是限制文件名长度,并且利用数据结构大小做对齐,使得文件名不会跨越两个 block。
在 UNIX v6 中规定了一个文件名最大长度是 14 bytes,可能就说明了它是使用了后一种方法来处理的。
上面的 LOOKUP 算法只能针对同一级目录下的文件。如果文件数量很多,我需要分多个目录层级(目录里套目录),这个时候我们要么使用递归查找(效率慢),要么引入一种新的描述方法,直接描述文件在层层嵌套的目录中的位置。这就是 path name;
1.2.7 Path Name Layer & Absolute Path Name Layer
为了解决上面多层目录文件定位的问题,我们引入了新一层抽象:path name layer;
对应新的映射关系如下:
xxxxxxxxxxprocedure PATH_TO_INODE_NUMBER(string path, int dir) -> int // 如果是单独的文件名(没有由“/”组成的 path),即递归终止条件 if PLAIN_NAME(path) return NAME_TO_INODE_NUMBER(path, dir) else // 在当前目录(dir,context)下找最前项目录文件(例如 FIRST("a/b/c") = "a") // 找到最前项目录后更新 context 为该目录,进入下一层 // 找不到也递归终止 dir <- LOOKUP(FIRST(path), dir) // 例如 REST("a/b/c") = "b/c" path <- REST(path) // 递归查询 return PATH_TO_INODE_NUMBER(path, dir)注意到目录结果是否有终极父结点?答案是有的。UNIX FS 的所有文件全部是 /(根目录)的子文件。
而以 / 开头的就是绝对路径。当然 / 目录文件会放在 inode table 的特殊位置(一般 inode number 为 1),方便让系统查找(提供递归终止条件)。
那么一个相对路径和绝对路径是能相互转换的。
xxxxxxxxxxprocedure GENERATEPATH_TO_INODE_NUMBER(string path) -> int // 就以 / 的 inode number 为 context 开始查找 if path[0] == '/' then return PATH_TO_INODE_NUMBER(path, 1) // 开头没有 '/' 说明是相对路径,则从 wd(working directory)的 inode number 开始 else return PATH_TO_INODE_NUMBER(path, wd)1.2.Ex Quiz
如下图的文件系统中,系统如何查找 /programs/pong.c?
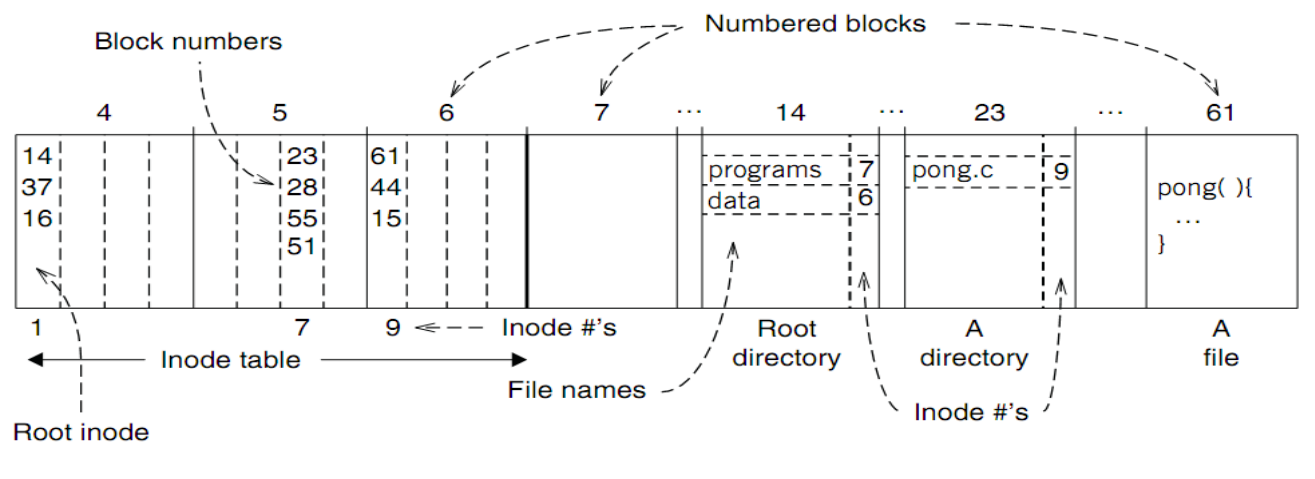
解析 path 为绝对路径,找
/(inode number = 1)的目录文件的 block number:14, 37, 16;先在 block number = 14 的 block 中查找
"programs",找到其映射的 inode number 为 7;索引到 inode table 中,发现
"programs"目录文件占用 block number:23, 28, 55, 51;现在 block number = 23 的 block 中查找
"pong.c",找到其映射的 inode number 为 9;索引到 inode table 中,发现
"pong.c"的内容占用 block number:61, 44, 15;现在可以按 offset 在 block 中读取数据了;
1.2.8 Hard Links
在 path name layer 的基础上,做一种快捷方式,可以用较短的 path name alias 到很长的 path name,实现快速的解析和访问。
为了实现这个目标,我们想出两种接口:
LINK(filename, shortcut):为一个 path name 建立 shortcut,实际上就是在dirname(shortcut)目录文件下创建新的映射,这个映射用的filename的 inode number 和shortcut的名字;这就是 UNIX 中的 “硬链接”(hard-link)。
这下就能回答,为什么硬链接不能跨磁盘(文件系统)创建了。
因为硬链接名和原文件名映射的是同一个 inode number,而一个磁盘上有一个独立的 inode table,相互独立、两个表间一个 inode number 可以表示不同文件;
UNLINK(filename):解除filename与 inode number 的映射。就是 UNIX 中的 “删除”(rm);
另外我们需要设计几条规则:
引用计数:当 file name 与 inode number 的最后一条映射解除后,可以视作文件被删除(free inode / block);
因此我们需要 inode 的结构中含有引用计数:
xxxxxxxxxxstruct inode {long block_nums[N];size_t size;int type; // directory or regular fileint refcnt; // reference count// other fields here...};有向无环:由于建立了 path name layer 后,文件系统组织成了树形结构,因此需要有向无环(directed-acyclic)的特性;
因为如果存在自环,引用计数的系统就会存在问题。这会给系统带来无法释放的 inode,明明已经没有用了(没有任何从
/出发能访问到这个 inode 的文件名),但引用计数仍然存在,导致磁盘空间资源泄漏;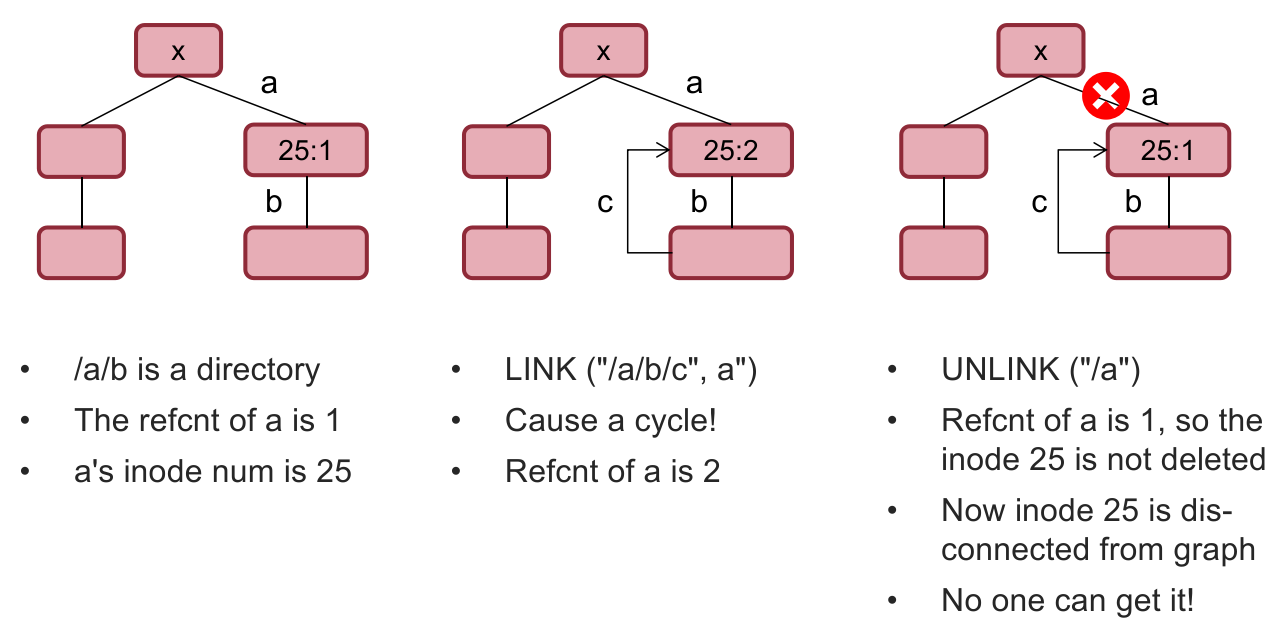
因此 UNIX 系统规定不允许给目录创建硬链接,就为了避免这种情况。
但是
.和..是特例,它们是指向当前目录 或 上层目录的硬链接,只能由文件系统自己创建确保不会出现资源泄漏的问题;同样,UNIX 系统不允许直接删除一个非空目录,而是需要先删除内部映射的文件,再删除目录本身,其目的也是类似的(防止资源泄漏)。
根目录回环,对于
/.和/..都指向/自身;
有了 LINK 和 UNLINK 的接口和语义,我们就能在此基础上实现更丰富的功能。
例如重命名 和 移动,它们本质上在 UNIX FS 中是同一种操作。无非是 将一个文件原来记录在目录 A 中的映射关系移动到目录文件 B 中记录,其中 A 和 B 可以相同(重命名操作),并且移动过程中映射的文件名可以改变(移动操作);
那么实现这个功能:move(from_name, to_name),就可以由下面的操作完成:
UNLINK(to_name):如果有to_name就会覆盖,相当于先删除;LINK(from_name, to_name):在dirname(to_name)下创建一个from_name的 inode number 和basename(to_name)的映射;UNLINK(from_name):最后把原先的文件删除即可;
但这么做有问题:如果 OS 在 1~2 步骤间掉电,那么 to_name 的文件会被删除,但 from_name 还没有移动,这就会产生意料之外的行为。
1.2.9 Symbolic Link Layer
为了解决 “不在一个文件系统下,却想要创建快捷方式” 的问题,UNIX 提供了更高一层抽象:软链接层。
这个软链接也是一个文件,不过它和硬链接产生的 regular file 不一样,它是一种特殊的文件,里面只包含要链接文件的 pathname;
因此,和硬链接不一样的一点是,甚至目标文件不存在时,我也能创建一个软链接(因为这个文件只包含 path name,并且是独立的、特殊文件类型,本身有独立的 inode);
例如:
xlrwxrwxrwx 1 xhw xhw 14 Oct 7 20:36 tiler-json -> tiler/geojson/为什么
tiler-json软链接的大小是 14 bytes?因为它内部内容只有字符串"tiler/geojson/"(长度 14)!我们可以通过
readlink指令阅读软链接的实际内容。
所以,symbolic link 是以 path name 与目标文件关联,不受 reference count 影响;
hard link 是以 inode number 与目标文件关联,会影响 reference count,并且不能跨文件系统;
总结区别:
inode 是否独立?
是否影响 reference count?
是否能跨文件系统?
存放内容的机制是怎样的?
sidebar: 在
cd到一个软链接指向的目录后,如果想显式去往当前目录的真实上级目录(不考虑软链接),则需要指定cd -P ..,否则大多数 shell(bash / zsh 等)会认为你是想去历史上上一次 context 位于的目录;
1.3 Implement the File System API
在了解 FS 基本的设计理念和规约之后,我们可以着手实现一个 file system 了。首先列出 OS system call 需要的 File System API:
CHDIR, MKDIR;
CREAT, LINK, UNLINK, RENAME;
SYMLINK;
MOUNT, UNMOUNT;
OPEN, READ, WRITE, APPEND, CLOSE;
SYNC;
在此之前,我们揭晓 inode 数据结构中剩下的数据成员。剩下的数据成员没有体现在 File System 的设计理念中,是因为它们是 OS 管理文件必要的其他元信息,和文件存储本身关系不大:
xxxxxxxxxxstruct inode { long block_nums[N]; size_t size; int type; // directory or regular file or symbolic link int refcnt; // reference count // other fields here... int userid; int groupid; int mode; int atime; // 文件内容上次被访问的时间(READ) int mtime; // 文件内容上次更改的时间(WRITE) int ctime; // inode 上次更改的时间(例如 LINK 改了 refcnt,或者改了权限)};现在我们再回头看看磁盘文件系统中详细是什么:

提问:2T 硬盘的 data free block bitmap 大约占多大的空间(忽略 inode free block bitmap 和 boot/super block)?
2TB bytes 空间需要 2T / 4K 个 bit 作 data free block bitmap;
2T / 4K (bit) / 8 (bit / bytes) = 64 MB;
1.3.1 OPEN
此操作需要完成以下步骤:
检查当前用户权限;
更新文件
atime(也可在 READ 时更新);返回临时的、对某个进程而言的,该文件的 short name(file descriptor),这样不必反复进行字符串比较;
为什么 short name 不使用 inode number(或者 inode 指针 / block number)?有以下几点考量:
Security:file descriptor 相当于一层 indirect layer,让用户态无法直接访问内核态数据;
Non-bypassability:任何 FS 操作都由 Kernel 完成;
其中还需要回想一下 file descriptor table、file table、v-node table 三者的关系及其组成。
fd table 保存了:
file descriptor;
file table entry index;
file table 中保存了:
inode number;
file cursor;
file table entry reference count(不是 inode reference count);
其中 fork 出的父子进程一开始复制 fd table(但不共享)、共享 file table entry;
所有进程共享一个 file table,但不一定共享 file table entry,如图:
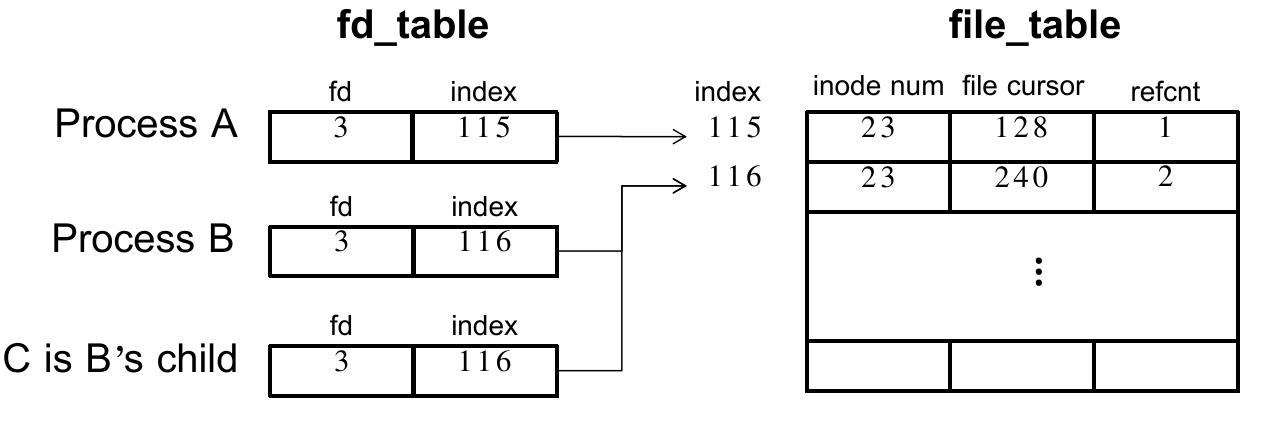
注意 file cursor 可以被 SEEK 操作改变、随着 READ 而不断前进;
搞清楚细节后就可以开始实现 OPEN 方法了:
xxxxxxxxxxprocedure OPEN(string filename, int flags, int mod) -> int inode_num <- PATH_TO_INODE_NUMBER(filename, wd) if inode_num == FAILURE and flags & O_CREATE then inode_num <- CREATE(filename, mode) if inode_num == FAILURE then return FAILURE inode <- INODE_NUMBER_TO_INODE(inode_num) // 检查当前用户权限和其要求的权限,对于指定的 file 是否有权 if PERMITTED(inode, flags) then // 更新 file table 和 fd table file_table_index <- INSERT(file_table, inode_num) fd <- FIND_UNUSED_FD_TABLE_ENTRY(fd_table) fd_table[fd] <- file_index return fd else return FAILURE1.3.2 READ
在打开文件后,READ 操作也不难,尤其是我们已经清楚了 fd table 和 file table 的机制:
xxxxxxxxxxprocedure READ(int fd, char[] &buf, int n) -> int // 获取 file cursor file_table_index <- fd_table[fd] cursor <- file_table[file_table_index].cursor // 检查实际能读取的长度 inode <- INODE_NUMBER_TO_INODE(file_table[file_table_index].inode_number) m <- MINIMUM(inode.size - cursor, n) // 更新 atime atime of inode <- now() // 读取文件数据 if m <= 0 then return EOF for (int i = 0; i <= m - 1; ) do // 一次读取不超过一个 block b <- INODE_NUMBER_TO_BLOCK(cursor + i, inode_number) copy_size_in_one_time <- MINIMUM(m - i, BLOCKSIZE) COPY(b, buf, copy_size_in_one_time) i <- i + copy_size_in_one_time file_table[file_table_index].cursor <- cursor + m return m现在我们综合起来讨论一下,1 次 OPEN、1 次 READ 大量数据需要多少次磁盘的 read 和 write:
xxxxxxxxxx/* /foo/bar 存在 */int fd = open('/foo/bar', O_RDONLY);char buf[3 * BLOCKSIZE + 1];read(fd, buf, 3 * BLOCKSIZE);
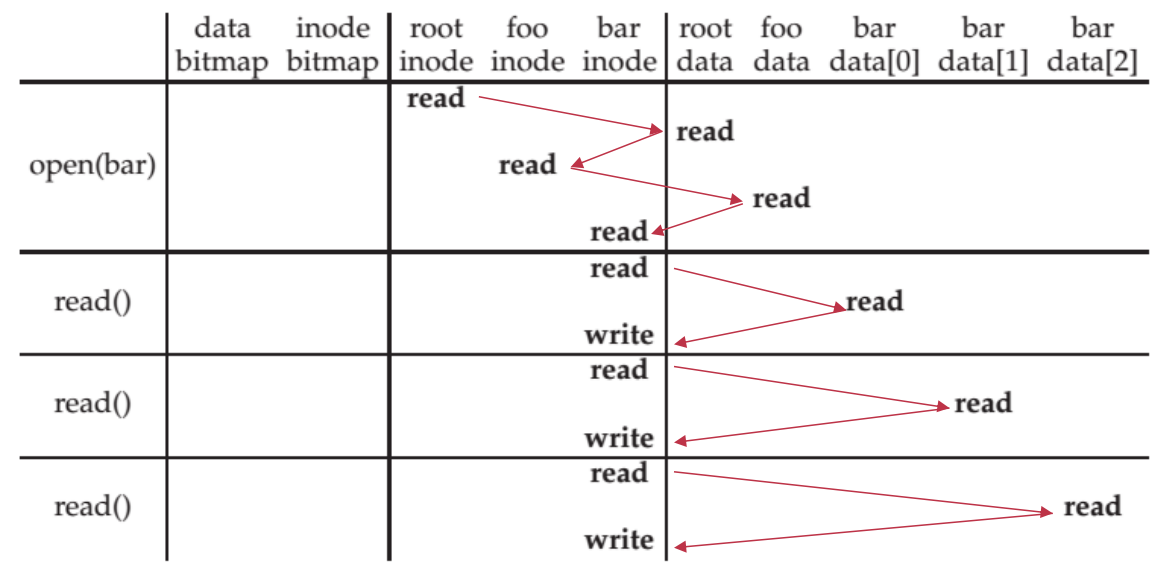
首先 open 时:
按
/inode number = 1,找到/的 block number(磁盘 read 一次);按
/的 block number 找到/的 block 中的内容并扫描"foo"(磁盘 read 一次),顺便找到它的 inode number;按
/foo的 inode number 去 inode table 找 block number(磁盘 read 一次);按
/foo的 block number 找 block 中的内容并扫描"bar"(磁盘 read 一次),顺便找到它的 inode number;注意:最后得到
/foo/bar的 inode number 后,还需要去bar的 inode 中读取并检查权限信息(磁盘 read 一次);
read 因为跨了 3 个 block,因此分 3 次 read;
第一次 read 时:
按照 fd table & file table 找到 inode number(读内存),然后去 inode table 中找
/foo/bar的 block number(磁盘 read 一次);再按 block number 去文件占用的 block 中读取并复制一段数据到内存 buffer 中(磁盘 read 一次);
再去文件 inode 中修改文件
atime(磁盘 write 一次);
第二次、第三次同理,不过遍历了
/foo/bar的 inode 中的 block number 数组;
在 UNIX FS 加载过程中,如果有参数
-noatime,那么 READ 就不会每次 磁盘 read 时写一遍atime,而是在文件关闭时写一次;
1.3.3 CREAT
如果是创建的话,除了文件(包括目录文件)内自身的数据,还需要注意更改 data free block bitmap、inode free block bitmap 的数据(一般不考虑 super block,因为在 FS 加载时就读完了);
下面的图片是这段代码的 timeline:
xxxxxxxxxx/* /foo/bar 不存在 */int fd = open('/foo/bar', O_CREAT | O_WRONLY);char buf[3 * BLOCKSIZE + 1];read(fd, buf, 3 * BLOCKSIZE);
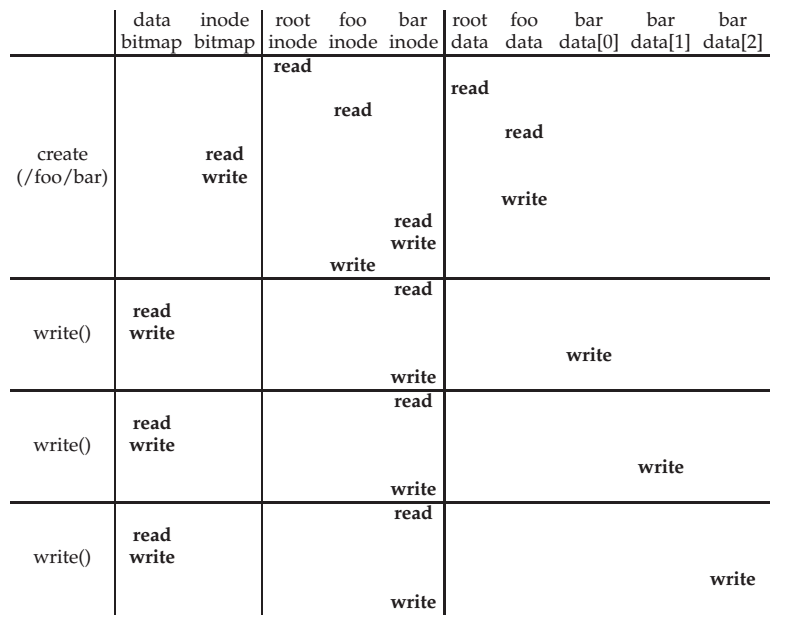
那么现在有个问题,在写一个新的文件的时候,下面哪个顺序更好?
Update block bitmap, write new data, update inode (size and pointer);
Update block bitmap, update inode (size and pointer), write new data;
Update inode (size and pointer), update block bitmap, write new data;
最好的是第 1 种方案。
第二种坏在如果在第二步~第三步间断电,那么内存中原来被释放的数据可以在下次启动时被完好地读出来,造成信息泄漏的隐私安全问题。
第三种在哪一步断电都有安全危险。
第一种最坏的情况不过是泄漏了一些磁盘空间,而且可以通过磁盘扫描(扫描 free bitmap 和实际 inode 引用)进行纠正。
1.3.4 WRITE, APPEND, CLOSE
就像上面演示的一样,WRITE 操作类似 READ 操作,不过需要分配一些新的 block、更新 inode 的 size 和
mtime;APPEND 操作和 WRITE 类型,向文件尾的 block 写数据,必要时分配新 block,更新 inode size 和
mtime;CLOSE 操作则需要完成 释放 fd table、减小 file table reference count、释放 file table 中 refcnt 为 0 的 entry;
上面的操作在中途断电后都会造成 inconsistency 的问题;
1.3.5 SYNC
反复的磁盘 read 和 write 在磁盘看来问题不会那么大,因为磁盘厂商可能会在其中做一些 block cache;
因此可能在写完一组数据后 / 批处理后 / 关机前需要真正落盘(force flush),而不是放在 cache 中。所以产生了这个指令。这条指令会让所有对 file 的更改全部落盘。
这条指令的问题是,在断电后会出现 inconsistency;
1.3.6 DELETE
其实就是我们之前实现的 UNLINK(取消硬链接)接口,和 WRITE 是类似的反操作。
不过需要注意的是,如果一个进程打开一个文件的时候,另一个进程删除了这个文件,虽然这个 file 的 inode reference count 为 0,但在 file table 中如果这个 inode 的 file table entry reference count 不为 0,因此 inode 不会被释放。直到进程关闭了这个 inode 文件后、file table entry 中所有对于 inode 的 entries 全被释放,该文件的 inode 才会被释放(+ free bitmap)。
Window 上删除一个被打开的文件是禁止的,实现方式类似文件锁。
1.3.7 RENAME
实际上我们之前讨论过这个问题,使用 LINK 和 UNLINK 方法实现 RENAME,但是 UNLINK + LINK + UNLINK 的操作在第 1-2 步间掉电时会出现意外的行为(to_name 丢失),所以改成两步:
LINK(from_name, to_name)(weak specification):将to_name映射的 inode number 转为映射from_name指向的 inode number,并且减小to_name指向 inode 的 refcnt;Q&A:思考是否有必要增大
from_name的 inode refcnt?UNLINK(from_name)(weak specification);
注意到:
to_name的 inode number 与原来的from_name的 inode number 完全相同;如果在 1-2 步间断电,那么需要注意,
from_name的 inode refcnt 在理论上是需要增大的,但实际上上面的步骤没有更改,所以为了保证 inode 一致性需要在恢复时增大from_name的 inode refcnt;并且在文件系统恢复时需要删除
to_name的映射;
1.4 RPC
定义:远程跨进程调用;
一段话概括:
RPC simplifies programming w/ an interface similar to local function call;
RPC uses stubs to avoid handling argument encoding/decoding and send/receiving messages, etc.
Ensure correctness & efficiency.
目标:It should appear to the programmer that a normal call is taking place;
实现思路:build the RPC atop of the socket interface;
要求:Hide the construction of messages and remote invocation logic from the developers;
在单个语言层面其实有各自实现。
例如 Java 中有 RMI(Remote Method Invocation,面向对象版本的 RPC);
1.4.1 RPC Message
应该包含:
Service ID (e.g., function ID);
Service parameter (e.g., function parameter);
Using marshal / unmarshal;
保证在内存中的数据结构在网络上传递,并且在 server 端能够正确解析;
例如:
[TYPE][SIZE][DATA...];
费时:
系统调用 domain switch;
消息 copy、marshal;
注:最初的 RPC 库安排的 Request Message 有如下构成:
Xid(Transaction ID)、call/reply、rpc version(for compatibility);
program #(Process ID / port)、program version、procedure #(Function ID);
auth stuff、arguments;
而 Reply Message:
Xid(Transaction ID)、call/reply;
accepted? (Yes, or No due to bad RPC version, auth failure, etc.);
success? (Yes, or No due to bad prog/proc #, etc.);
auth stuff;
results;
其中消息传递的挑战性很大:
消息传递方式是 value 而不是 reference。所以传输前需要确保 pointless;
DSM(Distributed Shared Memory):可行性有点低。关键是任务难以干净地切割。如果两台机器需要操作同一片内存地址,那么数据需要频繁在多台机器间传递。因此它只能用在特殊的业务场景中;
分布式系统间兼容性不佳。有很多不同:
byte ordering;
sizes of integers and other types,floating point representations;
character sets
alignment requirements
etc.
我们对于消息传递的目标如下:
正确传输:Correctly encode and decode a object to a byte stream;
兼容性:Support multiple language, multiple versions of program;
传输信息效率:Reduce the traffic transferred from the network; Network bandwidth is a scarce resource!
如果是 Texture Format:
优点:human-readable、easy to debug;
缺点:
Ambiguity around encoding of numbers(如整型类型模糊);
Binary String have to re-encode the string as Base64(二进制字符串需要特殊编码);
use more bytes to store the data(空间效率低);
如果是 Binary Format:
优点:可以极致压缩、表达数据更准确(约定 schema: Interface Definition Language (IDL))、解析/存储更快、传输效率高;
缺点:less human-readablity;
1.4.2 RPC Implementation
框架通过声明自动化生成代码,实现 参数编解码、收发消息、消息传输 等动作;
Generate stubs from an interface specification;
Tool to look at argument and return types;
Generate the marshal and unmarshal code;
Generate stub procedures;
消息传递需要确保:正确性、固实性、兼容性;

RPC 传输协议:
TCP/UDP:根据实际场景选择;
对网络环境要求高的请求使用 TCP;
网络本身很好几乎不出问题的内网中,或者网络环境要求不高的请求可以使用 UDP;
是否使用新的网络协议?例如 RDMA(Remote DMA,某设备绕过 CPU 复制内存中的数据);
1.4.3 How does RPC Handle Failures?
A user sends an RPC but the server does not reply, possible reasons:
请求丢失;
消息拥塞(网络或服务器超负荷);
远程服务器节点崩溃;
处理方式要根据:
前提语义:at-least-once、at-most-once、exactly-once;
服务性质:是否幂等(重试的可行性);
1.5 Distributed File System
在 RPC 的帮助下可以建立一个分布式文件系统。
目的:file system scalability;
访问远程文件的设计办法:
显式声明(主动写网络访问的函数,例如 FTP/Telnet/网盘等) (knowing it is a distributed file system);
Transparent Approach(例如 NFS/GFS 等):应用程序访问远程文件就像访问本地文件一样的方式;
这使用了 remote access model:
文件服务通过 RPC 暴露了一系列和本地文件系统类似的 API 以供调取;
如果我们使用显式访问的方式来访问文件行不行?有问题:
(资源浪费)Wasteful “what if client needs small pieces?”;
(异常处理)Problematic “what if client does not have enough space?”;
(数据一致性保持)Consistency “what if others modify the same file?”
1.5.1 NFS: Network File System
Designs
设计目标:
任何机器可以作为 client 或 server;
可以支持 diskless 工作站;
支持不同的部署特性(Different HW, OS, underlying file system);
远程调用无感知(使用 remote access model);
轻松从 failure 中恢复(Stateless, UDP);
高性能(Use caching and read-ahead);
NFS 对外界发布的 API:
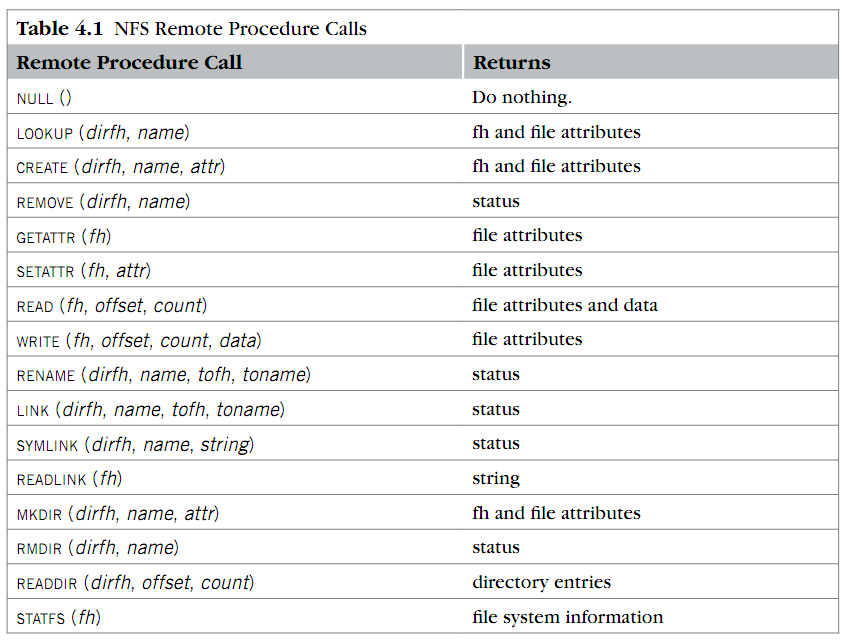
注意到几点:
No Open & Close;
为什么 NFS 中没有 OPEN,主要看 OPEN 的作用:
检查用户权限;
更新 atime;
返回一个同进程中使用的 file short name(fd),并且 file descriptor 管理在 fd table 中;
如果要在 NFS 中实现 OPEN,则 RPC 会变成 stateful 的请求。
而 stateful RPC 难以维持:
better fault tolerance(server 挂了/reboot);
scalability & performance(大量 client 请求?);
Use file handler instead of fd / inode number;
file handler 应该用什么?
它的作用就是用来指定/区别 server 上的文件。
不是 fd: fd 在打开时生成,但 NFS 没有 OPEN 操作;
不能用 pathname / filename:因为假设有两个 client,一个在改目录名
dir1 -> dir2; dir3 -> dir1,另一个在打开这个目录中的文件dir1/f;按 Unix Spec,最终修改的文件应该是
dir2/f,这在 NFS 内不方便实现;不能用 inode number:假设有两个 client,A 在打开某个文件,B 在这个文件打开后、阅读前删除了这个文件,并创建了新文件;如果这个时候 A 如果读这个文件,就会发现文件根本不是之前的;
解决方案:让 A 读之前的文件(但是是 stateful 的,并且 client 可能不会释放,因此在 NFS 场景下不能使用这个方法),或者报错;
这里就没有遵循 Unix Spec(读 previous file);
最终实现方法:在 Inode Number 基础上加入 Generation Number(File Handler 的真实身份)。每当分配一个 inode number 后,generation number 自增;如果出现上述情况,则 reader 的 file handler 和新的 file handler 的 generation number 不一致,因此可以报错;
Use offset directly instead of file cursor;
保持 Stateless(幂等性): 简化错误处理,at-least-once 语义;
但是像 WRITE 这样的调用,显然还是 at-most-once 语义。两个 client 如果在写一个文件,如果不做具体措施处理,一个很可能会覆盖另一个的操作。
一个可行的解决方案是 server 管理一个 “soft state”(例如 reply cache);
当一个应用尝试读一个远程文件时:
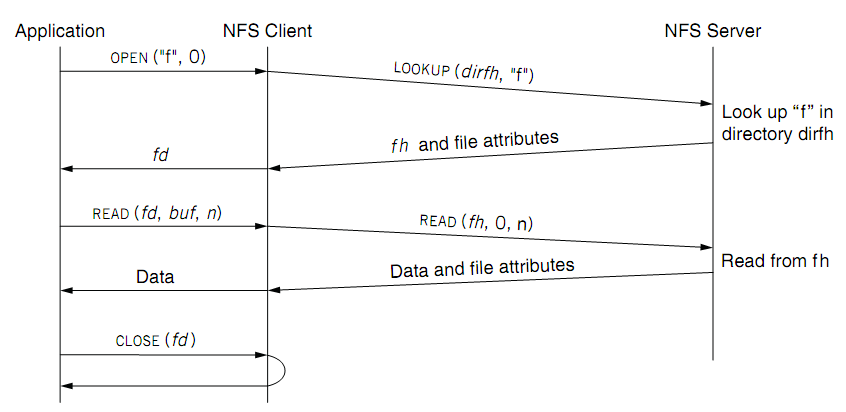
Performance & Improvements
分析:有时候 Network File System 会比本地磁盘还要快(取决于网速和文件服务器性能);
优化:在 client 端做 cache;
系统优化 3 大件:Cache、Hash、Batch;
目标:减少远程操作数;
缓存内容:
read, readlink, getattr, lookup, readdir;client 缓存文件数据:buffer cache;
client 缓存文件属性信息;
client 缓存 pathname bindings(为了更快的 lookup);
注:在 Server 端,OS 会自动地 cache;
缓存的问题:数据一致性。无法读到最新修改的数据。解决方案:
Close-to-open Consistency:
打开文件前检查文件属性(最后修改时间)并与 cache 对比;
当关闭时向服务器 flush cached 信息,server 在 CLOSE 这个文件时发现是 dirty 的,则写回文件;
Read/Write Coherence:
server、client 都保存一份文件的 timestamp;
当文件打开 / server 提醒时,比较最后修改时间,如果 remote 更新则 invalidate cache;
总是在一段时间后取消 cache 的有效性(文件 3s,目录 30s);
因此 inconsistency 可能总是会存在 NFS 中,但是能保证最终一致性;
除了 cache,还可以从 read-ahead(顺序读文件时,预加载)、消息网络传输压缩等思路考虑。
Drawback
NFS 目前还是基于单机的远程文件系统。
(Capacity)单服务器容量上限(一个服务器最多插那么多磁盘);
(Reliability)可靠性不佳(server 挂了就没了);
(Performance)文件读写性能限制在一个文件、一个服务器的网路带宽上;
想法:把很多台机器放在一起组成一个超大的文件系统。
具体实现思路是做手动的分区和备份——但不好,又回到了 FTP 的样子。
也许我们没法完全重用 inode-based file system,需要对它做一些改进:
Block Layer 改进为 Distributed Block Layer(增添 scability):
访问方式改进:将访问
block_id扩充为<mac_id, block_id>(MAC 地址可以定位机器);如何找 free blocks:最好不要轮询尝试。最好使用 master 结点管理 free blocks 的 meta-data,并且所有 block allocation/deallocation 工作移交给 master node 完成;
File Layer (Inode):几乎不需要变动,只需要把查找 File Inode Block 的
block_id改成上面定义的扩展形式就行;不过还要考虑性能问题,以后再来讨论;
Inode Number 改进为 Distributed Inode Number Layer:把 Inode Table 和 free blocks 信息一起放到 master node 中。
File Name Layer 目前还不需要改变!
这样的改进也只能改进 capacity,没法提升:
reliability(master 结点、存放 blocks 的结点挂的问题);
fault tolerance / correctness(一旦有一个错误出现,会导致整个系统 file system corrupted,这是很严重的问题);
performance:由于需要多次反复查询,path lookup 会很慢(不过可以通过 cache 缓解);
想要进一步解决上面的问题,还需要更强的武器(如 data replication,但又会引入数据一致性问题);
1.5.3 Case Study: Google File System
Design Assumptions: environments
文件本身很大(例如 large web index);
failures 很常见(成百上千台机器,出错是普遍而不可避免的);
文件写的方式大多数是 Append-Only 的(随机写的情况相当少);
workload 大部分是 sequential read(large read streams);
设计需求:scalable、data-intensive、fault-tolerant、high performance;
GFS Interface
不完全支持 POSIX API;
基本操作:
create/delete/open/close/read/write;额外操作(基于应用场景作出优化):
snapshot/append;不支持的操作:
link, symlink, rename;原因:这些操作在 failure 时需要保证一致性,需要花精力处理这些问题。而目前分布式事务实际上没法解决所有问题,所以就干脆不用了;
GFS Architecture
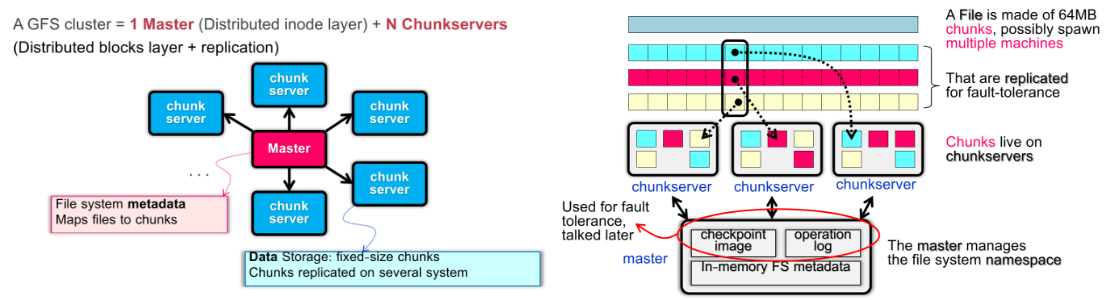
这很像我们之前尝试改进的 NFS 的做法:
一个 master 管理 chunks,map files to chunks;
chunks server 提供固定大小的数据存储空间,并且可以提供 replication & backup(异地亲和性和容灾措施);
为什么文件使用 64 MB 的 large chunks 作为文件存储基本单位?
减小网络交流频率:网络通信开销大,通过增大 chunks 牺牲一部分 utilizations 换取更少次数的请求(而且在 design assumptions 中说了 workload 的大部分文件都很大);
提升可连接的 TCP 数量上限:更小的 blocks 分散在更多的机器上,需要维持的 TCP 连接更多,实际能连接的能力就下降了;
减小 metadata 的大小,以便 master node 可以将信息存在内存中,加快访问速率;
GFS 还有更多的机制:
32-bit checksum for each chunk;
globally assigned 64-bit integer ID for chunks(by master when creation);
(scalable replicas)more replicas for popular files;
Comparison between Improved NFS & GFS
GFS 抛弃了 Inode Layer,直接将文件和 chunks 管理在 master node 中;
有助于简化设计、提升性能、简化正确性管理;
使用相当大的 chunks 来直接存放文件;
huge chunks 会做 replications 来保证 fault tolerance 和 high performance;
GFS 只使用 1 个 master node:可以保证设计简单,同时有多种方式保证安全和可用性;
"file-chunks" map 建立在 master 的内存中(用 operation log 持久化保证数据安全);
而 "chunk ID - chunk" map 可以不需要 log 放在内存中,然后在 startup 时询问 chunk servers 建立起来就行;
优势有很多:
"file-chunks" map 本身是 hotspot,这样能极大优化性能;
更简单的数据一致性的管理;
master 控制整个映射机制,确保数据最新;
GFS Interaction Model
没有 OS 级别的 API;
只有需要 meta-data 时与 master 交互,其余时候直接与 chunk server 交互,不会造成 master node 拥塞
这也是设置 1 个 master node 的原因之一;
No Cache: client/server 都是这样。这是由 design assumptions 决定的。workload 中大多数是超大文件,用到 cache 的机会很少;
Client 也可以 cache meta-data,进一步减轻 master node 的负担;
Reading a file in GFS

Writing a file in GFS
特点:
(原理复杂)more complex, because we need to deal with the consistency issue(应对两个 client 改一个文件的问题);
GFS adopts a relaxed consistency model(后面讨论 “relaxed consistency model”);
方法的实现高效简单;
设计目标:
仅保证最终一致性:Each replica eventually have the same data;
减少与 master 的交互(不然 master 就会成为瓶颈):Reduced communication with the master;
为了保证一致性、消除并发写冲突,需要在同一组 replicas 中选一个 chunk server 作为 a single primary(leader)来统一协调写操作。有两个问题:
master 如何选择一个 primary?这个 primary 不能持久,因为每台机器都有可能故障,而是定期随机地在每组 replicas 中通过给予 “a chunk lease”(租约)来选 primary,在这些 replicas 中只有这个 chunk server 才能修改 chunk(并且心跳连接);
允许允许续租机制;
更改 primary 后,master node 会通过更新(增加)chunk version 并通知 replicas 来完成。
因此写操作分为以下几个阶段:
phase 1 传输数据(Data Flow):
Client App 会得到一个要修改数据所保存的 replicas list,然后向最近的 chunk server 传输数据,并且采用 pipeline forwarding 的方法向其他 replicas list 中的 chunk server 传递;
不关心顺序、不存在写冲突,只管数据传递,解决性能、吞吐量;
注意:这种 pipeline forwarding 的效率优于从单个机器上并行传数据(由于一台机器的网络带宽上限),可以自己画图理解。
Chunk Server 在收到数据后不会保存,而是放在内存中(memory cache);
phase 2 写数据(Control Flow):
Client App 等待 replicas list 中的 chunk server 回复确认(ACK)后,再向 Primary Node 传递写请求;
Primary Node 再串行向各个剩余 replicas 中下达将刚刚 cache memory 中收到的数据修改落盘;
The primary is responsible for serialization of writes (applying then forwarding);
并且利用 master 管理的 chunk version 判断 replicas 中是否有过时数据、是否应该覆盖等等。
由 Primary Node 关心写顺序,解决写冲突、一致性问题;
当 Primary Node 获得所有 replicas 的修改确认后,再向 Client App 发送确认回复;
GFS 的写操作对 atomic append 非常友好:
Google 业务逻辑大多是日志型的数据结构:顺序写远多于随机写;
Append 写法总是能保证最终一致性(哪个行数多哪个新,不需要考虑覆盖问题),因此 GFS 的 weak consistency model 是有效的;
Naming in GFS
GFS 采用 simple flat naming,也就是不存在常见文件系统的 “目录” 结构、不存在 alias(即软硬链接)。因此 files namespace 就是一个查找表(lookup table),直接将 pathnames 映射到 file metadata(就像 KV Store);
HDFS
HDFS(Hadoop Distributed File System):一个 Apache 开源的分布式文件系统实现,受到 GFS 的启发(架构几乎一样,只是改了术语);
Summary
设计一个 Distributed File System 并不简单,没法直接用 single inode-based file system + RPC 实现;
考虑 performance、consistency model、failure handling;
学习了 NFS 和 GFS 的案例:
NFS 不是 scalable 的;
NFS 不支持 fault tolerance;
NFS 在大多数场景(局域网文件共享)下足够;
GFS 使用 relaxed consistency model 在并发写同一数据时是 undefined behavior,但是可以支持 append 的最终一致性;
GFS 使用 single-node master:好处是简化设计、加速请求(并且交换数据量少);坏处是牺牲一部分可用性。这在后续的 GFS 版本中有所改进;
GFS 是一种根据 Google workload 改良的文件系统,适用于它的 design assumptions(例如像数据库场景,就不适用);
1.6 KVStore: System with a Simpler API
Concepts
首先进行存储抽象,来定义讨论的范围:
每个数据值(Value)对于底层存储设备/数据库需要是模糊的;
The K and V can be arbitrary byte-sequence (e.g., JSON, int, string);
数据由 Key(K)索引,其本身也是一个数据;
数据需要存放在磁盘上(需要 fault tolerance、a large capacity),也可以放在内存中;
我们定义针对这种数据的存储系统为 “Key-Value Store System”(KVStore / KVS);
然后定义 KVS 的 API:
Get(K) -> V;Scan(K1,K2) -> V[](Optional);Update(K,V)、Insert(K,V)、Delete(K,V);
Design Natïve KVS
那么如何实现 KVStore 系统呢?有个 naïve 解决方案:
Key: The file name (may include the path)
Assume the key is not so long;
Value: The file content;
这样 GET 就是 OPEN + READ,INSERT 就是 CREATE + WRITE 等等,我们就可以利用类似文件系统的方法来处理 KV Store 的问题啦!
但有问题:
文件系统是为比较大的文件所设计的(例如图片、视频的 KV 存储)。对于较小较多的文件,基础的 block 大小会降低存储效率(如何快速高效存取小型数据);
并且文件系统没法有效 索引/查找 每个文件内的数据,不满足 KV Store 中的需求;
综上:
系统调用开销大(mismatched interface)的问题;
空间利用率比较低的问题;
数据索引性能问题;
Improvements I: Redesign Implementation & Pack Data
我们想出一个主意:
让一个/多个文件放多个的 kv data,让不同的 kv 打包进同一个 disk block 中;
这样缓解了上面系统调用开销大、空间膨胀等问题;
接下来,我们只需要在文件系统的基础上来设计 KV Store 系统就行了!
为什么要借鉴文件系统?
We still need a system to interact with the disk hardware
(还是要依赖于 file system)Though modern KVS may also bypass the file system, but is uncommon;
第一个目标:如何在 natïve KVS 上实现 UPDATE(K, V)?
两种策略:
直接改文件内容;
在文件后面追加更改的信息;
根据 ICS / 存储介质基本知识,顺序写远远快于随机写,因此我们选择第二种方案。
这样 INSERT 轻松完成,DELETE 可以通过插入 (K, NULL) 来完成(最后需要进行定期 GC 来避免写放大);
这种 Append-Only 的文件格式被称为 Log-structured file(an append-only sequence of records);
最终我们获得如下好处:
Suits the performance of underlying hardware(磁盘顺序写快);
Ensure consistency under failure,因为 append 写总是能保证最终一致性;
但是!我们还有最后一个 API 没考虑:GET(K)(或者 SCAN(K1, K2))。
结果因为追加更新的性质,我们需要最坏
Improvements II: In-memory / On-Disk Index For Read & Search
为了解决这个问题,我们可以借鉴数据库的 “索引” 来加速查找工作。
索引是从 primary data 中提取出的额外数据结构;
它可以添加、删除而不影响原始信息的正确性(只会影响性能);
像 B+Tree, HashTable 都可以作为索引。其实我们发现之前已经用过类似的索引结构了:文件系统中的 inode table 就是对 inode 的索引(不过太过简单);
我们可以先试一试用一个 in-memory hash map 来将 key 与 KV 数据所在 log file 的偏移量关联起来:
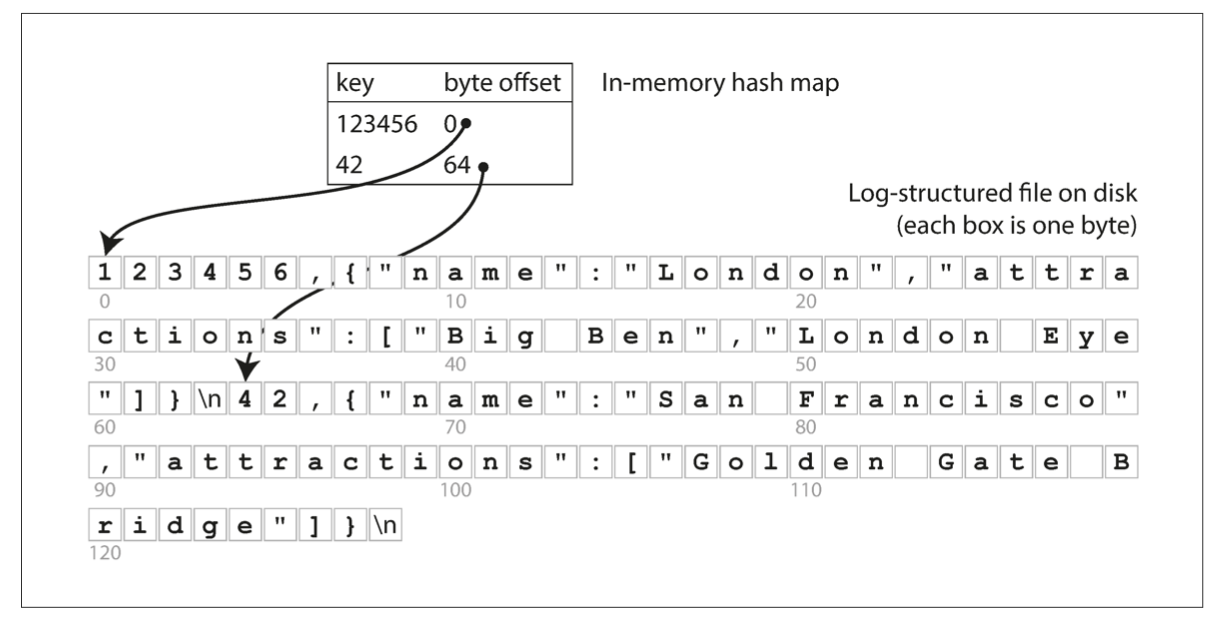
这种方法被一些商用系统采用(例如 Bitcask in riakKV);
优点:读写高性能;
局限性:INDEX 只在 RAM 中。而 RAM 大小有限,太多的插入操作(新建 key)会导致 INDEX 在内存中溢出;因此它仅仅在一些 workload 中适用:
适用场景:when workloads have many updates but not insertions;
因此,我们需要把 index 周期性搬到磁盘上。那么这个时候需要好好选择数据结构了,主要因为:
虽然有很多 hash 数据结构,但它们的性能在磁盘上的表现差异更为突出(这在内存上很难看出来);
有些 hash 数据结构天生适用于在磁盘(例如利用了磁盘的存储特性),但有些 hash 数据结构从内存移到磁盘上放反而会降低它的效率;
总之,我们需要基于某类 hash 数据结构作出针对磁盘存储介质的优化。
我们看看哪些数据结构符合我们的要求:
Linked-list based hash index:最简单的基于 hash table 的索引数据结构;
优点:易于实现;
缺点:hash collision 时,读写性能都有较大影响(尤其是并发时需要锁一个 bucket);
Cuckoo Hashing:高级数据结构中介绍的一种 Data Structure;
优点:读性能很好,最多两次随机 I/O;
缺点:插入比较耗时,可能需要多个 random disk I/O;并且插入较多时需要 rehashing(相当耗时,但不做的话可能死循环);
我们发现选取这样满足条件的数据结构并不是一件简单的事,需要考虑很多问题,做些 trade-off:
Read performance vs. update performance(而且在 update 时需要对 index 进行插入/删除);
这种 index data structure 的访问模式是否对存储设备友好(随机读写/顺序读写)?
其他问题:如存储效率、存储开销问题;
Improvements III: Alleviate Write Amplification
事实上目前除了前面提到的问题,还有一个问题是,KVS 中的 Log file 会不断增长,总有一天会超过磁盘容量。
除了分出多个 log files 以外,我们还想到之前设计实现 API 的时候,写和删除会出现多个重复、没用的 entries,因此我们的思路是:
Compaction with segmentation + Merge:
将文件再分成多个 segmentation(方便 compaction 快速进行);
一个 segmentation 满了后分裂新文件;
可以通过控制 segmentation 的大小来控制 compaction 的粒度;
Compact 时,在 segmentations 中移除多余重复的 records(称为 GC,可以通过标记时间戳);
Compact 导致 segmentations 缩小后,可以通过 merge 把两个 segmentations 合并起来,适当减小 segmentations 数量;
Improvements IV: Large Range Query Supports
我们可以使用 B+ Tree(或者用 B Tree)来存放 Key & Log File,以起到 Range Query 的作用。
这种数据结构针对磁盘进行了优化:
每个结点是固定大小的,可以存放多个有序键;
所有叶子结点都位于树的底层;
支持高效的顺序扫描、对于大规模数据读写有优势;
所以我们需要用 B+ Tree 来索引日志吗?不需要!如果我们用的话,应该直接把日志内容放在叶结点上。因为如果叶结点还要索引的话又会引入 merge & compaction,平白无故地多出了一次 disk random access;
综上,B/B+ Tree 对于存储 KVS 方面:
GET / INSERT / UPDATE相对较慢(对于插入频繁的 workload,需要很多的 random disk I/O 操作,开销比较大;
在综合考虑上面的几个问题后:
顺序写远快于随机写:使用 Log File Append-Only;
为了防止 Log File 过大:Log File 需要 Compaction with segmentation + Merge;
没有解决 Range Query、
GET效率不高的问题;
我们打算使用 SSTable(String Sorted Table)来索引 Log File 的方法来做 KV Store System:
使用固定大小的 segments 来存储键,每个 segment 间维护有序性,以及值位于 Log File 的位置信息;
一旦一个 segment 被填满,就新建一个文件;
这么做有一些好处:
二分查找,在一个 segment 中查找的效率相当高;
在 segment 中支持范围查找;
甚至合并两个 SSTable segment 都是高效的(相当于两个有序的数组 merge);
我们还可以作出一些优化:
应对快速的读写请求,可以留存一个不超过最大阈值大小的 in-memory table(
MemTable,可用红黑树/跳表等等)。先在内存中进行增删改查,直到
MemTable满了后再作为一个 SSTable 的 segment 生成一个新文件。内存中的 fault tolerance、data consistency 可以通过 Write Ahead Log 来确保;
SSTable segments 过多时,由于多个文件间需要扫描有序性,查找比较旧的值变慢、de-duplication 变慢、范围查找仍然不高效;
所以我们可以将 SSTable 以树形结构组织起来;
最终还要考虑:
Write Stall 的问题(多线程写?多个 MemTable 轮转使用?层级更高用更好的存储设备?),但都只能缓解;
对不存在数据查找很慢(一直找完所有 SSTable。引入 Bloom Filter?);
1.7 Consistency Model
1.7.1 Intro
假设我们正在建构一个 Chat App,消息结构如下:
一个 Chat(CID 标识)中包含多个 Sentences(SID 标识);
我们想部署一个 KV Store System 来存储消息,想了一种方法:将 KVS 放在中心化的服务器中;
不过这么做有问题:
不高效。每步动作都需要服务器确认;
一旦离线就无法得到消息;
那么改进一下:在中心化 KVS server 的基础上,每个端侧设备有一个 KVS 做数据备份;
这样就有一个 Naïve solution:
读数据:从本地 KVS 读最新的备份;
写数据:在更新本地 KVS 的同时同步其他的 KVS,最终 client 返回;
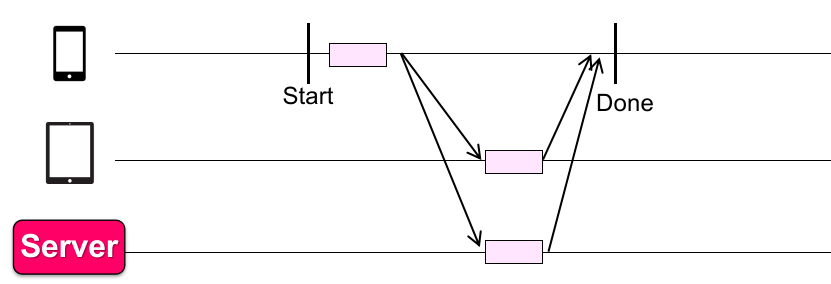
还是有两个问题:
写数据时同步不高效 :每次写都要等,而设备间 RTT 通常 100-400 ms;
没法应对网络断连的问题(可靠性问题):发送方可能会被阻塞;
Fix 为 Naïve solution++(这就是 WeChat 应用使用的):
写数据:立即更新本地 KVS,然后直接返回,同时在后台向其他 KVS 发起同步请求;
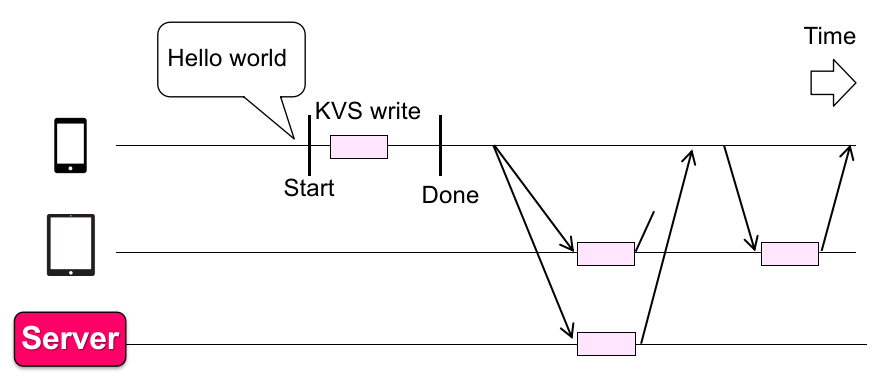
但是这里存在一些 consistency issue(unexpected behavior):
数据有丢失(但是已经返回,Missing an update);
顺序有问题(Order Mismatch),不能保证两次同步的数据谁先到达;
所以在网络上,对 KVS 的操作请求可能没法及时同步其他设备看到的信息,从而导致数据不一致性。因此我们需要建立一套 Consistency Model。
1.7.2 Definitions
Consistency Model 描述了一个数据存储系统在并发 / 分布式 / 出现错误(failure)时的应对行为;
例如,in GFS, the consistency model is that all the chunk will eventually be the same(最终一致性);
而一个 Strong Consistency Model:可以精确的保证哪些事会发生、哪些事不会发生,不会出现 unexpected behavior;
这是一个 Weak Consistency Model 所没法达到的。所以下面我们先考虑 Strong Consistency Model;
注意,没有正不正确的说法总是在:是否容易实现、效率高低、数据一致性之间做 trade-off;
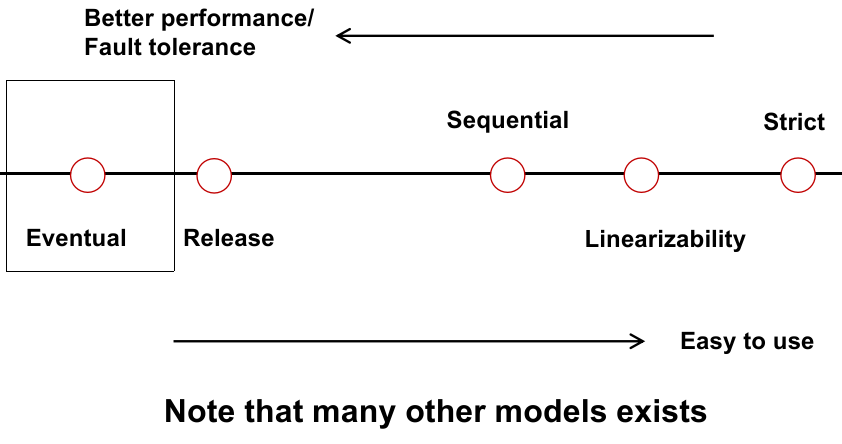
一个 Consistency Model 的光谱如下:
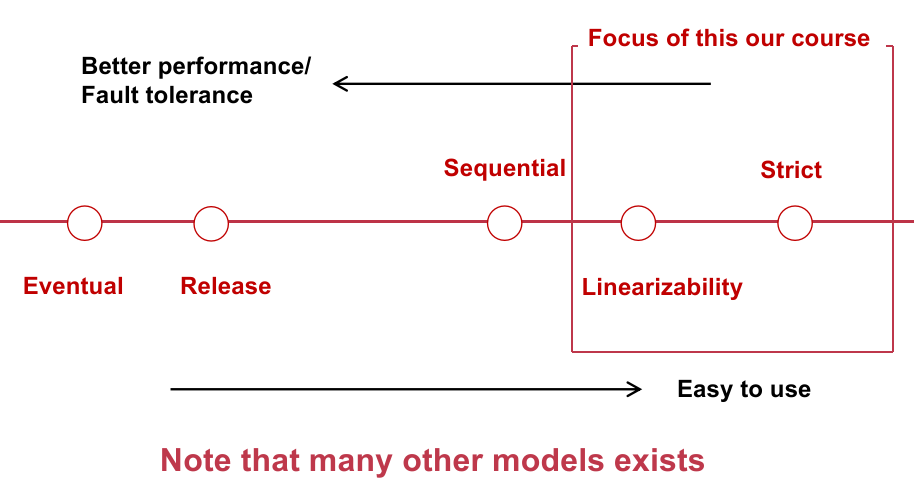
我们本章关注的是可线性化、严格的 Consistency。
那么直观上什么是 Strong Consistency Model 呢?
Everything has only one-copy;
The concurrent read/write behavior is equivalent to some serial behavior;
The overall behavior can be viewed as a system that never fails(后面讨论);
而一个正确的 strong consistency model,需要对一连串的并发请求,deduce 出一个正确的 serial behavior,就像数据库的并发调度。
从这个 deduce/调度策略,我们可以区分出 3 种比较强的 consistency model:
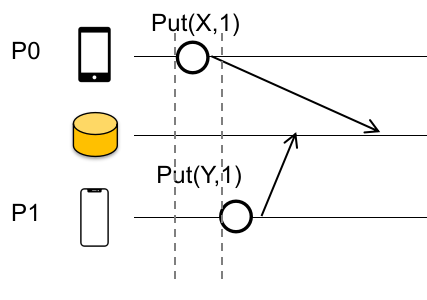
Strict Consistency
Strict Consistency:需要根据 global issuing order(global wall clock time)来决定这个 serial behavior!
优点:
单次值操作所能达到的最强的一致性模型;
所有并发操作都等价于一个正确的单线程串行操作;
缺点:
在分布式系统环境中几乎不可能正确实现;
出于性能和正确性的考虑:
很难高效、100% 正确地维持一个所谓的 “global wall clock time”;
而存在误差的 “global wall clock time” 会导致并发操作没法真正的等价为 100% 正确的串行操作;
很可能落得花了很大力气,最终却做错的下场。
网络环境永远不可靠:即永远无法确定一条指令之前是否有 global issuing order 在此之前需要被执行的(究竟等多久?);
如下图:
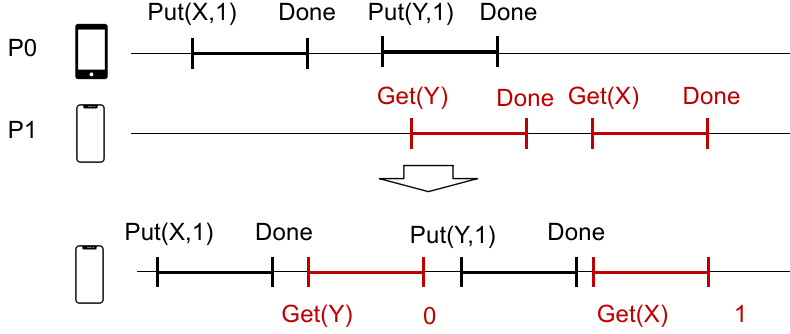
Sequential Consistency
Sequential Consistency:只有每个终端处理的一系列事务需要有序,Per-process issuing/completion order;
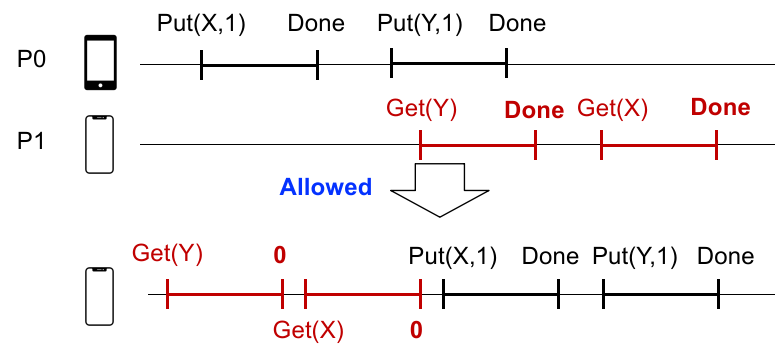
也就是说,只需要一个物理结点上的连续发生的事务间保持顺序就行。
优点:效率高;
主要缺点:Missing Update(Write Done but read old data)。像上面的例子,实际物理时间 GET(X) 在 PUT(X) 结束后,但是没法获得修改完成后的信息,因为分布式系统使用的是 sequential consistency,上述真实物理时间排布会最终同步成下面的线序。
Linearizability
Linearizability:除了保证每个终端处理的一系列事务需要有序,还要保证 Done-to-Issuing Order;
也就是说,所有的 done event 和 issuing event 的时间需要确保顺序。如下图:
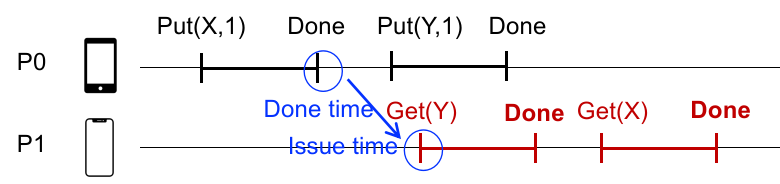
蓝色标注说明,在使用 Linearizability Consistency 的分布式系统中,串行化时会考虑到 所有操作的 done time 和 issue time 在真实物理时钟下的先后关系,确保最终 Put(X, 1) 在 Get(Y) 操作之前完成。这种程度的同步会比 Sequential 的更严格,但比 strict consistency 轻松。
例如上面的例子我们就能发现,如果使用 Linearizability,那么 GET(X) 能获得 PUT(X) 的最新值,缓解了 Sequential Consistency 的 Missing Updates 的问题;
另外,可以反证法证明:
If each object’s op is linearizable, then overall system is linearizable.
综上,真实应用中总是倾向于 Linearizability;
1.7.3 Implementation of Linearizability
如何实现 Linearizability?
第一种方法:Primary-backup approach,即:对每个对象,Clients 都会向某个指定的结点发送读/写的请求;
对读:返回本地关于 primary(M0)数据的缓存;
对写,在保证先后写有序(in-order)的同时:
M0向所有 replicas 发送写数据指令;完成后,
M0在本地执行写指令;Respond OK;
如下图:
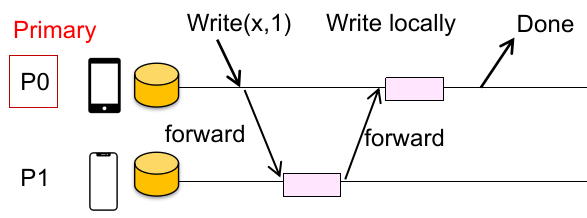
注:“in-order” 是指,两次写操作的顺序不会因为先后到达 node 而受到影响。
如何实现?有序性这个点不必要用 global wall time,使用 sequence number 给每个写操作计数就行(确保不会因为一些原因导致到达两个物理结点的写的信号不同)。
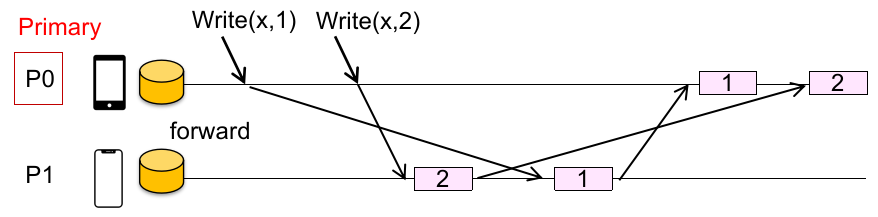
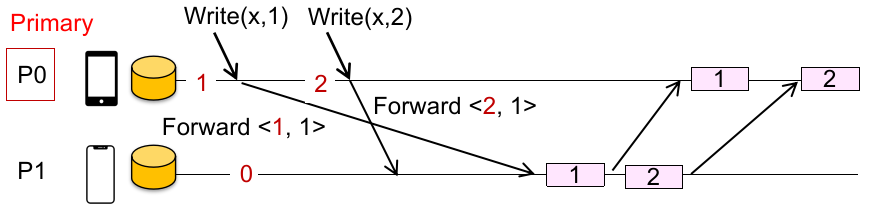
但有很严重的性能问题:
读请求:每个 client 都要承受联系 primary node 带来的额外 RTT(Real Time Transform)开销;
写请求:每个 client 都要承受联系 primary node,以及写多个 replica backups 造成的 RTT 开销;
可扩展性问题:随着 client 数量增大,primary node 就会成为性能瓶颈;
此外还有可靠性(可用性)问题:primary 具有脆弱性,一旦某块数据对应的 replicas 中,primary 挂了,系统应该如何应对?
我们先看 performance 问题。能不能读一个随机的 replica 中的数据(不总是读 primary machine),就像 GFS Read 一样?
不行,因为这存在一个 linearizable 的问题。如果尝试读一个不是 primary node 的结点,可能会读到系统的中间值,出现数据不一致性。例如下面的场景:
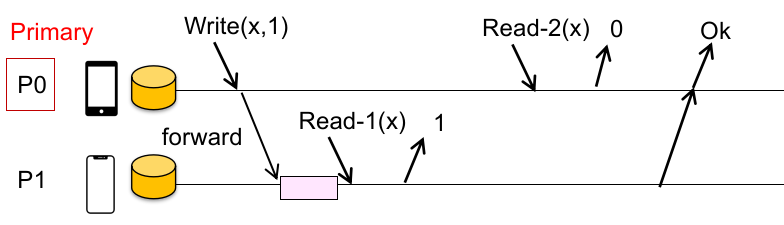
所以,为了防止 primary 成为性能瓶颈(fallback 到中心化 KVS 系统的性能),我们定义了 partition:
将所有数据对象存储在 KVS 时分为不同的 partition,不同的 partition 可以有不同的 primary,这样可以分散掉读写的请求;
Different objects have different primaries ,如下图:
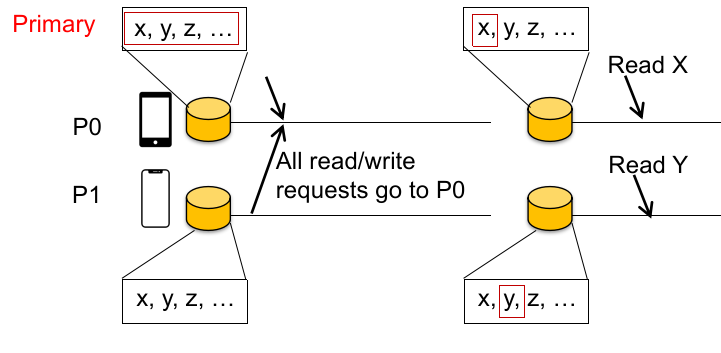
现在落到实处思考一下:
这种 Primary-backup model 实现 Linearizability 的方式对于一般 Mobile Chat Application 来说,显然是不合适的:
(性能缺陷)发送一个消息,就要等待所有设备都同步?
(在保证性能的情况下很难保证 fault tolerance)如果某个设备的状态是离线的,难道服务就不可用了吗?
所以,对于分布式 Chat Application 而言,数据不一致性时时刻刻都可能存在,只不过是一致性的要求、同步的方式随着业务逻辑调整,更加灵活。因此我们需要了解一种对一致性要求更宽松的一致性模型,它在上面这种 Mobile Chat App 的情况下更为适用。
1.8 Eventual Consistency
最终一致性模型是一个相当宽松的数据一致性模型之一,其地位如下图所示:
1.8.1 Definitions
这种应用场景下,我们更关心性能、fault tolerance,而不是 consistency。这是一种 weak consistency model,只要:
所有服务器最终会(不保证实时性)接收到并同步所有写操作,对某组数据的内容是一致的;
即:当一个数据不再更新后,最终所有对这个数据的请求都只返回上一次更新的值;
这样我们可以如此定义实现最终一致性:
Read(和 Linearizability 的实现方法不一样!这样的结果可能不是 linearizable 的): return the latest local copies of the data;
Write:在本地写,然后直接返回在后台逐步传播这个更新的数据(不要求后台一定请求同步更新,所以是 propagate);
但是,对于 “如何实现最终一致性” 的相同问题,在不同的实际场景下的回答(解决方案)是不一样的。
对 GFS(data center):传播数据的方法是,选出 primary 来写所有份的数据(回想:data flow + control flow)。这不适合像 mobile app 的场景;
对 mobile chat app:传播数据的方法是,直接向离 client 最近的 server 写数据:
在这个 server 确认后,就没有 client 的责任了,这个 server 可以之后将这个 update 传播到其他的 server 中;
这个 “最近的 server” 可以和 client 位于同一个物理节点上(co-locate);
考虑这种对 mobile chat app 的方案是否有问题?
是的,会出现 write-write conflict: 也就是说不同的 client 可能同时(concurrently)向最近的 server replica 更新同一个数据,而相互不知晓。
这样在数据传播后,最终会导致 data diverges,也就是出现同一时刻的两个数据版本(在一个 server 上先 X 再 Y,而另一个 server 上相反),永远没法达成最终一致性,如下图:
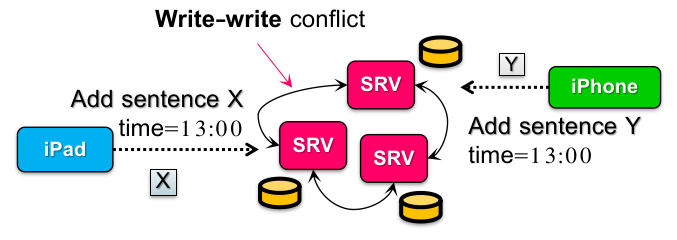
回想我们在 Linearizability 中的解决方案,它采取 “pessimistic conflict handling”(类似悲观锁),认为冲突是常见的,除非交给 primary node 的请求是 serialized,否则不应该生效(也就是说,先到 primary 的请求先生效)。
而在 eventual consistency 中采取 “optimistic conflict handling”(类似乐观锁),认为写冲突不常见(所以不设置 primary,每个结点自己都可以写),但希望修改最终会 propagate 到所有的设备中。
也就是说,选择 linearizability 和 eventual consistency,实质上是在 consistency 和 performance 间做 trade-off:
是否允许在确定能够串行化前就写一个值(以后在传播的过程中确定操作顺序);
是否接受在更新后可能读到一个旧值,并且没有绝对的全局顺序;
这个 “没有顺序” 是有要求的,也就是不能丢失因果性,参见下文。
所以,在不丢失因果性的前提下,最终一致性不会保证绝对的全局操作顺序,也就是微信上常常见到的两人同时发消息顺序可能双方看起来不一样。
但是说到底,eventual consistency 还是需要 cope with anomalies:
Write-write conflict:最终一致性模型需要 converging state(例如在上面的例子中,合并不同结点间的不同状态);
Loss of causality:最终一致性模型需要 causality preserving(保持因果一致,同一个前后依赖的事务间的顺序需要保持);
1.8.2 Converging State: Update ID & Write Ahead Log
先看如何合并不同结点间的不同状态(解决 write-write conflict)。我们可以像 git 处理冲突一样,只有必要才解决冲突,否则 auto-merge。也就是在传播途中:
在一次本地写操作后,适时(例如放入任务队列)在后台向其他 server 发送写请求;
每个收到传播请求的 server 需要在更新本地数据的同时,尽可能解决冲突;
例如,对于两个 client 向两个 KVS 中同时用 PUT 的方法更新一个数据记录 chat[cid] = [...chat[cid], new_sid];
这样如果不加处理,可能会出现数据丢失(因为 PUT API 的语义,最终只有一方的修改存在);
于是解决方案是引入 “Append Update” 的语义:chat[cid].append(sid),这样保证数据不会丢失。
丢失问题解决了,那么合并顺序呢?我们需要两个 KVS 所在的 server 对全局的顺序达成一致共识。如果一开始都更改 KVS,那么最后肯定分不清了(没有排序依据了)。
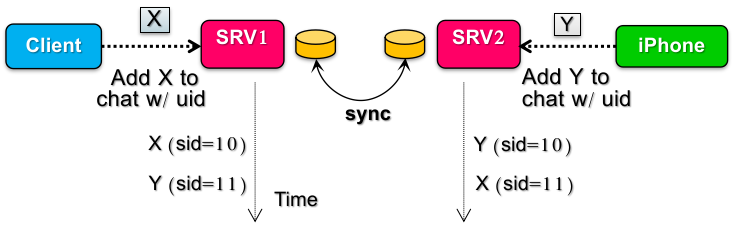
所以我们应该使用 Write Ahead Log,为操作打上时间戳(先不考虑两个 server 的 timestamp 不一致的问题)。如果不巧时间戳也相同呢?那么可以使用 server node ID 来决定,也就是 update ID 组:<time T, node ID>,这样一定能区分两个操作的先后(因为 timestamp 在 server 上不同的问题,不保证绝对全局顺序)。
注:肯定不能反过来
<node ID, time T>(先判断 Node ID 再判断时间),这样 “某些 node 的更新操作总是在另一些 node 之前” 的现象会很明显。
但是,还有一个问题,为了尽可能确保状态成功合并,应该先 merge(achieve state convergence),再将写的数据 update 到 KVS(如果先 update 的话,不同的 server 原始数据就不同了,更没法合并了)。但是如果先等 merge 完成再 update,会导致更新延迟,用户无法在提交后立即看见,这是在 mobile app 中不可容忍的。
我们再想一种解决方案,是否可以先 update,再处理 merge?
答案是,可以。我们从单机中的数据库事务处理策略中获取灵感,可以采用回滚(rollback/undo)和重做(replay/redo)来管理不恰当的 update,让状态在后续过程中合并、再次修正并达到一致:
当本地写操作发生时,立即 update 到 local KVS 中;
当接收到其他 server 的传播请求时,如果发现没有冲突,KVS 直接写;如果发生冲突(例如收到的 timestamp 小于当前本地最新的 timestamp),KVS 就通过 WAL resolve 出最终的合并的顺序,然后 rollback 到 empty state(指 sync 前的某次一致的状态),并且根据最终的 update 顺序 replay 一次,得到正确的数据;
如果直接 rollback 到 empty state,会出现两个问题:
sync 时间可能很长,影响性能;
日志文件可能很大,影响存储效率;
我们在本章最后讨论。
1.8.3 Causality Preserving: Lamport Clock & Vector Clock
好。现在假设我们通过上面的方法解决了 write-write conflict 的问题,那么 loss of causality 呢?
我们回想之前的做法,我们使用 <time T, node ID> 作为操作时间戳,但是两个 server 的 timestamp 是不同步的。
就像我们之前说的,这的确不影响 write-write conflict 的解决(sort & converging state),但是它会影响用户体验的因果性(loss of causality),例如:
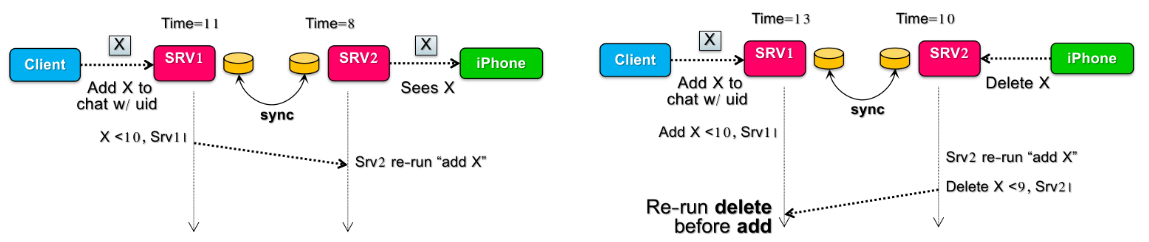
假设在全局时钟(global wall time,应用并不知道)下,client 对 SRV-1 写了 X(其中 SRV-1 产生的时间戳为 10),而在此后的很短一段时间内,SRV-1 和 SRV-2 间传播了一次数据(sync),SRV2 没有冲突立即写入 KVS 并在 WAL 中记录;
但是在这之后又是很短的一段时间内,iPhone 向 SRV-2 删除了 X,这个时候由于 SRV-2 和 SRV-1 时间戳不同步,SRV-2 此时才生成时间戳 9,并写入 KVS;如果这个时候,SRV-2 又向 SRV-1 传播一次数据(sync),那么 SRV-1 看见时间戳 9,会以为 Delete 事件发生在写入 X 前,在 resolve conflict & replay 时会导致 delete 在 add 前操作,X 实际并没有在 SRV-1 上删除,因此 SRV-1 和 SRV-2 数据又一次不同步了。
这就说明没有 preserve causality(没有保证前后依赖的事务的因果顺序)。为了解决这个问题,我们就需要指定好事件间的因果。
或者说,我们需要 clock 真实地反映因果(Clock should reflect the causal order)。但是不同机器时钟是不同步的!怎么办?那么就不用不准确的绝对时钟了。
人们想出了 “逻辑时钟”(相当于事件驱动时钟),这就是著名的 Lamport clock;思路如下:
每个 server 维护一个时钟值
T;当 server 时钟嘀嗒一下,
T进行自增;当 server 感知到其他 server 传播信息中的时间戳
T'后,再次更新T = max(T, T' + 1)这保证了已发生的事件
T'标记始终小于接下来要发生的事件T标记;
注意比较 tricky 的一点:同步后的两个有因果事件的 Lamport clock 值才有明显可比性。因为它展示的是 global order,例如:
当
事件在机器上发生后,同步到另一台机器发生 ,那这个时候保证 ; 但是从
没法推出下列的情况:
是否经过一次数据传播(各机器 timestamp 并不准确和同步);
的 global wall time 的关系;
事件导致机器向 所在机器 sync 时, 仍然不一定在 的 global wall time 前发生。因为并没有阐述 的因果关系;
现在,我们使用 <Logical Time, Node ID> 作为 Update ID,就既能解决 write-write conflict 的顺序问题,又能解决 loss of causality 的问题了!
但是很不幸,这样还有一个问题:这种测定方法过强了(对于已经沟通的两个 servers 来说,事件关系要么前要么后)。如果我需要做两件不相干的事,它们实际上可以(或者需要)在同一时间进行,也就是需要 incomparable timestamps!
在离散数学上说,就是我们不一定需要强的线序关系,而是需要偏序关系(partial order)!
这个时候,人们基于 Lamport clock,设计出了 vector clock。思路如下:
我们根据不相干事务数量
这样我们就可以比较多种不相干事务间的先后关系,在某些应用场景中比较有效。
总而言之,大部分场景下 sort & converging state + Lamport clock 已经能实现 eventual consistency 并解决大部分问题了,少部分场景下还要借助 vector clock;
1.8.4 Truncate WAL
最终还有一个问题:我们在 sort & converging state 中在本地写了 Write Ahead Log(WAL)。它不仅可以决定 merge order,还可以让我们在发生 write-write conflict 时进行 sync replay,但这并不高效。因此我们需要从两个方面下手:
尽量不要全部回到 empty state 并重做所有的 update(只做部分 replay);
减小 Log 文件大小;
先来看如何只做一部分的 update。
我们把那些不确定后面会不会有数据传播造成顺序重写(例如分布式网络中存在正在传播中的、在此之前的更改操作)的数据写操作称为 “tentative writes”(unstable writes),这些写操作可能在后续的传播同步的过程中出现 write-write conflict 需要 replay;
确定不会有其他传播对这个数据造成影响的写称为 “stable writes”;
于是整个 WAL 中由上下两部分构成:stable writes 和 tentative writes。借鉴了单机数据库的事务日志(redo/undo log),这里也相当于有个 checkpoint 的概念,不过是用 stable 和 tentative 来区分的。
在发现 write-write conflict 需要 replay 时,server 可以按照 WAL 回滚到 tentative 记录之前,不需要回滚 stable writes 的部分,初步提升了回滚效率。
那么我们如何判断一个写操作是 stable 的还是 tentative 的呢?
方法 1(de-centralized approach)是利用 Lamport clock:
一个 UPDATE 操作是 stable write 当且仅当 目前没有任何一个 entry 的 Lamport clock 值比它更小;
举一个例子:对 UPDATE <10, A> 操作,如果分布式系统中所有的 nodes 都发现了不少于 10 的 UPDATE 操作,那么这个操作就是 stable write;
但是显而易见,这种方法有个缺陷,就是分布式集群中有任意一个 node 掉线了,那么就无法继续判断 stable write 了,仍然会有很多 tentative writes 需要在 conflicts 时回滚。
方法 2(centralized approach)是借助 primary node:
设定一个 server 作为 primary,它不作为专门写数据的结点,而是专门生产一个特殊信息的结点:
当最后一个针对某个数据的写操作向 primary 请求后,primary 会生成一个标记
CSN(Commit-Seq-No,已提交流水号),并将修改后的信息<CSN, LocalTS, SrvID>广播(broadcast)出去,可以理解为终结了一组有 causality 关联的 writes(相当于分布式事务的 commit);所有收到
CSN的 server 在此之前的所有 write 都会被视为 stable writes;CSN本身可以在各个 server 间传递,但只由 primary 产生;
这样,只要 primary node 是存活的,分布式系统就能一直判断 stable writes;
还有一个问题,向 primary 申请 CSN 的 server 可能 Local Timestamp 并不是当前最小的(CSN),应该怎么办?
这比较简单:我们可以让一个机器向 primary 申请 CSN 时,带着前面所有依赖的(因事件)一起申请 CSN,这样一定能保证 CSN 也能反映 Causality;
考虑这个问题:两个没有因果关系的事件在传递时,由于没有互相通信,因此 CSN,primary 同步到剩余结点时就会出现顺序调换的现象:
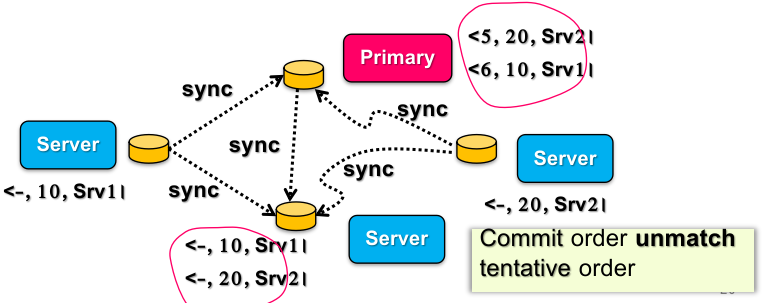
不过因为没有改变 causality(主要是 Srv1 和 Srv2 无关),并且发生的次数不多,不影响总体用户体验,因此也是满足 eventual consistency 的。
1.8.5 Conclusion
总而言之,Eventual Consistency 的 Anomalies 到底是否重要(发生的频率和相关的后果),取决于应用的场景。
对于一个 Mobile Chat App 而言,可能 Eventual Consistency 就足够了,但对于银行系统甚至 Linearizability 可能都不足够。
1.9 Consistency Under Single-Machine Faults: All-or-Nothing
回忆 strong consistency model 的定义:
每个数据对象都只有一份;
并发读写行为和串行的行为是一致的;
系统整体的行为相当于这个系统从来没有 fails(系统的 fails 对用户无感);
我们前面几节想要尽量通过保证第二条来实现较强的一致性。现在我们考虑第三条,如果系统出现 fails,分布式系统应该如何处理才不至于直接崩溃?
1.9.1 Shadow Copy for Atomicity
首先,我们要确保某一类操作要么不做,要么全部做完(all-or-nothing atomicity),例如对文件 / 数据库的写操作。
注:在数据库领域,all-or-nothing 就被称为 atomicity(原子性);
我们在学习单机数据库事务执行时讨论过这个原子性,那么在分布式系统中,如何实现 all-or-nothing 呢?
同样,仿照之前的做法,我们首先想到 shadow copy:
先把要修改的文件 / 数据库 copy 一份,操作时直接在上面修改;等到修改完成 + fsync 后,再将 copy rename 到使用的文件 / 数据库上。这样无论在操作的哪个步骤故障,总不会出现事情做到一半的情况(最多出现多出一个有问题的 shadow copy,这个在下次恢复时清除即可)。
在单机数据库的事务保证时,shadow copy 就是一种 No-STEAL/FORCE 性质的算法。
但是这种方法执行效率低,没法支持事务的大规模并发。为什么?我们后面讨论。
好,shadow copy 把 atomicity 的问题交给了 file system;
我们分析 file system 的 RENAME 究竟有几步、出错的可能性。rename(temp, final)最简单的情况是,rename 的两个文件在同一目录下:
directory data block 中,
finalinode number 改为temp的 inode number;finalinode 中的refcnt减 1;tempinode 中的refcnt加 1;在 directory data block 中移除
temp的 inode number 和名称映射;原先
temp、现在final的 inode 的refcnt减 1;
如何保证上述步骤执行的没问题?我们在 OS file system 中先想到的是 “journal”(相当于逻辑日志);
但是问题是所有操作都要重复到磁盘上写两次(尤其是文件比较大的时候,这种方法不可取)。如果解决这个问题?
首先观察:
不是文件系统上的所有东西都一样重要;
通常情况下,文件的 metadata 更为重要(例如 inode 结点所在的 blocks 需要关注);
因此作出缓解问题的方案:在 journaling 中只保护重要的 metadata。这样真正的数据只会被写一次;
但如果 data 也很重要呢?具体的 workout:
EXT4 文件系统提供了几种 journal 的选项:
data=journal/ordered/writeback;操作这些数据的应用程序也需要自己关注这个问题,例如等待
fsync同步刷盘后再继续处理接下来的任务;
那么写 journal 本身的时候挂了呢?
硬盘厂商本身会提供一定的能源供应最后一个 sector 完整写完;
例如内置的小电容可以维持几毫秒的 disk 能量供应;
这建立在 “写一个 sector花费的时间很短” 的假设上。
当然,如果写还没开始,那就更不用担心了,因为 nothing 也是符合 all-or-nothing 的策略的。
好,那如果仅仅 journal 的大小仍然超过一个 sector 大小呢?那么我们就需要更 generalized 的方案了(我们后面讨论)。
上面讨论,如果使用 shadow copy 会导致并发性问题。如果两个 client 同时对一个资源进行修改,这个时候 shadow copy 需要确保第二个 client 不要基于原来的数据直接创建新的文件(因为可能出现覆盖的问题)。但是如果共享一个新文件,那么其中一个 client 写完后 fsync 可能会把另一个的 intermediate 脏数据刷盘,在断点时会造成数据不一致。
因此还要保证只要有一个 client 在写,就暂时不要写回,以免出现数据不一致的现象。
所以我们需要:
同一时间只能进行一个操作;因为正常地执行并发操作会出现一致性问题,哪怕这些操作原理上可以一起执行;
很难同时合并处理多个文件、目录,特别是多个 client 需要进行多个 subdirs 的重命名操作;
哪怕发生了很小的更改也需要 shadow copy 整个文件;
这在客观上就限制了 shadow copy 操作的并发性。
如何改进 shadow copy?我们借鉴单机数据库的事务处理方案:Logging;
1.9.2 Logging for Atomicity
我们引入 undo log 和 redo log、checkpoints 来实现单机上的 all-or-nothing atomicity;
STEAL + NO-FORCE:基于 redo/undo log 的恢复算法;
在故障恢复时,需要:
反向扫描 undo log、正向扫描 redo log,出现没有闭合的
<T start>则判定为未完成事务、反之是已完成事务;重做阶段:在正向扫描 redo log 后按序将已完成(标注重做)的部分再次执行(重放历史)、未完成部分插入
<T abort>;撤销阶段:在反向扫描 undo log 后将未完成(标注回滚)的部分撤销执行,并插入
<T abort>。补偿日志机制:为了防止在恢复过程中再次崩溃而不知晓恢复的进度,人们设立 “补偿日志”,每次执行 undo 日志记录后,数据库需要向日志中写入一条补偿日志记录(compensation log record,CLR),记录撤销的动作,也就是实现了 undo 日志的 redo,记录已经 undo 的日志,保证 undo 不被重复执行;
检查点机制:数据库的日志会随着事务的执行不断变长,这会使恢复时间也相应地变长,需要压缩日志大小来降低恢复的时间。人们因此设计了一种检查点(checkpoint)机制,检查点定义了一个脏页刷盘的时刻,要求检查点之前的日志记录对应的缓冲区数据页面修改已经刷新到磁盘。这样:
在检查点之前完成(commit/abort)的事务不需要处理;
在检查点之后 commit/abort 的事务需要重做;
所有未完成的事务(不含commit/abort)需要回滚;
这同时也回答了之前 file system 中 journal sector 大小不足的问题。这个 generalized 的方案就是用专门的 logging file 来存储多出来的数据。
注意,在 OS 中,我们将 undo-log 和 redo-log 结合起来,一个 entry 包含:
Transaction ID;
Operation ID;
Pointer to previous record in this transaction;
之所以需要当前 transaction 的前一个记录的指针,是因为在 OS 中存在调度问题,可能在一个 transaction 中途调度到其他线程,因此需要连接前一记录的指针。
Value (file name, offset, old & new value);
…
然后恢复过程也有变化:
从后向前扫描,标记所有不闭合的事务(没有 COMMIT/ABORT),并且:
同时 undo 所有 Checkpoint 后 ABORT 的完整事务,以及不闭合的事务;
然后从前到后 redo 所有 Checkpoint 后 COMMIT 的事务(如果有部分在 Checkpoint 前,则该部分可以不做);
为什么 redo 在 undo 之后?因为 undo 可能会擦除 redo 的修改,即一个未提交的事务把另一个提交的事务回滚了。
为什么 undo 要从 end to start?因为后续的事务可能会依赖于前序的事务;
checkpoints 标记的方法:
native:直接 run 一遍 recovery process(非常慢);
观察:
对 redo log,事务的脏数据都在 page cache 上,因此我们需要 flush page cache 到磁盘上才能清空当前 redo log;
对 undo log,但是我们需要等待所有 transactions 全部结束,才能清空当前 undo log;
所以优化后的方法(basic approach):
等待所有事务全部完成;
刷新 page cache;
丢弃所有的 redo & undo log;
但这种方案是有问题的:如果一个事务进行的时间很长,怎么办?因为有些应用场景下一个事务可能需要执行 1~2 hours。
我们能接受在有正在执行事务的情况下,进行 checkpoint 标记吗?
现在改进一下 basic approach:
定义一个 action(粒度细于 transaction,例如转账事务中一个 action 就是 deposit),然后:
等待所有的 action 全部完成;
向 log 中写入
CKPT(checkpoint)记录;Contains a list of all transaction in process and their logs;
flush page cache;
丢弃所有除了 checkpoint 记录的其他记录;
这样含有 checkpoints 的恢复情况如下:
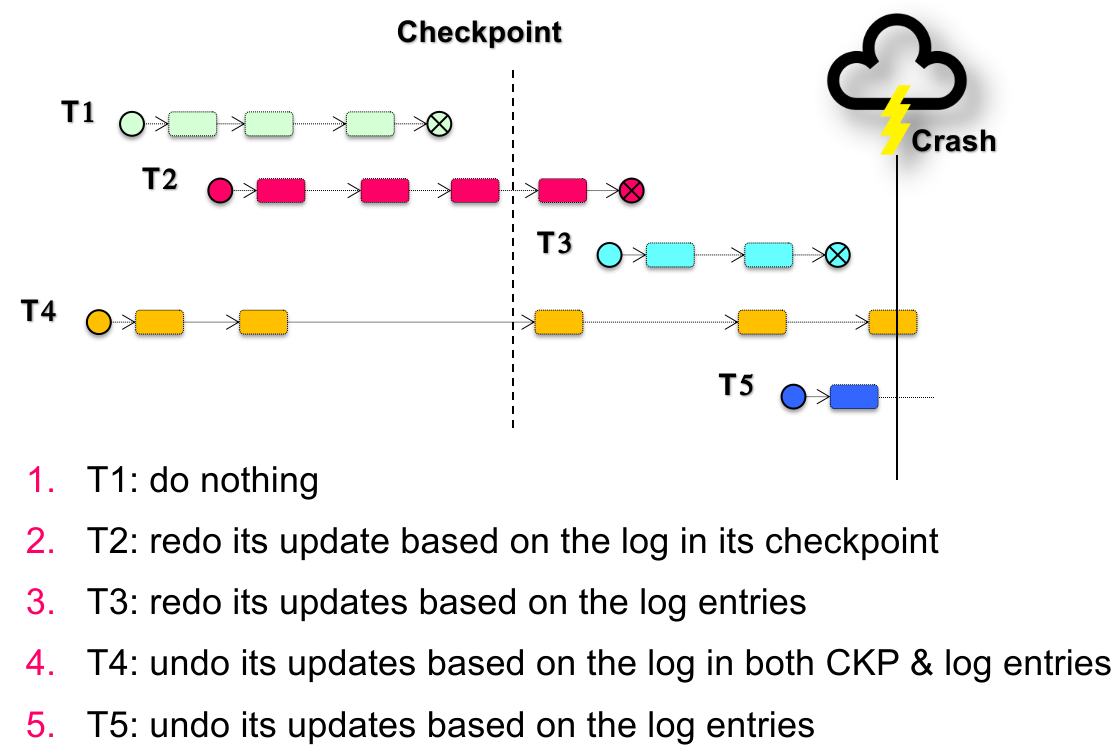
注意:
每个 action 都会让日志落盘;
在 Checkpoint 前,无论是否是脏页,肯定刷盘;
在 Checkpoint 后、Crash 前的 action,因为是 STEAL 策略,因此可能已经刷盘(state modification),需要 undo 这部分以防万一。就像数据库的 STEAL + FORCE/NO-FORCE 策略;
1.9.3 Conclusion
对比 redo(only)-logging 和 redo-undo logging,redo-only 的优势:
相比 undo-redo logging,前者有更少的磁盘操作;
仅需要从前到后扫描一次日志文件;
实际:除了那些在内存中状态很大的事务,Redo-Only Logging 都是首选(NO-STEAL + NO-FORCE);
我们发现,高并发数据库其实会存在很多 “内存中状态很大” 的事务,它如果使用 redo-only logging,那么内存缓冲区小的弊端就会显现,因此像 MySQL 数据库就用 redo-undo logging。
而操作系统和其他需要保证 all-or-nothing atomicity 的应用只需要 redo-only logging 就足够了。
为什么很少用 undo(only)-logging(STEAL + FORCE)?
因为它既需要 STEAL(提交前的各个时刻都可落盘),又需要 FORCE(提交前一定需要落盘),因此 disk I/O 更大,比其他所有情况的时延更大(即便 undo-logging 可能恢复更快一点);
1.10 Consistency for Isolation: Before-or-after Atomicity
1.10.1 Definitions & 2PL
我们再讨论另一种情况。现在我们实现了 all-or-nothing atomicity,也有 linearizability 保证数据一致性,那么一定就没问题了吗?
非也,因为还会存在并发访问共享数据的问题。
分布式系统下,如果出现多线程共享数据时,可能出现 race condition。这也许可以用一致性模型解决?
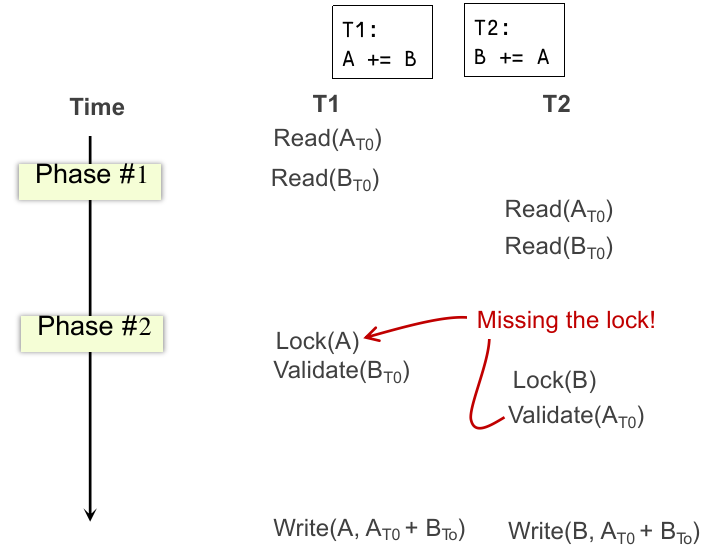
我们回顾一下前面讨论的好实现的 Linearizability 一致性模型。这样行吗?不一定行,因为:
正常情况下,Linearizability 这么做是没问题的,但是如果
所以现在我们还需要再引入一种 consistency model,这种 model 可以有效避免多线程程序下出现共享资源的 race condition 的问题,也就是实现了 before-or-after atomicity(在数据库领域被称为 Isolation,在 OS 领域还被称为 Serializability Model)。
我们详细定义一下 before-or-after atomicity:
Concurrent transactions have the before-or-after property if their effect from the point of view of their invokers is as if the transactions occurred either completely before or completely after one another;
用数据库领域的话说,就是并发执行的两个事务能够等价于事务的串行执行(可串行化)。
回忆一下,在数据库领域我们如何实现事务的 isolation?
我们采用的方法不就是 调度策略 + 锁吗?这里也是!
如果是分布式数据库事务呢?Two-Phase Commit,这里也是!
和数据库处理事务的 isolation 一样,我们要实现 before-or-after atomicity 就可以用锁来完成。解决办法:
Coarse-Grained Lock(Global Lock):每个 action 修改共享资源前后加一把大锁;
缺陷:粒度太粗,同时只会有一个 action 执行,甚至不考虑读写的区别,严重影响并发性能;
Fine-Grained Lock:每个共享资源有一个锁,一个 action 必须获得一个资源的锁才能访问它;
能否避免所有的 race condition?显然不能。
从数据库角度来看,只是加了互斥写锁,避免了基本的并发冲突,就是可能出现脏读(隔离级别 read uncommitted 不够);
同时为了避免全局脏读(例如全局 audit 程序可能查询正在转账的 A、B 时脏读),我们引入了新的 fine-grained lock 管理方式:Two-Phase Lock(和 Two-Phase Commit 无关);
它指的是,一个获取共享资源的 action 必要时拿锁,然后必须在 action 结束时释放。
也就是说,第一个阶段只拿锁,第二个阶段只放锁。
这里和 Global Lock 相比,虽然都有全部上锁的情况,但是毕竟这里的粒度小一点,阻塞时长短一点。
对比一下 Global Lock 和 Fine-Grained Lock:
Fine-Grained Lock 需要的锁更多(尤其是涉及数据记录多的时候),内存资源占用率更大;
Fine-Grained Lock 也可 on-demand 调整锁的数量,只需要确保访问同一个数据记录时用同一把锁就行。
但 Global Lock 的并发性能更差一点(同一时刻只允许一个 action 访问);
Serializability Model 中有几类并发顺序,恰好和数据库领域的 “调度” 的概念对应:
Final-state serializability(数据库中的 “终态可串行化调度”);
Conflict serializability(数据库中的 “冲突可串行化调度”);
View serializability(数据库中的 “视图可串行化调度”);
我们定义:交换事务相邻两操作(action)的顺序,如果不改变最终结果相同,则称这是一次等价交换(两个调度是等价的)。并且,如果调度
也就是存在一个这样的调度就行!
根据交换等价以及 冲突可串行化调度的定义,我们直接有结论(通过等价类理解):若冲突可串行化调度
因为这个保序性,我们可以借助拓扑排序描述等价类间互不可等价交换的关系,称 “优先级图”。若调度
我们再定义:一个调度是视图可串行化的,当且仅当最终写状态,以及中间的读状态和对应的串行调度是相同的。
也就是说,终态可串行化只关心事务调度的最终状态与串行调度一致(也是我们的目标),视图串行化除了关注最终状态,还关注中间读的状态;冲突可串行化不仅关注最终状态,还关注了数据依赖。因此严格性依次上升,但判断难度逐级下降。
如何证明 2PL 协议是 Conflict Serializability 的?我们假设一个前提,所有共享资源冲突都可以用锁来管理。
反证:假设不是这样的,因此 Conflict Graph
设
xxxxxxxxxxT1 and T2 conflict on x1T2 and T3 conflict on x2...Tk and T1 conflict on x_k
紧接着:
xxxxxxxxxxT1 acquires x1.lockT1 releases x1.lockT2 acquires x1.lock and x2.lock...Tk acquires x_{k-1}.lock and x_k.lockT1 acquires x_k.lock
发现前两步骤违背了 2PL 的定义,因此假设不成立。
1.10.2 Case: Salary System
那么如果没有 “所有共享资源冲突都可以用锁来管理” 的前提,2PL 还能保证 conflict serializability 吗?
我们假设在一个工资数据库中,每一个雇员的记录都有一把 Fine-Grained Lock。
如果
如果
解决方案有:
谓词锁:通过标记相关联的数据记录,对这些记录任意之一上锁就是将它们全部上锁。粒度在 Coarse/Fine Grained Lock 间;
在 B/B+ 树索引结点上范围锁;
但一般不会处理它,因为代价很高。
1.10.3 Deadlock
对于 2PL (悲观的)锁,极有可能因为拿锁顺序的问题而持续地相互等待。
解决方案是:
尝试避免 deadlock:每个以 pre-defined 的顺序来拿锁。
问题是这与具体业务逻辑(read-write pattern)有关,不支持通用的事务;
尝试检测 deadlock:固定周期检测 conflict graph;
如果有环就可能死锁,于是 abort 一个事务来破除冲突环;
问题是代价很大。在大规模分布式系统中难以实现;
启发式缓解方案:例如超时重试、pre-abort;
可能的问题是 false positive、live locks;
因此我们需要反思,悲观的 2PL 协议可能引发死锁,而且不得不付出代价解决。
那么我们能不能使用乐观的方式来实现 Before-and-after Atomicity?
1.10.4 OCC: Optimistic Concurrent Control
乐观的并发控制机制主要有 3 个流程:
Concurrent local processing:读、写都在本地 buffer 进行并记录在 read/write set 中;
Validation serializability in critical section:
检测 serializability 是否能保证(也就是 read set 中是否被修改过);
Commit the results in critical section or abort:
如果 validation 失败了,abort 这个事务;
如果 validation 成功了,刷入 write set 指定的 buffer 并提交事务;
也就是说:
当事务开始时:tx.begin(),初始化 read set 和 write set;
此后事务内对特定资源第一次读操作,读并更新 read set(read set 需要缓存这个数据值。此步需要 atomic);
写操作写入本地 buffer 并更新 write set,并且检查当前事务的 read set 是否有这个数据,有则更新 read set 缓存的数据;
对特定资源的第二次及以后的读操作,需要看 read set 中是否有缓存,有直接返回,无则说明是 “第一次读操作”;
当事务提交时:tx.commit(),同时包含 phase 2 和 3;
如果 read set 中的内容被其他事务更改,则 abort;
否则对每个 write set 内容刷回数据库;
注意 phase 2 和 3 需要在 critical section 中(事务互斥),有两个原因:
因为可能出现 ABA problem:
如果
解决方案是在数据基础上加上版本号(64 bytes)。我们在 read set / write set 中就可以用这种方法。
并发事务同时执行 phase 2 时,都对
那么如何实现 phase 2 和 3 的 critical section?
使用 global lock(和 2PL global lock 不一样,这个大锁只存在 phase 2 和 3 中,不会对性能有很严重影响);
但客观上还是降低了并发性能;
使用 2PL 协议,对 read set、write set 排序上锁(尝试避免死锁);
能否不对 read set 上锁,只是检查 read set 是否被更改?
不行,因为只能说明 read set 目前没被改,不能说明没有上锁。如果有同步 commit 的两个事务,也会有问题:
因此如果不锁 read set,就还需要检查 read set 中的数据是否被上锁。如果被上锁也 abort。伪代码:
xxxxxxxxxxdef validate_and_commit() // phase 2 & 3 with before-or-afterfor d in sorted(write-set):d.lock()for d in read-set:if d has changed or d has been locked:abort()for d in write-set:write(d)// release the locks...
OCC 的优势:
OCC (in the optimal case, i.e., no abort):
1 read to read the data value;
1 read to validate whether the value has been changed or not (as well as locked)
2PL:
1 operation to acquire the lock (typically an atomic CAS);
1 read to read the data value;
1 write to release the lock;
A single CPU write is atomic, no need to do the atomic CAS;
综上:Locking is costly especially compared to reads!
OCC 的劣势:显然,在 serializable 情况下,即便没有出现 conflict cycle 也可能判断需要 aborts,如下:
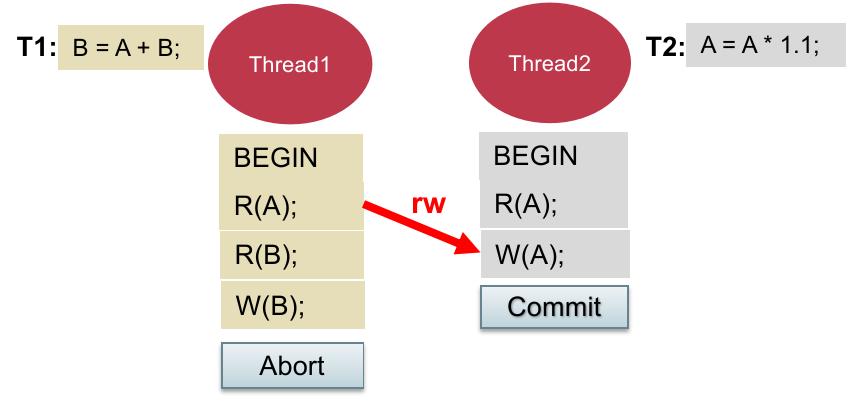
注:这种情况下可以串行化为
先执行, 后执行;
这种情况就是 False Aborts;尤其是在很多读的情况下(read set 很大);
更严重的情况时,当大量事务并发时,两个 aborts 的事务在重试时又再次 aborts,结果可能造成 live locks!
这样 2PL 和 OCC 在不同并发数量情况下的吞吐量关系如下:
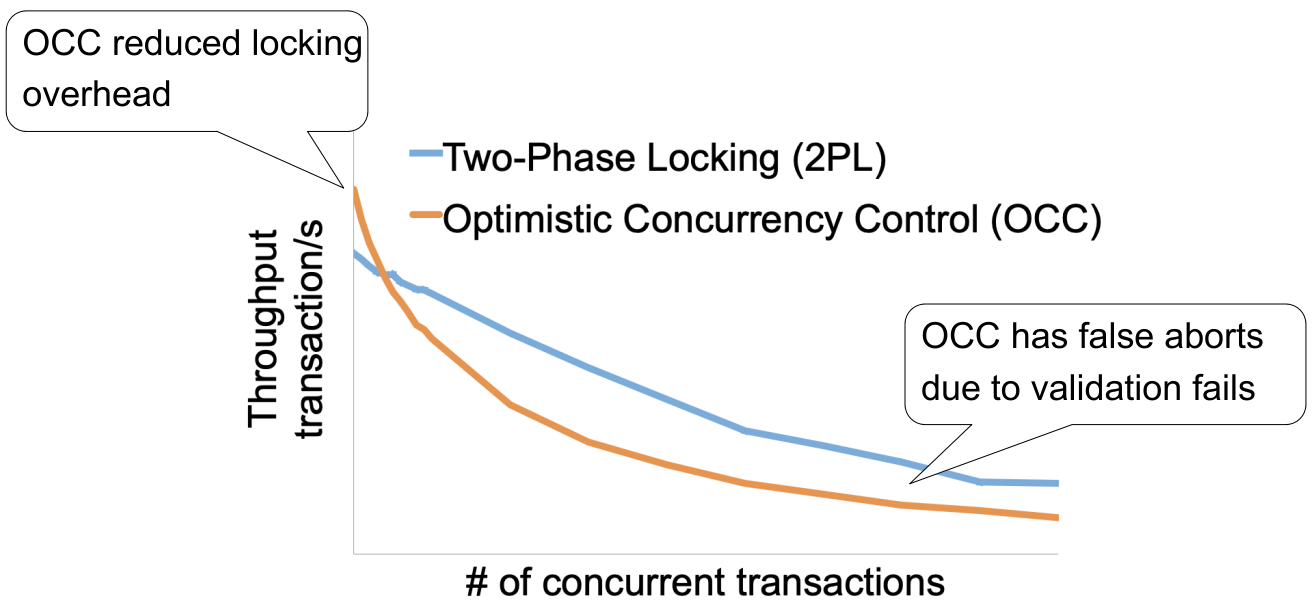
1.10.5 Lock Preliminary:锁如何实现
底层主要借助硬件实现。只是软件上的话不是很充分。互斥锁的硬件原语如下:
Compare-and-swap (on SPARC);
Compare-and-exchange (on x86);
最终编译器遇到上述指令后使用 Lock Prefix 确保在内存地址中原子执行;
Lock prefix to ensure an instruction is atomically executed on a memory address;
也就是提供了 CAS 的语义,软件可以在 CAS 的基础上实现对应的原子语义。
但是这 CAS 会极大地影响性能(比 L1 cache 慢 10 倍以上);
1.10.5 OCC & Hardware Transaction Memory (HTM)
硬件厂商,例如 Intel、ARM 会提供对内存的 Before-or-After Atomicity 的读写,这样就不需要软件层面的 2PL 和 OCC,进而提升并发性能。
Intel 推出 Restricted Transaction Memory (RTM),ARM 推出 Transactional Memory Extension (TME)。
以 Intel 的 RTM 为例,它提供了两个新的汇编指令:xbegin 和 xend,相当于事务的开始和结束。
在 OS 及以上层次,可以这么使用:
xxxxxxxxxxif _xbegin() == _XBEGIN_STARTED: // 成功启动事务 if conditions: // 手动取消事务 _xabort(); // abort (rollback) // critical code here(访问共享资源) // ... _xend(); // 事务 commitelse: // 与其他线程冲突,启动失败 abort case优点:
处于
xbegin()和xend()间在内存中执行的操作满足 before-or-after atomicity;大多数情况下,比 2PL 和 OCC 编程起来更简单;
大多数情况下,性能会很好(硬件高效于软件实现);
缺点:不保证成功(可能多次 abort),因此处理 abort case 时较为麻烦;
而且不能直接使用 retry(可能导致 live lock)。一般的做法参见下文;
为什么 RTM 不保证成功?
因为 RTM 底层是采用 OCC 的思想实现的:
Use CPU cache to track the read/write sets of CPU reads/writes;
Use cache coherence protocols to detect conflicts ;
什么是 cache coherence protocols?
在多处理器系统中,很多情况下多个进程可能需要一些相同内存块。主要由于:
可写数据共享,例如两个进程通过
mmap共享一块匿名页或文件页;多核间进程调度(process migration);
……
那么需要 cache 做一些统一措施,确保多进程能看到的数据是一致的。
实现这个协议有两类思路:directory-based 和 snooping;
前者提出将一块物理内存的共享状态存放在特定的位置(称为 “directory”,不宜译为目录);
后者设计比前者简单,提出对 CPU Cache 的共享总线进行侦测,如果侦测到总线上的操作与当前中的某个 block 相符 (tag一致),则采取某种动作(具体动作由具体的实现决定,比如 MSI),这种系统需要支持广播功能的总线。
更多信息请查阅网络。这是 CPU 设计领域的知识。
问题是 CPU cache 比较小(取决于硬件),一旦用完了就会导致无条件 abort;
一般情况下 RTM 使用 L1 Cache 跟踪 writes,L2/L3 Cache 跟踪 reads;
为什么 L2/L3 Cache 不会同时跟踪读写?
RTM 除了受到 CPU Cache 的限制,还有 Limited Execution Time:事务的执行时间越长,transactions abort 的可能性更大:
主要原因:CPU 中断会无条件打断 RTM 操作;
为什么会打断 RTM 操作?因为 Context Switch 会污染 CPU Cache,导致需要重新再来;
如何处理不成功的情况?
就是因为 RTM 是基于 OCC 的硬件实现,因此会因为 false validations 或者硬件上的限制(cache 不够大)而出现频繁的 Aborts。
所以在使用 RTM 时,在尝试一定次数(counter)后就需要切换到 fallback path 上(pessimistic sync),例如:
xxxxxxxxxxif _xbegin() == _XBEGIN_STARTED: // 成功启动事务 if lock.held(): _xabort() // critical code here(访问共享资源) // ... _xend(); // 事务 commitelse: // 与其他线程冲突,启动失败 // switch to perssimistic sync lock.aquire()
简单总结一下:
OCC 是区别于 2PL 的实现 before-or-after atomicity(isolation)的另一种经典协议;
OCC 的思想也被硬件设计者所接受(出现了各种 HTM);
硬件实现了对 Transaction Memory 的支持;
编程模型很简单(不需要锁):程序员只要在内存中进行计算就能利用到(例如 in-memory database);
底层基于硬件支持,如果使用得当,性能很好;
也不需要软件层面的锁和原子操作;
但是编程人员需要注意一些常见陷阱(CPU cache 和执行时间的局限,需要特殊处理 aborts 的情况);
1.10.6 MVCC
我们知道,无论是 2PL 还是 OCC,在大量的只读事务情况下性能很差。OCC 是因为 read validation fails,2PL 是因为读的时候锁住了其他线程。
当问题是大多数实际应用场景(例如淘宝页面)都是以读为主的,因此不得不针对读的性能优化。
我们先从 OCC 下手。OCC 多数的 False Aborts 主要是因为一下两种情况:
无关读写冲突(
T1 Read(A)=A0 -> T2 Write(A=A1) -> T1 Validate(A)):不违反 serializability,但是无法通过 read validation;无关写读冲突(
T2 Write(B=B1) -> T2 Read(B)=B1 -> T1 Validate(B)):没有 isolation 的情况下,写会影响到读,但我们希望预先隔离起来;
能否让读的情况不发生 false aborts(也就是能不能不 validate read)?
于是我们引入 “多版本” 的概念,每个事务操作的数据都有多个版本(multiple-versions),于是一个事务操作的一组数据就被称为 snapshot:
事务总是从一个持久化的 snapshot 中读;
事务修改 snapshot 的数据时更新数据的版本;
带有版本的数据的结构如下:

因此减少 false aborts 的目标就是:尽量避免在读 snapshot 时 race condition(如何让 read 总是读到符合顺序的 snapshot 上的数据)。
如何确定版本?可以使用时间戳来表示。我们需要它反映事务的串行执行顺序:
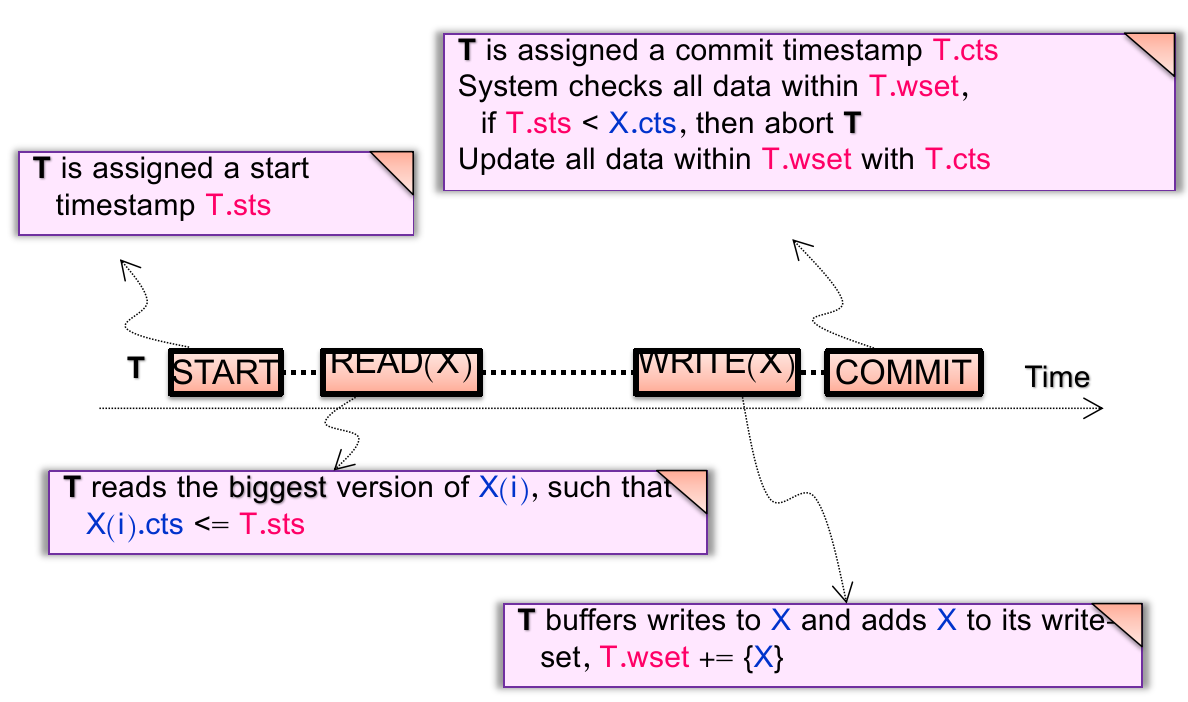
如果
最简单的解决方案的就是使用 global counter:
Using atomic fetch and add (FAA) to get at the TX’s begin & commit time;
TX Begin: use FAA to get the start time;
TX Commit: use FAA to get the commit time;
但有两个问题:
全局 FAA 可能在高并发情况下仍然不能很好;
在分布式系统中不同物理结点是不同步的(以后讨论更先进的 timestamp);
现在我们用 MV 改进一下 OCC(incomplete):
获取 start time;
Phase 1: Concurrent local processing
Reads data belongs to the snapshot closest to the start time(总是从最接近当前 start time 但 commit time 不晚于这个时间的 snapshot 中读);
Buffers writes into a write set;
获取 commit time;
Phase 2: Commit the results in critical section;
Commits: installs the write set with the commit time;
这样我们就不需要 validation 了!
xxxxxxxxxxCommit(tx): for record in tx.write_set: lock(record) let commit_ts = FAA(global_counter) for record in tx.write_set: record.insert_new_version(commit_ts, ...) unlock(record)
Get(tx, record): while record.is_locked(): pass for version,value in record.sort_version_in_decreasing(): if version <= tx.start_time: return value但是仍然需要锁来锁住从获取 commit time 到提交完成的区间,因为可能出现 partial updated snapshot;
我们看一个读过程(一个 start,另一个准备 commit):
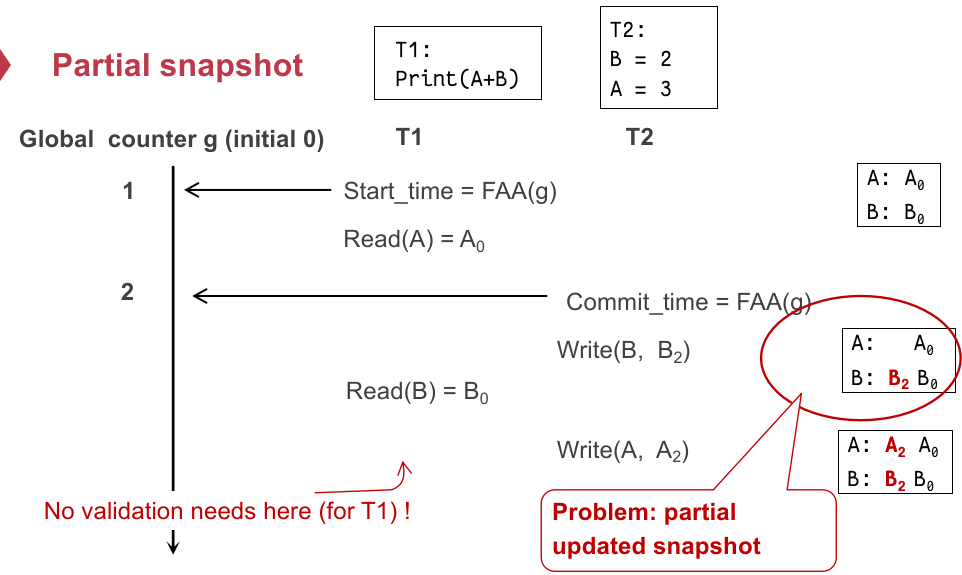
在
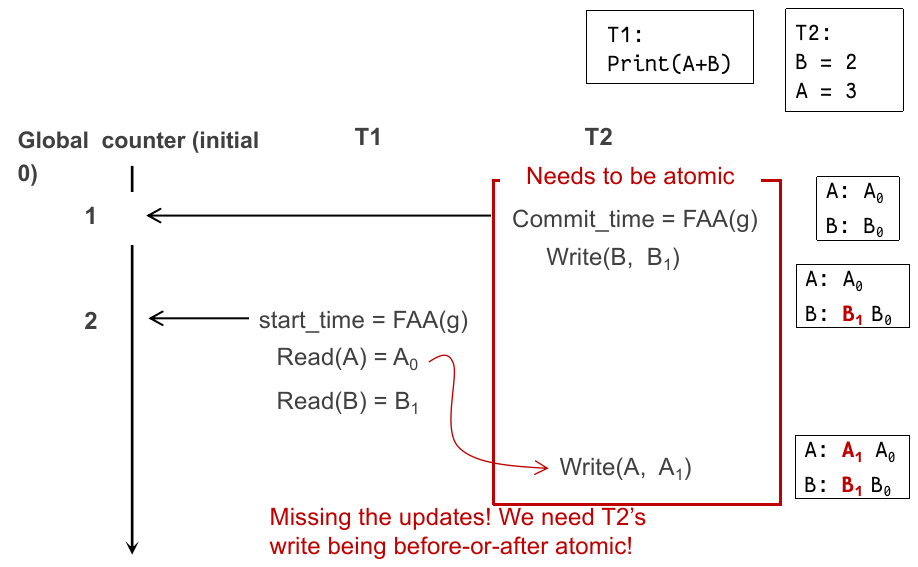
这个时候就会出现没法跟踪到另一个串行顺序在
综上,我们需要确保
xxxxxxxxxxCommit(tx): for record in tx.write_set: lock(record) let commit_ts = FAA(global_counter) for record in tx.write_set: record.insert_new_version(commit_ts, ...) unlock(record)
Get(tx, record): while record.is_locked(): pass for version,value in record.sort_version_in_decreasing(): if version <= tx.start_time: return value 这样在完全修改 snapshot 的状态前,未修改的部分不会被读到:
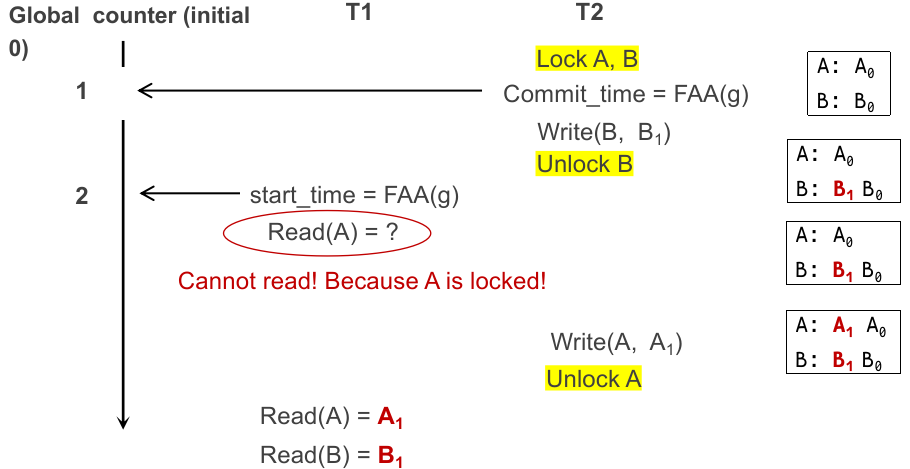
考虑一个问题,能否交换 commit 阶段的 “获取 commit time” 和 “上锁” 的顺序?不行:
xxxxxxxxxxT1 T2CTS = 1STS = 2Read(A) = A0Lock(A)Lock(B)Write(A)Write(B)Read(B) = B1
相当于
最终,我们可以使用改进的 incomplete MVCC 完成 read 过程的 isolation!
但还是要 validate writes,因为两个并发写冲突通常不可串行化,难以避免。
validate writes 的方式就是在 commit 阶段,其他事务针对当前事务已经写的 write set 中的数据,commit time 是否晚于当前事务的 start time(是否有更新的版本),如果有就 abort;
总结一下:
事务开始阶段,先从 global time 获得事务的 start time;
读数据
写数据
最后事务提交时,先从 global time 获得事务的 commit time,然后逐一检查 write sets 中每一个数据是否有比当前事务 start time 更晚的 commit time。如果有则 abort,如果无,则更新所有 write set 中的数据,并将数据对应的 commit time 更新为当前事务的 commit time;
现在这个 incomplete MVCC 就没问题了吗?大部分情况都符合 Before-or-After Atomicity 了,但现在还有一个问题需要解决:Write Skew;
可能会出现这种情况:
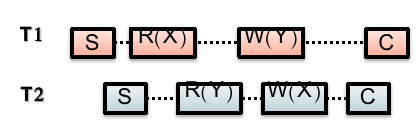
主要是只 validate writes 而没有 validate reads 造成了这个问题。
解决这个问题很简单:
对于 read-write transaction 的情况 fallback 到 OCC(再检查一次 read set);
但 read-only transaction 仍然能够享受 incomplete MVCC 的没有 aborts、没有 validations 的优势;
这个 incomplete MVCC 就被称为 Snapshot Isolation(SI);
其实,除了在 snapshot isolation 中首先实现了 multiple-versions,现在的 2PL/OCC 的变种也用到了 multiple-versions(以后讨论)。
1.10.7 Conclusion
总结一下事务中的 consistency。
我们在 OS 系统中讨论 “事务”,其实是一种管理数据行为的抽象。这个数据可以是 KVStore entries、文件系统的 meta-data、处理器 meta-data 等等;
我们要让事务保证 ACID 的性质:
Atomicity: all-or-nothing
Isolation:确保两个线程间的 before-or-after 的 atomicity,不会读到中间结果、避免 race condition;
Durability:一旦事务被提交,就需要对数据的更改是持久化的;
Consistency:它的必要条件是 atomicity;在此基础上,还需要编程人员保证程序语义的正确性,才能实现数据一致性;
之所以需要这些性质,就是想要实现 failure atomicity 并避免 race condition,最终简化管理数据的抽象。
我们通过 Logging 和 Recovery 策略,实现了 Atomicity 和 Durability;通过 Concurrent Control Methods(2PL/OCC/SI)实现了 Isolation;最终数据库约束系统和编程人员共同确保 Consistency(这里不讨论)。
1.11 Replications & Multi-site Atomicity
如何让 1000 台机器像 1 台机器一样工作?
1.11.1 2-PC
回忆一下,OCC 和 2PL 在大量读的情况下性能不佳,因此我们引入了 MVCC,利用 Snapshot Isolation 实现一个更高效的读,规避了 read validation;
假设一台机器的物理资源已经不足,现在我们希望分布式存储,将同类数据存在不同机器上;
Clients + coordinator + two servers;
在每台机器上,我们都有 logs 来确保 atomicity;
这个时候显然单机的数据库的通过 logging 是不能实现整个系统的 all-or-nothing atomicity 的!
这是因为事务分布在不同物理节点上,于是,事务会被切分为两种:
high-layer transaction:全局语义下的事务;
low-layer transaction: nested 在 high-layer 事务中的每个物理节点中的事务;
问题转化为,如何使 high-layer 事务协调 low-layer 事务,保证所有 low-layer 事务的 all-or-nothing atomicity;
我们需要知道,在分布式场景下,仅仅有 commit 和 abort 的状态是不行的,还需要 tentative commit 状态,表示已经准备好 commit,需要等到 coordinator 判断让其他所有 servers 都写入时再进行;
于是人们基于这个思想,引入一种新的协议:Two-Phase Commit;
Phase 1: Preparation / Voting
推迟所有 low-layer transaction 的 commitment,而是进入 tentative commit 状态;
当前 low-layer 事务要么 tentative commit,要么 abort,higher-layer 事务需要逐一发送
prepare请求,判断是否全部准备好 commit;
Phase 2: Commitment
一旦有任何一个 low-layer 事务 abort,coordinator 向其他所有事务发送
abort请求;一旦所有 low-layer 事务 tentative commit,coordinator 发送
commit请求,通知所有事务提交;
看起来很美好,对吧?我们讨论一个 conner case 来考虑系统的 fault tolerance:假设分布式系统中任一台机器挂了 / 任一次请求通信挂了(不可靠)怎么办?
我们回忆单机的 logging 会写 redo-undo log,如果事务应该提交,但是准备 commit 时挂掉,那么单机会在重启时重做,而如果全局决定了 abort 那么数据就会不一致!因此我们需要更改记录 log 的方式。
解决方案是:
在 low-layer 事务中,将原先的 commit 的 log entry 改成 tentative commit entry(PREPARED);
在 high-layer 事务中,收集所有 low-layer 事务是否有 ABORT / timeout,有则 ABORT / retry(可能是网络连接问题);
如果没有 ABORT,则 COMMIT(也记录日志);
总而言之,我们有原则:
总是遵循 coordinator 的决定;
一个 low-layer 事务如果 abort 就等待 coordinator 的处理;如果 tentative commit,则还是等待 coordinator 处理(没有消息就不动),让它 commit 再进行,让它 abort 再 abort;
举个例子,一个 high-layer 事务有两个 low-layer 事务:
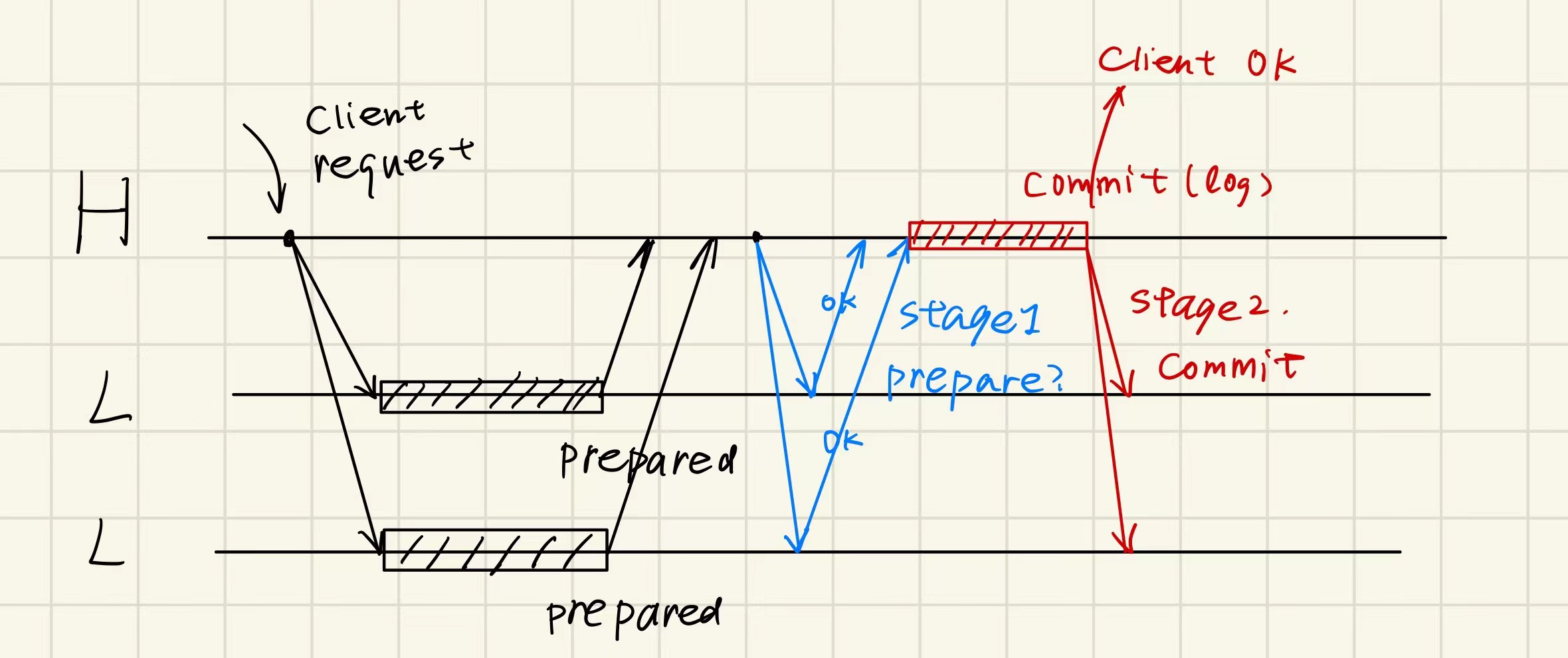
现在我们在新的解决方案下讨论所有故障的情况:
High-layer 事务 phase 1 发送错误:timeout,resend 即可解决问题;
High-layer 事务 phase 1 接收错误:timeout,resend 即可解决问题;
High-layer 事务 phase 1 发送时 low-layer 事务所在 server 宕机:重试超时,认为 abort,全局 abort。
无论这个宕机的 low-layer 事务是否准备好(prepared/abort),都不会让当前事务 commit 的;
后者好理解,如果是前者,在重启后看到日志是 prepared,还会向 high-layer 事务 server 发送请求查询,发现 abort;
High-layer 事务 phase 2 发送错误:timeout,可以 resend,也可以等这个接收方超时询问,即可解决问题;
High-layer 事务 phase 2 接收错误:此时收到 commit 的 server 已经提交,为了防止问题发生,会 resend commit 指令直至有回应;
High-layer 事务 phase 2 发送时 low-layer 事务所在 server 宕机:high-layer 事务 server 必须等待(因为有的 server 已经交了),直到挂掉的 server 重启后,看到自己日志 prepared,会再次向 high-layer 事务所在 server 确认,这个时候再 commit 和确认就行;
High-layer 事务 server 自身在 phase 1 任意时间宕机:其他 servers 等待,重启后发现原来事务的 log 没有结束,因此 undo 并向其他 servers 发送 abort;
High-layer 事务 server 自身在 phase 2 任意时间宕机:某些 servers 已提交,某些 servers 正在等待,重启后发现原来事务已经 commit 但是为了防止没有 commit 完全,再重新全部对这个事务发送一次 commit 请求;
这个是否重试的依据,可以考虑在 phase 2 结束时,在所有 low-layer 事务 commit 后再记一个 log 表示全部 commit 已经核实(类似 checkpoint);
Remaining challenge:我们最终发现,这个解决方案看起来实现了 all-or-nothing atomicity,但是可用性不强,尤其是 coordinator 挂了后,事务就需要一直等待它重启了。
此外,我们还需要知道:
尽可能少记日志(就像 redo vs undo-redo logging,对性能好)。只在必要的时候(例如 commit/abort 时)才记日志;
low-layer 事务如何处理 checkpoints(方便移除日志)?需要 high-layer 事务做一些 additional work;
最终,Two-Phase Commit 需要在 2PL 和 OCC 上应用:
2PL:只有到 high-layer TX 决定 commit 或 abort 时,每个 low-layer TX 才能放锁;
OCC:其中 phase 2 和 3(the validation & commit phases)会被转移到 coordinator 中执行;
1.11.2 Replication
那么 2PC 实现了 CAP 的哪些特性?答案是只保证了 Consistency。因为:
如果 coordinator 挂了,其他相关的 transaction 都需要等待它恢复;
参与分布式事务的一个服务宕机后,需要一直等待这个服务可用后才能继续进行;
因此我们需要 replication 来确保高可用性。
实现 high availability 的优点:
For performance:
Higher throughput: replicas can serve concurrently;
Lower latency: cache is also a form of replication;
For fault tolerance: Maintain availability even if some replicas fail;
这里我们主要讨论如何备份多份数据,对 coordinator 的备份是类似的。
有两种备份方法:
Optimistic Replication (乐观备份,只保证 eventual consistency)
容忍一定程度的数据不一致,之后在慢慢 fix;
适用于允许 out-of-sync replicas(备份节点可以存在过时数据)时的场景;
Pessimistic Replication (悲观备份,保证 linearizability)
在各个 replicas 间保持强一致性;
在 out-of-sync replicas 会造成严重问题的时候应该使用这种方法;
有些情况下应该采取 悲观备份方法,例如 2PC 的 coordinator(需要 commit 决定是统一的),也就是要求 “Single-copy Consistency”(多台机器和一台机器是一样的),需要从外界看起来只有一份数据。强一致性的代价就是牺牲一部分性能和可用性。
我们可以用 Replicated State Machine(RSM)这个模型来做 pessimistic replication(尽管 RSM 中会有很多 replicas):
(初状态相同)Start with the same initial state on each server;
(完全相同的输入)Provide each replica with the same input operations, in the same order;
(保证操作不随机)Ensure all operations are deterministic
E.g., no randomness(把随机数生成也作为统一输入), no reading of current time, etc.
理想情况下 RSM 能实现 single-copy consistency;
问题是,clients 的请求到达不同 servers 的顺序可能不一致(这是物理情况决定的)。由于我们现在要实现 pessimistic replication,因此不能之后再 re-order,而是需要立即 re-order。我们后面讨论这个问题。
现在来看 RSM 模型的实现。一般来说类似 GFS 的 primary backup(主从备份)就能解决问题:
也就是:使用 view server(可以是独立物理节点/独立进程),来确保只有一个 server(primary)从 clients 接收请求。并且 primary 应该:
统筹所有的写操作,One-Write Principle:
决定所有操作的唯一顺序;
决定所有的 random value(
random() / time()等等);在确定所有 replicas 全部写好后向 coordinator ACK 确认(和 GFS 的 Write,以及 Linearizability 的 Primary-backup 实现一样);
在某个 backup failed 后重新建立一个新的 backup(有些问题需要注意,之后讨论);
这个 primary-backup 为什么这么构建?
首先,我们需要 primary、backup 来做 replication;谁做 primary、谁做 backup 可以事先指定。
如果 backup 挂了,primary 来检查并建立新的 backup;
如果 primary 挂了,则依赖于 coordinator(知晓 primary/backup 的状态),用它来选举新的 primary。
这种解决方案还是有问题:
如果 coordinator 挂了?那么我们建立多个 coordinator 来确保容错性。
如果两个 coordinator 间 “split-brain”(network partition)了,怎么办(Partition Tolerance)?这可能会选举出多个 primary,在 network 恢复后出现问题!
因此我们引入唯一一个 view server,将 coordinator 中判断、任命 primary 的工作分离出来,与所有 primary 和 backup 维持心跳,并告知 coordinator 谁是 primary。
View Server 的具体任务是:
与其他所有 server 构成心跳连接;
维护一个表,记录 a sequence of view,每个 view 包括:
view number:相当于版本号;
primary server:当前谁做 primary;
backup servers:剩下在线的做 backup 的 servers 列表;
必要时提醒指定 server 是 primary 或 backup 的身份(例如切换 primary 的时候);
回复 coordinator 的查询:“谁是 primary”;
一般回答一次后 coordinator 的后续请求就向该 primary 发送,可以减小 view server 的负担;
直至 coordinator 无法联系该 primary 或对方一直拒绝;
在一个 server 挂掉后,动态地 recruit 新的空闲 server(之前 primary 的任务);
此外,primary 和 backup 需要遵循下列规则:
primary 统筹写操作需要完成上述 3 个同样的要求;
backup 必须拒绝来自 coordinator 的写请求;
相反,primary 必须拒绝来自其他 server 让它 forward 和写的请求;
primary 必须是上一轮 view 的 backup/primary,不能是新被 recruit 的 server;
考虑一个 corner case:
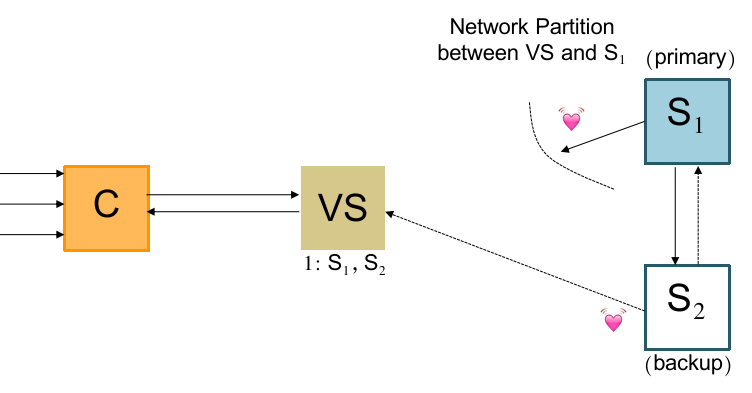
如果此时 View Server 因为无法和 S1 建立心跳连接(但 S1 是存活的,和 S2 和 coordinator 都能联系),而决定选 S2 为 primary 时,它会先更新一轮 view 并且向 S2 发送身份变更信息:
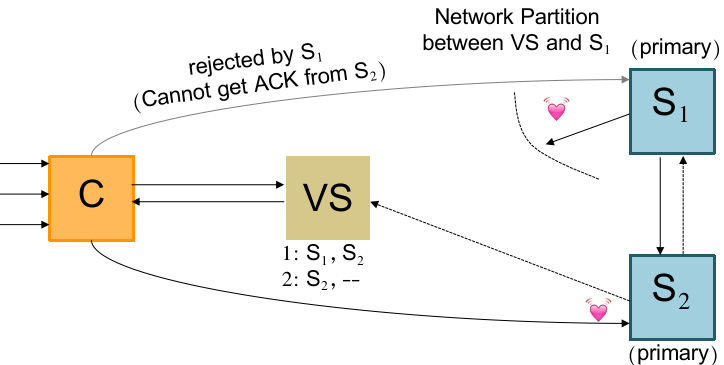
此时无论 coordinator 联系谁都会错误:
一开始 coordinator 按缓存的信息联系 S1,由于 S2 称为 primary(现在两个 primary),拒绝 S1 的 forward 请求,导致 S1 返回错误;于是 coordinator 重新咨询 view server;view server 告诉 coordinator 应该找 S2;
coordinator 找 S2 也会被上面同样的理由拒绝;
这个中间状态称为 “repair time”,我们一般允许系统短时间地处于该状态。
有了上述规则,即便 coordinator 也有 replicas,整个系统也能有 partition tolerance 了。
现在还有一个重要问题:如果唯一的 view server 挂了怎么办?我们知道,为了保证 partition tolerance,我们不应该再对 view server 继续 replication 了。
不过幸运的是,view server 的任务足够简单、本身足够轻量,我们可以使用分布式协调服务来确保多个 view server 的对外完全一致性。
这个分布式协调服务像 ZooKeeper、Raft 都可以胜任,它们的思想都起源于 Paxos(经典,但晦涩),下面介绍 Paxos 的基本原理。
1.11.3 Single-Decree Paxos: Distributed Consensus Mechanism
Paxos 这样的分布式协调机制需要解决的问题就是,如何在系统存在大量并发读写、延迟、network partition、每个 server 随时可能宕机的情况下确保数据的写操作能够以正确和唯一的顺序最终传达给所有分布式 servers 并持久化。
而 single-decree Paxos 则是用来解决上述问题的子问题:如何确保系统不受上述因素影响 agree on one value。
也就是,实现 RSM 的某个状态在所有 replications 上都能保证最终顺序一致,不论现在的情况如何;
或者说,让 RSM 的单个 Log Entry 维持一致;
Single-decree Paxos 机制如下:
在 Paxos 这个独立的 “岛” 中,有 3 类角色:Proposers(提议者)、Acceptors(选举者)、Learner(记录者)。
这 3 类角色都是逻辑角色,实际上可以一个物理节点分饰两角。
其中:
Proposers(Leader)需要接收外界 clients 发来的请求,并且执行整轮 Paxos 协议;
Acceptors 需要记录:期间 proposers 提出的决议、接受过的协议,以及其他状态信息。下文中,我们将超过半数的 acceptors 同意称为 “多数同意”;
Learners 在协议最终达成共识后,从 acceptors 广播的信息中记录固定下的结果,并且将结果响应外部 clients;
注意,提出的 proposal 有一个 ID 和对应的 Value,Value 是什么不重要,只要知道一个 proposal 中有一个 ID 和对应的 proposal value 能携带信息就行。
此外,在 paxos 协议中,存在决议轮数(round),每一轮有唯一的 ID 标识。每轮之间不需要维持同步关系。可以使用超时等待的机制。
并且当一个位于
而每一轮可以分为不同的 phases。下面详细阐述不同 phases 的内容:
Phase 1A: Prepare
Leader 视角:
Proposers 中的 leader(optional,也可以不选举,每个 proposer 都行)创建一个 proposal
并且要求
注意:这里的 proposal 不含有 proposal value,只是为了确认是否能获得多数同意。
具体为什么,后面介绍。
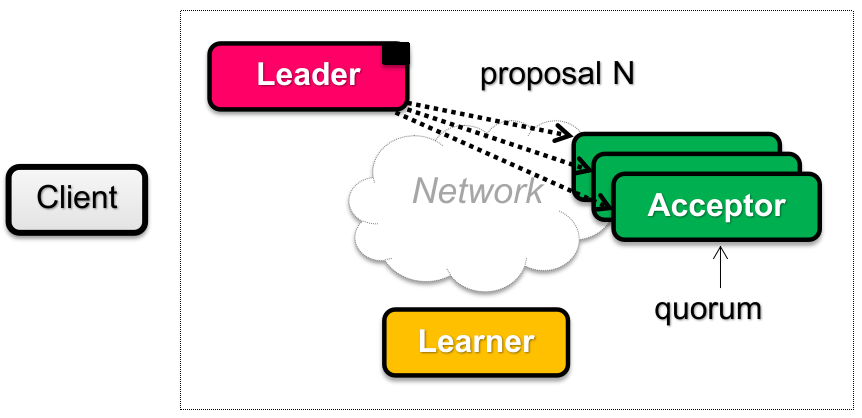
Phase 1B: Prepare
Acceptors 视角:
接收来自 leader 的 proposal(s),并且判断:
如果这个 proposal ID
回复之前同意过的 proposal ID 最大的 proposal ID
保证从这之后拒绝所有 ID 小于
更新 “见过最大的 proposal” 的 ID
否则直接忽略(不予回复);
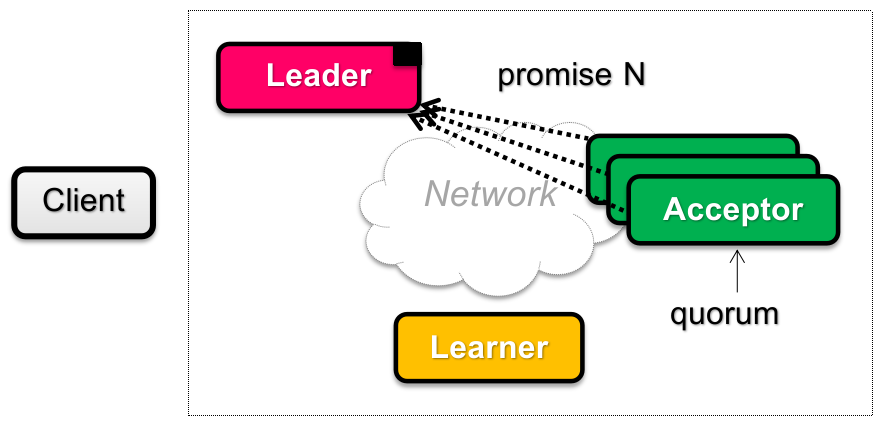
Phase 2A: Accept
Leader 视角:
如果一段时间后没有收集到 Acceptors 的多数同意(超时或者发现 proposal
反之,如果 Leader 收到了 acceptors 的“多数同意”(定义参见上文,下面不再赘述),则说明自己的 proposal ID 极有可能(为什么是可能?因为可能存在 network partition)是目前最新的,因此判断:
如果 acceptors 返回的 “之前同意过 proposal ID 最大的 proposal value”
那么为了保证分布式协调一致性,这轮 proposal 只能使用该轮的 proposal value
注:如果 acceptors 返回有很多种 proposal value(来自不同 proposal ID),那么总是取最大 proposal ID 的非空 proposal value;
如果 acceptors 返回的 “之前 proposal ID 最大的 proposal value”
然后,在上述判断确定好 proposal value 后,向 acceptors 声明:proposal
让 acceptors 补充记录 “同意过最大的 Proposal” 对应的 proposal value
让 acceptors 知道当前被多数同意的 proposal,并且让 acceptors 广播给 learners;
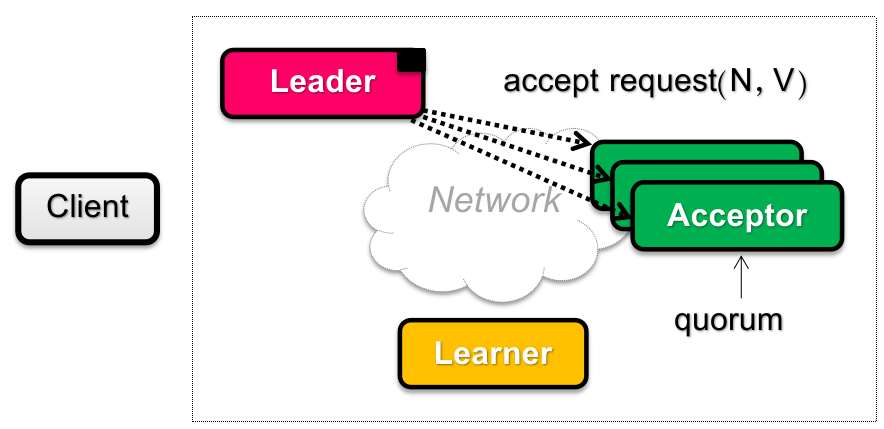
Phase 2B: Accept
Acceptors 视角:
如果 leader 发来的 “声明获得多数同意” 的信息
补充记录 “同意过最大的 Proposal ID” 对应的 proposal value
向 Proposers 广播 proposal ID
发给 proposers 是为了:
让处于 phase 2A 等待的未拿到多数同意的 proposers abort 更旧的 proposal,回到 phase 1A;
让所有 proposers 更新 “看到的最大的 proposal ID”
否则(期间有 proposal ID 更大的 leader 声明 “获得多数同意”)会忽略这个声明。这种情况可能是 leader 遭遇了延迟,或者其他原因。
这也是为什么 acceptors 存放的 “同意过的最大的 Proposal ID”
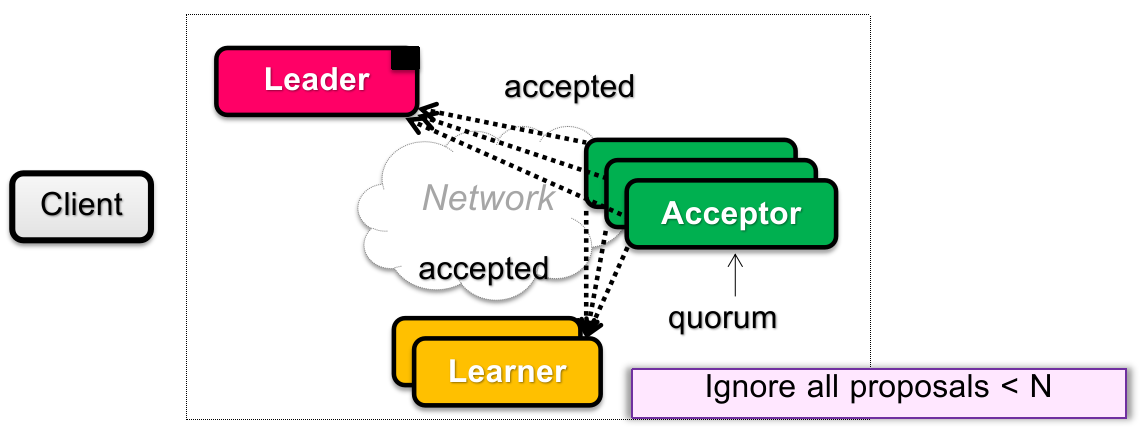
Phase 3: Learn
如果 leader 获得了多数 acceptors 的 “达成一致” 的响应,则说明真正确定了 Proposal Value(因为确保多数 acceptors 已经在 Phase 2B 记录了这个 value 作为
否则 leader 重新回到 Phase 1A,带着这个值重新提出一次 proposal。
最终获得消息的 Learner 持久化决定(decide)的 proposal value,并且向 clients 回复。
最终,无论 clients 输入什么请求,所有 learners 总是会保持这个 proposal value 不变。
现在我们最终考虑几个问题:
思考 1:如果 “获得多数同意” 的声明
答:不会有影响。此时多数 acceptors 已经记录了
如果
思考 2:可能出现
答:不会的。因为如果 Phase 1B 同意并记录了
思考 3:如果多数 acceptors 虽然达成一致,但因为某些原因未能向 proposers 发送达成一致的信息,会不会造成出现多个 “达成一致” 的 Proposal Value
答:不会的。不用担心这个多数达成一致的
所以,之后即便有 proposal ID 更大的 leader 声明获得了多数同意,也会 “继承它的遗志”(原因参见 Phase 2A,“总是取最大 proposal ID 的非空 proposal value”),选这个最早达成一致并广播的
因此无论怎样,最终总会保持最先多数达成一致的 proposal value。
思考 4:最终达成一致的 Proposal Value 最早在什么时候被确定的?
答:
不是在 leader 获得多数同意时。因为 Leader 可能挂掉、可能因为延迟,期间有更新的 proposal 被多数同意并且首次设置了 proposal value;
不是在超过半数 acceptors 收到 “声明获得多数同意” 的信息时。首先这个时间节点只有从上帝视角才能知道(acceptors )。其次,收到声明的 acceptors 可能之后立即挂了,导致回应少于半数,leader 重试;
只有当超过半数 acceptors 发送 “达成一致” 的信息(这个也只有上帝视角才能知道),或者说 leader 收到超过半数 acceptors “达成一致” 的信息(这个比前面稍微晚一点点,但系统能感知到);
思考 5:如果 Phase 1B 中 acceptors 在发送完成同意后立即挂掉,是否应该保存一些信息?
答:应该利用日志等手段持久化
思考 6:如果 Phase 2B 中 acceptors 在接收到 “声明获得多数同意” 的消息后挂掉,是否应该保存一些信息?
答:应该持久化
思考 7:如果 leader 在发出 “声明获得多数同意” 的消息后挂掉,应该怎么办?
答:应该持久化
但是
也不必要(不会影响正确性),只是如果没有的话 proposers 需要一轮一轮尝试,会增大 conflicts 和 restart 的次数,降低性能;
思考 8:从第一次 propose,到 learners 最终得到决定的值,最少需要几个 Phase 的通信?最多呢?
答:不考虑其他干扰因素,完整需要 2 个 phase(两个来回),最坏情况一直没法选出决定的值。
思考 9:如果没有 Learner,能否知道 paxos 最终决定的值?
答:可以,但是过程会更复杂,性能会下降。proposers 需要 2 次请求并对比结果才能知道最终决定的值;
1.11.4 Multi-Paxos
Basic Approach
我们注意到,single-decree Paxos 只是解决统一一个值的子问题(确定 RSM 中的一个状态在所有 replications 中统一,也就是让 RSM 单个 Log Entry 统一),如果希望统一一系列值(RSM 继续转移状态),就没法办到了(因为 single-decree Paxos 总会保持最先多数达成一致的 proposal value)。
永远只投出单个值的 single-decree paxos 在实际场景中几乎不可用。
例如我们没法用 single-decree paxos 来实现 View Server(对于不同 view 的变化没法应对)。
最简单的解决方案是,我们可以为每个 Entry 创建一个独立的 single-decree paxos 实例,让它们各自沉淀出唯一确定的值。
例如对于一个正常情况,我要向 RSM Log 中插入一个 Entry yyy(状态转移),正常情况初状态如下:
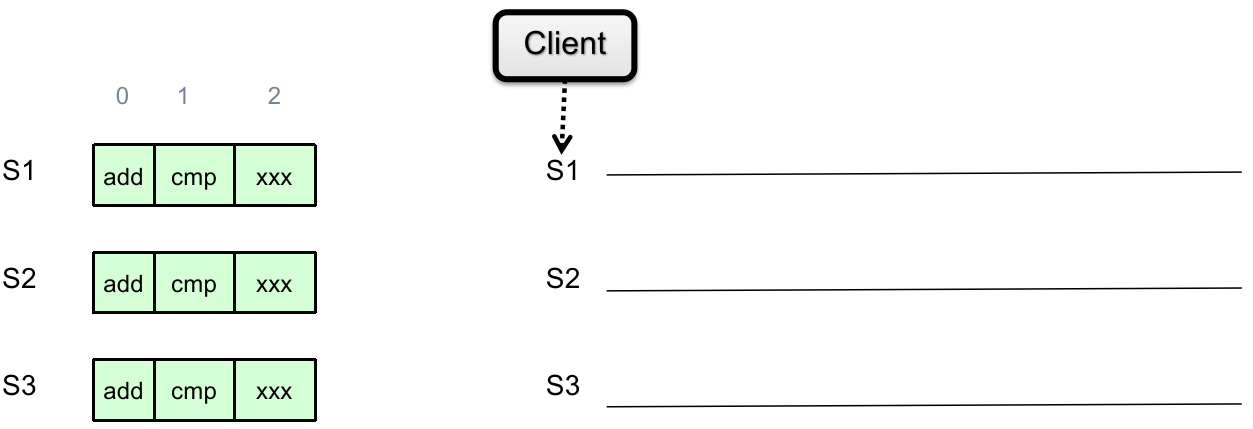
然后接收到 client 请求的
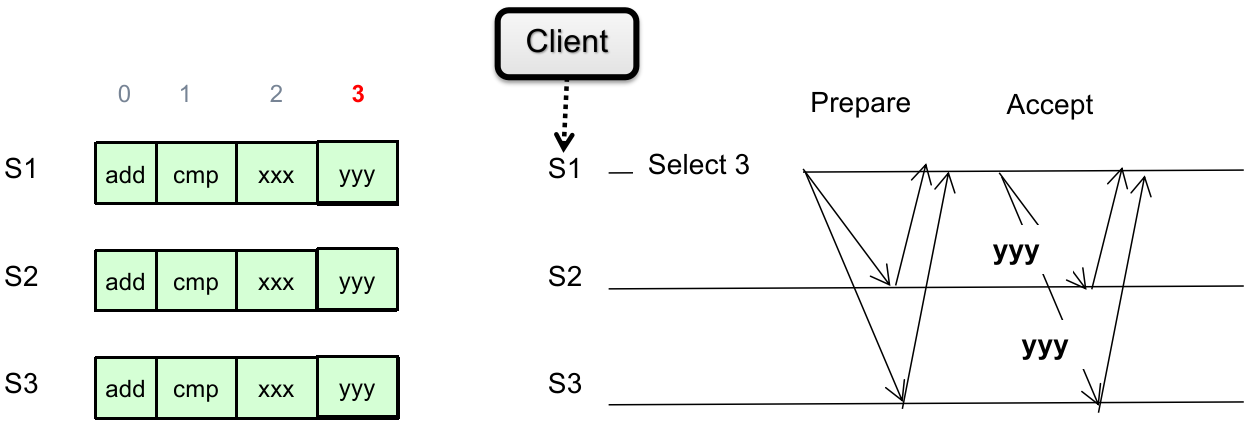
如果之前是有问题的呢?例如假设有一个 server
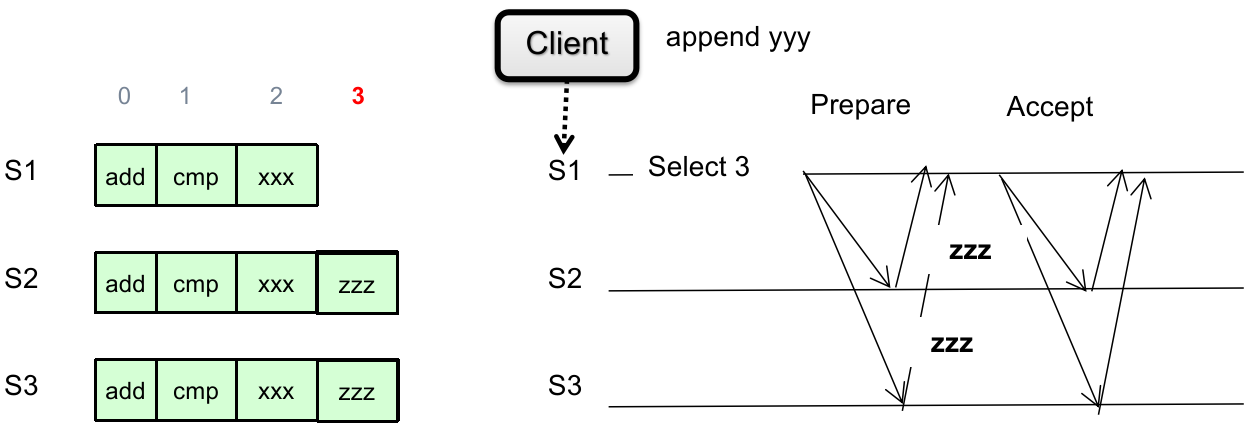
现在 client 想向 yyy 的请求,这个时候 yyy 肯定无法获得多数同意(因为在旧的实例中,多数 acceptors 已经对 zzz 达成一致了),因此最多只会补上第 3 轮的 zzz;
还需要重新再请求一轮才能真正写入 yyy:
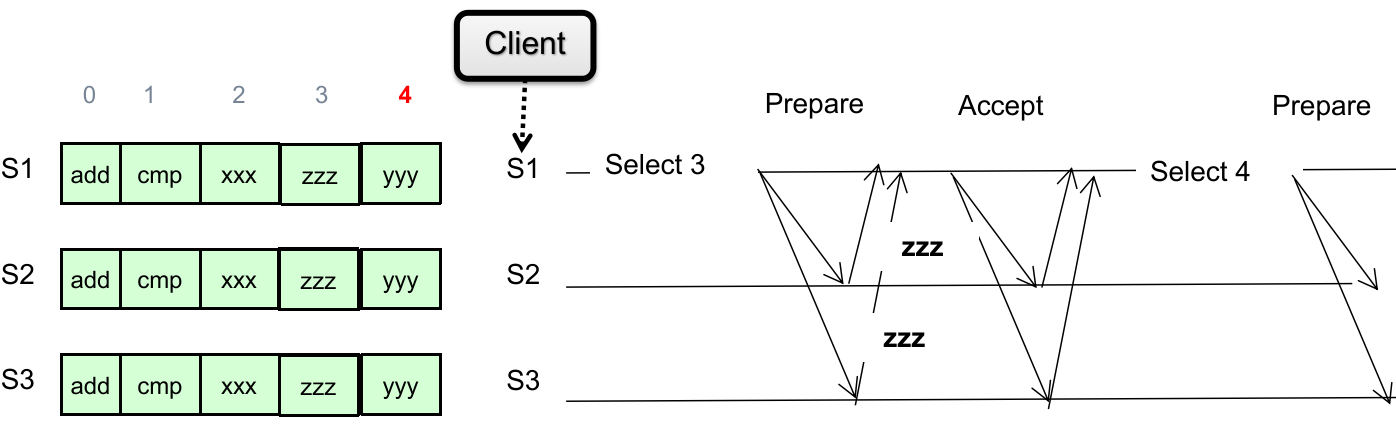
依此类推,如果 client 请求的是比最新决议晚
Improvements
我们知道这样是不高效的,原因有几点:
每轮 Single-Decree Paxos 可能有多个 proposers 并发 propose,会频繁出现 conflicts 和 restart 的情况(例如它们都没能拿到多数同意);
不同 Server 间的 Learners 情况不一,可能造成需要多轮请求才能写入的情况;
我们可以作出如下改进(以下改进不必要,但可以提升 multi-paxos 的性能):
每次只选出一个 Leader 可以 propose(随机选取一个就行,因为不需要保证唯一,只是尽可能减少);
一个 Leader 收到 requests 后,可以先向多个 paxos 实例提前发送 Prepare(Phase 1,反正不需要 propose value),提升性能;例如下面两个做法的结果一样:
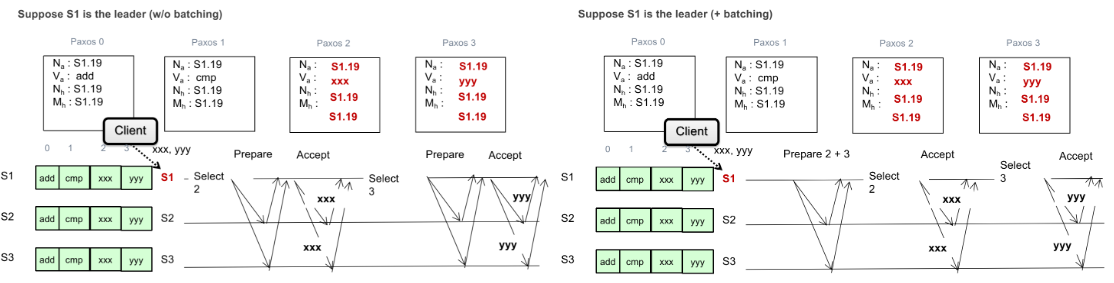
不过除了性能问题,multi-paxos 还可能出现日志空洞的问题:
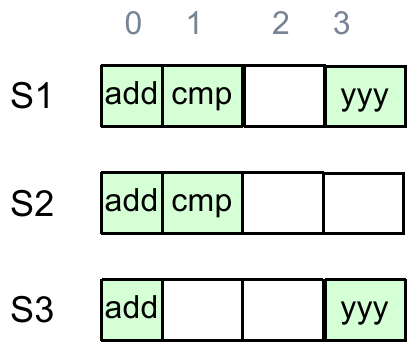
有些 server 有、有些没有决定值的情况我们前面就讨论过,可能是因为延迟或者 partition 或者宕机等等原因。一般需要再过一段时间才能最终一致;
而对一个 paxos 实例所有 server 都没有决定,则可能是一个 server 在提出 propose 时立即挂了,或者决定前立即挂了,则需要 client 单独重新请求(但不影响分布式协调的特性,RSM 可以最终统一)。
总的来说,paxos 从数学理论层面描述了分布式协调系统的可行性,但是对于工程上如何实现 RSM 而言并不友好。因此人们提出了 Raft 算法来在工程实现层面支持分布式协调机制。
1.11.5 Raft
Raft 作为一个与 Paxos 等价的分布式协调系统,它在工程实现方面非常友好。
其中,Raft 与 Paxos 最重要的一点不同就是,它们的目标不同。Paxos 确保在分布式环境中选取出唯一稳定、一致的 proposed value,需要 multi-paxos 多实例实现一系列稳定的值(也就是日志),并且它不保证日志的 entries 全部填满;
Raft 目标就是在分布式系统下,为 Replicated State Machine 维护 replicated log,确保这些 log 的顺序一致(前缀内容相同),最终一定能相同。
Raft 的实现方法从较高的层次上看,有如下几点:
Leader Election:仍然坚持 One-Write Principle,选举其中一个 server 作为 leader;当 leader 挂了后重选;
Log Replication: Leader 负责接受来自 Clients 的请求,将它们按照某种顺序 append 到日志中,并且通过 overwrite inconsistencies 来 replicates 到其他所有 servers 中;
Safety:为了保证 logs 的 consistent 特性,只有 log 相对更新的 servers 才能成为 leader;
对于 Leader Election,Raft 设计了和 Paxos 类似的 “身份系统”:
在任意时刻,Raft 中的每个 server 都是以下身份之一:
Leader:接受 clients 请求,并进行 log replication;
和 multi-paxos 不一样,必须同时有且仅有一个 leader,才能保证正常工作;
当 follower slow/crash 时一直尝试 retry replication;
Follower:被动接收并执行 leader 发送的请求;
Candidate:等待选举、准备成为 leader 的 server;
上图的过程解释两点:
candidate 在发现当前存在一个更大的 term(选举 leader 时使用的任期)的 server 作为 leader,则转为 follower;
leader 如果发现当前存在一个更大的 term 的 server 作为 leader,则可能是之前出现了 network partition,但由于更新的 leader 有多数承认,于是当前 leader 重选转为 follower;
其中 term(任期)代表的选举周期符合:
每个 term 总是从 candidate 发起一个 election 开始;
最终出现 split vote(平票/无法获得多数票,no leader)或者成功的 election;前者会立即新建一个 term 进行选举;
因此每个 leader 与唯一一个 term ID 相关联。这样做可以避免过时的信息传递。
此外,只有当 leader 与 followers 的 heart beat 断开后才发起一次选举。heart beat 的 timeout 太大,那么 leader 挂了后很久才能发现,降低了系统可用性;反之太小会造成频繁选举降低性能。
一般情况下 timeout 在 100~500 ms 内,需要根据网络情况微调。
选举过程:
将自身 follower 身份切换为 candidate;
增加当前 term ID;
为自己投票,并且向其他所有 servers 发送请求投票的 RPC,重试直到下列之一满足:
收到绝大多数票,则自身变为 leader;
收到当前更大 term 的 leader 的信息,则自身变为 follower;
election timeout/draw,重新开启一轮新的 term 进行选举;
值得注意的是,follower 收到投票的请求后,只有在请求的 term ID 比之前投过的都大,大于自身的 term ID,才能进行投票。确保 follower 在一个 term 中只投一次。
还有一个有趣的点,选举开始通常意味着 leader 挂了,因此如果所有 follower 同时开始成为 candidate,那么同时选举为 leader 会造成性能问题(大量冲突)。
因此我们可以对不同的 follower 使用不同的 timeout,保证它们大概率不会同时成为 candidate(有点像随机 TTL 防止缓存雪崩);
日志内容:
注意到我们对每个 entry 保留了 term 信息,主要用作 overwrite inconsistencies(后面介绍)。
并且 log entries 分为两类:committed 和 uncommitted,前者的 entries 不会再出现 overwrite,可以放心写入 RSM Log。
现在考虑出现 crash(network partition)的情况,说明为什么会出现 inconsistencies,以及何时 commit、何时 overwrite consistencies。下面的情况就会造成 xxx 指令并不是 committed 的。
因此我们说,inconsistencies 是不可避免的,只不过 raft 降低了后续恢复的成本(维护 prefix 的 consistency)。
下面我们阐述 Raft 在 consistency check 的过程中如何进行 overwrite inconsistencies、确认 committed entries 以及 entries replication;
我们首先以 Leader 的 Log 为 “真理”,follower 和 leader 不同时,认为 follower 是无效的。也就是说:
在 append entry 时,检查当前 prefix 与 followers 是否完全相同:
如果只有最后一个 entry 不相同,则进行 overwrite,然后再 append;
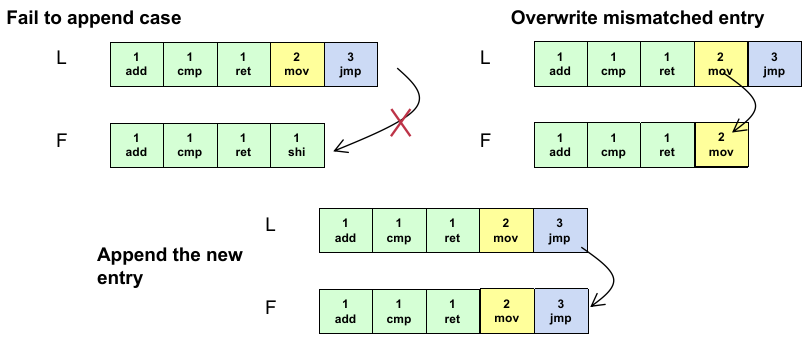
如果不一样的 entries 很多,则递归进行 overwrite,最后 append;
这种方法非常 “粗暴”,也会导致一个 entry 即便被多数 followers 写,也不见得就是 committed 的状态。如下:
但是,我们希望一个 entry 被多数 followers 写就是 committed 的,怎么办?
这就是 Raft 的 Safety,我们需要同时确保:
对 entries 的限制:日志 entry 是 committed 的就是多数 followers 写的 entry;
对 leader 的限制:之后选出的未来的 leaders 必须要以 committed entries 作为 prefix;
也就是说,在上面的问题中,
也就是选取 leader 的依据:
首先确保最近的 log entry 的 term 最大;
在 term 相同的情况下确保最近的 log entry 的数量最多;
这样上面的问题中,如果
那么,我们通过限制 leader 标准、划分 committed entries,实现了 safety 吗?可惜还没有。再考虑一个特例:
因此我们判断 committed 依据是,只有在处理当前 term
总结,选举 leader 需要检查 2 个方面:
检查 entries:确保最近一次的 log entry 的 term 最大;
检查 leader 新旧:在 term 相同的情况下确保该 term 中的 log entry 数量最多;
然后,上面两条仍然不能确保 raft 在 term N(最近一轮)的 safety(多数 followers 有相同的 entry 是 committed 的),只能确保 term N-1(本轮的上一轮)是 committed 的、可以刷盘的;
也就是说,只有当 term N 的 entry 获得多数接受并且进行 replica 时,term N-1 以及之前的 entry 才能视作 committed。
Chapter 2. Revisit: Network
OSI 7 层架构 & TCP/IP 4 层架构:
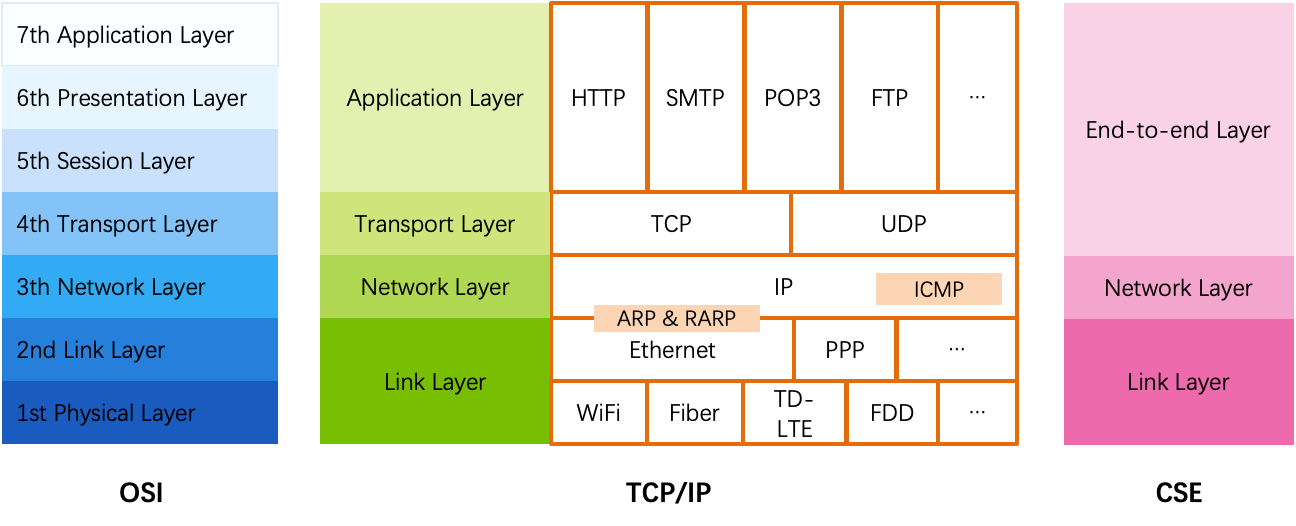
工程方面的实现,更多的是 TCP/IP 4 层架构;
2.1 Layers
Link Layer (Data Link Layer):两个节点间直接传输数据。因此此层的唯一目标就是如何将数据从一个节点传输到另一个节点;
ARP / MAC / Ethernet / PPP / Sonet, etc.
或者还有物理层:WIFI、Fiber、FDD, etc.
Network Layer:将中间节点需要的数据传给目标地点。通常情况下由 Link Layer 形成了网络拓扑图,图中的两个中间节点可能不直接相邻(没有 Link Layer 直连)。给定任意两个中间节点,找到一条最优路径将它们连接起来;
IP (v4/v6)、ICMP (ping);
End-to-end Layer:包装网络底层的信息、错误以及处理方案(错误处理如丢包重发、消息顺序),提供应用级别的抽象;
Application Layer:包装应用抽象,但一般已经不考虑为网络系统的部分,只作为协议/程序存在;
Transport Layer:这层引入了一个 name space: Port Number(可以复用连接,但是有限);
UDP / TCP;
处理 sender 和 receiver 的抽象;
保证两台机器不止可以建立一个连接(port);
如何稳定地在两台机器间建立连接(考虑丢包处理策略、第三人插入等等情况);
另外有些共识:
应该将网络做成笨拙的(更底层),还是智能的(包装很好,尤其是错误处理)?
人们设计时发现,丢包和性能相比,性能更重要。
并且人们希望由应用/端到端层来处理;
网络应该是黑盒,只对应用、硬件提供接口,使用者无需知道内部的信息;
packet encapsulation:
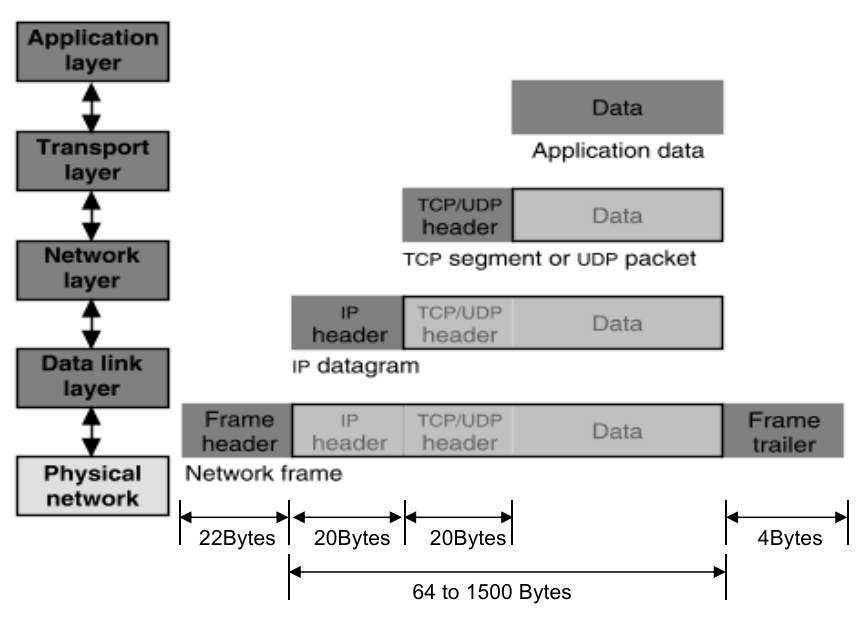
2.1.1 Link Layer
如何将数据从一个节点传给直接相邻的节点?考虑解决几个问题:
物理介质是什么?
如何让一个线路上尽可能多地负载数据流?
如何处理网络层间的约定?(如何解析/添加包头)
如何检测/处理在这个层中异常?
如何给上层提供可用接口?
我们考虑借鉴一些例子:
CPU 寄存器间数据传输?使用 Shared Clock(前提:传播可以在一个时钟周期内完成,否则没法衡量);
这种方法显然不能使用,因为直连物理节点间的距离可能很远;
能否用这个不借助 shared clock 的方案:
A 放数据、更改 ready 状态为 1;
B 收到 ready(耗时一个 propagation time)开始接受数据(读 data),处理好后,更改 ack 状态为 1;
A 发现 ack 为 1,更改 ready 状态为 0;同理 B 更改 ack 状态为 0,完成一次传递;
但是如果 propagation time 设为
因此人们为了提升传输效率,使用 parallel transmission 的思路:SCSI 接口(模仿硬盘数据传输)、printer 并口等等。
但是 parallel trans 有问题:
大部分情况下总有最慢的拖后腿,并且需要处理并发/同步问题,因此性能总是上不去;
多个数据并行传输过程中会相互干扰(物理效应);
因此人们考虑 serial trans(如 USB/SATA):
只在用一根线来传递数据(还可用另外的线传递其他信号);
不需要等待 receiver 响应;
更高的传输效率、更长距离、更少的数据线;
现在又有两个传递过程的问题:
传递过程中波形变形问题:VCO(压控振荡器);
VCO 可以从波形中恢复原始的时钟频率;
但 VCO 会锁定到一个 phase 中,如何区别连续的 1 / 连续的 0 发送的信息?
解决重复数据编码:
Manchester Code(
0 -> 01,1 -> 10),但应付1010交替的数据时容易出现频率丢失的情况。信息量 50%;8b/10bCode:每 8 bytes 拆 5/3 分,5 bytes 和 3 bytes 分别有 2 套映射方式(+/-,互为反码,每次选择相反的映射方式),信息量 80%;
现在看如何让一个线路上尽可能多地负载数据流(共享一根线)。
同步机制(Isochronous communication,也是早期电话线使用的方法):一根线先后发送定长数据;
但运营商考虑电话和网络使用两个机制成本较大,因此目前电话都使用的是另外一种方式;
不过像飞行编队间的通话就可以使用这种方法;
一根线分时复用,将 1s 分为 8000 个 frame,每个 frame 传递 8-bit 数据:
优点是能保证通话质量(无论是否说话,都会获得固定的 reserved 的信息);
缺点是限制同时通话数量(即使线路上不是所有人同时说话),更多的人(上例中是第 704 个人)则会被拒绝连接;
异步机制(Asynchronous communication):更加现代的数据传输方式。它是基于异步消息的传递:
并不是针对某个节点,而是在收集一定量来自各个节点的、目的地相同的数据后,打包发出去;
通常情况每个中间节点(这里以 switch 交换机为例),需要维护一个 buffer queue 用来存放当前从各个 clients 到达,但是没来得及处理 / 转发的数据包;
每个 frame 可以是任意长度、在链路空闲时发送。而 packet 就是变长的 frame + header 信息;
这时会出现问题:
两个包同时到达,如何排布在 buffer 中(考虑优先级就行)?
buffer 满了怎么办?告诉对方已满的情况也要占用带宽,而且没有回来的路。加大 buffer 大小?实践证明会导致问题更严重:
更大的 buffer 导致更长的队列、更长的处理时间、更多请求 timeout 但保留在 buffer 中,重发又留在 buffer 中,造成正反馈效应;
因此我们应该适当丢包,让对方知道当前网络拥塞,又能解决当前的燃眉之急。
frame 是任意长度、任意时间的,应该如何知道一连串 01 数据哪里是开头呢?
一种可行的解决方案是,让 frame 开头有 7 个 “1”,然后,数据包中一旦出现 6 个 “1”,则在第 6个 1 后面插入一个 0(你可能会问,如果在数据中出现
11111101应该怎么办?简单,再插入一个 0 变为111111001,因为这样解码时看到前面 6 个 1 就会删去这个添加的 0);
现在我们考虑错误处理(Bit Flip Error Handling):
首先,容错最本质的做法就是 “冗余”。如果有效的编码稀疏地落在巨大的编码空间中,只错 1 次或 2 次大概率就能发现是非法的。
因此我们引入编码数据的 “海明距离”(Hamming Distance)来衡量两个数据表示的相似程度,并且表示发生 bit flip 错误后可能落到的位置。
只要让有效的编码方式间距离的海明距离大一点,能发现更多次 bit flip 错误的可能性就更大。例如如果希望发现 2 次 bit flip 错误,那么可以让每两个有效编码的海明距离为 5 以上。
举例,一种最简单的 Simple Parity Check(奇偶校验)方法如下:
我们将 00 -> 000, 11 -> 110, 10 -> 101, 01 -> 011,也就是将原本编码空间扩大一倍,使得每两个有效编码间的海明距离由 1 变为 2(在编码空间中相距最远),这样新的编码就能识别 1-bit 的 flip error(但不能纠正);
另一种编码校验方式更强大一些,4B/7B 编码:

让每 4 bit 数据中的 3 bit 是异或计算出来的。只要某些地方发生了错误,就能利用等式信息反推出哪位出错(纠正能力)。
为什么规定如上的计算方法?因为可以发现,“Not-Match” 和 “Error” 的下标可以直接用加法计算,简化了硬件实现。
总结一下,这种方法能够:必定能发现、纠正 1-bit flip error、必定能发现 2-bit flip error、有概率发现 3-bit flip error;
缺点是数据利用率比较低(数据量扩大了 1 倍);
2.2 Network Layer
IP 协议使用的是 Best Effort Network 设计模式。除了 Best Effort,还有 Guaranteed-delivery:
Best-effort network:
If it cannot dispatch, may discard a packet;
Guaranteed-delivery network:
Also called store-and-forward network, no discarding data;
Work with complete messages rather than packets;
Use disk for buffering to handle peaks;
Tracks individual message to make sure none are lost;
现实生活中,很难满足完全 guaranteed,而且可能也不需要。
所以在 IP 协议中,定义了一些概念:
network attach points;
network address:在物理节点接入网络的 network AP 后,它会利用 DHCP 或者其他协议为节点分配一个网络地址;
Source & destination;
并定义了一些接口:
NETWORK_SEND (segment_buffer, destnation, network_protocol, end_layer_protocol);NETWORK_HANDLE (packet, network_protocol);
如何让 packet 在两个 network address 的设备间传递?这就是 network layer 需要完成的任务:Routing(路由)。
由于实际网口数量很多,因此我们需要一张表来记录指定的 IP Address 应该从哪个网口出去。
而且我们希望这张表可以不用手动维护。
因此 IP 协议分为两个部分:
Control Plane:设立规则、填表(routing algorithm);
Data Plane:根据规则转发数据,性能更重要;
2.2.1 Control Plane: Routing Algorithm
目标:
让网络中的所有交换机(执行 routing 转发的节点)知道:到某个目标节点
dst的路径;让网络中的所有交换机知道:到某个目标节点
dst的最短路径;在每个交换机中构建一个 routing table,使用
table[dst]表示到dst的最小路径长;
算法内容:
新加入的节点使用 Hello Protocol 告知邻居;
新加入的节点使用广播(advertisement)告知可达节点自己的相邻节点;
每个节点计算并决定到已知的、可达节点的最短路径和距离;
如何知晓两个可达节点间的最短路?两种算法:
Link-state protocol:将自己与邻居的直接距离传播出去(via flooding),接收到的节点更新距离并递归发送,直至网络中的所有节点都发送了一次;这样可以用 Dijkstra 算法得出特定节点到其他可达节点的最短路;
advertisement 中有什么:自己与邻居的距离(link costs);
谁会得到 advertisement:网络全体节点(flooding),因此这种方法在大规模网络中不适用;
结果:源点(自己)获得了到所有节点的最短路;
有节点挂了:容忍性强;
缺点:每个节点都进行
Distance-vector protocol:告诉邻居,自己到所有可达节点间的距离,并且反复几轮直至表格不再变化;这样可以使用 Bellman-Ford 算法更新两两节点间的最短路;
advertisement 中有什么:向邻居发送 所有自己知道、可达的节点(link costs);
谁会得到 advertisement:自己的邻居;
有节点挂了:会出现 Infinity Problem。解决方案是从哪里发过来的更新消息不允许原路返回;

缺点:需要详细考虑的 failure handling。而且当大规模网络变化速度快于方法的稳定速度时,还会无限进行下去;
综上,两种方法都没法应用在大规模、变化频繁的网络中。我们现在讨论如何进行 scaling。三种方法:
path-vector routing:类似 distance-vector,但是在 advertisement 时给出更全的路径
优点:减少路由表收敛所需要的轮数、避免 loop 造成无尽循环(拒绝广播含有自己的路径);虽然增加了传输信息的量,但是总体开销小于 link-state;
缺点:每个 attachment point 需要有一个唯一的标识,并且 path vector 会随着 attachment points 的增多而增多;
Hierarchy of Routing:可以解决 path-vector 的缺点,有点子网的思想。将问题拆分为小区域解决;
跨 region 时,可以采用 BGP(Border Gateway Protocol)来解决跨 region 的路由转发;
优点:大大压缩路由表大小,并且可以继续将继承关系 extend 到更大的 level,对 scaling 友好;
缺点:需要 address 和 location 绑定(一旦更换位置就需要更新 address)、算法可能没法得到最短路径(更少的信息);
Topological Addressing:配合 Hierarchy of Routing 的使用。由于 BGP 现在只能给到特定 IP 地址,没法选中 region 中的任意一个 IP。这个时候可以借助 CIDR notation(Classless Inter Domain Routing)表示连续的 IP address 块。
例如
18.0.0.0/24表示18.0.0.0 ~ 18.0.0.255的区域(于是它们也一般位于相近的物理位置);
2.2.2 Data Plane: Packet Forwarding
一个快点的网络包从查表到发出大约 100 cycles,而访存快的 100 多 cycles,慢的 200~300 cycles,这对系统有很大挑战。
xxxxxxxxxxstructure packet bit_string source bit_string destination bit_string end_protocol bit_string payload
procedure NETWORK_SEND (segment_buffer, destination, net_protocol, end_protocol) packet instance outgoing_packet outgoing_packet.payload <- segment_buffer outgoing_packet.end_protocol <- end_protocol outgoing_packet.source <- MY_NETWORK_ADDRESS outgoing_packet.destination <- destination NETWORK_HANDLE (outgoing_packet, net_protocol)
procedure NETWORK_HANDLE (net_packet, net_protocol) packet instance net_packet if net_packet.destination != MY_NETWORK_ADDRESS then next_hop <- LOOKUP (net_packet.destination, forwarding_table) LINK_SEND (net_packet, next_hop, link_protocol, net_protocol) else GIVE_TO_END_LAYER (net_packet.payload, net_packet.end_protocol, net_packet.source)
4 条路:
收包:
LOOKUP 给自己的:传给上层的 end-to-end layer;
LOOKUP 不是给自己的(可能是路由转发):直接调用 SEND 传出;
发包:
LOOKUP 给自己的(loop back,本地回环):传给上层的 end-to-end layer;
LOOKUP 不是给自己的:直接调用 SEND 传出;
corner case:
LOOKUP 没找到 next hop:直接将包丢掉;
每个网络包需要有 TTL(time-to-live),每经过一次路由器转发就递减一次(递减的时候需要更新 checksum,这很耗时,因此就出现了 Intel DPDK 的case,使用路由直接映射的内存,绕过 Kernel 轮询转发)。当接受的包的 TTL 为 0 的时候直接丢掉;
发送包方一般会设置一个 TTL(例如 ping 的时候可以设置
TTL)。
2.2.3 NAT: Network Address Translation
私网(内网)和公网:随着网络规模扩大,上面介绍的 IPv4 协议给出的 IP Address 已经不够用了。这应该怎么办!
人们的解决方案是接一个网关(Netgate):
这是在利用 NAT 网关自己的 IP 和 Port 作为 Proxy,并在 NAT 网关中存放映射关系(<内网 IP, 内网 Port> -> <NAT port>);
Quiz:计算一个 NAT 网关最多能承载内网中的多少台机器?
NAT 网关的承载上限就是 port 数量。
但这种设计破坏了网络层次化设计。因为在网络层需要知道上层的协议(Transfer Layer,Port),并且修改它(修改了 payload)。
所以有些协议就没法支持,例如:
IPSec(安全 IP 协议),因为 payload 会被加密;
FTP Active Mode Function:服务端可能会向 payload 写入 Server IP 信息,让 client 以后请求该地址(这也是破坏网络层次化的设计);
但是 Netgate 会 proxy server IP,导致 client 没法访问了(不走 NAT proxy 到不了内网)!
2.2.4 Ethernet Protocol & ARP
以太网,全称 载波监听冲突监测(Carrier Sense Multiple Access with Collision Detection,CSMA/CD)。

它提供了两种接口:
xxxxxxxxxxprocedure ETHERNET_HANDLE(net_packet, length):# Simple, can even be implemented in hardware# Pass the call along to the link layerdestination <- net_packet.target_idif destination = my_station_id or destination = BROADCAST_ID then GIVE_TO_END_LAYER (net_packet.data, net_packet.end_protocol, net_packet.source_id)else ignore packet
procedure ETHERNET_SEND:# Pass the call along to the link layerEthernet 有两种类型:
半双工 Ethernet:两次数据传输时间间隔最小需要 576 bit times。并且硬件实现时,需要在发送前监听线路,防止信息冲突;
如果出现冲突,则等待随机时间,如果第 2 次还不行,则指数级增长等待时间,依此类推;
全双工 Ethernet(点对点):不存在 collision,连接最大长度取决于物理介质;
以及两种拓扑构建方式:
集线器(Hub)式:一个 frame 会被广播到 hub 的所有的网口。所有网口共享整体带宽上限;
交换机(switch)式:记录设备的 MAC 地址映射,每个网关独享一个带宽上限;
Ethernet 是如何广播的?
由于 MAC 地址(Link Layer)实际上管控不严格,不同 Ethernet 中的 MAC 地址可以相同,甚至可以人为永久刷入新的 MAC;
例如 E 设备的 MAC 可以标识成 15(和 M 一样);
同样,和 Network Layer 一样,同样需要把 router 另一端接入的其他设备映射过来,这就是 ARP/RARP 协议。它在 Link Layer 中,将 IP Address 和 MAC 地址联系起来;
这个 ARP 表一般需要广播(Broadcast)建立;
举个例子:
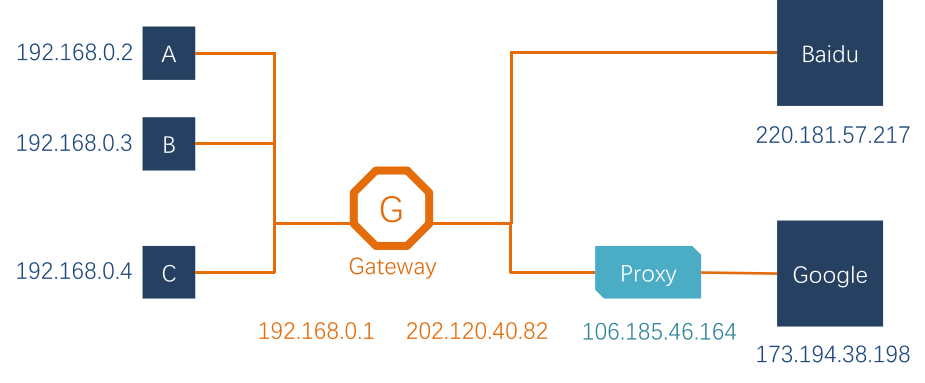
如果一个包需要从 C 传给 Baidu,过程如何?数据包头信息如何变化?




如上图过程,首先应用层给出目标 IP 地址(也可以是 hostname 然后通过一次 DNS lookup 得到),以及需要传输的数据;
然后 OS 无法在本地查询到 MAC 地址,使用 ARP 表找到应该交给局域网配置的 gateway(即 router-1),于是将 Target MAC 设为 gateway 并且 Source MAC 填成自己,方便后续消息回传工作;
数据包在 Link Layer 传给 gateway 后,它发现虽然 MAC 地址是给自己的,但 IP 地址并不是,意味着需要再次进行转发。gateway 查看它的 ARP Table,应该向 router-2 转发,因此将 Source MAC 改成自己的 MAC,Target MAC 改成 router-2 的 MAC;
因为 gateway 还是内网网关,因此通过 NAT 协议向外请求,此时还会修改 Source IP 为自身 IP、Port 为新的 gateway port,并将映射关系记录在 gateway 的 NAT 表中;
最终 router-2 收到 packet 后发现能够找到 Baidu MAC 地址了,因此最后将 Source MAC 改为自己的 MAC,Target MAC 改为 Baidu 的 MAC,成功将数据发送给 Baidu 了(不存在 NAT,因此没有更换 Source IP,还是 router-1);
如果是 A 传给 Google 呢?
上述例子中,我们发现两个 MAC 地址就能成功描述在 Ethernet 中的点到点的数据传输路径,比较方便。
ARP Spoofing(一种 Man-In-The-Middle Attack):
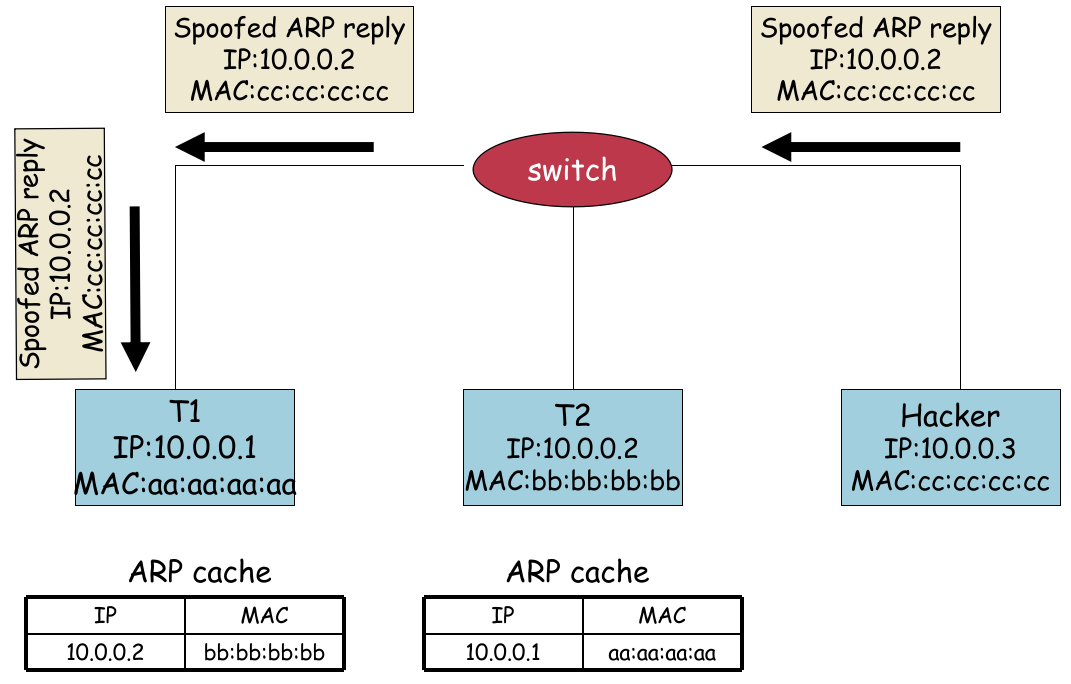
防御方法:
ARP Static Entries:特殊场合写死 IP-MAC 映射,只允许特定设备接入网络(例如军队中的管控);
ARP Watch:在网络中监听 ARP Broadcast 包,当出现流量异常(短时间、大量的 ARP broadcast,IP 不同但 MAC 相同),禁用这个相同的 MAC(通常是 hacker 的 MAC),也就是将攻击者的设备赶出网络;
但由于 ARP 协议本身的问题(任何人都能进行 broadcast),ARP Spoofing 本身没有违反协议的规则,因此上述防御方案治标不治本(例如通过减缓 ARP poisoning 的速度、只污染特定某个设备的 ARP,来规避第二种防御方案)。
2.3 End-to-End Layer
由于网络层不确保 Delay、Order of arrival、Certainty of arrival、Accuracy of content、Right place to deliver;
因此在 End-to-End Layer(Transfer Layer + Application Layer)可能需要处理上述部分或全部问题(因上层应用需求而定);
不过无论是 UDP/TCP/RTP,都没法完成一个方法通吃所有实际应用情况(有些实时应用需要速度而不需要保证丢包率,另一些则相反)。
因此 End-to-End Layer 需要确保:
Assurance of at-least-once delivery;
Assurance of at-most-once delivery;
Assurance of data integrity;
Assurance of stream order & closing of connections;
Assurance of jitter control;
Assurance of authenticity and privacy;
Assurance of end-to-end performance;
2.3.1 At Least Once Delivery
为了保证 “最少发到一次” 的性质,策略是:
Send packet with nonce(加密通信中的 随机数/伪随机数,用于防止旧数据的干扰,或者重放攻击);
Sender keeps a copy of the packet;
Receiver 收到后 ACK: Receiver acknowledges a packet with its nonce;
Sender timeout 重发: Resend if timeout before receiving acknowledge;
但我们需要解决以下问题:
没收到怎么办?
对方收到了,但 ACK 没传回来怎么办?
这两种问题没法区分。这个问题我们在确保 At Mose Once 的性质时就会解决。
在上述策略中,我们怎么知道丢包了?或者说,sender 如何发现 timeout?
fixed timer:设置固定的超时时间;但这样大量 client 的同步超时会拖垮服务器。工程上不是好选择;
adaptive timer:先测试当前 RTT,设置 timeout 为 150% 的当前 RTT 值;
在 Linux Kernel 中的设计方案:
xxxxxxxxxxProcedure calc_rtt(rtt_sample):rtt_avg = a*rtt_sample + (1-a)*rtt_avg; /* a = 1/8 */dev = absolute(rtt_sample – rtt_avg);rtt_dev = b*dev + (1-b)*rtt_dev; /* b = 1/4 */Procedure calc_timeout(rtt_avg, rtt_dev):Timeout = rtt_avg + 4*rtt_dev但是写死参数的方法也不优雅。
并且 adaptive timer 会存在指数时间尝试的现象(策略是每次 timeout 后超时时间大小翻倍);
NAK (Negative AcKnowledgment):
接收方负责统计收到的 segments 序列,发送 NAK 信息通知发送方 missing items;
如果发送方没有收到 NAK,可以默认数据传输是成功的;
因为接收方检测到问题时会立即发 NAK,不会因为数据错误而长时间沉默;
“sender set timer only once per stream”:即使发送方不为每个数据包设置定时器,它仍然需要为整个数据流(stream)设置一个单一的定时器,用来确保数据传输不会无限期地等待;
2.3.2 At Most Once Delivery
上面提到,现在的单次 ACK + timeout resend 的策略没法区分 “没收到” 和 “收到后 ACK 没传回” 的情况,这在某些情况下不允许的,因为有些应用不能容忍重复的网络包。这时我们需要让 End-to-End Layer 来选择性支持 at most once 的性质。
解决方案:
在 receiver side 维护一个 table of nonce;
问题是 table 会无限增大,并且永远无法删除(tombstones),会对空间和搜索时间有严重影响;
让 application 容忍重复的包(例如 NFS 的幂等性机制);但这会给 application 带来工作量;
还有几种解决方案:
Monotonically increasing sequence number(小于当前序列号的就算收过了):但 old nonce 变成 tombstones 了;
Use a different port for each new request:但 old port 变成 tombstones 而且不能复用了,更严重;
Accept the possibility of making a mistake(接受一定错误的概率):
如果约定 sender 总是在 5 倍 RTT 后抛弃没有收到的数据,那么 receiver 就可以抛弃在 5 倍 RTT 后生成的 nonce;
缺点:对于收到长于 5 倍 RTT 的数据就会出现问题;
此外,还可能存在一些问题:
receiver crash 或 restart 后会导致 table 丢失。这个时候可以考虑每次启动时使用与上次不同的端口;
总之,de-duplication 会给系统带来比较大的复杂度!
2.3.3 Data Integrity
如何确保 receiver 收到和 sender 相同的信息?
答案是 sender 在头部维护一个 checksum 信息校验,receiver 接收到后再次计算校验一下;
link layer 中也有 checksum,请问这里是否多余?
答案是不多余。因为可能会有其他错误,例如在 message copying 中出错;
但也不绝对保证数据完整性。例如,如果数据包 mis-delivery(送错或者丢包没发现问题),并且 receiver 仍然 ACK 了,那么可能出现问题;
2.3.4 Segments and Reassembly of Long Messages
End-to-End Layer 这个部分需要处理 “网络长数据分段和组装”,其中消息长度由 Application 决定,MTU 则由网络本身决定。
这样 message 本身的 ID,可以用在 at-least-once 和 at-most-once 中;
这里可能出现一些问题:
包乱序问题:可能与其他 message 缠在一起;
通常需要分配足够大的 buffer 来装下 message;
对于乱序问题,我们的解决方案有很多:
方法 1: receiver 只 ACK 有序的 packets,其他的丢弃?不行,浪费带宽;
方法 2: receiver ACK 每个 packet,并且将之前的 packet 保存在 buffer 中,当它们全部有序时 release?不行,需要很大的 buffer 空间;
方法 3:结合上述方法,先按方法 2 来,如果 buffer 快满了就按方法 1 来;
新问题:buffer 设置多大更好?
此外,如果想要加速,可以引入 NAK 来避免 timeout 情况;如果发现 NAK 导致 duplication,则停止这种策略;
2.3.5 Jitter Control
可以类比观看在线视频的情况,假设存在一个最长的时延,
但是某些实时场景,例如股票交易/游戏渲染,就没法使用这种方法了。
2.3.6 Authenticity and Privacy
我们还要考虑到 Internet 上的大多数资源是不可信的,可能存在恶意的 robot 或者 hacker 窃听或更改包的数据。
为此的解决方案是非对称加密。
2.3.7 Performance Improvement: Sliding Window
我们考虑现在我们已经设计的发包方式(segments):
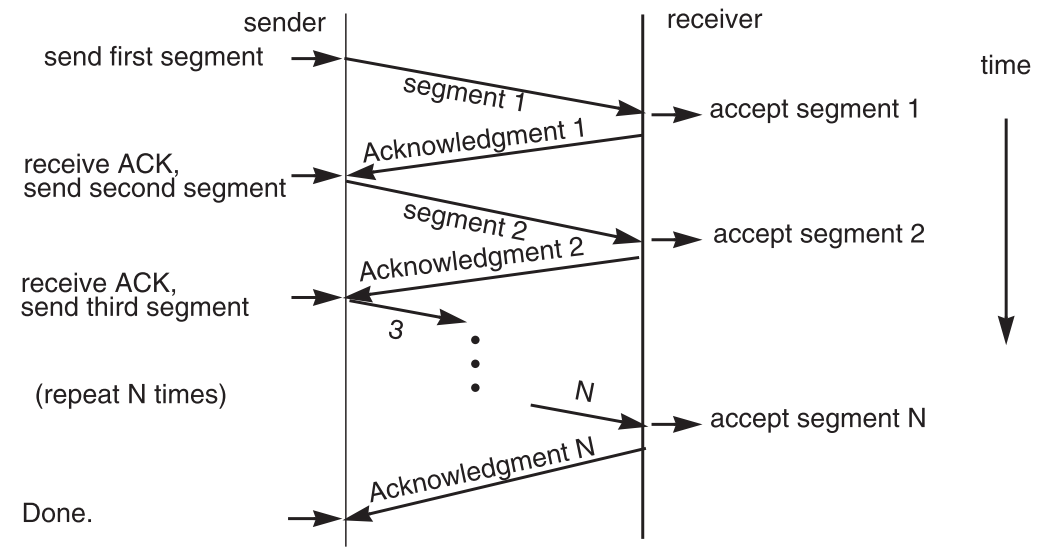
但是这种方式会引起性能问题,因为 Segment/ACK 发送、和接收到存在时延,如果每次都等待 ACK 再继续发送 segment,那么性能是不行的。
因此采用 overlapping transmission(pipeline style):
![]()
但不能真的不管了,因为这么做可能出现包丢失的问题。并且最好考虑到 receiver 的接受能力。因此人们想到了 fixed window 的设计:
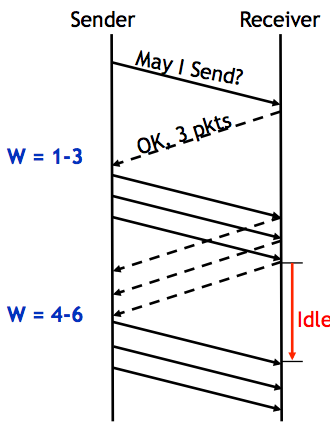
如果 N 个包任一个 ACK 超时,则 resend。
不过我们发现空闲时间还是很长,于是改进为 sliding window,充分利用等待时的资源:
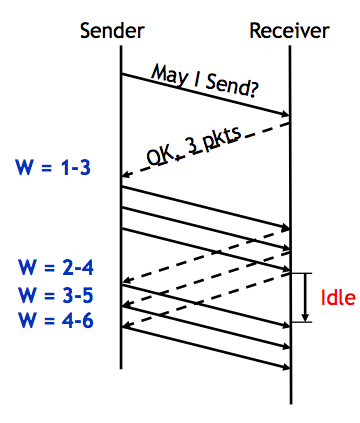
接受一个最前面的 packet,滑动窗口立即向前移动一位,这样能减小空闲时间。如果最前面的 packet 迟迟没有 ACK,则哪怕窗口后面的 packet 确认了,也等待在原地(保守的特性,因为一个网络故障可能意味这有 serious problems):
还有一个问题,滑动窗口的大小设为多少比较合适?
如果 window 太大,会导致网络拥塞(sender 一口气发送超过网络带宽能承受的上限的数据);如果 window 太小,会导致更长的空闲时间,没有充分利用网络资源。
如何科学地确定 window size 的大小,是其既不会出现网络拥塞,也不会出现资源浪费?这时候,就需要进行 TCP 的拥塞控制(congestion control)了。
2.3.8 TCP Congestion Control
拥塞的定义是,过多的 packet 同时出现在网络的一部分后导致延迟增大/丢包的现象,或导致 performance degraded;
要想处理网络拥塞,需要 network layer 和 end-to-end layer 协作处理:
network layer 会直接感受到拥塞的现象,最终决定如何对待过多的 packets;
end-to-end layer 则可以通过控制发送速率来高效地处理这个问题;
发生的原因,无非是 sender 发送过多的 packet 导致等待队列延长、时延增大。超过队列大小后发生丢包。
因此,我们从网络拥塞的原因中讨论 window size 的合理范围:
遵循 TCP 保守原则,我们设定 window size 为动态计算,并遵循以下原则:
Additive Increase:不存在丢包时,线性增加 window size(
+=);Multiplicative Decrease:认为丢包是一种很严重的事情,出现一次丢包,立即指数形式减小 window size(
/=);
上面的策略统称 AIMD;
针对这个策略进行改进,为了防止初始阶段(从 window size = 0 增长)过慢,在从 0 开始增长时以指数形式增长(*=)。这个改进被称为 slow start;
于是,在 AIMD + slow start 的改进策略下,一个网络的可能 window size 的变化如下:
注意到:
sender 收到 duplicated ACK,说明可能拥塞或丢包,因为可能情况如下:
packet 在到达 receiver 前丢了,receiver 看 timeout 还没收到就主动发送上一个 ACK 来催一下(同步一下);
或者 sender 因为没接收到 receiver 的 ACK(但实际上只是拥塞,等会才到)重发了一次;
上述 window size 波动幅度有点大,没有充分利用网络理论上最大承载量;
如果想让波动更贴近理论值(这会给网络更大压力,因为尖峰次数上升),称为 “更激进的策略”,就是 DC-TCP 的改进。这在数据中心常用,因为 DC 的网络比 Internet 的拓扑结构更稳定,理论值不会经常波动;
在另一个层面,我们可以从 sender 和 receiver 的 window sizes 两个维度更全面地检视一下 AIMD 策略。或者说,在多个 user 共享一个 router bottleneck 时如何确保网络资源占有的公平性(fairness):
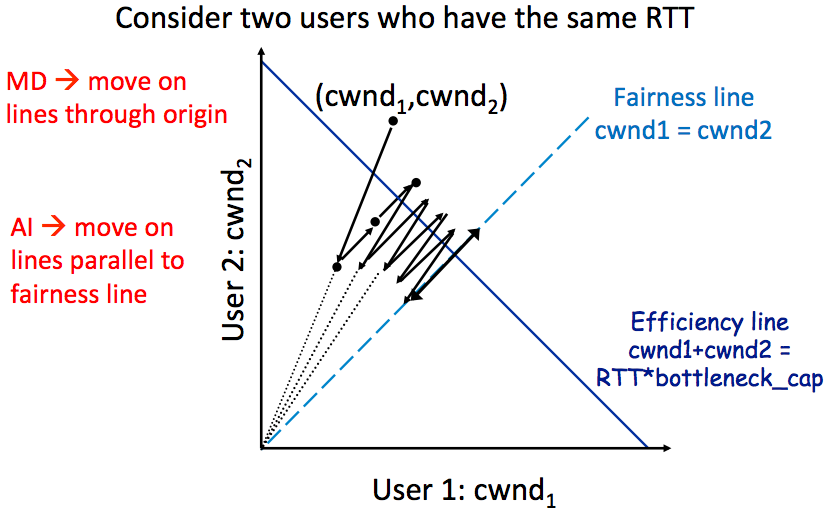
这就说明了 AIMD 强大的稳定性:即便 sender 和 receiver 最开始设定的 window size 不一样,也能通过多次调整来匹配它们的 window size,实现资源最大化,降低 receiver 丢包概率;
这也解释了为什么不用 Additive Decrease,因为 additive decrease 没法让双方 window size 较为稳定地保持在同样大小范围内;
2.3.9 Weakness & Summary of TCP
现在一个基础版本的 TCP 内容就介绍完全了,但不是在所有情况都适用的:
不是所有的 packet loss 都会有严重问题 / 由拥塞造成,例如无线网络中,可能是信号不好(因此初级阶段的 TCP 在 wifi 场景效果较差);
因此 MD 方法在这种情况下比较保守,不是最优的,而且在无线情况下会造成恶性循环(总是因为丢包就导致 window size drop 到 0,这种因为网络信号原因的丢包相反应该多发一点!);
普通版本的 TCP 不适用于 data center 这种高带宽、低时延、低变动性的情况。应该使用 DC-TCP(参见上文);
普通版本的 TCP 只以 TTL 为核心考虑的因素,如果真的单纯因为物理距离原因 TTL 比较高,但网络并不拥塞,则不应该武断地下调 window size,这会导致性能问题;
总结:
window size(
拥塞控制需要保证:
普通 TCP 使用 AIMD + slow start 的策略尽量保证动态的 window size 的适应,以灵活应对网络拥塞的情况;
可以根据实际工程情况进行调整和 tuning,例如 DC-TCP;
2.4 Yet Another Protocol in End-to-End Layer: DNS
2.4.1 Definitions
DNS(域名解析服务),不存在它,网络也能 work。不过它也有作用:
human readable(semantic);
load balance;
特性:
一个域名可以对应多个 IP;
根据物理节点的远近进行分配,load balance;
一个 IP 地址可以有多个域名;
多个服务 / 网站共享一个物理服务器(server consolidation);
2.4.2 Look-up Algorithm
最开始,人们使用 hosts.txt 来保存 address binding(domain name 到 IP address 的映射);
注:现在还在同时使用这个文件,具体做法参见后面的算法。
但是 scalable 不能适应网络的发展,于是出现了一个沿用至今的系统:Berkeley Internet Name Domain(BIND);
还有,由于域名太多,因此人们采用了分级架构(顶级/二级/三级 域名),每级的特定域名可以由特定组织/个人来负责。
显然,DNS 可以 cache 下来,减小查询时延。我们现在讨论一台机器没有 cache 任何 DNS 记录的情况下,查询 ipads.se.sjtu.edu.cn 的情况:
因此一个新的机器只需要记住 root 节点所在的 DNS server 的 IP 地址就行了。
现在我们来看 DNS 有 cache 的情况,它是如何设计的?
在本地机器上保留的
/etc/hosts(windows 上请自行搜索),直接定义当前机器范围内可以定义的 domain name - IP 的映射;在本地机器上存在
/etc/resolv.conf指定可以查找的 DNS server(例如8.8.8.8是 Google 提供的 DNS server,可以让机器查询 root);除了用本机写的 DNS server,在连上某些无线网时,可能会自动给机器推一个 DNS server(由这个无线网管理员配置的);
本地机器的 OS、甚至浏览器自己会进行 cache;
DNS server cache:在委托请求(recursion query)的 DNS server 中也存在 cache;
为什么不用 non-recursion 的方式?因为 client 的网络效率可能没有 server 的好。例如 client 本身的 packet 还需要出层层的局域网才能到公网;
上述 cache(浏览器/OS/DNS server cache)存在过期时间,称为 TTL(time-to-live),通常管理 DNS server 的人 / OS 或浏览器的配置可以控制各自的 DNS 解析 cache 的 TTL;

2.4.3 Design Pattern of DNS
是什么使得,在网络即便扩大几十万倍的情况下,仍然只需通过 replicas 就能维持可用性?
Benefits of Hierarchy Design(分布式取中心化的设计)
Hierarchies delegate responsibility;
Each zone is only responsible for a small portion;
Hierarchies also limit interaction between modules;
Global names(无歧义)
No need to specific a context;
DNS has no trouble generating unique names;
The name can also be user-friendly;
Scalable in Performance
Simplicity: look-up is simple and can be done by a PC;
Caching: reduce number of total queries;
Delegation: many name severs handle lookups;
Scalable in Management
Each zone makes its own policy decision on binding(Hierarchy is great here);
Fault Tolerance
If one name server breaks, other will still work;
Duplicated name server for a same zone;
但是也有一些问题:
Policy(非技术原因,可能是政治政策);
仍然依靠 Root servers:
甚至频繁发起对不存在 domain name 的请求,可能成为 DoS Attack;
Security: Client 如何知道响应是正确的(恶意攻击方);
证书机制、靠谱的 DNS server;
2.5 Naming Scheme
讨论比较抽象的理论。人们是如何通过命名机制建立起模块化系统的?
我们回想,email address name/phone number、之前的提到的 hostname、x86 register name、language function name、file path name、URL/URI、IP address,等等;
我们以磁盘为例,Linux 是如何将文件和磁盘联系起来?就是通过 naming 的层次实现:
file name: /dev/sda1(特殊 device inode);
硬件注册了 PCI address name,例如
19:00.0(SCSI Storage Controller);
总结一下 Naming 如何支持模块化(在什么时候使用):
Retrieval:例如使用 URL 获取 web page;
Sharing:(如变量名)向函数传递一个对象的引用,还能节省空间(发送名称而非对象本身);
Hiding:(如文件名)将底层文件系统的细节向上隐藏(可以做访问权限控制);
User-friendly identifiers;
Indirection:
(如寄存器名)寄存器重命名(renaming)将一个
%rax符号映射到多个实际寄存器,提升并发性能;(如电话号码)提供虚拟号码保护隐私;
(如面向对象语言的类名)同一个类名中存在不同实现;
并且可以只通过修改映射,而无需通知上层机构;
其中,我们注意一种特殊的 name: address,它们是软件用于表示有关物理信息的标识,它通常不仅仅作为 “name”,还有实际的含义(作为 “value”);
于是,naming 的抽象模型如下:
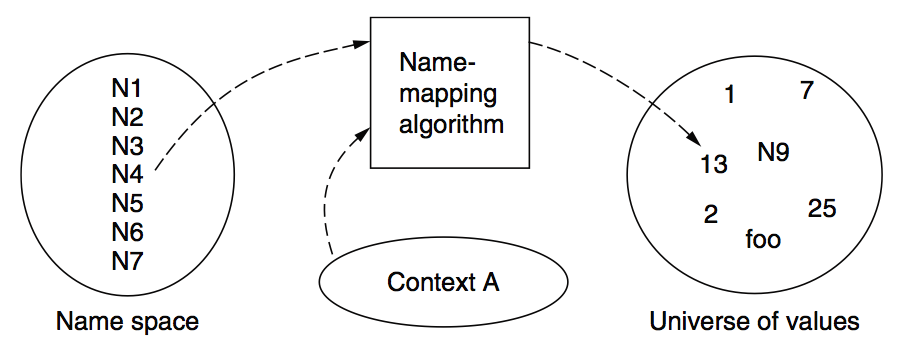
Context:例如 CSE 的老师说 lab-1 一般是指 CSE 的 lab-1 而非 Compiler 的 lab-1;
但 Context 不必要,例如 URL/URI,它具有全球统一的性质;
我们将上面 “只有一种可能的 context” 的情况称为 universal name spaces(例如 UUID、信用卡号、email address 、URI/URL等等);
但有些 naming 就需要,例如 file name,我们在 OS 中使用
$PATH来指定 context;
naming terminology 也对应了一组标准操作:
binding:将 name 和 value 映射起来(将一个存在映射的 name 称 “已经被绑定了 (bound)”);
lookup algorithm(name mapping algorithm):查询 binding 并返回;
table lookup;
recursive lookup:例如
/usr/bin/ls的文件系统 lookup;multiple lookup:例如
$PATH的搜索(多个 context);
API:
value <- RESOLVE(name, context):Return the mapping of name in the context;
status <- BIND(name, value, context):Establish a name to value mapping in the context;
status <- UNBIND(name, context):Delete name from context;
list <- ENUMERATE(context):Return a list of all bindings;
result <- COMPARE(name1, name2):Check ifname1andname2are equal;Q&A:
What is the syntax of names?
What are the possible value?
What context is used to resolve names?
Who specifies the context?
Is a particular name global (context-free) or local?
Does every name have a value? Or, can you have “dangling” names? (a name without any value)
Can a single name have multiple values?
Does every value have a name? Or, can you name everything?
Can a single value have multiple names? Or, are there synonyms?
Can the value corresponding to a name change over time?
2.6 CDN
Server Selection Mechanism:
HTTP Redirection:
优点:细粒度控制、Selection based on client IP address;
缺点:Extra round-trips for TCP connection to server、Overhead on the server;
Anycast Routing:
优点:没有额外的 round trip、能被路由到最近的 server;
缺点:没有考虑到 network/server 的负载,只能应对没有状态/单次请求的应用;
DNS-based server selection:
优点:
Avoid TCP set-up delay;
DNS caching reduces overhead;
Relatively fine control;
缺点:
Based on IP address of local DNS server;
“Hidden load” effect(存在连续加载的问题,例如 global -> regional -> nearby cluster);
DNS TTL limits adaptation;
2.7 P2P Network (End-to-End Layer Protocol)
P2P 网络面临的挑战:
整个 P2P 网络中到底有多少节点存了多少对象?
怎么找到其他人呢?
不同数据在节点之间怎么 spilt 呢?
数据有没有可能放在某个节点,某个节点挂了就丢了呢?
保证 consistency;
保证 security;
为了避免中心化网络的弊端:
Centralized point of failure;
High management costs;
If one org has to host millions of files, etc.
Not suitable for many scenarios;
E.g., cooperation between you and me;
Lack ability to aggregate clients;
人们使用了 Cooperative 的设计思路:
User downloads file from someone using simple user interface;
While downloading, BitTorrent serves file also to others;
BitTorrent keeps running for a little while after download completes;
区分 3 个角色:
Tracker:记录 peers 分别有文件的哪些部分(起到一定中心化的作用);
Seeder:文件块的所有者;
Peer:向存在 “需要请求的文件块” 的 seeder 发送接收请求;
然后需要一个中心化的 server(至少域名是中心化的)发布 tracker 的位置;
这个发布方法可以通过 .torrent 种子文件完成,其中就会包含 tracker URL、文件 (块) 的元数据(例如文件大小、名称、Hash 等等);
下载不同文件块的顺序由什么决定?
Strict? Rarest first? Random? Parallel?
BitTorrent: Random for the first one, Rarest first for the rest, Parallel for the last one;
于是 P2P 的缺点显而易见:Tracker 作为中心化组件,torrents 没法大规模 scale;
不过可以进行 scalable lookup: DHT(distributed hash table),让 bindings 存在于不同的物理节点上(因为一台 server 保存不高效,也无法实现高可用),并且实现下面的接口:
put(K, V)、get(K)、Loose guarantees about keeping data alive(允许一些节点是离线的);
P2P 如何实现 DHT?我们需要在找到两个机器间通路的同时(某个资源的 peer 到 seeder 的通路)确保 load balance 和
答案是一致性 hash(Chord 算法)。
保存方法:将机器的唯一标识(例如
MAC/IP/HOSTNAME等信息)以及需要缓存的 KV 都 hash 到环上(相同的 ID space),使用查找算法规定的方法来保存数据;Simple Lookup Algorithm(正确性只由 successor 保证):
xxxxxxxxxxprocedure Lookup(my-id, key-id):n = my successorif my-id < n < key-idcall Lookup(id) on node n // next hop (successor)elsereturn my successor // done但简单算法最坏
Finger Table 保存方法(一半范围一半范围地记):
Finger Table Lookup Algorithm:
xxxxxxxxxxprocedure Lookup(my-id, key-id):look in local finger table forhighest node n s.t. my-id < n < key-idif n existscall Lookup(id) on node n // next hopelsereturn my successor // doneFailure Tolerance:如果有结点挂掉,并且还使用 finger table 的查找算法,那么会出现找漏掉的情况;
为了防止这种情况出现,我们引入 successor lists(结合前面的两种算法):
每个结点保存
某个结点下线后,需要维护当前列表,当前结点会从表中知道第一个存活的结点信息;
并且查找时尽量避免直接跳过;
总结一下:
consistent hashing 可以这么实现:
我们先按照常用的 hash 算法将 Key hash 到
将机器的唯一标识(例如
MAC/IP/HOSTNAME等信息)以及需要缓存的 KV 都 hash 到环上;于是就能判断信息究竟放在哪一台服务器上了:按顺时针方向,所有对象 hash 的位置距离最近的机器 hash 点就是要存的机器,如下图所示:
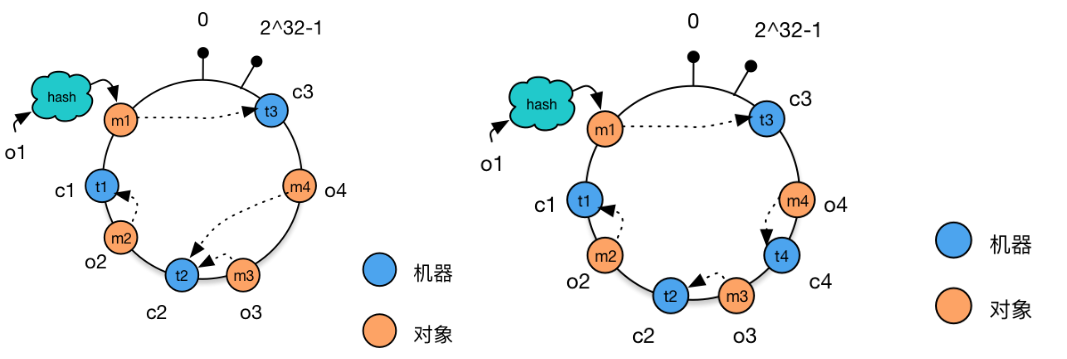
当有机器(
t4)加入分布式集群后,t3 - t4间的缓存将转移至t4上(少量数据交换);反之,有机器(
t4)从分布式集群中离线后,t3 - t4间的缓存将重新转移至t2;
这样的方案能在分布式场景下尽可能减少缓存失效和变动的比例;
但这种方案仍然存在问题:当集群中的节点数量较少时,可能会出现节点在哈希空间中分布不平衡的问题(hash 环的倾斜和负载不均),甚至引发雪崩问题(最多数据的 A 故障,全转移给 B,然后 B 故障,并重复下去,造成整个分布式集群崩溃)。
解决 hash 环倾斜的问题的方案之一就是引入 “虚拟节点”(相当于给机器 hash 点创建 “软链接”),将 virtual nodes 和 real nodes 的映射关系记录在 Hash Ring 中;
Chapter 3. Distributed Computing & Programming
现在我们回顾一下,我们已经讨论过的在一个云 OS 可能用到的分布式机制:
文件系统:Distributed File System(如 GFS);
分布式计算和任务调度:如 MapReduce;
数据存储:KV Store(如 BigTable);
内存管理:和具体项目有关。例如 GaussDB 将 RDMA 和硬件的特性相结合;
现在,我们想要考虑 “分布式计算和任务调度”,也就是说,我们在分布式环境上如何实现并行的、高效的调度和计算?
这就是 MapReduce 需要考虑的事,本章我们将讨论 MapReduce 的实现案例。
先关注一些基本概念。
3.1 Parallelism on Single Chip Device
如何 scale 一个 Single Chip Device 的计算能力?答案是并行。
单机并行的 3 种方案:
Single core+: pipeline + super scalar with instruction level parallelism (ILP);
策略:More efficient pipeline design & implementation, e.g., reduce bubble stall
Faster clock rate、Exploiting wider instruction-level parallelism (ILP), e.g., issue 4 instructions / cycle;
Single core++: added SIMD support;
Multiple core: a single core (single core, single core+, single core++) can be glued together !
如何实现 multiple core?
add more physical cores + 编写多线程程序充分利用;
问题:memory coherence。回忆一下什么是 cache coherence protocols。
在多处理器系统中,很多情况下多个进程可能需要一些相同内存块。主要由于:
可写数据共享,例如两个进程通过
mmap共享一块匿名页或文件页;多核间进程调度(process migration)/ 线程调度;
……
那么需要 cache 做一些统一措施,确保多进程能看到的数据是一致的。
实现这个协议有两类思路:directory-based 和 snooping;
前者提出将一块物理内存的共享状态存放在特定的位置(称为 “directory”,不宜译为目录);
注意到 directory 策略的 shared directory 就是性能瓶颈所在;
后者设计比前者简单,提出对 CPU Cache 的共享总线进行侦测,如果侦测到总线上的操作与当前中的某个 block 相符 (tag一致),则采取某种动作(具体动作由具体的实现决定,比如 MSI),这种系统需要支持广播功能的总线。
注意到 snoops 的次数和核数成线性正比。
因为 memory coherence 的问题,通常 CPU 的核心数不会无限制增长,需要作出一些妥协。例如 ARM CPU 有的可以达到 64 核,但是开发者需要手动添加 barriers 来确保上一轮修改能被其他核的程序所看见。
increase per-core density(提升单核的 ALU 数量):我们观察到大数据计算意味着处理大量数据,而数据计算指令是相似的。因此我们通过提升单核 ALU 数量,引入 SIMD(single instruction multiple data)将相同的指令、不同数据部分广播到多个 ALU 中并行执行,能够极大提升数据处理效率。
之所以是 single instruction 而不是多个指令,因为在处理 pre-ALU 阶段的指令流会遇到瓶颈。
为了提升并行计算能力,除了上面对于多核并行的探索以外,还有一个重要的方向需要优化和挖掘:访存。
因为除了单机的核数,并行计算的性能还可能被 memory stall 所限制(100 cycles ~)。你可能会说,我们可以根据 locality 进行指令 prefetch。但是在内存读写是主要瓶颈的时候,指令 prefetch 并不总是可行的。
为了刻画访存这个方面的瓶颈,我们引入一些 metrics:
memory latency:从处理器请求(例如 load/store)到内存系统完成动作间,内存请求消耗的时间;
数量级:DRAM 100 cycles,本地数据中心的网络中的话大约 1 us;
memory (storage) bandwidth:内存系统单位时间能向处理器传输数据的最大大小。
数量级:网络的话 20 Gbps;
因此数据加载时间为:latency + payload / bandwidth;
注意几个方面:
这是最理想的情况。实际上 latency 和 bandwidth 会被其他物理因素影响;
如果是 CPU load/store 场景,瓶颈可能在 latency,而在大数据量传输的场景,瓶颈可能在 bandwidth 上;
Roofline Model(刻画应用对访存和算力的需求):
y 轴:刻画机器的访存能力(超过证明算力不足);
x 轴:刻画应用每进行一次符点操作 (flop) 需要取多少 Bytes 的数据(取数据频率,即 operational indensity,OI);
这样我们可以表示设备带宽:
于是我们有了优化的方向:只要给定一个应用在每次内存读取时的 FLOPs 次数,我们就能根据硬件的 roofline model 来判断应用是 computation bound 还是 memory bound;
另外,仅仅有 SIMD 是不足够的,因为太过 low-level 了,如果我们想要对向量计算 ReLU 函数,就需要分支预测,并且每个 SIMD ALU 会共享同一个 Program Counter,这就没法充分利用 SIMD 的优势。
那么我们能否让 SIMD 指令表达 conditional branch 的策略(例如 conditional vector add)?
解决方案是 masked instruction:
每个 branch 都串行计算一遍;
使用 mask 决定 enable 哪些 ALUs 来执行哪个分支;
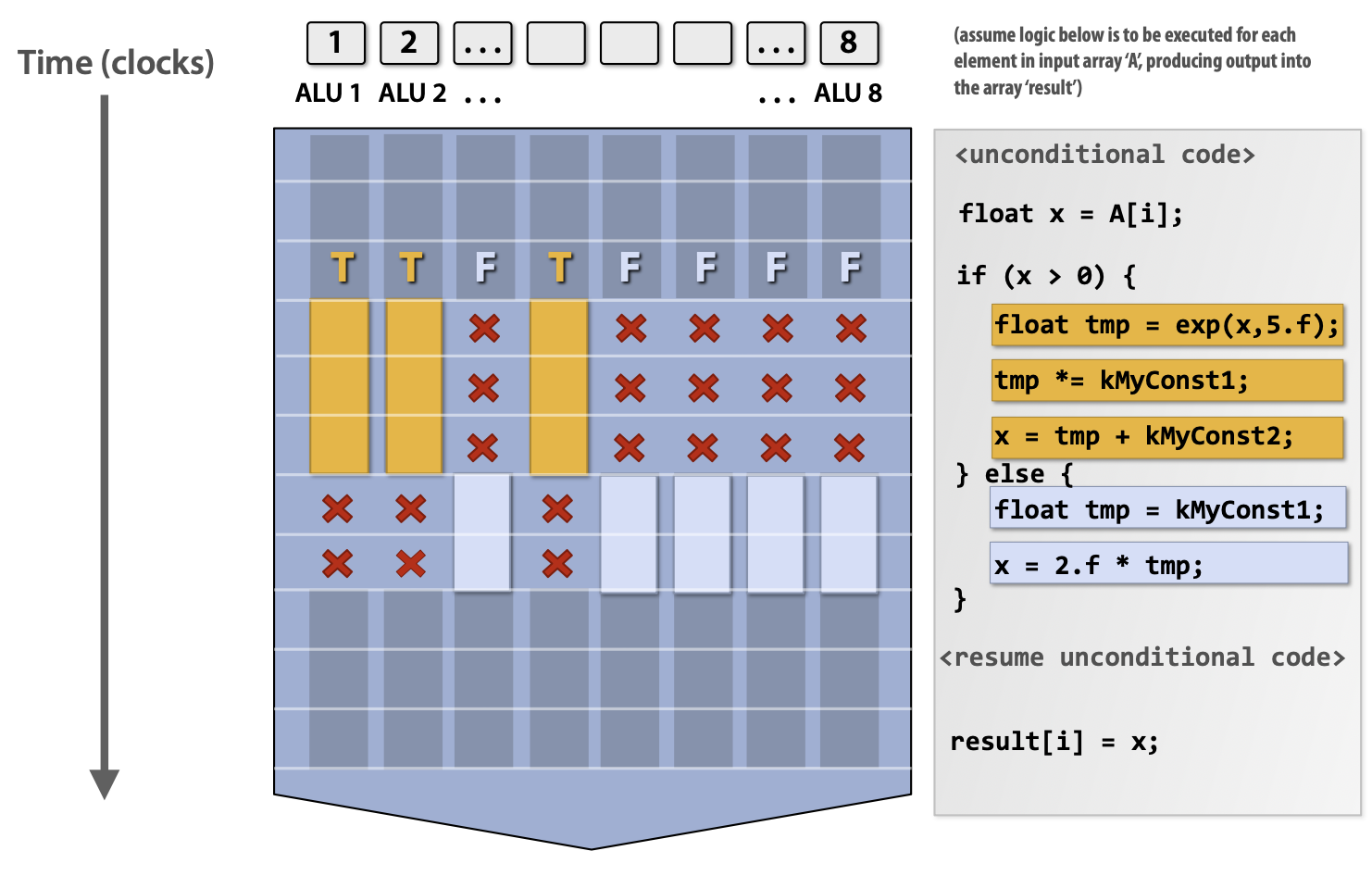
缺点是存在分支时,没法使用全部的 ALUs(每个分支间串行),浪费计算资源。并且分支很多时,性能不好。
基于上面的 CPU 缺陷,人们在 GPU 上引入了一个编程模式(Nvidia)SIMT(Single Instruction Multiple Thread);
SIMT 不是一个硬件实现,而是一种并行抽象。
threads 会被分组为 thread block,每个 block 中的 threads 可以同步执行,每个 block 会被映射到一个 GPU 核心上进行计算任务。
开发者只需要为一个 thread 写一个 C 程序,就能让一个 thread block 中的所有 threads 同时执行相同的代码,但是可以执行不同的 conditional branch!
这样 SIMT 可以帮助我们实现:
只需添加一些声明(例如
__global)就能利用多核资源;支持底层的 conditional branches;
不再需要手动编写 low-level 的 AVX 指令;
享受 GPU 高 bandwidth、没有 cache coherence 的性能优势;
……
例如 CUDA 就是使用这种思想。
general-purpose vs specification calculation (Domain Specific Language): Trade Off
我们还注意到 GPU 实际上不需要关心 cache coherence 的问题,因此它们可以有很多核、很多的 ALU。此外 GPU 还没有 branch predictor,实际上在 general-purpose computing 和其他功能方面作出了权衡。
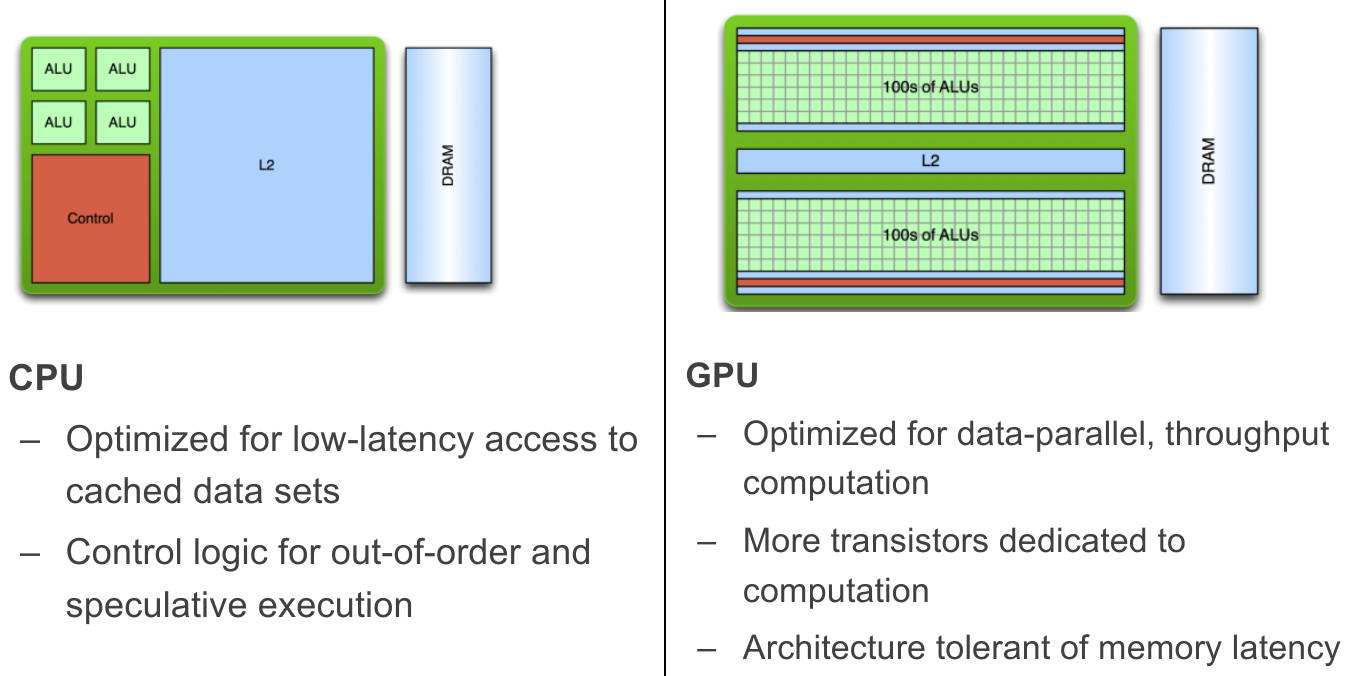
在考虑 general-purpose 和 specification 计算的上限时,最终会落到单机芯片的主频(物理限制)。
也就是说,有很多计算任务只由一台机器是没法解决的。我们需要模仿应用层面的做法:建立计算集群;
3.2 Distributed Computing Framework: MapReduce
3.2.1 Definitions: Batch Processing
为了应对不同类型的应用场景(complex queries),人们发展了不同类型的分布式计算框架。现在我们先聚焦于 batch process system;
考虑一个场景:我希望处理一个超大级别文件的文本内容,例如:
xxxxxxxxxxcat /var/log/nginx/access.log \ | awk '{print $7}' \ | sort \ | uniq -c \ | sort -r -n \ | head -n 5除了第一个 cat 指令可以用分布式文件系统进行 scale,其他几个顺序的指令都会被单机单线程计算能力和 DRAM 承载能力所限制。
这可以用分布式计算的思想进行优化,利用 RPC 把数据分散到多台机器(map),计算完成后在将结果汇总到一台机器(reduce);
这个实现会面临一些挑战(或者说编程者需要额外考虑的):
Sending data to/from nodes:发送和接收 RPC;
Coordinating among nodes:结点间 reduce 时需要考虑同步机制等等;
Recovering from node failure:需要保证 failure tolerance;
Optimizing for locality:在网络间传输数据经常慢于本地数据的访问;
Partition data to to enable more parallelism:如何对任务进行合理的 partition 来充分利用计算资源,以突破串行执行的性能瓶颈?
在以前一个分布式计算的应用通常是需要手动处理,就算上述问题得到解决,那么这些代码也会和具体的业务逻辑紧耦合,缺乏可维护性和可扩展性。
于是人们开发了 MapReduce 框架,用以应对:
将具体计算的业务逻辑和并行计算的上述挑战和要求解耦;
Map 和 Reduce 间自动 handle 数据传输;
MapReduce 本身的语义能确保同步(schedule reducers after the mappers);
node failure 通过 re-execution 来恢复;
为了充分利用 locality,通常有策略把 map 和 reduce 调度到同一机器上;
将输入数据分区(partition)提升数据并行性;
常见的使用场景有:
Distributed grep: Search for words in lots of documents;
Count URL access frequency: Find the frequency of each URL in web logs;
Inverted index: Find what documents contain a specific word;
Reverse web-link graph: Find where page links come from(Map: output
<target, source>for each link to target in a page source;Reduce: concatenate all source for each target, output<target, list(source)>);
3.2.2 Overview
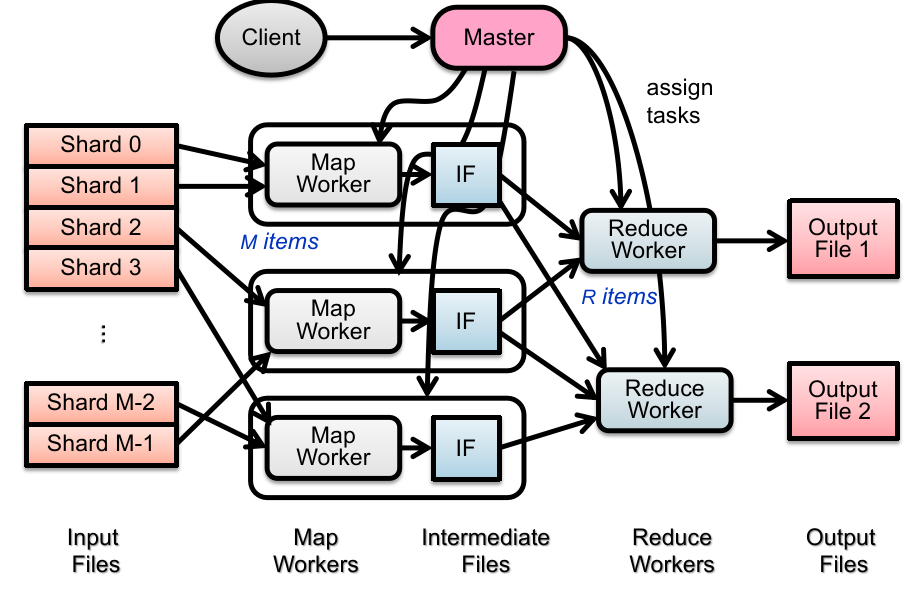
MapReduce 的接口语义是:
Map:将 input shards 按照用户指定的 function 映射到一系列中间结果(kv pairs)
先将输入数据分区为 M 份 shards;
再按照用户给定的 map function 处理输入,生成 key 和对应的 value;
将 kv pairs 按照 key 分组、hash,并放到中间文件(intermediate files)的不同 partition 中,传递给后面的 reducers。
注意:相同的 partition 需要进行 sort,方便 reduce 阶段处理;
Reduce:将不同 workers 的中间文件中的 kv pair partitions 读入、整理,使用用户定义的 reduce function 整合成最终结果,返回;
利用 keyspace 对自己需要的 keys 进行 hash(和 map 相同的 partition function),再从不同 workers 的中间文件抓取特定 key 相应 partition,然后 sort、merge;
由于 map 已经对每个 partition 完成 sort 了,因此这里的 sort 相当于 merge sort,非常高效;
对获取结果按 reduce function 处理然后返回;
用户只需要关心分布式计算的业务逻辑就行,其他的全部交给 map reduce 框架!
3.2.3 Implementation
(Client/Master) split input files into chunks (shards)
通常情况是 64 MB(可以 fit GFS chunk size,方便 RPC 读 chunk);

(remote) fork processes:
1 master: scheduler & coordinator;
lots of workers:每个空闲 workers 被分配 map tasks(each work on a shard)或者 reduce tasks(each work on intermediate files);
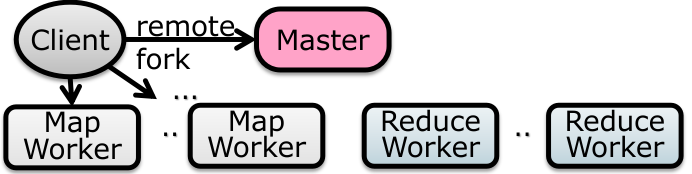
(mappers) map task:
从被分配的 input shard 中读取内容;
parse key-value pairs;
执行用户指定的 map function,生成中间 key-value pairs(buffered in memory);
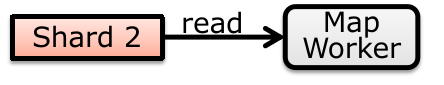
(mappers) create intermediate files:
将 buffered in memory 的 intermediate key-value pairs 定期落盘;
其中每个 key-value pair 被 partition function 分到
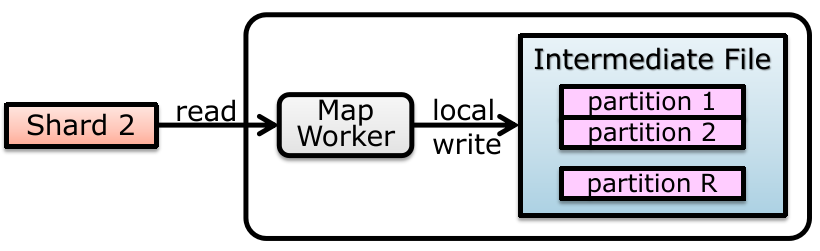
(reducers) sorting intermediate data:
接收 master 关于 intermediate files 的不同分区位置的提醒;
使用 RPC 从 map workers 中读取文件内容;
将从不同 intermediate files 中 sort keys(类似 merge sort,因为 mappers 和 reducers 都会做排序);
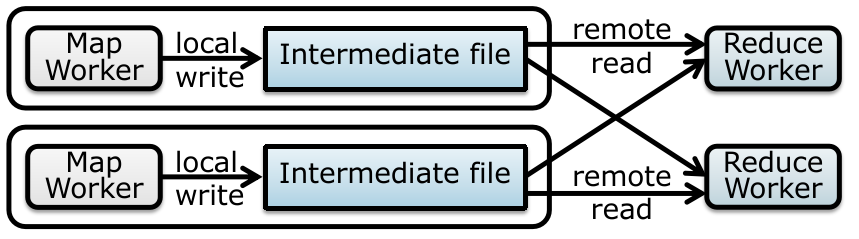
(reducers) reduce tasks
按 unique intermediate key 来为数据分组;
执行用户指定的 reduce function,按指定的 key 对多个数据进行 reduce;
输出到一个 output file 中;
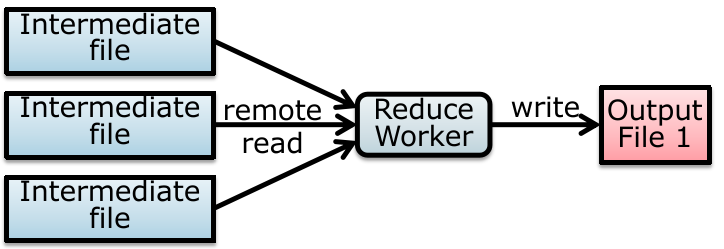
(Client/Master) return to user
当所有 map/reduce 任务完成后,master 唤醒用户程序;
结果将存放在
3.2.4 Fault Tolerance
总之我们现在已经完成的部分:
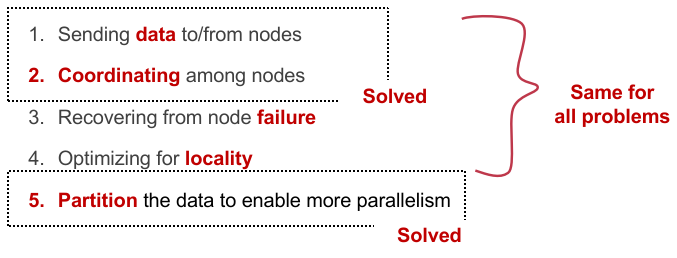
考虑我们如何解决 fault tolerance 的问题(machine failure 很常见的问题);
retry(幂等的情况。本身 MapReduce 编程模型循环简化了此过程);
a map or a reduce can simply re-execute the computation to recover from failures;
建立在 reliable task 基础上(例如 GFS);
我们分别看 worker 和 master 的情况。
worker:
detection(master ping worker via heartbit)。如果发送请求后的一定时间没有响应(timeout),则 master 认为这个 worker 出现 failure;
recovery:传递给这个 client 的任务请求,将中途计算的 map 和 reduce 重置,并重新调度给其他的 worker(re-execution);
robost: 即便 1800 机器挂了 1600 台,仍然能够正常完成任务;
master: 没法直接通过 re-execution 恢复。另外,master 只有一个,出现 failure 的可能性很小,并且我们可以引入 replicas 和分布式协调服务,让服务高可用性的同时对外呈现一个 master 的特征。
master 的状态保存在 GFS 中,因此可以直接从 GFS 中恢复;
状态包括:每个 mapper/reducer 的执行状态(空闲、完成、正在处理)、每个中间文件的位置;
并且可以周期性地向 GFS 进行 checkpoint,保证不需要 redo 很多操作;
还有一类错误的情况不是集群本身的问题,而是第三方程序 / 数据的问题:
第三方程序 / bad records 的问题:如果 debug 没有找出,则通常会导致在处理某些数据时故障。MapReduce 的默认行为是简单跳过:
SIGSEGV:在 signal handler 中发送 UDP packet 给 master 汇报情况(包括被处理的记录的 sequence number);
如果 master 发现有两个或以上(可以设置阈值)次数的相同 record 出现错误,则 master 会在分配任务给新的 reducer 时告知它跳过该 record;
3.2.5 Optimization
网络带宽资源稀缺:每次从网络取数据则性能不佳;
locality!由于 MapReduce 可以使用 Google 的 GFS 分布式文件系统,可以利用一个 chunk 多个 replication 的特性,将 map workers 的任务调度到有需要数据 copy 的 server 上;
重复/超时执行:有些非常奇怪的原因会导致某个 worker 出现执行问题,但是不会报出问题/严重影响性能(例如积灰降频、disk soft errors 等等);
redundant execution!master 可以设置超时时间或者其他策略,然后对某个数据取计算快的结点的结果,能显著降低较慢操作的执行时间;
3.2.6 Summary
优点:
Easy to scale;
Fault tolerant;
Good performance (depends!);
Good for tasks that suits MapReduce, e.g., wordcount;
用户不再需要关心 parallelization / data distribution / load balancing / fault tolerance;
缺点: Limited programming abstraction ;
但 MapReduce 也不能解决所有问题。
例如 Google 爬虫使用 MapReduce 统计页面,一般需要 8 小时左右,但网页更新速度更快。
也就是说,特性如下:
面向批处理的:Batch-oriented;
性能开销很大:Huge performance overhead;
不适合近实时处理的应用(for OLAP):Not suited for near-real-time processes;
对某些特性的任务不能很好地优化:Not optimized for specific tasks (e.g., Graph, ML);
在前一个任务结束前不能开始下一个(不支持任务流水线):Cannot start a new phase util previous completed;
上面的最后一个问题很严重。这意味着稍微复杂一点的任务,MapReduce 都没法胜任,例如 “find the five most popular pages in web logs”,我们需要 chain multiple MapReduce tasks together!这个时候 MapReduce 的缺陷就显现出来了:
对开发者不友好,尤其是多级任务传递间的错误处理。Fault tolerance of multiple map-reduce tasks is not supported, should be handled by the users;
每级任务间引入不必要的 startup 和 disk I/O penalty(尤其是 GFS 在持久化数据时的 I/O 开销);
也就是说,MapReduce 并没有对于 multi-stage execution 这种场景做出优化。
于是更新一点的概念抽象:Computing Graph 就被提出来了。
3.3 Computation Graph
3.3.1 Definitions
对某些比较复杂的计算场景,仅仅使用 MapReduce 的计算抽象已经不足以完成任务了。于是人们提出了另一种计算抽象:计算图。
也就是说,计算会被表示为一个有向无环图(DAG):
结点表示特定计算过程;
边表示数据传输信道(communication channel);
DAG 的好处:总是可以找到一个前序结点,进行 re-execution 将故障结点的数据恢复回来。
一个典型的计算图的运行时抽象如下:
V(计算图结点):执行任意的应用程序代码、通过 TCP 管道交换数据、向 Job Manager 报告执行状态;
JM(Job Manager):向 Name Server(Master)发现计算节点、维护这个 job graph 并且调度这些结点;
D(Daemon Process):用于启动计算图结点计算的进程;
计算图的调度规则:
总是向节点分配这样的任务:使得该节点离所需数据更近(locality);
基于节点的这样的特性:只要 input 准备完成,顶点可以在任何地方运行;
计算图的 fault tolerance(和 MapReduce 很类似):
如果节点 failed:re-execution;
如果节点的 input 丢失了(通常是上游节点 failed 导致):recursively re-execution;
如果节点性能很慢,则重复向另外一个节点发布任务(redundant execution),取更快的一个的结果;
思考:如果计算过程并不是幂等的呢?和 MapReduce 类似,还是可以通过日志等手段恢复。
人们对于 computing graph 的实现之一就是 Dryad(一种通用的分布式执行引擎,面向粗粒度数据并行应用),它和 MapReduce 的目标都是相似的。
Dryad lets developers easily create large-scale distributed apps without requiring them to master any concurrency techniques beyond being able to draw a graph of the data dependencies of their algorithms.
相较于 MapReduce,牺牲了部分的架构简便性,但是也向上隐藏了分布式执行的细节;
自动管理 scheduling, distribution, and fault tolerance;
提供了更灵活的抽象,但也需要应用级别的语义来将任务拆分为多个节点(否则 fallback 到 chain 而失去并发优势)。不过另一方面也便于开发者将分布式计算应用表达成 DAG 的形式。
3.3.2 Application: Distributed Training
这是个在 AI 中实际应用 computing graph 的例子:分布式训练。回顾一下,我们为什么需要分布式训练?
单机存在物理能力上限。即便加上之前的 CPU multiple-core、GPU core(without cache coherence、many ALU、SIMT)也是不够。一张 A100 显卡训练 GPT-4 参数量的模型需要约 412 年;
模型计算需求、参数量仍然在增长;
本章我们不讨论 AI 训练中的收敛问题(机器学习应该看的),我们将着重讨论训练的 throughput 性质(系统的性质);
以 Stochastic Gradient Descent 算法为例:
有两种让它并行分布式计算的方法:

Data Parallelism
我们考虑同步的 data parallelism 方式:
具体来说,我们可以通过 Bulk Synchronous Parallel (BSP) Execution 的方式来实现上述思想(同步数据):
Using a strict barrier to coordinator processes in a distributed computing;
Barrier can be implemented in a centralized way (master) or decentralized;
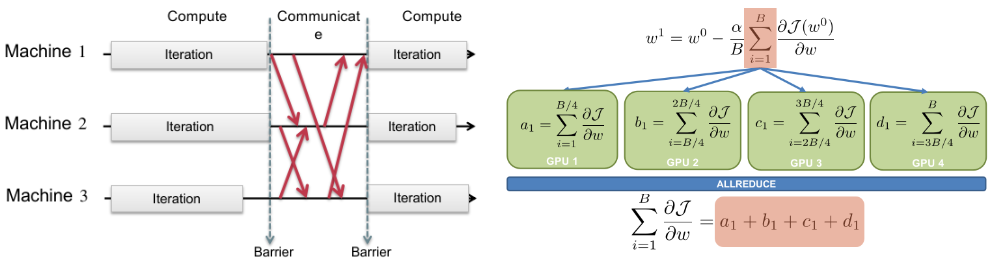
注意到我们需要优化 allReduce 算子,目标就是降低网络开销(单机上的运算开销已经优化到位,不是性能瓶颈所在)。这里不妨记
Parameter Server(PS):这种
allReduce的实现是非常原始的,直接将个各部分的结果推到一个 parameter server 上进行计算,然后 server 再将结果返回给各个部分的 processor。我们发现 parameter server 的数据传输量来回分别是
Co-located & sharded PS:进行改进。模仿之前实现 linearizability 的优化,将每部分数据拆成不同 portion,每个 server 负责统一处理一个 portion 的数据运算和返回;
这种方法的交流轮数是
但是每个 server 的网络的 fan-in 仍然高达
De-centralized approach:其他 server 先给一个 server 逐个发送数据(每两个间等待计算完成),让它的计算完成后,再给下一个 server 重复这样的操作;
fan-in 复杂度
但是这种方法的交流轮数是
如果我们进一步优化,对数据进行 shard,然后每个 server 负责一个 shard 的 reduce(每两个间仍然 coordinate 等待计算完成)、仍然允许提前发送,这样每个 server 的总传输数据量有所下降(
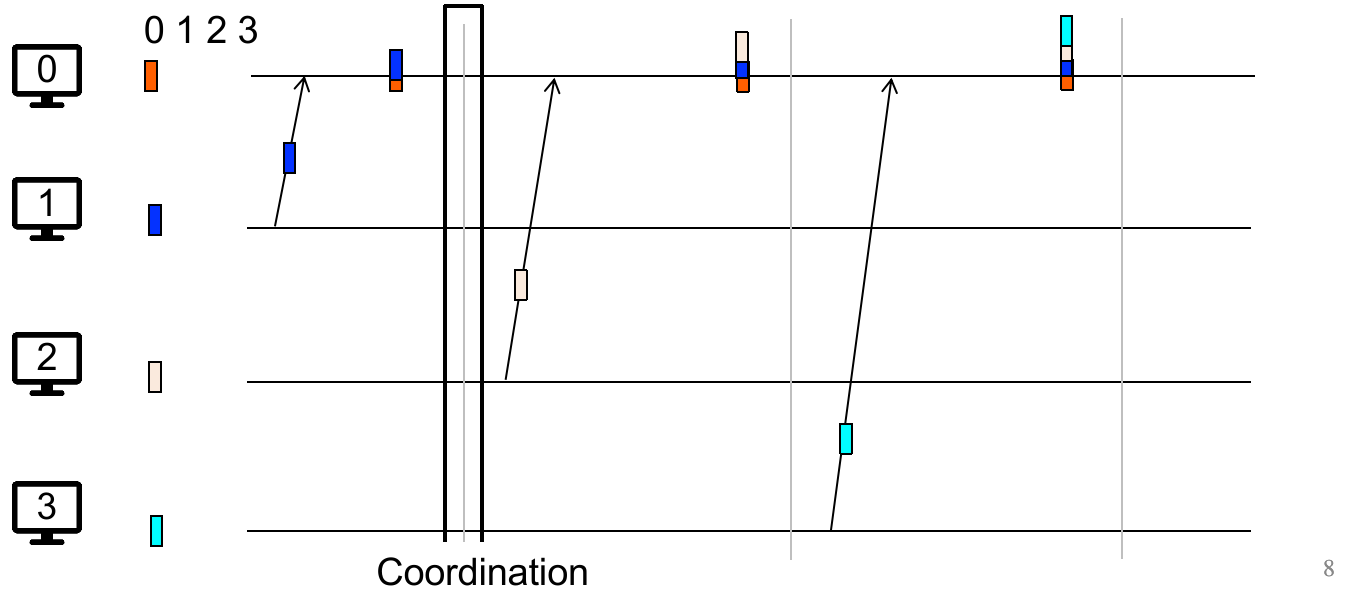
Ring AllReduce(Decentralized approach w/ only peer connections):在 decentralized approaching using sharding 的基础上仅维持相邻 peer 间的网络连接,然后构成一个环,这样管理某个 shard 的 server 沿着环发这个 shard,最终拼起来传到的最后结点上,就是某个 shard 的全部数据!
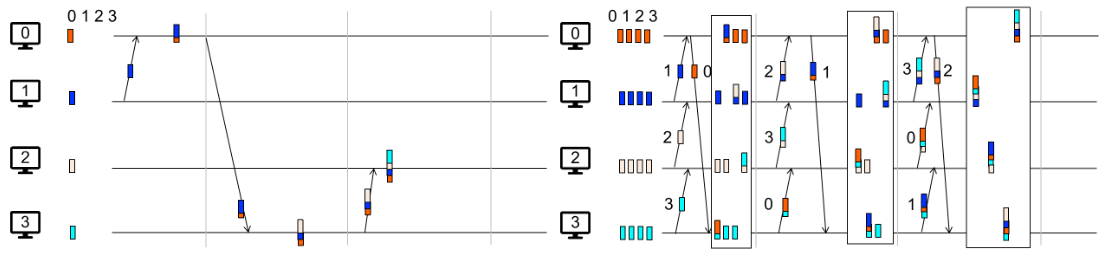
注意到这里浮点数的运算顺序有不同,所以这种方法的 assumption 是数据运算是可交换的;
总的来说,ring allreduce 的开销:
总体信息交流轮数:
缺陷:由于有额外 rounds 的通信开销,可能 latency 比较大;
这样还能继续优化!让每个 server 处理两个 shard(Double the fan-in),就能让 fan-in 下降到
总结一下:
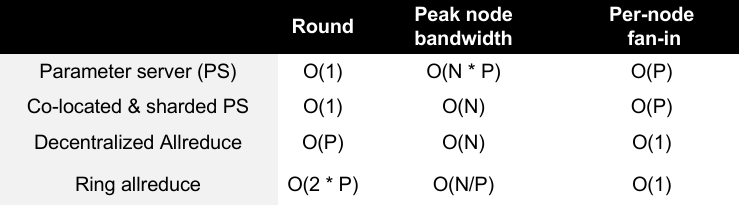
Model Parallelism
Data Parallelism 的缺陷:replicated model;
Such that they can do the forward & backward pass dependently
What if the model cannot fit onto the device?
既然一个 GPU 放不下这么多数据(data forward),我们可以考虑放到多台机器:
不过划分也有不同方法:
Partition on the layer(Pipeline Parallelism):主要看如何减少 bubbles;
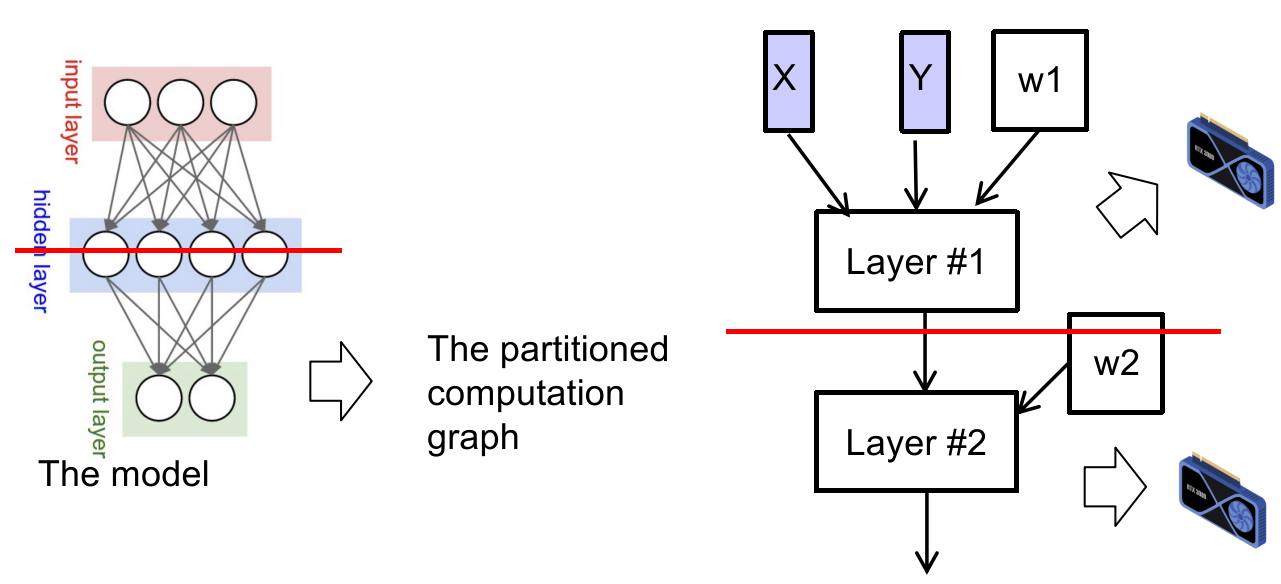
micro-batching: bubble size
设 forward 一个 micro-barch 的时间为
优化方向是:
增大
减小
Partition on weight(Tensor Parallelism):
forward pass:其实就是分块的矩阵乘法:
然后还需要最后一次 communication 将数据合并起来。每个结点的通信开销
backward pass:
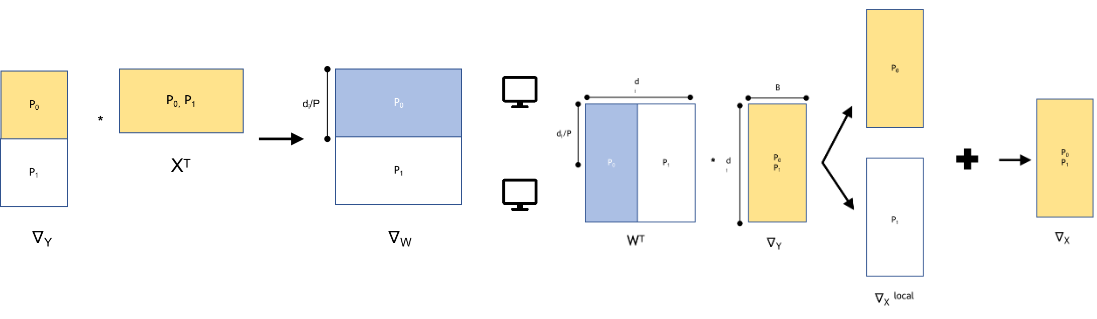
No communication needed as every processor only needs the gradient of its own parameters
Aggregating input gradient requires an allreduce operation
时间开销(ring):
一般真正的使用场景中,我们常常把 pipeline parallelism 和 tensor parallelism 的策略结合起来。它们的优缺点:
Pipeline parallelism: Partition the computation graph by layers;
Pros: reduced communication;
Cons: bubbles;
Tensor parallelism: Partition the parameters of a layer (or a set of layers);
Pros: better support for large models; Support pipeline parallelism with a large layer; Fit the hardware architecture of modern servers;
Cons: high communication cost;
Async vs. Sync execution
回忆我们在同步执行时讨论的 BSP 实现,它给每个节点带来了大量的空闲时间,因此我们可以采取异步方法,让节点间不再相互等待。这就是 Asynchronous execution;
Async
Pros: efficiency;
Cons: trade accuracy for performance;
Sync
Pros: Preserve the SGD training property;
Cons: poor performance;
Which is better? Hard to tell. But, as a system designer, preserving the algorithms property is very important. Any design that alter the training property should be justified.
因此大多数时候人们都选择同步执行的训练方法。
Chapter 4. Security
系统安全的目标:
Information security goals:
Confidentiality: limit who can read data;
Integrity: limit who can write data;
Liveness goals:
Availability: ensure service keeps operating;
系统安全的假设:Threat Model(威胁模型)
Bitcoin 的模型:攻击者控制了网络中的一些计算机,而不是全部;
手机的模型:攻击者控制设备中某些软件,而不是全部;
……
4.1 Authentication (Password)
目标:认证用户、让攻击者猜测困难。
算法 1(tenex):
xxxxxxxxxxcheckpw (user, passwd): acct = accounts[user] for i in range(0, len(acct.pw)): if acct.pw[i] != passwd[i]: return False return True侧信道攻击。密码判断的正确长度和运行时间有关。测试每一位,可以使用 Page Fault 增大运行时间的差异。
算法 2:于是我们不能在 server 上保存明文。现在考虑保存 Hash Value。
注意到 Hash 运算的性质 Hash(x) = a && Hash(y) = a => x = y,我们可以构造彩虹表(常用密码的 Hash),进行撞库。
算法 3:保存 Hash Value 也不安全。需要在 Hash 密码前,对 Hash 加盐(随机数),Hash(pwd | salt);
问题上这个方法没有从根本上解决泄漏的安全隐患,只不过是增大来攻击者的攻击成本:需要为每一个人的 salt 都要计算一个彩虹表,这样想批量攻击就很困难了。
而且很严重的问题是,总会存在首次验证的情况。以 Web Application 为例,如果是钓鱼网站,密码还是会丢。即便发送端事先和接受端商议固定的 salt,并且加盐 hash,攻击者还是可以通过重放攻击(replay attack)来非法获取权限。
算法 4:不把密码放在网络上,使用 nonce(server 给的随机数),然后计算 Hash(pwd | nonce) 传给 server;
还有一些小问题,首先防止攻击者能够 offline attack,需要对尝试的请求进行监控。
也可以使用 site key(输入 username 后交换一些独特的信息,例如历史产生的数据,验证是否是钓鱼网站);
也可以让密码只能使用一次。
4.2 CFI: Control Flow Intergrity
很多二进制攻击的本质是针对程序正常控制流的破坏(例如 Buffer-Overflow Attack、ROP 等等)。因此,我们考虑防御这些问题,就可以从保证控制流完整性的思路上入手。
注意到,在编写程序时,程序语义中实际上是包含 CFG(Control Flow Graph)的。问题是编译为二进制文件后,机器代码中的 CFG 的额外的信息限制丢失了。我们可以考虑在编译时,把源码中的 CFG 信息限制加入二进制中吗?
有调查表明,程序在静态编译后有 90% 以上都是 Direct Jump/Call,并且运行时几乎 95% 以上的 Indirect Jump/Call 都只有一个确定的 Target。也就是说,程序的 Control Flow 没有想象中的那么灵活。
方法:在编译器编写时,我们可以在在跳转的 CFG 路径上硬编码随机数(patch),调用时检查跳转的位置是否匹配。
如果是对外提供的库,担心硬编码的兼容性差,可以利用 prefetchnta 指令(quiet failure,错误静默)。
但是这么约束粒度很粗,不能防止所有的异常跳转。例如:
A 调 C,B 调 C & D,这时候 C 和 D 的跳转 tag 是一样的,可能出现 A 到 D 的非法跳转。
解决方案:duplicate code or inline / multiple tags;
F 既可以被 A 调用,又可以被 B 调用,如何判断 F 合法的返回地址?(如被 A 调了,却被挟持返回到 B)
解决方案:shadow call stack。为了 return address 特意维护另外一个隐藏的 stack,检验有效性;
除了上面的方法(unique IDs),一些措施例如 Non-writable code、Non-executable data、Enforcement: hardware support + prohibit system calls that change protection state + verification at load-time;
使用 CFI 方法能防御所有:stack-based buffer overflow、return-to-libc exploits、pointer subterfuge(指针诡计,通常利用了 buffer 不安全的库函数)这些类型的攻击。
CFI 不能防御的攻击有:
Incorrect arguments to system calls;
Substitution of file names;
Other data-only attacks;
这些攻击都没有违反程序正常的 CFG;
不过也没关系,因为这已经极大的增大了 ROP 等攻击的难度。
4.3 Example: Buffer Overflow - BROP
Stack Reading (Web Server):用来破解 ASLR 机制;
不断尝试(1 byte 加),有两种反映:crash/normal;
合理性来源于
fork不会改变程序启动后的 ASLR 偏移量;
find gadgets
stop gadget(never crashes)、crash gadget(always crashes)、useful gadget(crash depends on return address);
如何找 useful gadgets?
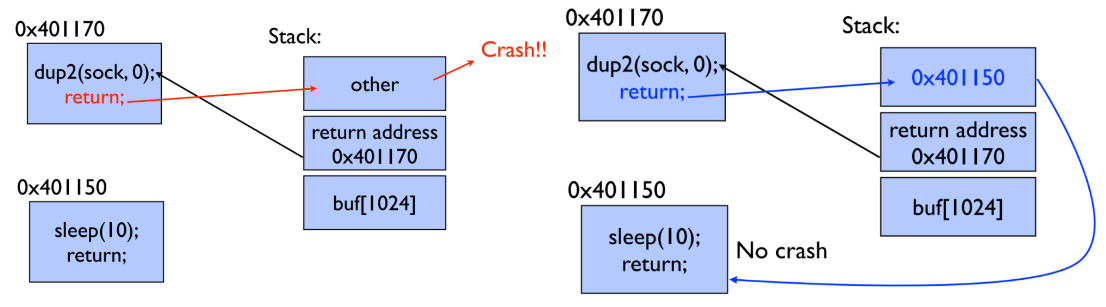
use
writesystem call: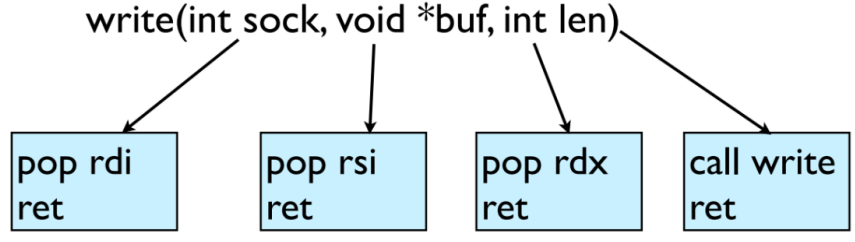
拼凑这些 ROP gadgets,我们的思路是:
BROP gadgets:
找
ret:找
pop %rbx(可能)和ret循环下去直至找到整个 BROP 片段;
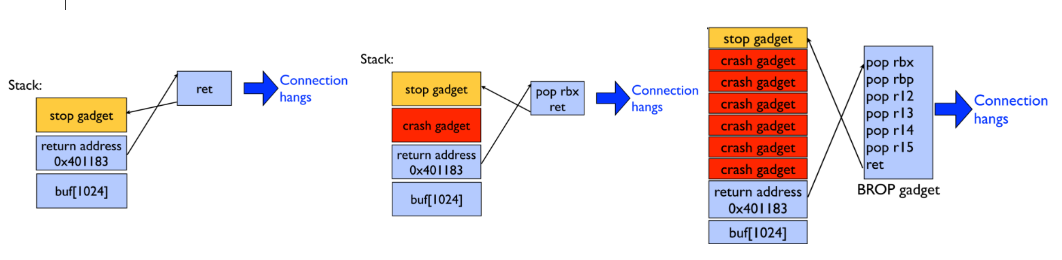
找
strcmp(因为用到%rdx,作为字符串长度)找
PLT表:大部分的 PLT 项都不会因为传进来的参数的原因 crash,因为它们很多都是系统调用,都会对参数进行检查,如果有错误会返回 DEFAULT 而已,并不会造成进程 crash。所以攻击者可以通过下面这个方法找到 PLT:如果攻击者发现好多条连续的 16 个字节对齐的地址都不会造成进程 crash,而且这些地址加 6 得到的地址也不会造成进程 crash,那么很有可能这就是某个 PLT 对应的项了。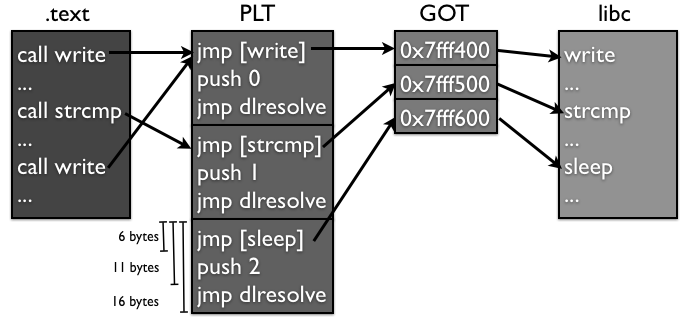
fingerprint
strcmp;
找
write同时调用好几次write,把它们串起来,然后传入不同的文件描述符数;
同时打开多个连接,然后使用一个相对较大的文件描述符数字,增加匹配的可能性。
总结起来就是:
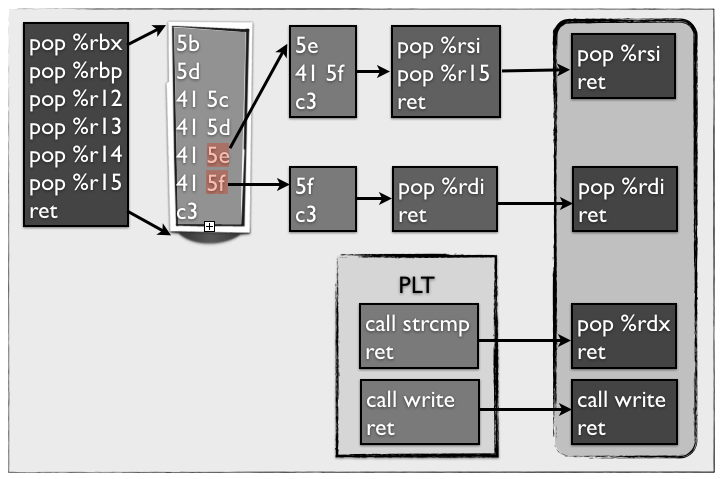
找到使用
write的方法后,我们可以将 memory write 到 network 上(dump binary)、dump 符号表来找 PLT calls、将stdin/stdout重定向到 socket,最终能执行execve获取 shell 执行;
4.4 Data Flow Protection
机密性、完整性、可用性(CIA);
4.4.1 Taint Tracking
敏感数据段的 lifetime 应该越短越好,这个时段被称为 “data exposure”:
The longer data remains in memory the greater its chances of being leaked to disk;
原因:Swapping, hibernation, VM suspending, core dump, etc.
依赖数据的流动(例如赋值)。
Taint 的数据应该存放在哪里?大概率是放在整个内存的最末尾位置(不是直接放在栈上的)。
弱点:利用控制流可以洗掉 taint,例如 b = a 的语句使用全分类讨论赋值 b 为常数。
4.4.2 Defending Malicious Input
使用 taint analysis 来预测可能出现的 malicious input 对系统产生的不安全影响。
4.5 Security Channel
4.5.1 对称加密
所以可以采用一种简单的做法来尝试防止 Eve 和 Ida 的行为:
Alice 和 Bob 约定一个函数
其中这对函数有一些硬性要求:
在发送消息
形象理解就是一把暴露在外的锁(
Sidebar:按位异或 与 AES 算法
按位异或(bitwise exclusive-or)就是一种选择。
;
; 因为它满足一些优秀性质:
是一个双射函数,其逆函数就是自身;
能保证
和 的关系不大。只要密钥 是随机的,那么 的每个二进制位有 50% 概率不变,有 50% 概率相反; 硬件计算很快,性能好;
但这个函数的
参数不能重复使用相同的随机数。为什么?因为重复的 会让窃听者获取和明文相关的消息:窃听者第一次拿到 ,第二次拿到 ,那么就知道 ;这个 就会间接地泄漏信息。 假设通信传递的是某个重要选举的票选信息,而每一位代表一个票选意见(比如是 1 就选 A,是 0 就选 B)。那么
中的 0 越多,说明选举群众的共识度越高,有更多的人选择类似。 为了解决这个问题,人们基于按位异或设计了一种更强的对称加密算法:AES(Advance Encryption Standard),它的好处是:
虽然算法公开,但可以重复使用密钥;
计算效率合适;
目前没有比 brute-force 更好的办法来破解(但也没有证明绝对不可破解);
这种方式被称为 “对称加密”(Symmetric Cryptography),即加密、解密用的密钥相同。
而
对称加密特点:
计算量小,吞吐量大,传输大量数据不会因为加解密成为性能瓶颈;
在不知道密钥信息的前提下,窃听者、中间人无法破坏通信的安全性;
但对称加密也有问题:在 Alice 和 Bob 第一次交流的时候,肯定需要约定一个密钥
也就是说,对称加密使用的密钥目前还没有办法保证不被网络上不可信任的设备截获。
因此需要更强大的措施来防止窃听者、中间人获取密钥。
4.5.2 非对称加密
假设我们通过某种方法获得了一个神奇的算法:
Alice 使用
也就是说,加密用的
相当于一把双钥匙锁:只能用
在通信前,Alice 先用某种方法生成一对
对,就这一个更改就让 Eve 没办法了:
因为虽然
这个公开的
而私钥加密、公钥解密的过程被称为 签名(signing);
Sidebar: RSA 算法
那么上面的 “神奇算法” 是如何实现的呢?数学家想出一个方法:
任取两个相当大的素数
,计算 ; 找到一个和
互素的数 ,则 是 上的双射,作为我们的加密函数; 解密相当简单:找到
关于 的乘法逆元,记为 ,则对 上的任一元素 ,都有: ; 证明:由于第 3 条蕴含第 2 条,所以下面仅证明第 2 条:
注意到
可以进行因式分解: ; 再由费马小定理:
( 是素数),因此对于素数 , ;即: ,或者说 得证; 也就是说,
是公钥, 是私钥, 是加/解密函数。 由我们前面讨论的知识,随机生成两个素数时间复杂度
,加密 / 解密是 指数 ; 这个算法安全的前提是,没有人能快速地从
获得 (即:素因数分解是难问题);
但是非对称加密也有缺陷:无论是生成公私钥,还是加密数据,计算都相当复杂、性能不佳,不适合用来传递大规模数据。
于是,一般可以采用这种措施:非对称加密 先用来传递对称加密的密钥,然后之后的通讯就使用对称加密来通信。这样既利用了对称加密的特性(计算量小、不知道密钥的情况下基本没法破解),又利用了非对称加密的强大安全性。
4.5.3 Replay Attack & Reflection Attack
replay attack: adversary could intercept a message, re-send it at a later time;
reflection attack: adversary could intercept a message, re-send it later in the opposite direction;
4.5.4 Diffie-Hellman Key Exchange, RSA & MITM
除了 RSA,DH key exchange 是一种安全生成和传递对称密钥的算法。
但是它们都可能受到中间人攻击。
现在 Eve(窃听者)彻底没法窃听到任何有效数据了,但是 Ida 还有办法。
Ida 可以拦截 Alice 和 Bob 间的所有流量,然后在 Alice 向 Bob 第一次发送密钥时:
截获 Alice 的公钥,自己再重新生成一份新的公私钥;
用 Alice 公钥解密、用自己的私钥加密,最后把自己的公钥交给 Bob;
Bob 以为这是 Alice 的公钥,解密也能成功,殊不知用的是 Ida 的公钥;
这下,Alice 和 Bob 在不知情的情况下,把消息全都发给了 Ida,Ida 既掌握解密的公钥、所有消息,还能不被 Alice 和 Bob 发现。
Ida 在这里被称为 “中间人”,而这种行为被称为 “中间人攻击”(Middle-in-the-man Attack,MITM);
这样是不行的。不过往好处想,还是之前的说法,只要我们保证第一次交换对称加密密钥的过程是安全的不就行了?这里的问题在于 Ida 可能会篡改公钥;
那么有什么办法是在暴露公钥的情况下,还能防止公钥被篡改的?
4.5.5 证书
这理论上肯定没法只由 Bob 和 Alice 解决,还需要外界的帮助。于是人们引入了 “第三方公证” 的机制:
人们需要设立一个第三方机构,确保它不会与中间人勾结。第三方机构本身事先生成一对公私钥,然后:
Alice 在将用自己的私钥加密的 “对称加密密钥” 传给 Bob 前,先传给第三方机构,让第三方机构用它自己的密钥再加密一次;
Alice 将第三方加密后的密钥传给 Bob,Bob 使用第三方公开的公钥解密,再用 Alice 的公钥再解一次密,就能安全拿到接下来要进行对称加密的密钥了;
由于 Ida 无法伪造第三方机构,因此最外层的密钥没法突破,因此也没法得到里面的数据进行中间人攻击了。
这里,第三方机构(证书签发机构)提供的公钥被称为 “证书”(Certificate)。Alice 使用第三方公钥加密、Bob 将加密信息给第三方解密的过程,就称为 “证书签名”;
目前,这套机制能够完全防御 Eve(窃听者)、Ida(中间人 / 攻击者)对信息的窃听和篡改。当然,证书 + 非对称加密 + 对称加密的整套机制被应用在了 SSL/TLS 当中,为 HTTPS、SSH 等协议重要通信场合提供全面的保护。
关于证书机构 CA 的 Q&A:
How does the browser get this list of CAs?
Generally they come with the browser;
How does the CA build its table of names <-> public keys?
Have to agree on how to name principals, and Need a mechanism to check that a key corresponds to a name;
What if a CA makes a mistake?
Need a way to revoke certificates: Expiration date? Not useful for immediate problems ;
Publish certificate revocation list? Works in theory, not as well in practice;
Query online server to check certificate freshness? Not a bad idea ;
4.6 Data Privacy
如何在使用数据的前提下,防止它们被偷走?
4.6.1 OT: Oblivious Transfer (无感知传输)
考虑一个场景,我需要从 server 的数据列表
这看起来很荒谬,我不告诉 server 我想拿哪个数据,却想要 server 发给我指定的数据。
这个问题就是 1-out-of-n OT 问题;
实现方法:
Non-adaptive OT;
Adaptive OT;
Publicly Verifiable OT;
……
4.6.2 DP: Differential privacy (差分隐私)
考虑一个场景,薪资查询的时候,不能让询问者知道其他人的精确薪资,只能知道一些统计学信息(例如总和、平均值等等)。
因此根据信息熵可知,我们需要返回的信息只能是模糊的(如果是精确的一定最终会泄漏。例如如果 client 问总数 + 除了某个人的总数)!
并且最好限制 client 的访问次数。lock 后下次修改才会重置次数。
安全性质:
Robustness to post-processing;
User can perform any operation on the result of M, and get nothing about the individual entry of D;
Composability;
Group privacy;
现存机制:
Random Algorithm;
Laplace mechanism;
Gaussian mechanism;
……
4.6.3 Secret Sharing
考虑一个场景,
优缺点:
An information-theoretically secure protocol (unconditionally secure, independent of adversary's computational capabilities -> quantum-safe);
Ideal assumption (At least k parts never collude);
Communication overhead ;
4.6.4 Secure MPC (sMPC): Multi-Party Computing
定义:Multiple parties (at least 2) work together to calculate a function;
Enforce the data privacy for each party;
Semi-honest adversary: Each party must follow the protocol;
Generic protocol: Can securely compute any functionality;
Multi-party computation: Secret sharing;
2-party computation: GC(Garbled Circuits) + OT(Oblivious Transfer)
4.6.5 Homomorphic Encryption (同态加密)
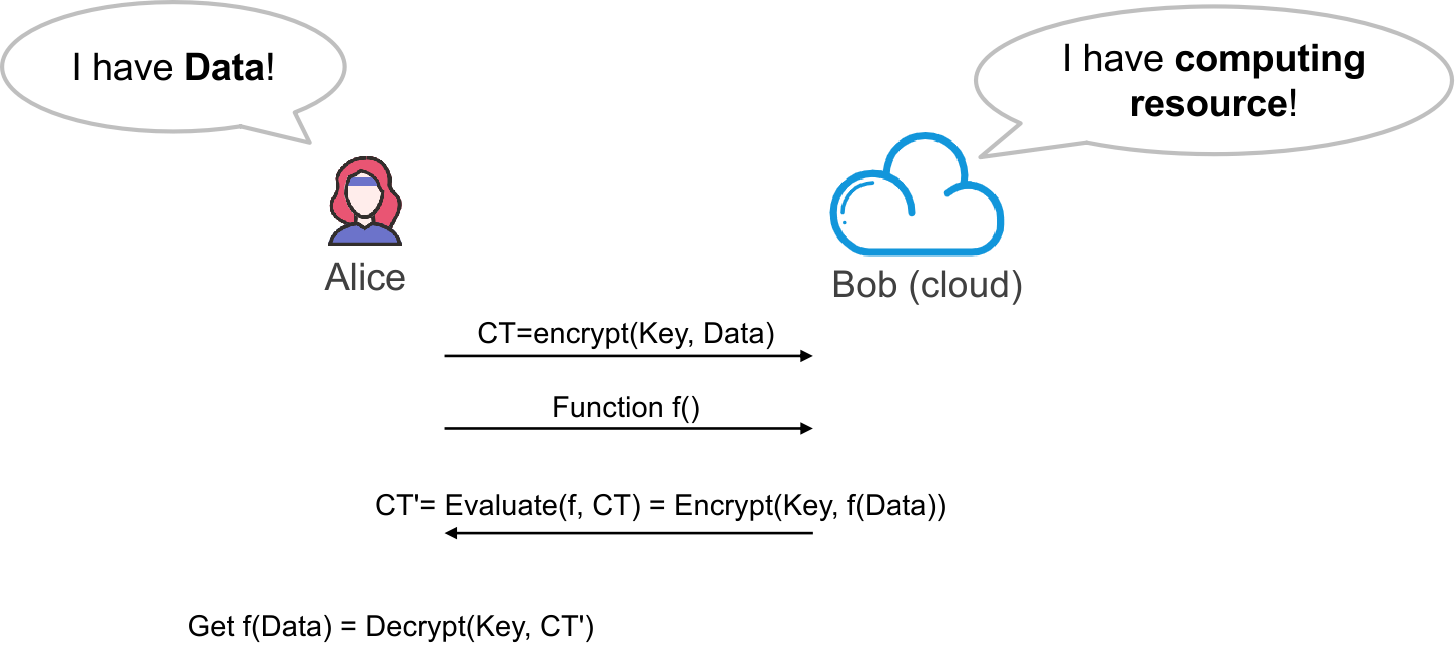
4.6.6 TEE (Trusted Execution Environment)