Chapter 15. Link15.1 Overview15.2 ConceptsStep 1. Symbol ResolutionStep 2. Relocation15.3 Linking Details15.4 Post-linking: Load Executable File into Memory (Load-time)15.5 Libraries & Link15.5.1 Static Libraries & Link15.5.2 Shared Libraries & Link15.6 Library Interpositioning15.6.1 Overview15.6.2 Usage: Compile-time Interpositioning15.6.3 Usage: Link-time Interpositioning15.6.4 Usage: Load / Run-time InterpositioningChapter 16. Virtual Memory16.1 Design a Memory Allocator16.1.1 Prerequisites & Issues16.1.2 Implementation16.2 Improve Allocator's Performance16.2.1 Method 1: Explicit Free Lists16.3 Garbage Collection16.4 Virtual Memory: From Hardware's Perspective16.4.1 How to Design Memory16.4.2 Page Table16.4.3 Address Translation16.4.4 Multi-level Page Table16.4.5 Cute Trick for Speeding Up L1 Access16.4.5 General View of Page Table & TLB16.5 Virtual Memory: From OS's perspective (Linux)16.5.1 How to manage OS Kernel ?16.5.2 How to Organize Virtual Memory in OS's View?16.5.3 How to deal with Page Fault in OS's view?16.6 Miscellenous16.6.1 Put it Togerther16.6.2 Application: execve()16.6.3 Sharing & Private Virtual Memory16.6.4 User-Level Memory Mapping: mmap()16.6.5 Application II: fork()16.7 Replacement Policy16.7.1 Metrics16.7.2 PoliciesChapter 17. Network17.1 Foundation for Network: Hardware-level17.2 Network Usage: System & Application Level17.2.1 Socket InterfaceConnection17.2.2 Details of RIO Package17.3 Web ServerChapter 18. Concurrency18.1 Overview18.2 Thread18.2.1 Introduction to Thread18.2.2 补充:Memory Sharing & Isolation of Thread18.2.3 Semaphores: 线程间信号量18.2.4 Applications of SemaphoreProducer-Consumer ProblemReaders-Writers Problem18.2.3 补充:GDB 多线程调试和多进程调试18.3 I/O Multiplexing
Chapter 15. Link
15.1 Overview
定义:collecting and combining various pieces of code and data into a single executable file;
link 的过程就是 relocate 或 组装,填写程序的地址,使得程序能够完成跨模块调用。
作用:模块化、提高编译效率(无论是时间上还是空间上)、提高复用性;
时机:
at compile time, when the source code is translated into machine code by the linker;
at load time, when the program is loaded into memory and executed by the loader;
at run time, by application programs.
15.2 Concepts
详细认识 link 之前,先从一个例子说起。假设现在有两个如下源文件 main.c、sum.c:
x/* file: main.c */
int sum(int *a, int n);
int array[2] = {1, 2};
int main(int argc, char** argv) { int val = sum(array, 2); return val;}
/* end of file main.c */
/* file: sum.c */
int sum(int *a, int n) { int i, s = 0; for (i = 0; i < n; i++) { s += a[i]; } return s;}
/* end of file sum.c */如果上面的程序都在一个文件中,那么 GCC 将其编成二进制文件的过程很简单,就像我们在 Arch Lab 中做的一样:
先用
cpp(C preprocessor)程序将*.c转译为 ASCII 中间文件*.i;再用
cc1(GNU Compiler Collection 中的 C 编译器)将*.i编译为 ASCII 汇编文件*.s;最后
as(assembler,汇编器)将*.s汇编语言一一对应地翻译为二进制文件*.o(又被称为可重定向目标文件,Relocatable Object File),这个文件如果不依赖其他库的话(实际上即便是一个最基本的 hello world 程序都依赖libc库,除非你手写汇编),理论上直接能被机器执行。
但是当这个代码被分到不同文件中,那么第三步获得的 *.o 就相互依赖,无法直接被执行。GCC 就需要做另一件事情:链接,来按一定规则组装这些 *.o,最终获得机器地址无关的可执行文件(Position-Independent Executable file),如下图所示:
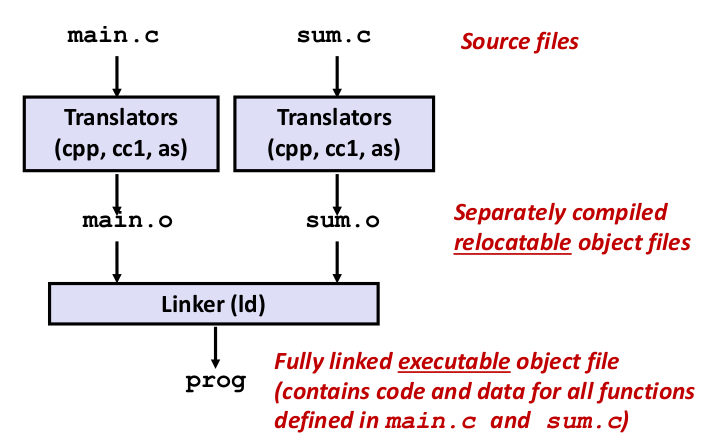
好,既然说链接是 “来按一定规则组装这些 *.o,最终获得可执行文件”,那么链接器所做的这个过程的细节究竟是什么呢?
我们先从宏观上看,链接的任务主要分为两个步骤:
Step 1. Symbol Resolution
这一步中,链接器大致会做几件事:
将程序中定义(define)以及引用(reference)的 符号 记录下来。以本章开头的程序为例:
对于链接器而言,“符号” 的定义是:
包括全局函数、全局变量(又称链接对象)之类的所有名称。
你可以用
readelf -s <object file name>来查看符号。void sum(...) {...}:这是一处 全局函数 的 符号定义;sum(...);:这是一处 符号引用;int val = sum(array, 2);:这是val符号定义,也是sum、array符号引用
将上一步记录的符号(位置、数据所占大小)全部放到汇编器生成的 目标文件(
*.o)中的一个预留的部分:符号表(symbol table,一种类似 “结构体数组” 的数据结构) 中;Q 1:为什么要把记录的符号放到符号表中?
A 1:因为可能有些地址或符号的某些属性目前不确定,尤其是运行时加载的部分;
Q 2:符号表是什么数据类型?
A 2:符号表就是一种:由汇编器插入的、存放在最终二进制文件的某个区域(后面介绍最终二进制文件的结构)的一种结构体数组,其每个单元都包含 符号名、符号大小、符号位置 等符号信息;
最后,链接器利用符号表信息将文件中各个 reference 符号 associates 在一起,确保在最终文件中仅保留唯一一个 definition;
如果链接器发现:
有些符号只有 references 而没有 definition,那么抛出
undefined references to ...错误信息;有些符号有多个 definitions,那么抛出
multiple definitions of ...错误信息;
Step 2. Relocation
这一步中,链接器会:
将不同
*.o的同一数据段的内容合并在一起;注:编译器生成的汇编代码(汇编器只是一对一翻译,暂时先忽略它)会根据数据、代码等不同类型分段,后面详细介绍。
将
*.o文件中相对地址符号的定义重定向为 将要执行在内存中的绝对内存地址;因为最初编译器生成的版本中,表示符号的位置要么是相对偏移量(位于同一个文件),要么根本不知道在哪、是什么(定义在其他文件中);
而链接器需要搞清楚每个符号(每个函数、变量),在执行在内存中的时候,应该存放在哪里。
更新上面获得绝对地址的符号的引用 为新的位置;
接下来,为了更进一步详细了解上面的步骤的具体内容,我们需要一点前置知识。
1. object file(目标文件,*.o)的种类
我们知道,预处理器+编译器+汇编器最终生成的是 relocatable object file,其实将它们链接后,可执行文件还是一种 object file。但是根据是否需要链接(里面有没有没有解析、重定向的符号)、是否有主函数入口,它们可以有不同的类型:
*.orelocatable object file:由汇编器生成的、其中包含了需要被 relocate 的 code 或者 data 的 object file;*.outexecutable object file(Windows 上*.exe):由链接器生成的、其中的 code、data 可以直接被 copy 到内存中执行的 object file;*.soshared object file(Windows 上*.dll):由链接器生成的、特殊的 relocatable object file,但其中的符号都是已定义的、可供导出给其他 relocatable object file 重定向的符号。它们既可以在程序 load time(装载时,即 copy 到内存中的阶段)加载,也可以在程序 run time(运行时)加载。
2. object file 的格式:Executable and Linkable Format(ELF)

如上图所示,每个 ELF 文件的开头都是 ELF header 结构,这个结构就类似 C 中的一个结构体,其中含有 word size、byte ordering、machine type、file type(例如是
*.o、*.so还是*.out)等等信息;你可以用
readelf -h <object file name>来查看这部分的信息;第二部分 segment header table 只有在可执行文件中存在,其中指明了 分页大小、虚拟内存段的情况(包括栈、shared libraries、初始化或未初始化的数据、代码内容 在内存中的位置) 等等信息;
第三部分是
.text段(由于某种历史原因才有这个名字),就是存放代码内容的部分;会被装载入内存,内存区域权限 可读可执行、不可写;
第四部分是
.rodata段,表示程序中的只读数据(常量),例如程序 switch 语句的 jump table;会被装载入内存,内存区域权限 可读、不可写不可执行;
第五部分是
.data段,包含所有已初始化的全局变量空间;会被装载入内存,内存区域权限 可读、不可写不可执行;
第六部分是
.bss(better save space)段,包含所有未初始化的全局变量,但它不占用任何 object file 的空间,仅仅是作符号占位之用。在程序被装载后,由操作系统对该部分符号所在的位置归零;会被装载入内存,但最终内存中会占用空间,所以内存中的名字不再是
bss了。内存区域权限 可读、不可写不可执行;这也是为什么未初始化的全局变量的值一定为 0;
第七部分是
.symtab段,就是之前提到的存放所有符号的表的位置;此外,标注
static静态的对象(函数、变量等)也会在这里出现;你可以用
readelf -s <object file name>来查看符号表;第八、九部分是
.rel.txt和.rel.data段,这两个部分也称为 “记录”(records),由链接器生成,包含需要重定位的信息;比如在 symbol resolution 一步中,链接器每找到一个引用,就记下一些记录,表示在后面的 relocation,以至于 load time 阶段、run time 阶段,要去更新填写这些引用指代的真实位置。
第十部分是
.debug段,这个部分仅在加入-g(gdb)编译选项后,编译器才会生成的部分。其中的信息是用来帮助调试的,例如源代码行号和机器代码位置的对应信息等。最后一部分是 section header table,用来记录以上所有分段(长度不定)的起始位置信息。
其实上面还有一些 section,例如字符串表 .strtab,但在这里用不到,以后再讨论;
3. 链接器符号(linker symbol)的种类
我们发现,在前面的描述中,似乎链接器对不同的符号处理方法不同。例如:
一个符号的定义,和这个符号的引用,虽然名称一样,但处理方式是不一样的;
一个符号在本文件的引用(定义),和在外部文件引用(定义),也是不一样的。
这些不一样主要是因为语法解析、 symbol resolution 和 relocation 的要求所致。
因此链接器将它遇到的符号分为 3 类:
Global Symbols(全局符号):被定义在当前模块(
m,即一个 object file 文件),并且可以被其他模块所引用的符号;在 C 中,指的就是 非静态函数、非静态全局变量;
External Symbols(外部符号):被当前模块(
m)引用,但是定义在其他模块中的符号;在 C 中,指的就是用
extern关键字修饰的声明符号;Local Symbols(局部符号):被当前模块(
m)定义,并且仅能被当前模块使用的符号;在 C 中,指的就是被
static关键字修饰的 静态函数、静态变量(包括静态局部变量,但不包含普通局部变量);
⚠️⚠️ 请注意:程序的局部变量不是局部符号,它甚至不是链接器符号!因为它会在编译阶段就被编译器用寄存器或栈管理起来了。 ⚠️⚠️
但是程序的 静态局部变量 也属于局部符号,因为它的语义要求它不能存储在运行时栈上,必须存放在 .bss / .data 段内,因此它也作为一个链接器的局部符号,不会被编译器用寄存器或者栈的位置替代。
事实上,编译器对于静态局部变量,会和静态全局变量一样,被分配 .data / .bss 段中,并且由编译器赋予它们符号名称。
你可能会想,为什么编译器要亲自为静态局部变量取名?用本身的名字不行吗?
还真不行。考虑一种情况:在同一个文件中两个静态局部变量同名。
15.3 Linking Details
现在我们可以讨论链接过程的所有细节了。重新拾起之前的例子,并做一些改装:
xxxxxxxxxx/* file: main.c */int sum(int *a, int n);
int array[2] = {1, 2};
int main(int argc, char** argv) { int val = sum(array, 2); return val;}/* end of file main.c */
/* file: sum.c */
int sum(int *a, int n) { static int times = 0; int i, s = 0; for (i = 0; i < n; i++) { s += a[i]; } ++times; printf("Called sum for %d times.\n", times); return s;}/* end of file sum.c */第一步是 symbol resolution:
在
main.o中,链接器会找到如下符号:array,全局符号(链接对象@object)定义;sum(array, 2),全局符号array的引用、外部符号sum(链接函数@function)的引用;外部符号
sum等待 relocation;main,全局符号(链接函数@function)定义;
至于
val是局部变量,会被编译器消解,因此链接器是感受不到的。在
sum.o中,链接器会找到如下符号:sum,全局符号(@function)定义;times,局部符号(@object)定义;++times,局部符号引用;printf,外部符号(@function)引用;
至于程序局部变量
i、s,同样是被编译器消解。
当然,现在每个 object file 间没有关联,因此有些外部符号的定义是不知道的(例如 main.o 还缺少 sum 符号引用的 relocation、sum.o 还缺少 printf 符号引用的 relocation),链接器会对这种情况也会做记录。为此,编译器会留出相应空间,等待链接器在 relocation 阶段填入。
链接器是如何记录上述信息的?我们知道它放在符号表(symbol table)中,这个表在那么符号表的详细结构是什么?
xxxxxxxxxxtypedef struct {int name; /* string table offset */char type:4; /* function or data (4 bits) */binding:4; /* local or global (4 bits) */char reserved; /* unused */short section; /* section header index */long value; /* section offset, or abs address */long size; /* Object size in bytes */} Elf64_Symbol;符号表数据结构中每个 entry 的结构如上声明。
为了使符号表的长度确定,因此符号名统一存放在
.strtab字符串表中,使用就用偏移索引即可(详见 18.4)。
type区分这个符号是 函数符号 还是 数据符号;
binding区分这个符号是否为局部符号(是否是被static修饰的变量、函数);
reserved会存一些其他数据(例如 visibility);
section表示当前这个符号最终应该位于哪个段(以索引表示);在 Relocatable Object File 有几个 pseudo sections:ABS(这个符号不应该被 relocate,即这个符号与绝对地址绑定)、UNDEF(当前这个符号的定义不在这个 relocatable object file 中,也许是外部符号,所以也不知道)、COMM(当前这个符号是全局的,并且没有被初始化。)
等一等!之前说过一个问题,可能编码的人无意重复定义了一些全局符号(局部符号不会出现这个问题!因为在一个文件作用域内,编译器就能发现为错误),链接器可能会抛出错误,那么这个机制是如何进行的呢?
针对符号的重复定义,链接器遵循一些规则来处理这种情况。
在此之前还要再定义一些内容:
Strong symbols(强符号):指已经定义和初始化的链接器 全局符号;
Weak symbols(弱符号):指未初始化的链接器符号;
Rule 1:不允许有多个同名的强符号。
Rule 2:允许存在一个强符号和多个同名弱符号,但链接器将认准强符号的定义;
Rule 3:如果同时存在多个同名弱符号而没有强符号的定义,则随机选择一个弱符号作为定义。
注:在
GCC10 及以上版本中,链接器已经默认打开选项-fno-common,这意味着 如果链接器遇到多个弱符号定义,但没有强符号,则直接抛出错误。如果你想要仍然使用这个特性,那么在
GCC 10及以上的版本中需要手动添加-fcommon选项。
虽然有这样的规则,但是真的不建议你定义同名的链接器符号!除非你知道你在做什么。有时候如果多个弱符号,的数据类型不同的时候,就会出大问题(甚至有强符号也不行!),因为链接器不会做类型检查!举个例子:
xxxxxxxxxx/* in one of the file */int x = 1;int y = 0;void p1() { ++x; }
/* in other of the file */double x;void p2() { ++x; }这个例子中,我们知道最终链接器肯定会选择强符号定义 int x = 1;,但是编译器编译时并不知道!因为编译器先编译单个文件,所以在 p2 所在的文件中,编译器会翻译成:将 x 当作 8 bytes 的内存数据结构写入。
但实际上,最终链接器将 x 这个符号链接到了一个 4 bytes(int)大小的内存地址上,这就会导致紧接着 x 定义的 y 全局变量被改变(因为都是全局变量,并且代码中紧挨着,因此会被编译器安排在相邻的 .data 段)!这是个非常隐晦的越界读写错误,极难以调试!
这些教训总结下来就是,尽量少用全局变量。或者如果要使用,就自己模块用的话及时修饰 static,给其他模块用的话尽量在定义同时初始化(让链接器能判断到错误)并且使用方要用 extern 声明。
C 毕竟也不是脚本语言,限制变量的作用域范围总是件好事,不会出现上面的错误。
好,再回到本节开始的例子 😂
我们知道,main.o 中包含了 main 全局符号的定义、array 全局符号的定义,sum.o 包含了 sum 全局符号的定义、times 局部符号的定义。
而 main.o 还缺少 sum 符号引用的 relocation、sum.o 还缺少 printf 符号引用的 relocation。
现在链接器要进行下一步动作 —— 第二步是 relocation。
链接器会先将各个文件合并到一个二进制文件中,这个合并只是按照特定顺序来组合各个目标文件(包括你要编译的目标文件、程序的系统引导代码、之前记录的符号数据等等),例如:
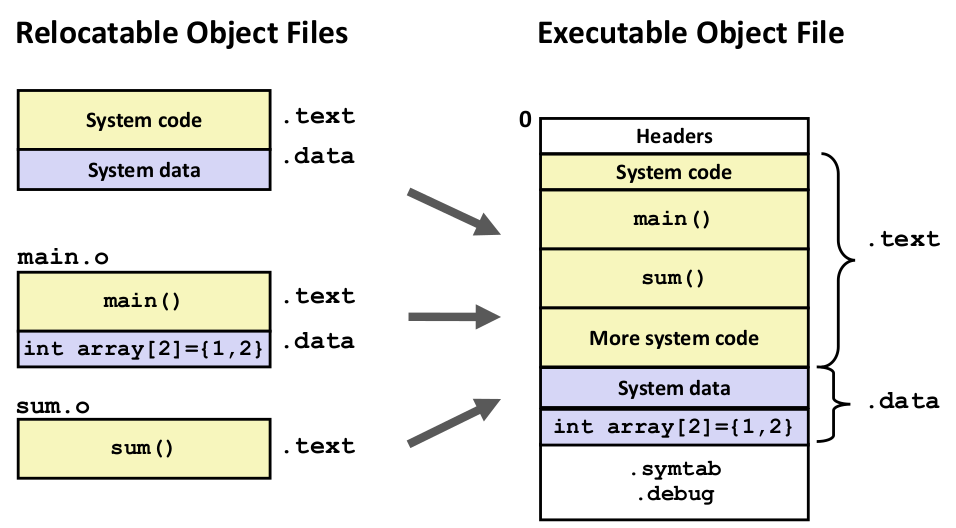
这个时候其实各个模块间还是 relocatable 的(相对地址),这意味着操作系统仍然无法知道应该将这个程序载入到内存具体的什么位置执行。那么这个时候链接器下一步动作肯定是计算并且向未知地址的位置上填入地址(例如 main 函数、数据地址的位置)。但是这个位置是怎么得到的呢?
众所周知,在编译阶段,各个 object file 还没有相互联系的时候,外部符号,甚至同一个模块中针对数据的符号,编译器都是没办法确定符号的最终地址的。
因此编译器秉持着:能用相对地址就用相对地址;不能用相对地址,就为数据留出空间,并添加链接器指令,告诉链接器此处应该 relocation 后填上 的原则。例如对于之前的 main.o,汇编器输出结果对应的汇编代码是:
xxxxxxxxxx0000000000000000 <main>: 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp 8: 48 83 ec 20 sub $0x20,%rsp c: 89 7d ec mov %edi,-0x14(%rbp) f: 48 89 75 e0 mov %rsi,-0x20(%rbp) 13: be 02 00 00 00 mov $0x2,%esi 18: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 1f <main+0x1f> 1b: R_X86_64_PC32 array-0x4 # Relocation entry (32 bits) 1f: 48 89 c7 mov %rax,%rdi 22: e8 00 00 00 00 call 27 <main+0x27> 23: R_X86_64_PC32 sum-0x4 # Relocation entry (32 bits) 27: 89 45 fc mov %eax,-0x4(%rbp) 2a: 8b 45 fc mov -0x4(%rbp),%eax 2d: c9 leave 2e: c3 ret因此在 main.o 中,我们注意到几个点:
main定义在本模块的全局符号(函数) 无法确定地址,但它最终不是由 linker 填入,而是 OS 控制程序 load time 的时候填入;array定义在本模块的全局符号(数据)无法确定地址,但它使用 相对位置标记(%rip),偏移量留空在 linker 的 relocation 合并完成后填写给出;sum定义在其他模块的全局符号(函数)无法确定地址,它也使用 相对位置标记(indirect location),是在 linker 的 relocation 合并完成后填写给出;
注:其中
R_X86_64_PC32表示需要 linker 填写的是 32 bits 的数据,内容是array - 0x4/sum - 0x4,至于为什么减0x4,是因为现在使用的是 PC(相对于%rip)的地址,当 PC 读完该语句的时候,PC 应该在这个数据后面 4 bytes。以上的 relocation entry 都由汇编器生成,记录在 relocation table 中。链接器只要读就行。
而对于 sum.o,汇编器输出结果如下:
xxxxxxxxxx0000000000000000 <sum>: 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp 8: 48 83 ec 20 sub $0x20,%rsp c: 48 89 7d e8 mov %rdi,-0x18(%rbp) 10: 89 75 e4 mov %esi,-0x1c(%rbp) 13: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp) 1a: c7 45 f8 00 00 00 00 movl $0x0,-0x8(%rbp) 21: eb 1d jmp 40 <sum+0x40> 23: 8b 45 f8 mov -0x8(%rbp),%eax 26: 48 98 cltq 28: 48 8d 14 85 00 00 00 lea 0x0(,%rax,4),%rdx 2f: 00 30: 48 8b 45 e8 mov -0x18(%rbp),%rax 34: 48 01 d0 add %rdx,%rax 37: 8b 00 mov (%rax),%eax 39: 01 45 fc add %eax,-0x4(%rbp) 3c: 83 45 f8 01 addl $0x1,-0x8(%rbp) 40: 8b 45 f8 mov -0x8(%rbp),%eax 43: 3b 45 e4 cmp -0x1c(%rbp),%eax 46: 7c db jl 23 <sum+0x23> 48: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 4e <sum+0x4e> 4e: 83 c0 01 add $0x1,%eax 51: 89 05 00 00 00 00 mov %eax,0x0(%rip) # 57 <sum+0x57> 57: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 5d <sum+0x5d> 5d: 89 c6 mov %eax,%esi 5f: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 66 <sum+0x66> 66: 48 89 c7 mov %rax,%rdi 69: b8 00 00 00 00 mov $0x0,%eax 6e: e8 00 00 00 00 call 73 <sum+0x73> 73: 8b 45 fc mov -0x4(%rbp),%eax 76: c9 leave 77: c3 ret对于 sum.o 我们还注意到了一些点:
printf定义在其他模块的全局符号(函数)无法确定地址,使用 indirect location 标记,留空给 linker 在 relocation 阶段填写;times定义在本模块中的局部符号(数据)无法确定地址,使用相对地址%rip标记,偏移量留空给 linker 在 relocation 阶段填写;
于是,我们可以总结出链接器对于符号地址处理的原则:
对于所有链接器函数符号(无论是定义在本模块的全局函数符号,还是定义在其他模块的外部函数符号)的引用,统一使用 indirect location 表示,在编译汇编阶段留空(记录在 relocation table 中),等待 linker 在 relocation 阶段填写;
它们最终一定会在链接结束都放在
.text段,并且相对位置在 load time 前就能确定。因此直接使用相对位置表示,这样在 OS 加载阶段就不用修改这些引用的相对位置了,只需要修改定义的绝对位置就行;
对于所有链接器函数符号 的定义,由 linker 先填写在 executable file 中的地址位置(offset),而真正在 memory 中的位置就可以按照在 executable file 的偏移量直接计算出来了(函数所在的
.text段在 virtual memory 中的偏移为0x400000);对于所有链接器数据符号 的引用:
对于
mov涉及到的地址,统一使用%rip表示,偏移量在编译汇编阶段留空(记录在 relocation table 中),等待 linker 在 relocation 阶段填写;对于直接使用数据的地址的情况,在 relocation
.data段完成后,取计算后的最终 memory 中的地址即可;
对于所有链接器数据符号 的定义,由 linker 先填写在 executable file 中的地址位置(offset),而真正在 memory 中的位置也可以直接计算得出(数据所在
.data段在 virtual memory 中的偏移为0x600000);提示:此处请回顾前面的知识点:“为什么编译器要帮助静态局部变量(局部符号)进行重命名?”
以上的规则,即便程序使用静态、动态链接库,也是遵守的。只不过涉及动态链接库的时候,有些链接器符号的定义、引用即便是 linker 结束也不会填写,而是留给动态链接器(dynamic linker)来填写。以后涉及动态链接库再详细叙述。
至此,链接器的工作完成了。但是有个问题,程序还需要加载到内存中执行,那么放在 executable file 中的各个段是如何加载到内存里的?要 copy 多少、抛弃多少?如何给这些 链接器符号定义 一个最终的绝对地址?
15.4 Post-linking: Load Executable File into Memory (Load-time)
理论上,编译器、链接器已经帮我们用相对地址处理好了绝大多数的符号引用,只需要 OS 在 load-time 将程序载入内存时,指定一些关键符号定义在虚拟内存中的绝对地址就行。
那么 OS 是如何将 ELF 的 Executable Object File 加载到内存中去的?
要理解这一点,我们还要知道从 多个 ELF Relocatable Object File 链接为 一个 ELF Executable Object File 后的文件结构,如下图:
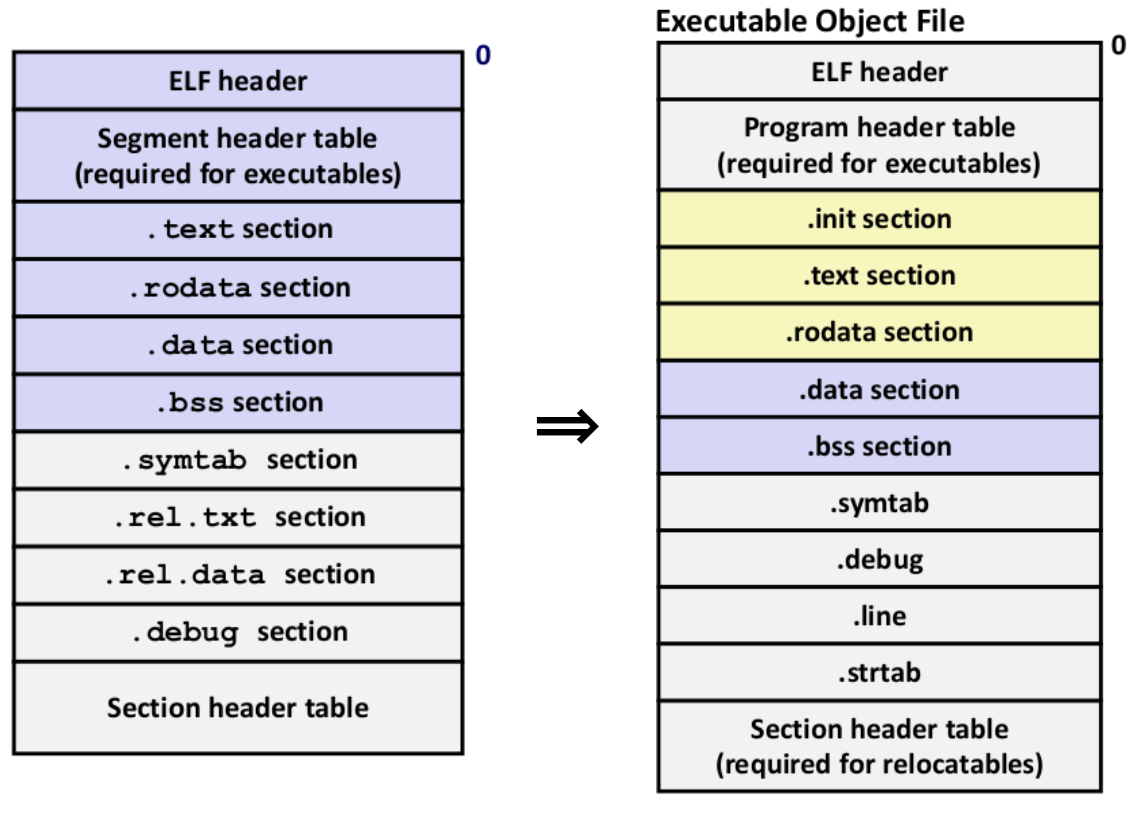
这个时候,注意到几个变更点:
多了
.init部分,这个部分实际上也可以算.text的一部分,是给主程序运行提供固定准备工作的代码;.init、.text、.rodata用黄色标注,提示内存权限为只读区域(这三者中前两个还允许执行);.data和.bss用深蓝色标注,提示内存权限可读可写不可执行;因为 linker 的 relocation 操作已完成,所以
.rel.*部分的所有信息在生成 executable 的时候被抛弃了;多了一个
.line部分,其作用和.debug类似,关联了源代码行数 和 汇编位置的关系;标注了
.strtab部分,其作用是:存储程序用到的很多常量字符串,不仅仅有程序内部的字符串常量,还有链接符号名、链接节名,每一个字符串以 ’\0’ 分隔,然后 ELF 文件使用字符串时,只要使用在字符串表中的偏移来引用字符串就行,事实上,
.strtab部分并不是多出来的,它在 Relocatable Object File 里面也有。只不过在 link 阶段不关心它罢了。你可以使用
readelf -S <object file name>来查看 object file 中的所有表的分布情况;
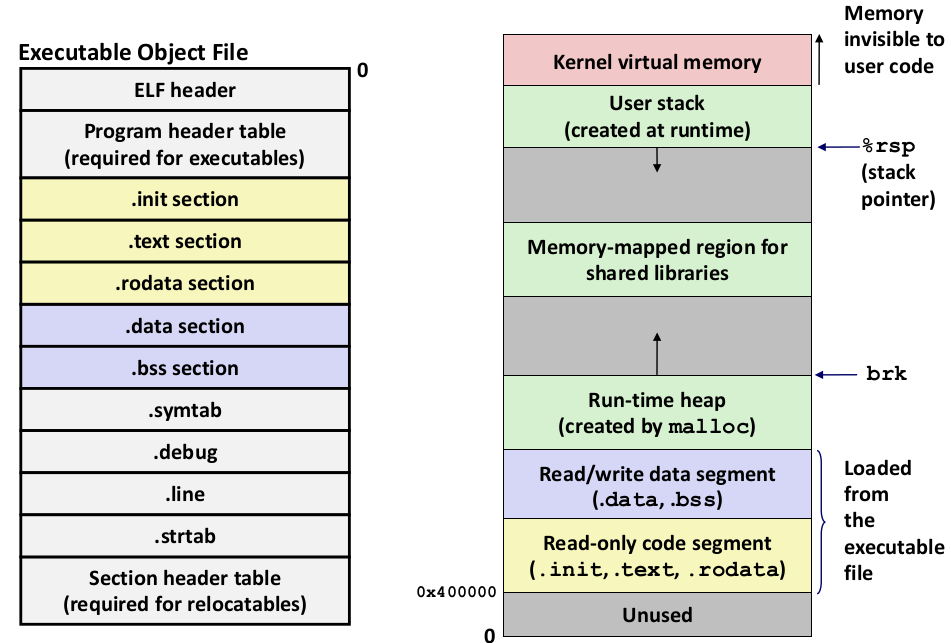
然后,OS 将 Executable Object File 加载到 Memory 的过程就比较方便了:
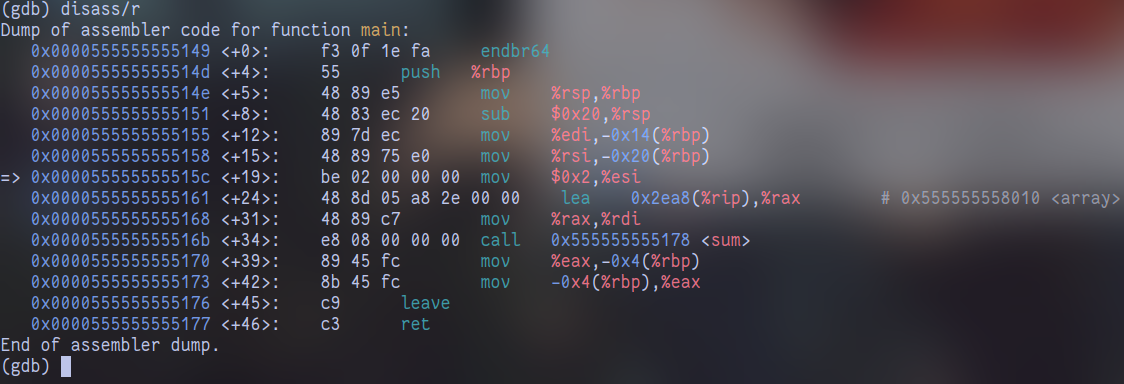
最终,我们以 main 函数中一句调用 sum 函数为例,看看它在链接前后、加载前后的变化:
在编译汇编结束、链接前(main.o):
xxxxxxxxxx0000000000000000 <main>: # ... ... 22: e8 00 00 00 00 call 27 <main+0x27> 23: R_X86_64_PC32 sum-0x4 # Relocation entry # ... ...在链接结束、装载运行前(program.d):
xxxxxxxxxx0000000000001149 <main>: 1149: f3 0f 1e fa endbr64 114d: 55 push %rbp 114e: 48 89 e5 mov %rsp,%rbp 1151: 48 83 ec 20 sub $0x20,%rsp 1155: 89 7d ec mov %edi,-0x14(%rbp) 1158: 48 89 75 e0 mov %rsi,-0x20(%rbp) 115c: be 02 00 00 00 mov $0x2,%esi 1161: 48 8d 05 a8 2e 00 00 lea 0x2ea8(%rip),%rax # 4010 <array> 1168: 48 89 c7 mov %rax,%rdi 116b: e8 08 00 00 00 call 1178 <sum> # 已经填上 indirect location 了 1170: 89 45 fc mov %eax,-0x4(%rbp) 1173: 8b 45 fc mov -0x4(%rbp),%eax 1176: c9 leave 1177: c3 ret在装载运行时(gdb dissasembly):
15.5 Libraries & Link
15.5.1 Static Libraries & Link
考虑一种情况,当我们想使用外部库来链接的时候,总不能要开发人员在编译工具上包含源文件再编译吧?那这就没法发挥链接的优势了。
人们在早期使用一种 静态链接 的技术,将外部库打包成一个 archive file(*.a,在 Windows MSVC 上是 *.lib),方便人们在编译好自己的源代码后,直接链接使用,如下图所示:
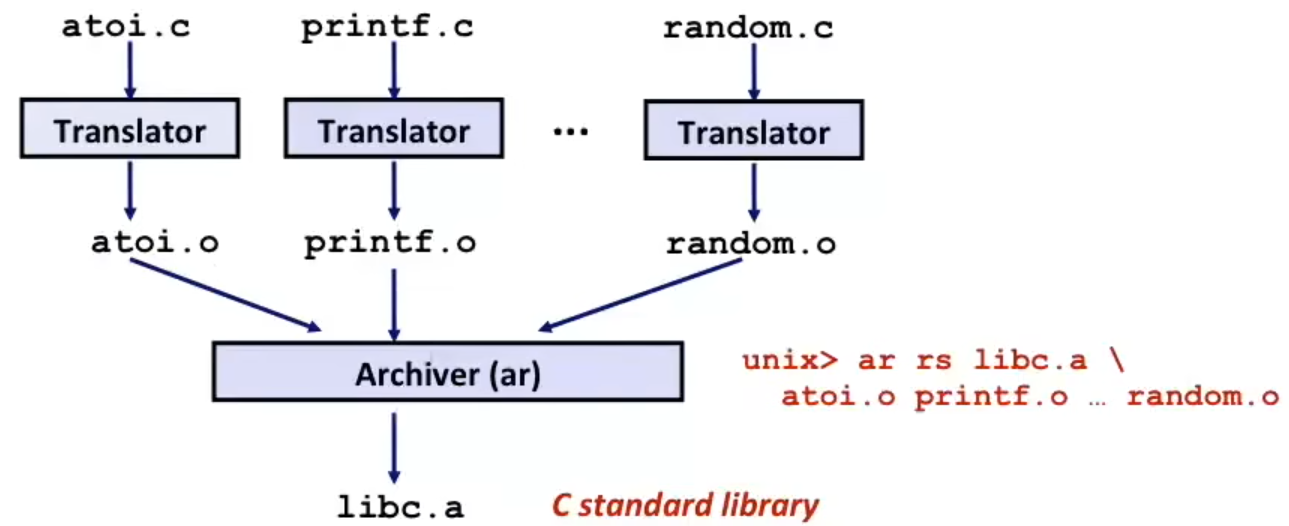
静态链接库的本质上,就是将编译好的 *.o relocatable object files 以一种特定的格式打包起来,头部含有每个 relocatable object file 的信息(例如名称、字节偏移量),在链接时,链接器看你所引入的外部函数在哪个 relocatable object file 中,然后链接特定的 *.o 即完成链接过程。
也就是说,静态链接库只支持 link-time linkage,不支持 load-time 和 run-time loading。
注:
GCC打包所使用的套件是ar,一般你调用gcc时如果要打包为静态链接库,那么它就会自动派上用场。你还可以用
ar -t <archive file name>来查看一个 archive 中打包了哪些 relocatable object file;
它的缺点显而易见,如果你想更新静态链接库,那么不仅要重新编译这个静态链接库,其他所有用到这个静态链接库的其他程序也全部需要重新编译(因为只是用了 archive 里面的 relocatable object file)。
重要补充:那么,如何告诉
gcc的链接器,指定链接某些 static libraries 呢?事实上,你可以使用
gcc的-L<libDir>指定链接器要首先额外查找链接库的目录(相当于CMake的target_link_directories),也可以使用-l<libName>指定特定的链接库。(另注:
libName不是文件名,而是库名,如果你没有修改库的默认前后缀规则的话,大部分的库前缀是lib,静态链接库的后缀是*.a/lib,例如libmime.a的库名是mime)但是,命令行的顺序很重要!原因是
gcc命令行的搜索算法:它如果遇到一个程序中有 undefined references,才会记录到运行时表中,此后遇到一个-l包含了一个库,就更新一下这个列表。当扫描完成后,如果还有 undefined references,那么抛出错误。因此如果你把主程序放在命令行参数后面、要链接的库放在前面,就会抛出 undefined references 错误,你还以为链接的没问题……
15.5.2 Shared Libraries & Link
更新一点才设计出的打包和链接的方法是使用动态链接库。这种方法规避了 static libraries 中的一些缺点(例如:更新库的版本的话所有使用的程序就要重新编译、每一个使用了库的程序都会在 executable 中保留一份 *.o 占用空间……);
与静态链接库不同,共享库(动态链接库)既允许 link-time 链接库(!!但不是 relocation 到 executable file 中 !!具体怎么做下面讨论),又允许 load-time 和 run-time 才加载库。
优点是,不需要占用主程序大小,而且更新动态链接库只要不改 API,就无需重编译使用它的文件。
那么前面有个遗留的问题就出现了。既然你能在 load-time,甚至 run-time 才加载这个库,那么链接器怎么 relocation 你用到的外部符号?
答案是,普通链接器(如 gcc 中的 ld)会在使用到这些存在于动态链接库的引用 仍然留空,交给 dynamic linker(动态链接器,在 Linux 系统上依靠 ld-linux.so)来运行时 / 加载时填写。
那么如果是 link-time 链接库,链接器因为不会提取当中的 *.o,所以链接器对动态链接库的做法和对静态链接库的处理方法肯定不一样啊!
因此,链接了动态链接库的程序,即便是在链接完成后形成了 executable file,它还是 partially linked 的状态,有些地方仍然留空,并且记录在 section header table 中(回忆 ELF 的结构),让 load-time 操作系统、run-time 动态链接器来处理这个填写地址的问题。
补充:这下你能明白,为什么别人给你一个可以开发的 SDK 库的时候,不仅要给你
*.a/so,还有给你头文件了吧?因为你需要外部符号声明来让链接器知道你要用、你能用哪些链接库内的函数(提示:
#include只是在 C preprocessor 中简单的将文件内容包含进来,做简单的插入扩展和处理)。
如下图所示,这是个 load-time 加载动态链接库的例子:
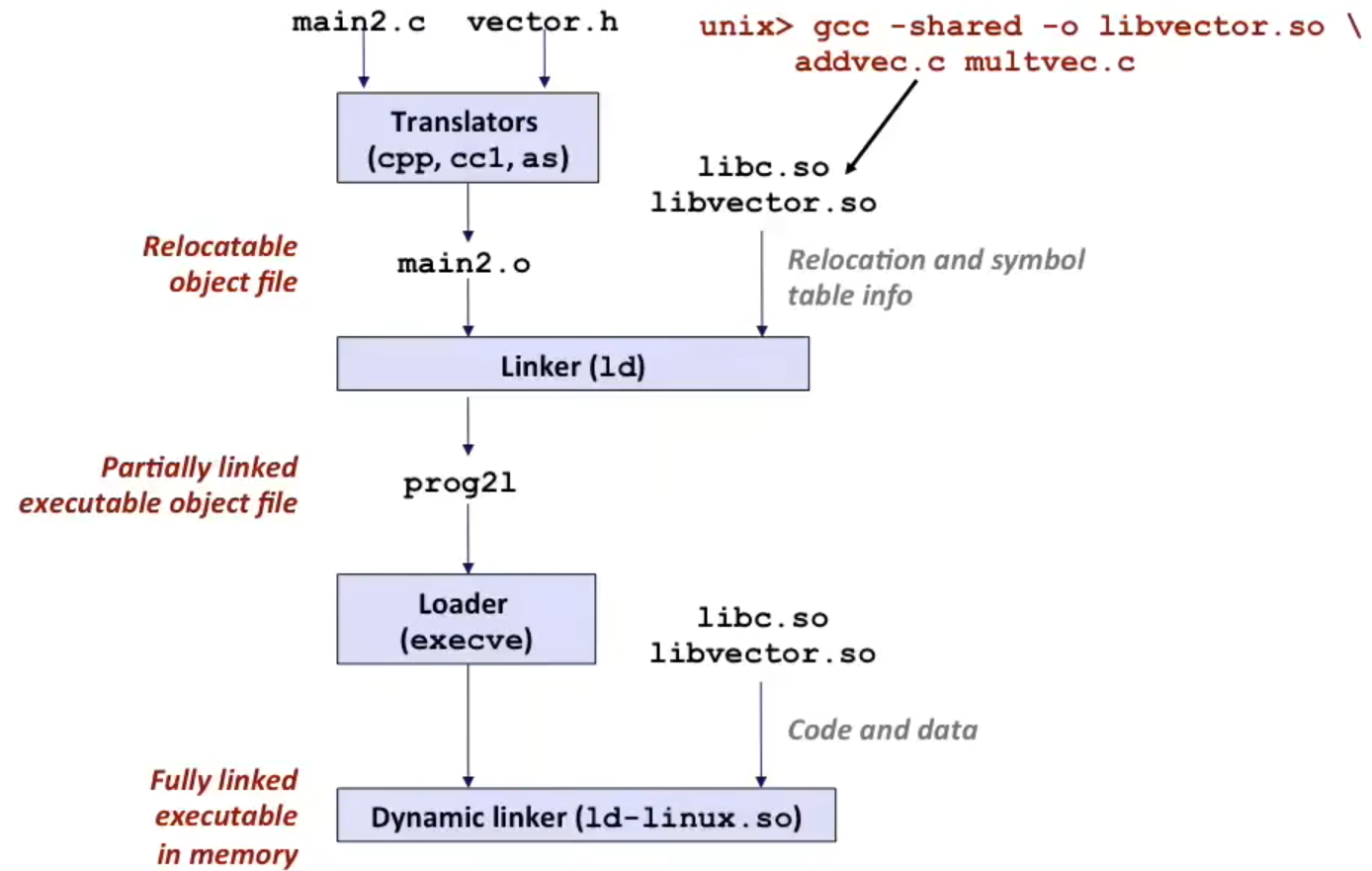
如果你在程序中使用了 dlopen,那么就是 run-time 加载动态链接库了。
这样比较抽象,我们举两个例子。
假设我们用来编译动态链接库的源文件是这个:
xxxxxxxxxx/* file: testShared-sum.c (用于创建动态链接库的文件) */int sum(int a, int b) { return a + b;}编译指令:
xxxxxxxxxxgcc -shared -fPIC testShared-sum.c -o libtestShared-sum.so得到动态链接库后,接下来,首先是 load-time 使用动态链接库的例子:
xxxxxxxxxx/* file: testShared-loadtime.c */
// declaration in shared library for load-timeextern int (*sum)(int, int);
int main() { printf("%d\n", sum(1, 2)); return 0;}这个例子应该这么编译:
xxxxxxxxxxgcc testShared-loadtime.c -L. -ltestShared-sum -o testShared-loadtime这种方法一定要把 testShared-sum.so 放到 /etc/ld.so.conf 指定的目录下,或者你可以向 /etc/ld.so.conf 或 向 LD_LIBRARY_PATH 环境变量加入这个动态链接库,不然操作系统在加载时找不到它!
另一个是 run-time 使用动态链接库的例子:
xxxxxxxxxx/* file: testShared-runtime.c */
int main() { // declaration in shared library for run-time int(*sum)(int,int); void *handler; if (0 == (handler = dlopen("./libtestShared-sum.so", RTLD_LAZY))) return 1; else sum = dlsym(handler, "sum"); printf("%d\n", sum(1, 2)); dlclose(handler); return 0;}这个例子编译方法类似:
xxxxxxxxxxgcc testShared-runtime.c -L. -ltestShared-sum -o testShared-runtime以第一个例子 load-time 加载动态链接库为例,我们将链接完成的 executable file 反汇编,这个时候会发现:
即便是 executable file,它在对动态链接库中的外部符号引用的时候,你会发现 sum 和 printf 一样,它们不在 .text 段,而是都放在 .plt 段,并且符号后面有 @plt 标识,如下:
xxxxxxxxxx# ... ...
0000000000001060 <printf@plt>: 1060: f3 0f 1e fa endbr64 1064: f2 ff 25 5d 2f 00 00 bnd jmp *0x2f5d(%rip) # 3fc8 <printf@GLIBC_2.2.5> 106b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
0000000000001070 <sum@plt>: 1070: f3 0f 1e fa endbr64 1074: f2 ff 25 55 2f 00 00 bnd jmp *0x2f55(%rip) # 3fd0 <sum@Base> 107b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1) # ... ...在 main 函数中的 sum 和之前处理外部符号的规则一样(indirect location 相对位置),不过指向的是 .plt 段的函数:
xxxxxxxxxx# ... ...0000000000001169 <main>: 1169: f3 0f 1e fa endbr64 116d: 55 push %rbp 116e: 48 89 e5 mov %rsp,%rbp 1171: be 02 00 00 00 mov $0x2,%esi 1176: bf 01 00 00 00 mov $0x1,%edi 117b: e8 f0 fe ff ff call 1070 <sum@plt> 1180: 89 c6 mov %eax,%esi 1182: 48 8d 05 7b 0e 00 00 lea 0xe7b(%rip),%rax # 2004 <_IO_stdin_used+0x4> 1189: 48 89 c7 mov %rax,%rdi 118c: b8 00 00 00 00 mov $0x0,%eax 1191: e8 ca fe ff ff call 1060 <printf@plt> 1196: b8 00 00 00 00 mov $0x0,%eax 119b: 5d pop %rbp 119c: c3 ret# ... ...
15.6 Library Interpositioning
15.6.1 Overview
在链接库的技术中,有一种强大的技术叫 “库打桩”,它可以让开发者 截获对库的任何函数调用,在此基础上进行其他操作。
你可以理解成 Java、Python、TypeScript 中的装饰器。
在 C 中,库打桩的应用有:debugging(gdb 就采用了这种技术)、profiling(某个函数调用次数或时长)、检查内存泄漏和追踪地址调用等等。
(以及软件优(po)化(jie)方面
15.6.2 Usage: Compile-time Interpositioning
如果是编译时库打桩,那么使用方法很朴实,就是定义一个包装函数 wrapper,然后用宏替换原来的函数,不过记得名字写的和要调用的库头文件名字一致。
最后记得指定 -I 参数(相当于 CMake 的 target_include_directories),这样标准库就会被自己写的 “包装函数库” 覆盖了。
15.6.3 Usage: Link-time Interpositioning
如果情况不允许在编译时库打桩(即不能重新编译原程序,但可以重新链接原程序),还可以链接时库打桩。
这时候需要用到 GCC 的一些链接选项。例如如果想包装 malloc/free 函数,那么在源文件中这么做:
xxxxxxxxxx/* file: inter_malloc_free.c */
void *__real_malloc(size_t size);void __real_free(void *ptr);
void *__wrap_malloc(size_t size) { /* your implementation */ }void __wrap_free(void *ptr) { /* your implementation */ }在最后链接时,使用链接器选项 -Wl:
xxxxxxxxxxgcc -Wall -Wl,--wrap,malloc -Wl,--wrap,free -o interd origin.o inter_malloc_free.o其中 , 会被 GCC 自动解析为同一个参数中的空格。
这个 -Wl,--wrap,malloc 的意思是,将链接符号表中所有 malloc 符号全部解析为 __wrap_malloc,原 malloc 符号会被解析为 __real_malloc(这样不会冲突或者导致符号消失,free 同理)。
15.6.4 Usage: Load / Run-time Interpositioning
甚至也可以在加载时、运行时库打桩。
这个时候,你需要生成的自制链接库中需要包含一个与想要替换的库函数的签名相同的函数,但是在你的函数中,使用 dlsym(RTLD_NEXT, "<funcName>"),表示在目前栈上的动态链接库区域,查找下一个叫 funcName 的函数的函数地址(也就是被你覆盖的函数地址),进行相应操作即可(无需 dlclose)。
最后,在加载前,修改 LD_PRELOAD 环境变量(这样才能让操作系统加载时找到,并且先于其他库加载,达到运行时覆盖的目的),表示先加载的库,指定为你打桩的库路径就大功告成了。
Chapter 16. Virtual Memory
16.1 Design a Memory Allocator
16.1.1 Prerequisites & Issues
xxxxxxxxxxvoid *sbrk(int incr)If successful: It returns the old value of
brk;If unsuccessful: It returns
–1&& setserrnotoENOMEM;If
incris zero: It returns the current value;incrcan be a negative number;
以上函数调用返回的一定是 double-word alignment(8 bytes 对齐)的地址。因为要适应所有数据结构的内存创建操作。而结构体又需要对齐(结构体对齐的原因见前),最大对齐要求是 8 bytes,所以 malloc 也会在分配时对齐 8 bytes;
内存分配器的要求:
Handle arbitrary sequence of requests (随机的申请序列);
No prior knowledge;
Making immediate responses to requests (不能批处理,必须立即处理);
No batching;
Using only the heap (只能用 heap);
Aligning blocks (8 bytes 对齐);
Not modifying allocated blocks (不允许在应用层随意切换分配块的位置,即改变 VM 位置);
但操作系统可以改 MMU 影响虚拟内存的映射;
内存分配器的性能目标(对于一串分配指令
最大化 throughput(单位时间内完成分配指令的数量)、最大化 utilization(尽可能集中的 payload
两种碎片:Internal / External Fragmentation
Internal Fragmentation 定义为:实际被分配了,但不是用于存放用户数据的空间。主要产生于对齐要求 / 维护堆元数据的空间开销 / 编译者的显式要求(例如不允许 split block);
内部碎片只与之前的 requests 有关,可以从外部衡量;
External Fragmentation 定义为:总剩余空间足够 (enough aggregate heap memory),但是每个空余块大小不足;
外部碎片与未来的 requests 有关,因此难以测量;
内存分配器实现细节阐明:
free只传一个指针,怎么知道它指向已分配空间的大小?解决方案:开头留出 4 bytes 的 meta-data,表示这个块的大小;
如何跟踪已释放块的位置?
解决方案:每个分配块设计成如下 implicit list 的格式(类似单向链表):
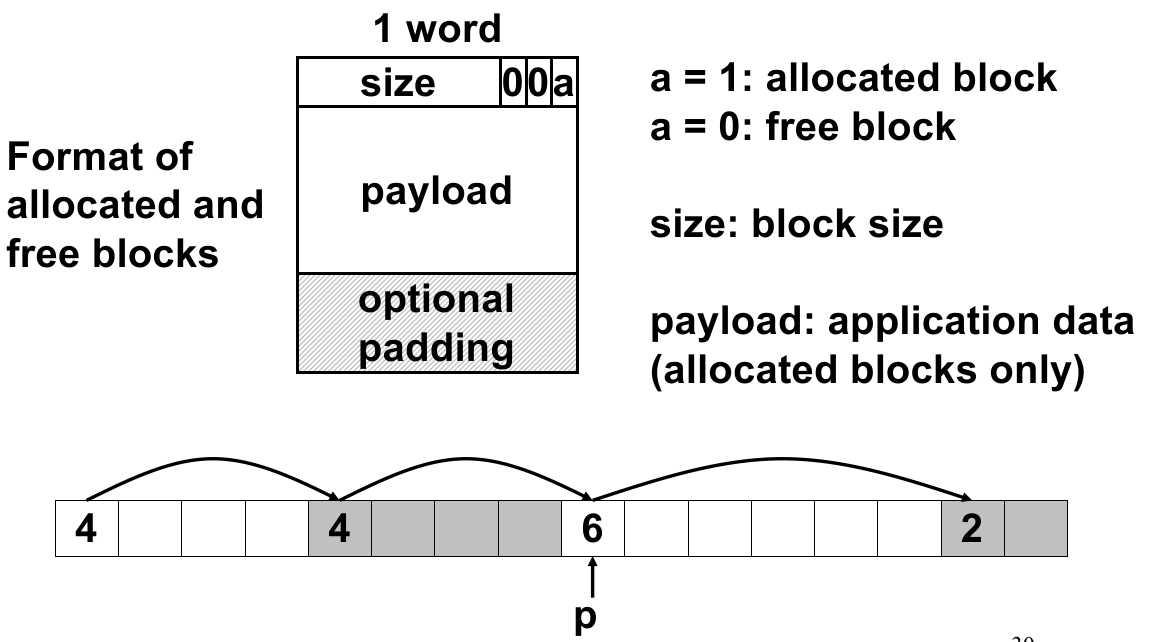
其中
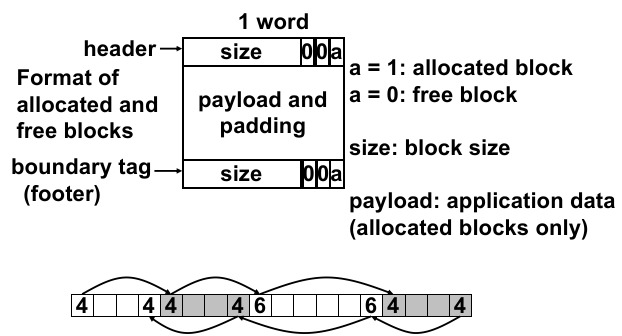
size是包含 meta-data 的大小(因此不等于malloc传入的数据);因为
size是 8 对齐的,所以低 3 位一定是 0,因此可用于保存其他信息(例如上面的是否 allocated);如何从当前空闲块中选择分配哪些部分?
有几种选择方案:First fit、Next fit、Best fit;
first fit:从 heap list 的最开始查找,选择最开始的、足够大的空闲区域;
优势:线性时间的分配和释放操作;
劣势:造成列表前端的外部碎片、内部碎片增多;
next fit:从上一次 fit 的位置向后查找,选择下一个足够大的空闲区域;
优势:线性时间的分配和释放操作,并且 utilization 足够分散;
劣势:实验证明这样的方法会导致更多 fragmentations;
best fit:从前向后查找列表,选择大小最接近要分配大小的空闲区域;
优势:最大化 utilization,减小 fragmentation 平均大小,从而减少 fragmentation 数量;
劣势:算法运行耗时更长(每次都是
如何处理 extra space(向空闲位置分配后,但没用完)?
解决方案:split;即在分配时,修改空闲单元的大小。
如何在已释放的块的位置分配新的块?如果释放的时候仅仅是标记一下,那么会导致块越分越小,产生越来越多的 external blocks(false fragmentation);
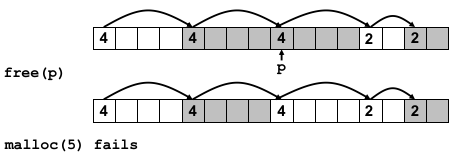
解决方案:coalescing;即 free 时检查空闲块上一个(和下一个)是否空闲,如果是就合并一次。
问题是怎么合并前一个空闲块?如果不能合并前一个空闲块,那么问题还没有解决;
那么就 bidirectional coalescing(双向合并),将 implicit list 的结构换成双向链表的结构:
这样合并操作只有 4 种情况:
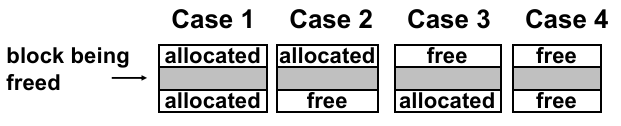
每次 free 的时候判断是何种情况。根据最大的 free space 范围,只需修改整个空闲区域的头尾 meta-data 信息即可。
16.1.2 Implementation
按照上面的问题约定,我们可以设计出如下的内存分配器管理的堆列表结构,如下图所示:
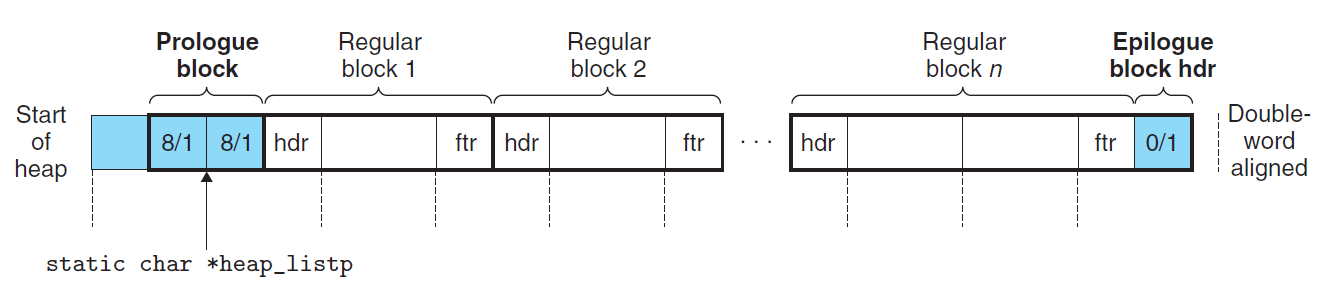
注意到,对于一个堆列表结构而言:
列表开头是一个 4 bytes 的 reserved word(保证每个列表的 meta-data 区域是 4 对齐,分配区域的指针是 8 对齐);
紧接着是 8 bytes 的 prologue block,包含 2 个 表头信息(4 bytes)两个表头信息是固定的(
8/1代表word size = 8,bit allocated = 1);prologue block 存放的是
heap_listp指针,用于表明表头的位置。相当于链表中的表头指针。之所以用 2 个 4 bytes meta-data 是为了方便对齐。
标识头、尾的 entry 使用 1(allocated)标识。表示已被分配,不可继续划分。
表的最后一定是一个 epilogue block,包含一个表头信息(固定
0/1),标识堆列表的结尾位置(size = 0);中间存放的就是分配的 block,
malloc可以在空间不够时扩充堆顶,移动 epilogue block 的位置,创建新的 entry meta-data;
16.2 Improve Allocator's Performance
16.2.1 Method 1: Explicit Free Lists
使用真正的指针来串起所有空闲块;
不一定按照地址顺序连接;
使用空闲块中原来存放 payload 的空间(大于等于 8 bytes)来存放前后两指针;
当产生新的空闲块时,如何插入 free list?
策略 1:使用 LIFO 策略插入 free list:向空闲块的开头插入;
优势:实现简单,
劣势:产生的 fragmentation 比顺序的地址还要多;
策略 2:使用 address-ordered 策略:插入 free list 时比较地址大小;
优势:改善了 LIFO 的 fragmentation 的 utilization;
劣势:需要搜索,时间开销增大;
策略 3:使用 simple segregated storage 策略:
按空闲块长度范围维护多个 free lists;
不存在 splitting 操作;
当要分配
存在
不存在
当要释放
理想情况下,
优势:时间复杂度更好;
劣势:产生碎片数量更多;
策略 4:使用 improved segregated storage 策略(segregated fits):
按空闲块长度范围维护多个 free lists;
当要分配
存在
如果没找到,则扩展堆的空间;
当要释放
优势:
16.3 Garbage Collection
内存管理器如何判断已分配的部分是应该被回收的(以后不会被用到)?
经典的方法是判断这块内存的 reachable(可达性)。
那么怎么判断这块内存的可达性?在 C/C++ 中可以通过当前程序中是否有指向这块内存的指针判断。但是由于 C/C++ 允许强制类型转换,因此 C/C++ 如果要有 GC,就是保守(conservative)的,把所有的整型都看作指针。
16.4 Virtual Memory: From Hardware's Perspective
分时复用 CPU 资源:进程轮流使用 CPU 核心(Context Switch,高频切换)、由 OS 决定;
进程一章介绍了抽象:Logical Control Flow。每个进程都感觉自己独占了计算机资源,不用担心寄存器、CPU、内存等的重要数据被更改;
之前从 Exception Control Flow 的机制介绍了进程间的 CPU、寄存器等 CPU Context 的隔离方法。
接下来的几个小节会介绍一种内存的隔离机制:虚拟内存,来保证进程间内存数据隔离,确保安全性、方便性。
16.4.1 How to Design Memory
为了隔离各个进程的内存状态,那么应该怎么设计?有一些思路:
以约定的方式划分区域:安全性和容错性差,没有实质上的隔离抽象(例如编译器还要考虑当前操作系统正在运行的程序);
模仿 Context Switch,直接将总体物理内存全部保存到磁盘做 “Memory Switch”:效率低下,存储空间要求高;
上面两种方法都不行。我们吸取教训,还是先总结一些必须要遵守的条件:
不同进程的内存地址空间具有独立性(彼此隔离,实质上的隔离);
进程不能直接使用物理地址访问内存(缺乏管控);
不同进程的内存地址空间具有统一性(易于开发,具有隔离抽象);
每个进程看见的地址空间都是连续的、统一的;
不同进程能够使用的内存总量可以超过物理内存总量;
同时要保证性能开销较小;
也就是说,操作系统为了将离散、有限的资源抽象为连续、近乎无限的资源给应用程序使用,并将各个程序隔离开,就需要采用一种措施,这个措施就是 虚拟内存抽象。
虚拟内存的抽象是操作系统和硬件配合完成的。操作系统维护了一个从物理内存(简称 PM)到虚拟内存(简称 VM)的映射(还记得 Memory Hierarchy 最后介绍的 TLB cache 吗?就是为这个准备的),将主存(main memory)上离散的空间映射到连续的虚拟内存空间上。
这个 “映射” 存在处理器芯片的 MMU(Memory Managing Unit,硬件层面) 中,这个映射的数据结构被称为 页表。页表由 OS(软件层面)来设置和管理。
一个页是固定大小 4K(
)bytes;
为了充分利用主存(物理内存)的空间,页表将 PM 和 VM 切分为很小的块(大家能懂往瓶子里装石子、沙子、水的道理吧?),这些很小的数据块被称为 页,而页表就是将这些虚拟内存页映射到物理内存页,如下:
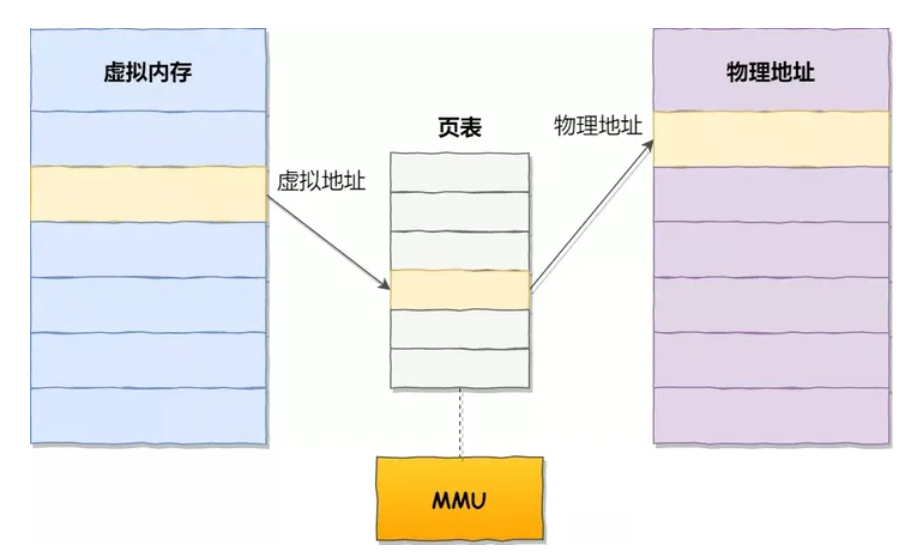
那么这样能拥有如下优点:
充分利用有限物理空间,为应用程序提供连续的虚拟空间;
很容易实现物理内存的重分配、不同进程能够使用的内存总量可以超过物理内存总量;
虚拟地址和物理地址的映射(页表数据)可以在 OS 运行时更改,动态的给不同进程分配空间;
每个应用程序间的虚拟内存很容易实现隔离(页表数据不同就行,这样哪怕相同的虚拟地址,映射到的物理地址也不同),相互不影响对物理内存的访问;
保证权限和安全性:操作系统可以在页表中规定权限,例如不允许用户态程序访问进程的内核空间;
每个应用程序所能看到的就是完整的虚拟内存,其中有独立的运行时栈。运行在 CPU 上的应用程序也直接使用虚拟地址,因为 VMA 出 CPU 前会经过 MMU 转换为物理地址,再向主存硬件请求。
但是!为了节约空间,操作系统不会一次性将全部的虚拟内存(地址 0 ~ FFFFFFFF)全部用页表映射上物理内存(一来大小不够,二来浪费资源),只是先为虚拟内存的必要部分(例如程序栈的 data 段、code 段、shared libraries 段、stack 段等)分配物理内存、记录在页表上。其余部分被称为未被分配的段。
未被分配的段又分为 Uncached area 和 Unallocated area;
Uncached area 的出现可以分成两种情况:
应用程序确实申请了一段空间,但是比较大,OS 认为有一部分应该不会立即访问(暂时不必要分配物理内存),因此 OS 会在另一区域记录一下(例如磁盘中的 swap file,但实际上并不会……),但是在页表中只挂载一部分;这个另一个部分没有挂载到物理内存的区域就是 uncached area;
例如 mmap 1G 不会写页表、PM full & evict 时才会写 disk address
Unallocated area 就是应用程序没申请、OS 也没挂载到物理内存的虚拟内存区域。
16.4.2 Page Table
那么页表的结构是什么样子的?
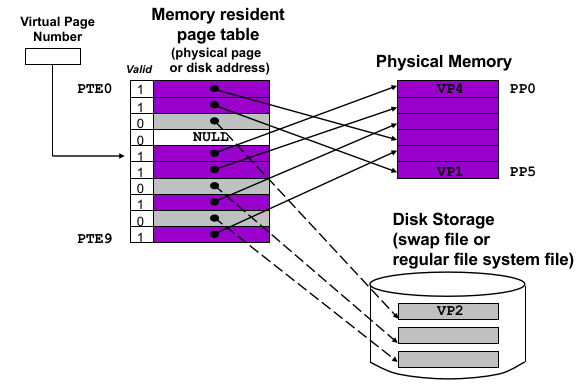
注意到,每个页会被编号(在虚拟内存上的页被称为虚拟页,即 VP / Virtual Page,对应物理内存上的页被称为物理页,即 PP / Physical Page)。所以对 64 位机器(假设真的有 64 位物理内存)而言,这个编号大小是 64 - 12 = 52 位(减去 12 是页的大小
而页表只是将 VPN(Virtual Page Number)翻译到 PPN(Physical Page Number),因为是一页一页地映射。
MMU 在翻译虚拟地址时,只会看 valid 位,如果有效就直接翻译,无效则抛出 ECF Page Fault;
由于 OS 对于 uncached area 的处理是放到磁盘里(page table entry 中记录磁盘地址),并且 valid = 0,这就是为什么应用程序访问 uncached area 和 unallocated area(这里的 page table entry 是 NULL,不指向磁盘地址)都会导致 page fault;
在 CMU 的书上一开始的部分,都是这么描述的:
如果是 uncached area,entry 一定指向一个磁盘地址(即便 OS 要懒加载,也至少要填磁盘地址);
如果是 unallocated area,entry 直接是 null;
如果是 allocated area,entry 一定填写了一个物理页号;
这种解释非常简单,也通常很有效。
但实际上现代的 OS 并不是这么做的。大部分的情况下,OS 应该是这么处理 page table 的:
所有的页都分为 文件背景页(file-backed page)和 匿名页(anonymous page)。
比如进程的
.code/.data、mmap映射的文件都是 文件背景的,而进程的堆、栈都是不与文件相对应的、就属于匿名页。而 OS 对于虚拟内存到物理内存的映射是懒加载(demand paging)的:
假设当前机器的物理空间充足(足够多空闲的物理页)时,
对于匿名页,例如如果程序想要在栈 / 堆上分配一段 比较大的、不需要初始化的 虚拟内存页 到物理内存页,那么 OS 不会立即将这段虚拟页映射到物理页,而是几乎不作任何操作。只是在内核中标记这段内存是应用程序申请的;等应用程序真正访问的时候,再触发 page fault,OS 再动态地为一个虚拟页分配一个物理页。
怎么标记的?通过 VMA 数据结构。后面详细介绍。
例如,我们如果在内存中申请了一个超大数组,占用了 8 个虚拟页,OS 不会立即分配 8 个物理页,而是什么都不做(也不填 entry),只是知道已经给程序分配了这段虚拟页(匿名页)。等到真正访问其中一个虚拟页时,会触发 page fault,此时 OS 才在将这个虚拟页挂载上物理页;
再例如,我们使用
malloc在堆上申请了相当大的一段空间,OS 也不会填页表。这种策略被称为 demand paging;对于文件背景页,例如如果程序加载时,想从可执行程序加载到内存中。我们以
.data段为例,假设有一大段数组空间被分配了数据,OS 加载时也不会立即将这个 ELF 文件中的数据需要的空间分配物理页、并全部复制到虚拟内存中(都是 demand paging 吗?),等访问这块空间、硬件抛出 page fault 时,再分配物理页、将磁盘的该部分数据复制到对应虚拟页中。再例如,假设程序执行中,执行了
mmap将很大的文件(1G+)动态映射到虚拟内存中,OS 甚至不会向页表中填入磁盘地址,因为虚拟内存页实在太多了。OS 会在内核其他地方为这个地方标记一下,等访问到这个区间的时候再挂载物理页(挂载到 page cache 上,因为 OS 会在内核中进行 page cache,cache 在一块物理内存中)。假设当前机器的物理空间不足(没有足够多空闲的物理页)时,类似缓存的 evict,
对于匿名页,磁盘上没有对应的文件,只能常驻内存。但是如果分了 swap 分区,那么 OS 可以将不活跃的页交换到硬盘中(swap分区可以当做针对匿名页伪造的文件背景),缓解内存紧张(称为 swap-out);
对于文件背景页,直接将这个不活跃虚拟页对于的物理页内容重新存到这个磁盘文件中,将 page table entry 改成磁盘地址(称为 page-out),这样就能空出物理页给其他虚拟页使用;
但是前者能被 OS 恢复(swap in,OS 从页表 valid = 0 entry 存的磁盘地址取出页的内容,随便放到一个空闲物理页上,再在页表上建立 valid = 1 的 entry),而后者 OS 认为应用程序自己有错,会向应用发送 SIGSEGV(软件层面的信号)停止程序。
可以看到,Recoverable Page Fault 非常耗费时间(从磁盘搬运),但是由于程序的 temporal locality,程序不会经常使用 uncached area 的内容,所以就能维持性能;
但是,如果当前所有程序的虚拟内存总的 working set 大小大于物理内存的大小,就会频繁存在 Recoverable Page Fault(也就是从 swap 磁盘空间加载、存放的交换过程),则会导致 thrashing(性能抖动);
此外,还需要补充两点。
一点是,除了上面叙述的好处以外,这种虚拟页和物理页的抽象还有几个好处:
能够实现进程间某些空间的共享。例如只读的库空间可以被 OS 挂载到同一个物理页上;
由于加载页时 on demand page,因此哪怕是连续申请的虚拟页也不必同时挂载、不必挂载到连续的物理页上。
另一点是,一个 page table 的 entry 中大致内容是什么:
Physical Page Number:物理页编号。我们假设一个 64 位程序真的会使用
实际上,一个 64 位程序只能使用到 48 位的物理地址空间。因为目前主流 64 位硬件规定,虚拟地址的高 16 位地址必须和第 48 位数码一样(主要是硬件没
然后在软件中这么规定:虚拟地址中,用户态程序使用前 17-bit 全为 0 的地址空间(
0x0 ~ 0x0000_7fff_ffff_ffff),内核态使用前 17-bit 全为 1 的地址空间(0xfff8_0000_0000_0000 ~ 0xffff_ffff_ffff_ffff)。二者之间分开很大一部分区域,全部不允许进行挂载物理页(硬件规定)。

valid bit:如前面介绍的,指示当前 entry 是否能被 MMU 直接翻译;
permission bits(
SUP、READ、WRITE、EXECUTE等):为了实现每个页的权限管理页表项中还放了一些权限位,指示当前页是否为内核空间、可读/可写/可执行 空间。这下除了访问 unallocated area 会导致 page fault,permission bits 和当前操作不符时也会导致 page fault(unrecoverable);
这不是全部的内容。详细内容在下下节讨论。
16.4.3 Address Translation
地址翻译完全由硬件和 OS 配合完成。
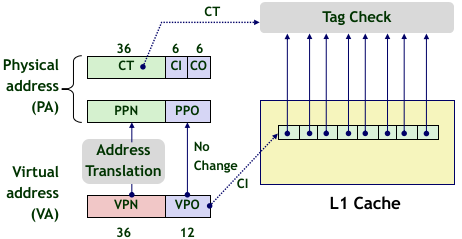
由于虚拟内存是按页映射的,并且地址翻译时都是整个页进行翻译(即翻译 Virtual Page Number 到 Physical Page Number),而页内的偏移量是相同的(VPO = PPO,Virtual Page Offset 和 Physical Page Offset);
所以翻译地址的方法如下:
![]()
于是 CPU 只需要将虚拟地址的前面一部分进行翻译,后面的一部分进行复制。
这个地址翻译规则放在页表中(OS 维护),而 virtual page number 会作为页表的索引,利用存放在 page table base register(PTBR,x86 放在 CR3 寄存器,这不可能放虚拟地址,因为它要用来翻译虚拟地址,显然也是 OS 维护);
页表在内存中保存(进程页表位于一个进程的 PCB 块中),page table base register 则存放当前进程的 page table 的起始位置。
所以,目前翻译过程如下:
当 CPU 根据指令请求一个虚拟地址,会被先传到 MMU 中,MMU 找到 virtual page number,并且根据 page table base register 计算出 page table entry 的物理地址,向物理内存读 page table entry,并检查 valid 和 permission bits:
如果有效,则再按照得到的 PPN 向物理内存读取 Physical Page 并按 Page Offset 通知主存传给 CPU,翻译完成;
如果无效,则抛出 Page Fault,利用 exception base register 进入 OS 的 handler 进行处理;
现在举个例子,以一个小的地址为例,如果一台机器:
14 位长的虚拟地址、12 位长的物理地址;
一个页大小 64 bytes(6-bit 长的 Page Offset);
当前页表内容如下:
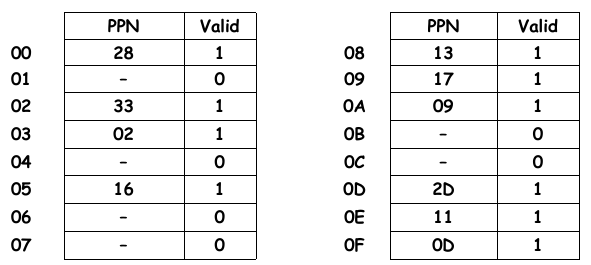
那么可以推出,它的地址 layout 如下:
![]()
假设有虚拟地址 0x3D4(0011 1101 0100),则 PO = 010100,VPN = 1111 = 0xF,PPN(page hit) = 0x0D = 1101,翻译出的物理地址为:PMA = 11 0101 0100 = 0x354;
我们发现一个问题,在上面的步骤中, MMU 无论是取 Page Table Entry,还是按物理地址向主存通知要取指定位置的数据给 CPU,都是直接与主存交互的。这样的效率可能会很慢,也不符合实际情况。
真实情况是,我们应该考虑到在前几章节介绍的缓存,因为 Memory Hierarchy,CPU 对主存的访问间还有一层 Cache(高速缓存器,通常是 L1、L2、L3 Cache),于是更完整的步骤应该是这样的:
当 CPU 根据指令请求一个虚拟地址,会被先传到 MMU 中,MMU 找到 virtual page number,并且根据 page table base register 计算出 page table entry 的物理地址(
PTEA),向 cache memory 请求PTE(page table entry)的具体内容(其中可能发生 cache hit/miss,但最终得到PTE),MMU 检查 valid 和 permission bits:如果有效,则直接取
PTE中 Physical Page Number 翻译完成;如果无效,则抛出 Page Fault,利用 exception base register 进入 OS 的 handler 进行处理;
如果是 recoverable page fault(包括 swap-in/page-in),则会加载要求的 Page 到内存中,即修改 Page Table Entry 的 valid 位 并 挂载对应的物理页。必要时选取 victim page 存回磁盘;
翻译完成后,MMU 将得到的物理地址通知 cache memory 传给 CPU;
![]()
Tips.
我们发现,上面的步骤中,传给 Cache 的
PTEA是物理地址。现在主流的机器的 cache 也都是使用物理地址来做缓存。如果使用虚拟地址索引 Cache,那么意味着 Cache 是和进程相关的(不同进程虚拟地址对应的内容不一样),所以每次 context switch 时,cache 都需要清空。
所以如果使用虚拟内存地址索引的 cache 的 context switch 代价很大。这也是为什么现在的机器大多是物理地址索引 cache。
但是用物理地址索引的 cache 也有问题。就像上面的步骤。
如果采用物理地址索引,则相对于使用虚拟地址索引的 cache,后者在 cache hit 的情况下甚至不需要进行地址翻译,降低了操作的 latency。
在看上面的步骤,我们发现页表和普通内存数据的 cache 都共用一个 cache。而地址翻译作为一个很基本的步骤,能不能像 “指令和数据区分 cache(L1 中有 data cache 和 instruction cache,见缓存一章)” 一样,我们为页表单独设计一个 cache?
实际上,主流的机器是会做这个事情的!因为研究表明单独为 page table 设置 cache,其 cache miss 的概率几乎没有!于是人们在 MMU 内部设置了一个专门用于缓存 Page Table Entry 的硬件 TLB(Translation Lookaside Buffer)。
切记:TLB 存放的是从 VPN 到 PPN 的翻译结果(VPN 对应的 PTE)!
缓存到 TLB 的实际上是整个 PTE,包括了权限位信息。
我们知道,请求 cache 的时候,是使用请求的地址来解析缓存内容的位置的。根据缓存设计的规格参数,把请求的地址切成几段再对缓存查找。这个方法无论是对 TLB 还是普通的 Cache 都是一样的。
这样的话,翻译的总体步骤就又改变了:
当 CPU 根据指令请求一个虚拟地址,会被先传到 MMU 中,MMU 找到其中的 Virtual Page Number,直接分成 TLB 的 set index、tag(注意设计 block 正好一块
PTE因此不存在 block offset)请求 TLB;如果 TLB hit,则直接得到
PTE;如果 TLB miss,则还要将 VPN 借助 page table base register 计算得到
PTEA物理地址,向 Cache 请求PTE;找到后直接放入 TLB;PTEA的计算很简单,只需要取得PTBR中的 Page Table 起始地址(肯定是物理地址),加上VPN x Page Table Entry Size (64 位下 8 bytes)就能得到PTEA物理地址。
然后无论是 TLB hit 还是 TLB miss,MMU 都会将得到的
PTE检查valid和 permission bits,得到 Physical Page Number;如果也没找到,说明 Page Fault,MMU 抛出 Page Fault 并且进入 OS Handler 进行相关处理。否则继续下一步;MMU 将 PPN 与 Page Offset 拼接得到物理地址,通知 cache memory 传给 CPU;
![]()
现在同样以一个小地址的机器为例:
14 位长度的虚拟地址、12 位长度的物理地址;
页大小 64 bytes(6-bit Page Offset);
TLB 采用 4-way associative(2-bit 行索引
L1 Cache 采用 Direct Mapping(一组一个行),块大小
当前的 TLB 状态如下:
![]()
当前 L1 Cache 状态如下:
![]()
那么可以推得:
PO长度 6-bit,VPN长度 8-bit,PPN长度 6-bit(做这类题前一定要记住先去除 page offset!);TLB set 2-bit、offset 0-bit、tag 6-bit;
Cache set 4-bit、offset 2-bit、tag 6-bit;
虚拟地址 0x3D4(0011 1101 0100):TLB set index = 11 = 0x3,TLB tag = 0011 = 0x03;
于是 TLB hit:PPN = 0x0D = 1101,PA = 1101010100 = 0x354;
Cache set index = 0101 = 0x5,Cache block offset = 00 = 0x0,Cache tag = 001101 = 0x0D;
因此 cache hit,取出的 1 byte data 是 0x36;
16.4.4 Multi-level Page Table
现在考虑另一个问题。我们知道页表放在内存中,那按照上面的设计,一个页表的大小是多少?
以 x86-64 机器为例,一个页表要对应 48-byte 的地址空间,由于一个页表 4K(4096 bytes),每个 entry 8 bytes,那么我们需要:
如果我只要用几个 KB 的内存,还要花 512 GB 建立页表?
所以真实的页表肯定不能像前面几节一样建立。
但在一个页表中,我们又不能用多少开多少页表项,因为 MMU 对页表的索引是数组索引式的。
这时候,人们就引入了多级页表的设计(硬件规定),有效降低了页表的内存占用:
将页表分级,没分配的虚拟页可以不存在;每个页表仍然是 4K 大小,64 位下每个页表项仍然为 8 bytes;
第一级页表必须存在,以供 MMU 开始索引(翻译);
前一级页表 entry 的内容不是
PPN,而指向下一级页表的起始地址;只有最后一级页表的 entry 存放PPN;注意,每一级中可能有很多页表!
MMU 翻译(索引)方法变成下图所示:
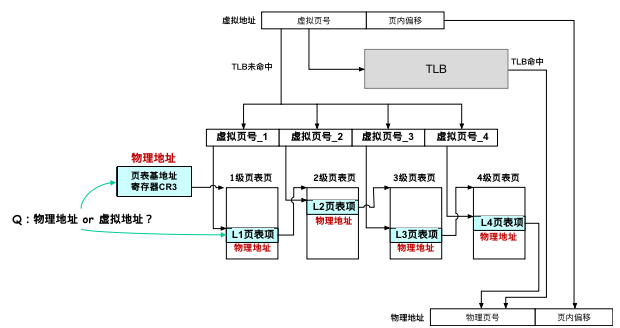
根据地址大小,一般情况使用 4 级页表。
因为 64 位机器地址总长度 64-bit,4K 页大小决定了 Page Offset 12-bit 长度,再去掉硬件决定高 16-bit 是无效的(如前面提到的,区分内核态和用户态),只剩下 36-bit 存放
PPN;而一个页表的 entry 数目是 4K/8 = 512 个,至少需要 9-bit 长度索引,恰好 36-bit 可以被 9 整除为 4,因此采用 4 级页表。
其中,第一级页表被称为 Page Global Directory(
pgd),第二级页表被称为 Page Upper Directory(pud),第三级页表被称为 Page Middle Directory(pmd),第四级页表被称为 Page Directory(pd);在未命中 TLB 时,MMU 使用
VPN对页表的查询方法变成了分段查询,前一段虚拟页号指向的 entry 决定了下一级虚拟页表究竟是该级中的哪一个(每一级可能不止一个页表,上图各级只画了一个);而最后的一级页表才存放的是最终的
PTE。这样做的好处是,能够在保证 MMU 数组式索引的同时,不需要为所有空间开辟页表 entry。举个例子:
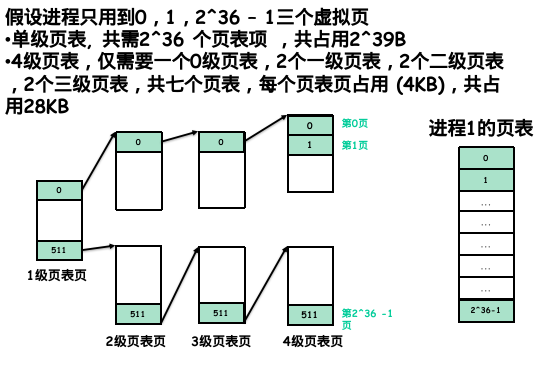
现在有一个问题能够帮助更好地理解多级页表:如果页表总共占 16 K 大小,请问页表所能翻译的最大地址空间是多大?
因为对 4 级页表而言,注意一个页表大小 4K,想要正常翻译地址,因此 4 级页表每级 1 个,并且要依次相连。于是,最大的范围取决于最后一组页表的范围。因为一个页表的 entry 有 4K/8 = 512 个,每个 entry 映射一个虚拟页到一个物理页,所以能够映射的大小范围是 512 * 4K = 2 MB;
举个例子,对于一个 64 位的虚拟地址 0xFFFF FF80 8060 4FFF,它的四层页表索引分别是什么?
xxxxxxxxxx1111 1111 1 | 000 0000 10 | 00 0000 011 | 0 0000 01000x???? / FF8080604 / FFF
按照上面的拆分方法,各级页表索引是:
L1 0x1FF,L2 0x2,L3 0x3,L4 0x4;
另外一个值得讨论的问题是,四级页表的 entry 究竟存放什么数据?
我们讨论单级页表时,说过一个 PTE 大小 8 bytes,不仅用于存放 Page Offset(4K -> 12 bits),再除去开头的硬件规定区域限制的 16 bits 信息,剩下的 52 - 16 = 36 bits 的数据可以用来可以用来存放足够多的数据。
对于第 1~3 级页表而言,它们的结果稍稍有些不同。我们就介绍常用的一些 bit:

XD(execution disable)放在每个 entry 的第一个 bit,标注这部分是否允许执行,判断当前内存页的执行权限;中间一个相当大的区域和单级页表的思路类似,但是是用来存放下一级页表起始物理地址;
P位在地址的最后一个 bit,就是我们之前常说的valid位,留给 MMU 判断是否有效;R/W位在地址的倒数第二个 bit,标记这部分的读/写权限,0代表只读,1代表可读可写;U/S位在地址的倒数第三个 bit,标记这部分的访问权限,0代表用户态 ring 3,1代表特权态 ring 0;G位在 payload 后的第一个 bit,标记这部分是 global page(在一般的 TLB flush 时,不会被 evict);为什么有 TLB Flush?
考虑一下 TLB 中存放的数据内容。TLB 是页表的 cache,也就是一个进程使用的虚拟内存和物理内存的映射关系。这个关系应该和页表一样,会在 context switch 时发生切换。我们知道页表在 PCB 中,切换不同进程可以有不同的页表。但是 TLB 作为一个缓存就需要在 context switch 时清空(事实上所有需要更改页表映射关系的场景下都要进行 flush),防止两个进程读到同一份映射关系;
什么时候会用到 global page(即 context switch 时不需要改变的翻译关系)?答案是 OS Kernel 的内存空间。在多个进程中可以保持内核的内存空间不需要改变,实现了多进程共享的内核。
注意,和之前说的一样,
*.so动态链接库等共享库在有些情况下可能会共享物理页,但是不能用 global page,因为 ASLR(地址空间随机化)的机制,每个进程的 shared libraries 的位置不尽相同,所以即便使用同一个物理页,其翻译规则也不相同。那为什么 OS Kernel 不会受到 ASLR 的影响,可以直接共享物理页以及翻译方式呢?这和 OS Kernel 在页表中的映射方式有关,我们将在 16.5 中介绍。
注意,对于 cache 而言,由于 cache 是使用物理地址索引的,所以在 context switch 时不需要进行 flush。只有一些特殊情况(例如软件主动指定)才会用到。
PS(page size)位在 payload 后的第 2 bit,顾名思义就是表示一个 page 的大小;现在回想,第一级页表有几个?答案是只有一个,因为
CR3页表基地址寄存器只有一个!不过第一级页表只有一个的话能表示的地址空间有 512 x 512 GB,也足够 x86-64 架构使用了。
那么 2、3、4 级页表最多都只有 512 个(因为一个页表的 entry 数目最多 512)。
那么既然翻译要走 4 级页表,假设读一个页表 entry 的时间开销比较大,人们会考虑尽量让翻译过程 “走捷径”。例如如果当前进程分配的页表 1、2、3 级都只有一个页表,那么我们是不是能在第 3 级页表就结束翻译呢?
比如,我们将第 3 级页表每个 entry 不再表示下一级页表地址,而是表示一个 2 M 的连续物理地址,这样就可以在第三次页表访问的时候就获得物理地址(相当于直接将 2 M 虚拟地址翻译为 2 M 物理地址)。
MMU 在读取时,如果读到一级页表中的
PS被置为 1,则说明翻译过程到此为止,将当前级页表的 entry 存放的地址不再看作下一级页表基地址,而是直接看作一个物理大页的起始地址,将还剩下来的、没有翻译的 9/18/27 bits 并入 page offset 进行整体索引。这样实现了物理大页的快速翻译。
我们分配大页有什么好处?
节省 TLB 缓存、降低 TLB miss 概率。假设一个程序的内存 working set(频繁使用的部分)有 2 M 这么大,那么它就会占用 512 个 TLB 单位,这对于一个只有几 K 的 TLB 来说是不能接受的,会频繁发生 eviction。如果我们为这个程序分配了 2 M 物理大页,那么虽然有可能降低了物理内存的利用率(utilization,或者相反,内部碎片出现的情况),但是客观上降低了 TLB miss 的可能性,减小 thrashing(性能抖动)出现的可能性;
减少四级页表索引开销,降低 TLB miss 的 penalty。理由如上面的举例。
什么时候使用大页更好?
我们知道过大的页可能降低内存利用率,但是实际上有一类情况使用 1 G 大页可能更好 —— 还是 OS Kernel。因为它的地址不经常变动,使用的是 global page,而且内存占用较大。所以使用大页可以极大节省 TLB 的缓存单元,并且不会太影响内存利用率。
A(Access bit)位在 payload 后的第 4 bit,硬件标识给软件使用。如果 MMU 在使用到这个 entry 后,会将这个 bit 置为 1,告诉软件这个页表项对应的区域已经被访问过了。我们可以通过设置 time window 的方式(定期扫描、清空这个 bit),来探测一个进程的 working set(或者 hot page);
CD(Cache Disable bit)/WT(Write Through bit)位在A位之后,指示这块空间使用的缓存策略(是否经过缓存)。有些 memory 例如 device memory 是实时的,使用缓存会出现问题。
对于第 4 级页表而言,它和 1~3 级页表很类似。

D(dirty bit)位在 payload 后的第 3 bit,用来指示这个 page entry 是否有访问(特别地,写入)的情况,是硬件向软件暴露更多的信息。
16.4.5 Cute Trick for Speeding Up L1 Access
VIPT(Virtual Address Index - Physical Address Tag)和 PIPT(Physical Address Index - Physical Address Tag);
16.4.5 General View of Page Table & TLB
实际的一个处理器中 TLB 在哪里、究竟有哪些类型,我们可以从下图看到:
而虚拟地址翻译的总体流程如下图所示(注意,TLB miss 后取页表的过程也是向 cache 申请的):
![]()
16.5 Virtual Memory: From OS's perspective (Linux)
16.5.1 How to manage OS Kernel ?
再次强调一下,CSAPP 3e 有一点是错误的。
实际上,一个操作系统上的虚拟内存中的 OS Kernel 使用 Global Page,并且地址映射是完全相同的(这是少有的各个进程共享一些物理页的情况)!
你可能会好奇,为什么即便有 ASLR,OS Kernel 的空间也能共享物理页呢?
首先,每个进程有一个独立的页表,也就是说有独立的第一级页表(CR3 寄存器值不同)。其实在不同的进程中,由于 OS Kernel 占用的是高地址的部分,因此它通常从第一级页表的最后一项开始映射。
于是有一个很好的映射 OS Kernel 的方式:将每个进程的第一级页表的后面部分的 entry 写入相同的地址,这样所有进程的 page table 的高地址翻译到的物理内存是共享的 kernel 内存。
所以,这样设计可以在 context switch 时翻译规则不改变,这样也就无需进行 TLB 的刷新,解释了前面章节为什么 OS Kernel 可以使用 Global Page,进行多进程共享物理页的问题。
16.5.2 How to Organize Virtual Memory in OS's View?
我们知道,虚拟内存和物理内存映射的机制是 OS 和硬件共同完成的。
但是我们到目前为止,了解的都是硬件层面对于 Virtual Memory 和 Physical Memory 关联的抽象,解释了比 OS 更底层的处理虚拟内存和物理内存映射的机制。
现在,以 Linux OS 为例。我们想从 OS 的角度(更高级的层级)看一看这个地址映射的过程是如何进行的。
还记得很早之前对 虚拟内存和物理内存映射机制的 Overview 一节,我们说:
…… 那么 OS 不会立即将这段虚拟页映射到物理页,而是几乎不作任何操作。只是在内核中标记这段内存是应用程序申请的;等应用程序真正访问的时候,再触发 page fault,OS 再动态地为一个虚拟页分配一个物理页。
你知道这里 “在内核中标记这段内存是应用程序申请的”,这个标记的机制是什么吗?
或者说,操作系统怎么记住哪些是一个进程的 uncached area(应用程序自己要求分配,但是还没有真正在物理页上挂载),哪些是 unallocated area?
这就是内核中的 VMA Struct(Virtual Memory Area 结构体) 的作用了。
我们知道,目前几乎所有主流的 OS,它在管理各个进程的时候,使用的几乎都是 PCB(进程控制块)数据结构。其中包括了超级多的关于这个进程的信息,想要进一步了解的可以跳到 18.2.2 节 一探究竟。
在 Linux 中,PCB 这个数据结构是由一个 C 结构体实现的,它的名字叫
task_struct。它的字段很多,不过我们这里只需要关注mm成员字段。
task_struct::mm是一个指向另一个结构体mm_struct的指针,用来管理进程的内存分配的相关信息。而
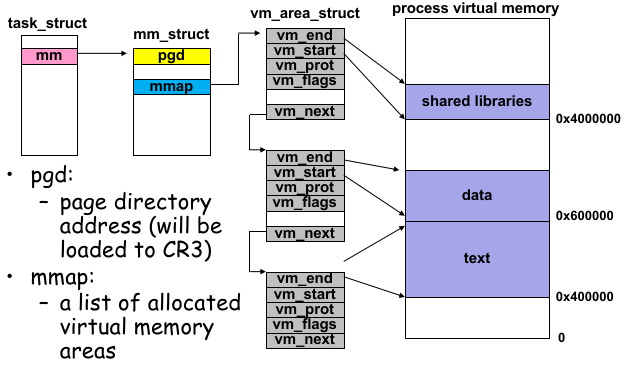
mm_struct中有两个重要的字段,能够解释、呈现我们目前学到现在虚拟内存和物理内存映射关系在 OS 视角下的样貌。结构体的第一个字段是
pgd,大家回忆一下四级页表的名称 —— 没错,是 Page Global Directory(一级页表),也就是说这里存放的是这个进程的第一级页表的基地址,在 Context Switch 时会被 Kernel 填入CR3(Page Table Base Register)中。中间还有一个字段,是
mmap指针,它指向了本节的主角:vm_area_struct(VMA Struct)。
这个 VMA Struct 在 Linux 中的组织形式是红黑树,在某些 case 下有良好性能。但是这里为了解释方便,我们以链表为例说明。
它是怎么表示 OS 为一个进程究竟分配了哪些空间的呢(同时包括 uncached area 和 allocated area)?
其中有一些字段 vm_end、vm_start 标识了分配空间的起止地址,vm_prot 标识了这段空间的读写权限。
vm_flag 标识了这段空间是否是共享的内存空间(这个 “共享” 的含义和 global page 有些区别,之后详细讨论)。
如下图所示:
16.5.3 How to deal with Page Fault in OS's view?
接下来我们在来看看,OS 层面是如何处理硬件抛出的 Page Fault 的异常,并进行相应的识别和处理的。
首先,在 CPU 执行一段代码时,遇到读取/写入的地址就是虚拟地址,它会传给 MMU 解析出物理地址并进行请求。
MMU 如果在解析时发现 P bit 无效,或者 permission bit 不符合行为,或者其他的 attribute 冲突,都会抛出一个异常,按照 Exception Table Base Register 的地址索引找到 OS Kernel 中处理 Page Fault 的 Handler,然后传递 PC 就是传递了控制流。
此外,MMU 会将具体翻译出错的虚拟地址,传递到 CR2(Control Register 2)中,以供 OS 在错误处理时检查出错原因。
在 Page Fault Handler 中,OS 会首先检查虚拟地址是不是 unallocated area。它通过在 VMA Struct 中查找这个地址是否落在这些结构体指定分配的区域内。
如果没有落在这些区域中,说明程序访问的是 unallocated area,于是 OS 认为程序访问非法内存,向程序发送
SIGSEGV然后中断执行流;如果确实落在这些区域中,但是检查
vm_prot发现访问权限有问题,则 OS 认为程序也是访问了非法内存,可能向进程发送SIGSEGV,也有可能发送SIGILL,这取决于 OS 自己的实现;如果确实落在这些区域中,而且访问权限正确,则说明是 uncached area,OS 的 demand paging 的策略。这个时候 OS 会根据情况在页表中为这段区域挂载真正的物理页,并且让程序控制流回到
16.6 Miscellenous
16.6.1 Put it Togerther
现在把这个过程连起来想一想。假设 CPU 要执行一条汇编指令:
xxxxxxxxxxmovq (%rax), %rbx这条指令可能发生几次 Page Fault?
实际上可能发生 0 次、1 次、2 次都有可能。
0/1 次的情况比较好理解。因为 CPU 从
%rax寄存器中拿出虚拟地址,并且将要用这个地址到 cache 中取值。这个过程经过 MMU 翻译时,可能%rax存放的地址是 on-demanding page(uncached area),触发 page fault 后由操作系统进行修复;2 次的情况是,这条指令本身一开始就存放在某个文件中,不一定全部加载到内存中来。在 CPU 使用 PC 取这条指令的时候,也可能遇到一次 page fault;
那么如果指令是这样的呢:
xxxxxxxxxx0x40000: movq (%rax), %rbx jmp *%rbx这个时候 jmp 指令可能出现几次 Page Fault?
我们注意到这个时候 movq 指令位于页表对齐的地址,因此只要能执行到 jmp,那么 jmp 一定不会因为取指令而发送 page fault;
还要注意的一点是,即便 %rbx 存放的是无效地址,也不一定会导致 jmp 指令的错误。假设在执行 jmp 时,%rbx 中存放的是 0,那么访问非法地址也是在 jmp 结束后的下一条取指令的时候发生,不算 jmp 本身的 page fault;
所以这条指令一定不会 page fault 吗?并不是!
考虑一个问题,因为 CPU 会进行 context switch(分时复用),导致各个指令出现 interleaving。在 context switch 的时候,TLB 会被清空,而且同时可能会发生 page evict。所以在 jmp 指令发生 page fault 是有可能的事情。
16.6.2 Application: execve()
现在我们回忆下多进程一章节中介绍的系统调用 execve,它是用来在当前进程中执行指定的程序,通常和 fork 一起使用。
那么 execve 底层要做的事情,很大一部分就涉及到了本章讨论的 OS 对虚拟内存和物理内存的管理和映射。在一个程序进程中执行 execve,会做以下的事情:
释放掉当前进程的所有
VMA结构体(相当于将之前应用程序申请的空间全部回收);程序之前的页表关系、内存数据就没有意义了;
OS 重新为新程序的
.text/.data/.bss(file-backed),以及栈区域(anonymous)等区域分配VMA,并且适当地创建一部分页表、挂载一部分物理页;
16.6.3 Sharing & Private Virtual Memory
你还记得在 vm_area_struct 中有个字段叫 vm_flags 吗?我们说这个字段用来标识这块内存区域是共享的(shared)还是私有的(private);
注意,这个 “共享” 不是我们说过的 global page。
我们考虑一个情况假设一个 Linux 可执行文件在两个 shell 中执行了 2 次,现在 OS 的 shell 会为这个可执行文件开辟两个进程。
这个时候,我们发现 OS 要映射诸如 .text/.data 之类的 file-backed 的虚拟页的时候,可能会遵循 demanding page 的策略,不立即分配一个物理页并写在页表里;而是在内核中向这个进程的 VMA 结构体集合中加入几段标识分配的新结构体,然后什么都不做。
这个结构体比较复杂,除了之前提到的几个字段,它可能还会记录它对应的
fd,如果fd == -1就代表了 anonymous page;
这个时候,我们想,它们既然对应同一段磁盘上的文件,那么假设其中一个进程对 .data 段更新了数据,为什么另一个进程不会受到影响?或者说,为什么磁盘上的可执行文件没有被更新?
这就归功于分配的这页是 private(私有属性)的,这个信息是在 OS 分配这段虚拟内存时就决定,并且记录在 VMA 结构体的 vm_flags 中。
页的私有属性决定了,这个页即便是 file-backed 并且有可写的属性,一个进程书写的信息也不会真正地更新到文件中。
再考虑一个比较迷惑的点:程序的 shared libraries 段对应的页的属性其实是 private 的。因为 shared libraries 中可能存在 .data 等可写的部分(由一些全局变量产生,例如 libc 中的 errno)。我们在运行不同程序的时候,显然不希望其他进程能更改自己的 shared libraries 中的一些值。
所以 “共享库” 实际上说的是共享的磁盘上同一个 file-backed 的位置,和不同进程运行同一个可执行文件是一个道理。
另一种相反的情况是,程序使用 mmap 主动读入、更改磁盘上的文件,这个时候 OS 分配的空间就可能不是私有的了,因为数据会更新到磁盘中,详细内容我们在 16.6.5 中讨论。
16.6.4 User-Level Memory Mapping: mmap()
其实,除去 OS 自动会进行的分配工作、除了 malloc 扩展堆的大小时,间接让 OS 为程序在 VMA 上分配一段虚拟内存以外,还有一种方法是程序可以主动让 OS 为自己分配一片虚拟内存。这就是系统调用 mmap():
xxxxxxxxxxvoid *mmap(void *start, int len, int prot, int flags, int fd, int offset);start参数是建议参数,建议操作系统以start为地址起点,分配一段虚拟内存。填入NULL代表并不关心 OS 分配在哪里;len表示要分配的虚拟内存的大小(bytes);prot有几种取值,用于设定VMA的vm_prot字段,规定这段分配的虚拟内存所在的页的读写权限PROT_READ/PROT_WRITE/PROT_EXEC;
flags就是用于设定VMA的vm_flags字段,标识这段虚拟内存所在的页是共享的还是私有的;MAP_PRIVATE/MAP_SHARED&MAP_ANONYMOUS/MAP_FILE;
fd就是设定了这个页对应的文件背景。如果是
-1,说明这个新的虚拟内存所在的页是匿名页,不对应磁盘上的任何文件;此时必须设置flags存在MAP_ANONYMOUS,否则mmap认为读到无效的文件描述符;而如果是有效的
fd,则这块虚拟内存就是文件背景页,对应了磁盘上的文件,当访问这块区域时,OS 会将磁盘上的文件内容加载进来,相当于快速的读文件。
offset仅在文件背景页中有意义,表明将文件映射到这个文件背景页时,从头开始的偏移量究竟是多少。
所以说,mmap 的实质就是在 VMA 结构体中加入了一项分配记录,允许应用程序之后访问这段虚拟内存,这和 malloc 很像,或者不如这么说:
malloc 在分配小空间时底层调用 brk 增长堆,分配大空间时底层调用 mmap 来直接向 OS 的 VMA 添加记录,避免直接写页表,实现了 demand paging,提升了程序性能。
这就解释了早在 Chapter 7 中,我们发现 Linux memory layout 在
malloc分配小空间时,从堆的地方增长,而分配大数据时,是从 shared libraries 的下方开始反向增长。因为底层使用的系统调用不一样!
你看,mmap 有这么多好处,它具体被用在哪些地方呢?
快速读写文件:就如上面提到的,如果
fd是有效的文件描述符,那么新分配的虚拟内存在VMA中会被标记成这个文件对应的一个文件背景页。这也意味着,我们访问这段空间时,OS 会将文件中的内容直接呈递到这段虚拟内存中。这不就相当于间接完成了一次读文件的操作吗!这里有个很有意思的点,你能区分
mmap映射文件,和普通read方法读文件,这两者的区别吗?我们之前提到多次,当我们使用
mmap映射文件到虚拟内存中时,OS 采用的是 demand paging 的策略,只是在VMA中插入了一条记录,描述这个映射关系,然后什么都不做(性能好);如果我们要访问这块虚拟内存时,肯定会触发一次 Page Fault,然后 OS 会将对应磁盘文件上的一个页大小的数据利用
DMA(Direct Memory Access)先搬到物理内存上。这个物理内存,在 OS Kernel 看来,就是一个 Page Cache。Page Cache 是 OS 自己管理的 cache,会记录一段预加载到物理内存中的文件数据与它磁盘上的文件的对应关系。
然后 OS 再将这个物理内存的这个区域与指定的虚拟内存地址在页表中建立关联,完成了 on-demand page 的页表补充的工作。
这样的好处显而易见:我们可以像操作普通虚拟内存一样操控文件!只要有 page cache,那么
mmap时就不需要进行任何复制操作!只需要将 page cache 所在的物理内存在页表中挂载到指定的虚拟内存上就行。而普通的
read方法在做什么呢?实际上,如果之前没有 page cache,那么 OS 会先将文件读到物理内存(page cache 中),然后将这段内容复制到用户
read指定的、已经分配的虚拟内存对应的另一个物理内存(可能是匿名页)中。所以多了一步复制的冗余操作。
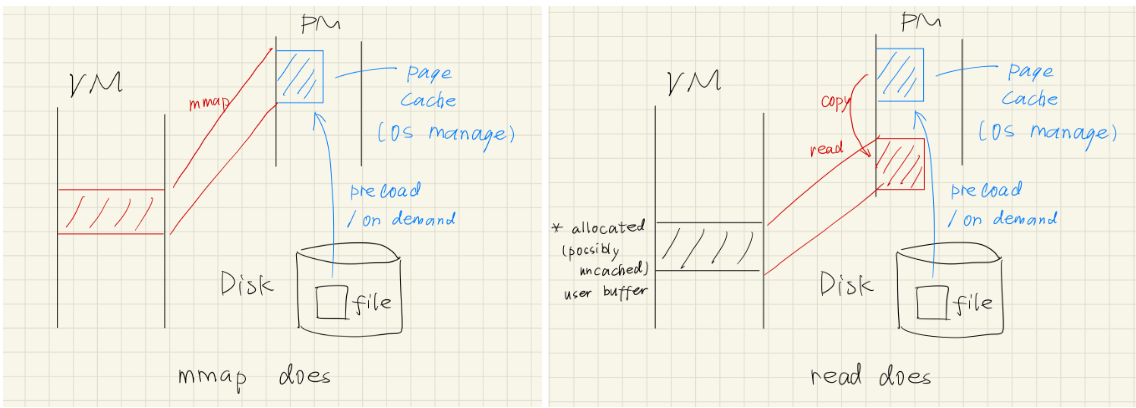
16.6.5 Application II: fork()
现在我们有了基本的虚拟内存的知识,再回来看一下 fork() 的具体行为。
fork 的作用是 clone 一个新的进程,那么它会 clone 原来进程的哪些内容?回忆一下我们已经知道的:
父子进程的 file descriptor 表整体复制,但不共享,每个 entry 指向同一 file structure;
父子进程的 CPU 寄存器状态、PC 值整体复制,但不共享;
那么父子进程的虚拟内存的情况,fork 是如何处理的?
fork 会直接将父进程的 VMA Struct(回忆一下,虚拟内存分配信息)、mm_struct(页表信息)、page tables(所有页表)全部完整复制给子进程。
这里的 “完整复制” 是 deep copy 的意思。父子进程的
mm_struct和 page tables 本质上已经位于不同的物理内存空间了!
你可能会好奇,这样不会导致父子进程完全共享虚拟内存空间吗?怎么保证隔离性?
为了理解这个问题,我们需要更详细地理解内存区域 private / shared 的深层含义和行为;
如果一块虚拟内存区域是 shared,那么一般来说,它是一个文件背景页。这也意味着,对这块虚拟内存的修改会持久化到磁盘中去,并且还被其他进程共享(如果另一个进程也使用
MAP_SHARED映射了同一个文件,那么它们映射同一个 page cache,并且能在之后的某个时刻被 OS 持久化到磁盘中);什么是 “不一般” 的情况?(什么时候匿名页是 shared object?)
匿名页的
MAP_SHARED体现在fork之后的共享方面。当且仅当mmap分配了MAP_SHARED | MAP_ANONYMOUS的虚拟内存空间,并且使用fork后,父子进程才会共享这块匿名页。如果一块虚拟内存区域是 private 的,那么它可能是匿名页,也可能是文件背景页。进程对这块虚拟内存的修改不会持久化到磁盘中,也不会被其他进程所看见(因为修改只存在进程自己的虚拟内存对应的物理页中)。
大多数情况下,不同进程间不会共享内存,因此大部分内存都是 private 的;
所以 fork 采用了一种技术:Copy-On-Write(COW);
刚执行 fork 时,父子进程的虚拟内存的映射情况确实完全一样,但是 fork 会做一些额外的工作:
对子进程的
VMA Struct中所有标记MAP_PRIVATE(private object)并且可写的分配块 的页表项权限改为 Read-Only(OS 故意为止,让 MMU 翻译写时出错),并且在VMA中加上标记CopyOnWrite(OS 提醒这里权限位是故意更改的);注意:
父子进程的
VMA中都要标记CopyOnWrite!因为如果只有子进程标记,那么假设父进程先写,那么子进程就会看到父进程的修改;再次强调!OS 只会在:原本就存在可写权限、且标记了
MAP_PRIVATE的分配块中标记上CopyOnWrite标记。
对子进程的
VMA Struct中所有标记MAP_SHARED(shared object)的分配块(或者是标记MAP_PRIVATE的不可写块)就不需要改变(现在已经 shared 同一块物理页了);
父子进程对自己虚拟地址进行读操作时,什么事都不会发生,因为尽管这个时候它们共享了虚拟内存的映射,但是因为没有修改,所有也不需要变化。
只有当子进程对虚拟地址进行写操作时,MMU 发现读写权限错误,通过 CR2 和 ECF 通知 OS,OS 在 Page Fault handler 中检查到读写权限问题,但是!它又看到了 COW 被标记,因此它知道现在的虚拟块可能是可写的,只不过因为 COW 的机制延迟分配物理页,暂时借用了父进程的物理页。
于是 OS 现在找一块空闲的物理页,并且重新给这块虚拟内存挂载,修改 VMA Struct 和页表记录,还原这块虚拟内存在页表中的读写权限。
再考虑一些具体的问题:
如果是本来就是只读的页,但是
fork之后向里面写入,会有几次 page fault?
fork之后,pgd怎么办?
带着问题,我们来看一个例子:
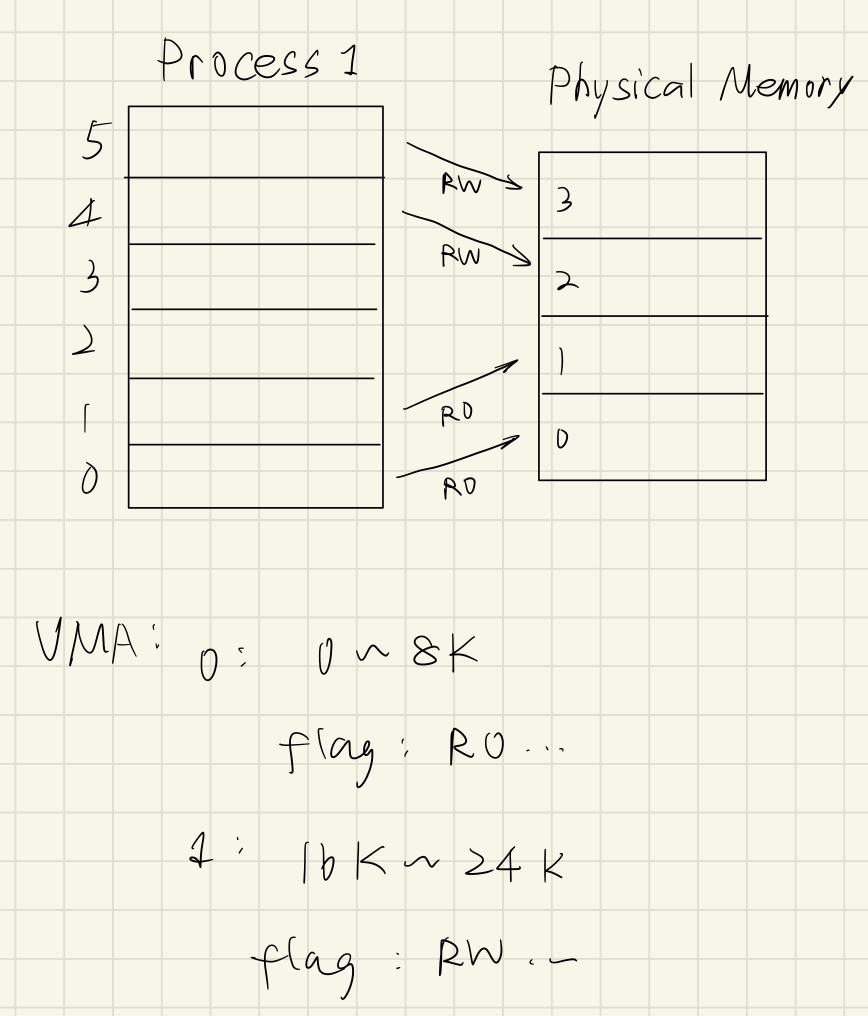
假设有个进程的虚拟内存到物理内存的映射如上所示。映射关系,也就是 虚拟页号-物理页号联系的箭头 存在页表中,缓存在 TLB 中。因此 VMA 结构体如图所示。
注意到
VMA结构体保存的是连续的虚拟内存映射(OS 会做合并操作),所以VMA是 2 个。
考虑一个问题,当 process 1 调用 fork() 时,发生的变化:
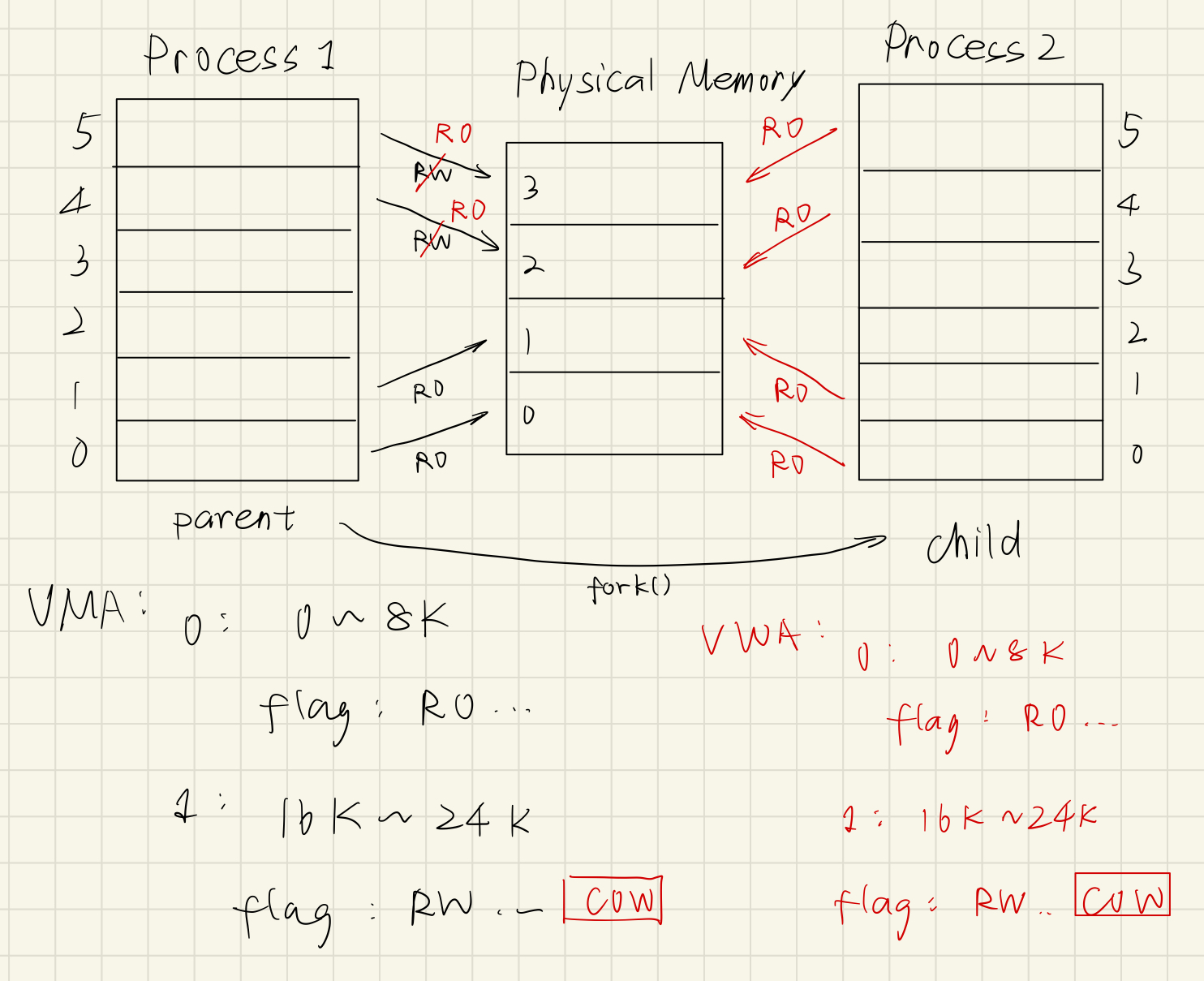
父进程中的 可写的、
MAP_PRIVATE的页会在对应的VMA中打上CopyOnWrite标记,并且在页表中修改可写权限为只读。必须改页表、flush TLB,不然 MMU 还是看不到更改。
子进程完全 deep copy 父进程的
mm_struct、VMA结构体、页表,所以映射关系完全一样。再次注意,是 deep copy,虽然内容一致,但是已经位于不同的物理地址了。
还有一个重点图上没标注体现:在子进程 deep copy 时,还是会更改一些数据,例如
mm_struct的pgd项(毕竟页表的地址已经换了嘛!),这就解决了我们之前 “fork()后的pgd如何处理” 的问题。现在假设物理内存有足够的空闲物理页。假设进程(父子进程都可以)要对上面的一个曾经可写的页进行写操作,这个时候 MMU 看到了 OS 故意设置的只读权限会抛出 Page Fault。OS 的 handler 会根据
CR2确定到出错位置、发现COW标记,于是进行 Copy On Write 操作:将要进行 Copy On Write 的页复制到新的空闲的物理页上;
更改原来的虚拟页挂载关系,挂载到复制出来的新的物理页上,恢复读写权限,并且进行 TLB Flush;
注意!!!一切需要更改页表映射的操作,OS 都需要对 TLB 进行 flush。因为 TLB 是缓存,如果更改后不及时 flush 则会导致 MMU 读到旧的映射关系(脏读)。
将
VMA进行 split,为已经完成 Copy On Write 的页的部分清除COW标记。这里的情况是恰好两个相同权限的虚拟页连在一起,所以 Copy On Write 其中一个的时候会出现
VMA的分裂。
如下图所示:
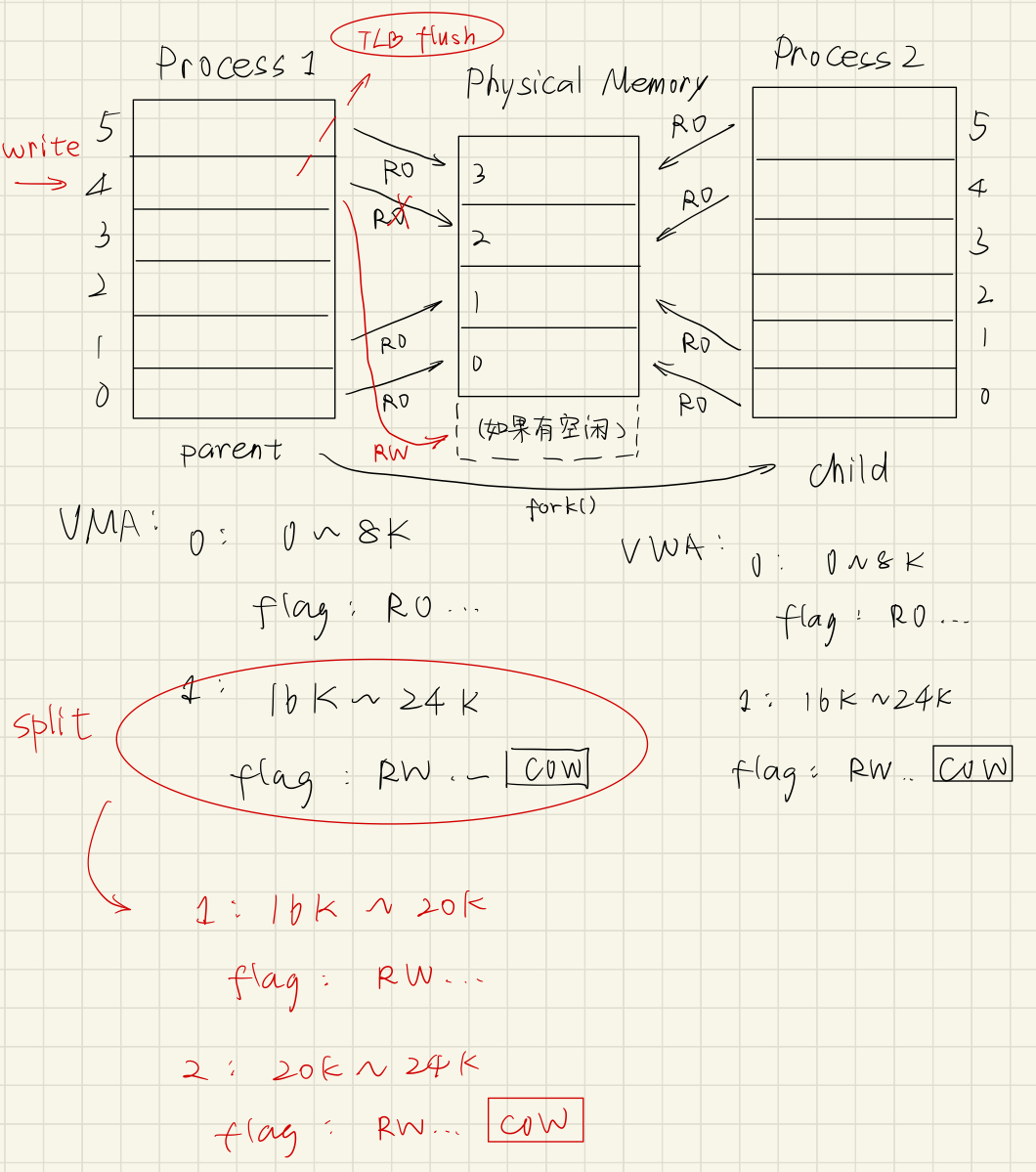
如果上一步写操作触发 Page Fault 时,OS 要进行 Copy On Write,如果没有空闲的物理页(比如只有上面的 4 个物理页),会发生什么?很显然,由前面的知识我们可以知道,会有 swap out / page out 的情况。
那么 OS 会选择要 evict 的页,把它的内容写回磁盘(swap 分区 / 文件背景),把 evict 的进程、evict 的页对应的页表项 valid 设置为无效,page table entry 中填磁盘地址。
然后就会空出一块物理页,可以让新 Copy On Write 的页落脚。如下图:
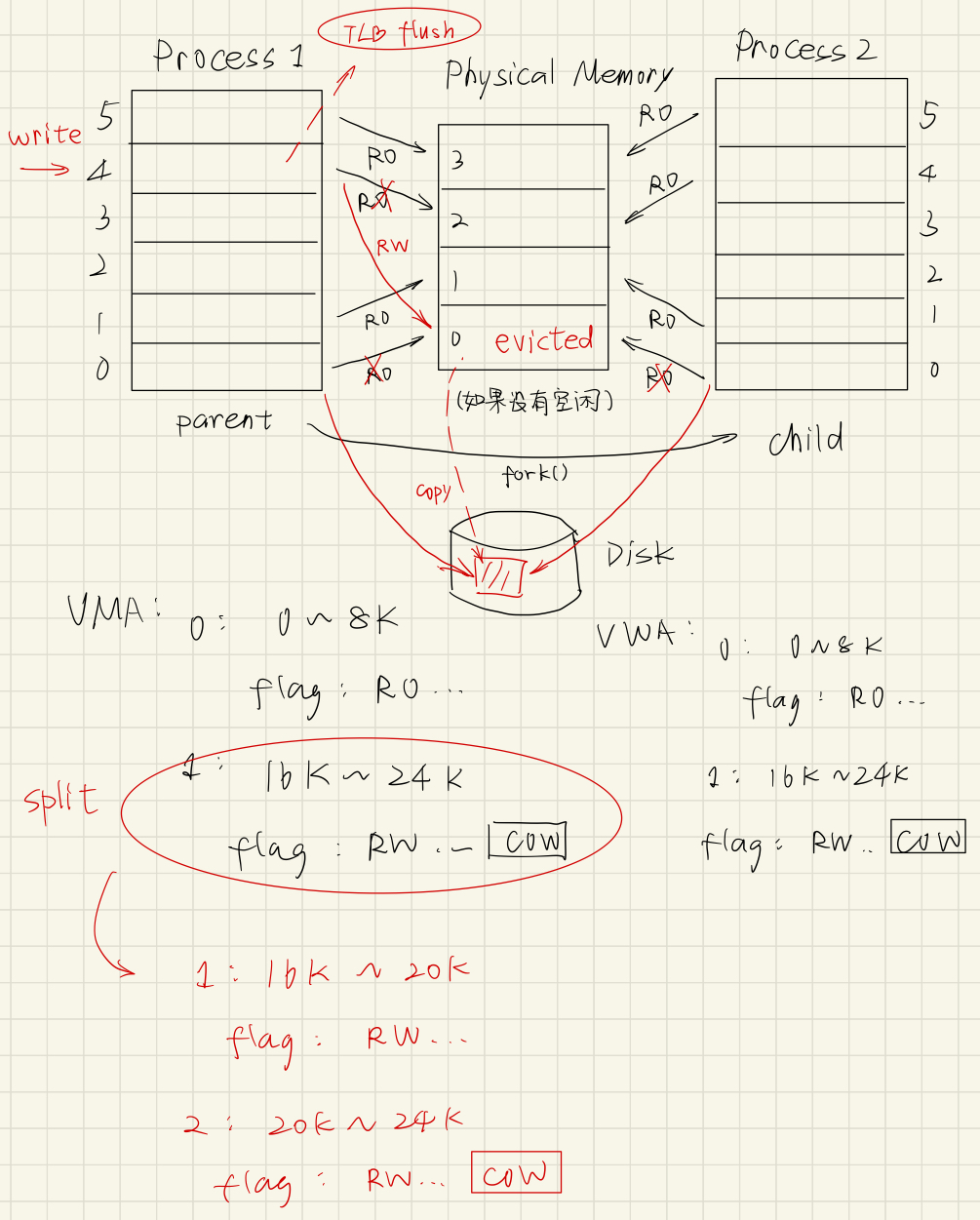
下一节,我们就详细讨论,OS 是如何选择这个 evict 页的。
16.7 Replacement Policy
再考虑更详细的场景。我们知道当空闲的物理页数量不足时,OS 会选择一个物理页 evict 到磁盘中,并且给申请方分配物理页。这个过程就是 swap out / page out;
这节我们就来详细讨论缓存 page 的 evict 策略。
这部分在 CSAPP 中没有,是 OSTEP 的补充内容。
16.7.1 Metrics
首先引入一些 metrics:
AMAT:Average Memory Access Time(平均内存访问时间);
可以知道
可以由数量级发现,
( )对 AMAT影响很大(主要因为磁盘访问时间很长)。
16.7.2 Policies
首先我们知道 page evict 策略有一个理论上的最优上界,我们称为 Best Possible Replacement Policy。它的思路如下:
每次 evict 选择在未来的请求序列中,离当前最远会访问的物理页。
在实际情况中,这几乎不可能实现,因为没有 OS 能够预测所有程序未来要申请的页的情况。但在性能研究中,可以作为一个模拟上界,与其他设计出的策略形成对照。
首先我们考虑第一种替换策略:FIFO(先进先出)。这种策略的实现非常简单,就是为页表维护一个普通队列,即可完成既定任务。
但是这种策略的效果并不好,主要是因为:没有考虑到经常使用的页的信息,可能导致频繁替换的现象。不仅如此,FIFO 还会发生 Belady's Anomaly,也就是说,这种缓存策略甚至会出现随着缓存大小的增大,发生 evict 次数增大的反常、反直觉的现象。
其次我们考虑第二种缓存策略:Random Replacement(随机替换)。这种策略实现也非常简单,而且它还有一个优点,就是不会受到某些 corner case 的业务情况影响,总不至于一直出现极低的性能。
实践证明,在某些 benchmark 下 Random Replacement 有近 40% 的概率可以达到 Best Possible Replacement Policy(理论上界);
还有两种常见的策略:LFU(Least Frequently Used)& LRU(Least Recently Used)。
LRU 和 LFU 的实现方式有些差别:对于 LRU 而言,直接维护一个可变队列,最近访问的元素(无论是否 hit)都会被直接放到队尾;对于 LFU 而言,更加严格,需要维护一个访问次数数据,以及一个关于访问次数的优先级队列。
LFU 和 LRU 策略都满足一个重要的特性:Stack Property(栈特性);大小为
数学上可以证明,满足栈特性的策略一定不会发生 Belady's Anomaly;显然 Random Replacement Policy 和 FIFO 都不满足栈特性,目前只有 LFU/LRU 满足。
现在,我们从不同的使用场景(负载业务场景)来评估上面的策略的优劣。考虑下面 3 中不同类型的负载:
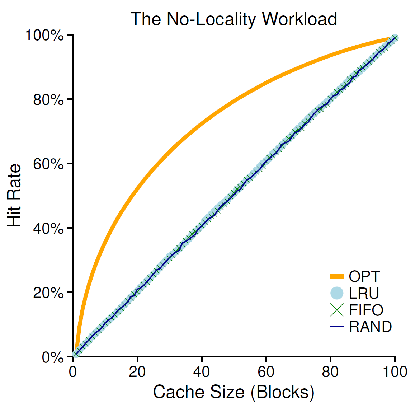
Random Access Workload:对页的访问是完全随机的。这种负载模拟的是程序局部性较小的业务场景,这个时候,无论是 LRU、FIFO、Random 的方式都无法显著有效地提升 hit rate,因为这种 workload 不依赖于任何历史信息,因此在数据量较大的情况三者表现相近,都劣于 Best Possible Replacement Policy。直至缓存足够大,能放下所有页的内容:
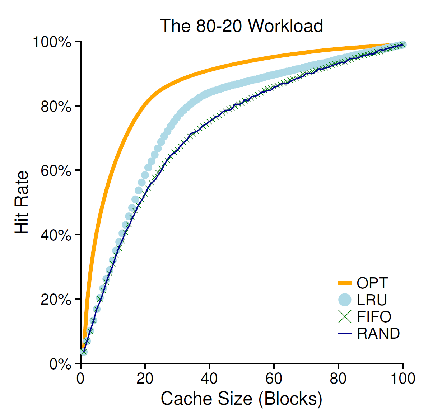
“80-20” Workload:现实情况中,我们可以借助实际的负载来总结可能出现的情况。例如 “二八定律”,我们可以认为,某些情况下,有 80% 的页的访问都只指向所有页的 20% 的部分。
也就是说,在一般情况下,只有 20% 的页是活跃的,其余 80% 的页并不活跃。
这个时候,一个策略的历史经验有能起到一定的预测作用,所有 LRU 的表现会优于 FIFO 和 Random 的实现方法。
“Loop Sequential” Workload,其实还有一种情况,是我们在编码时可能遇到的一种业务情况:
for/while循环构成的顺序 workload。我们会发现由于这种顺序访问,恰好让 LRU 和 FIFO 总是踢出下一个要访问的页,使得这两种策略总是出现 eviction,这也是 LRU 和 FIFO 的最坏情况: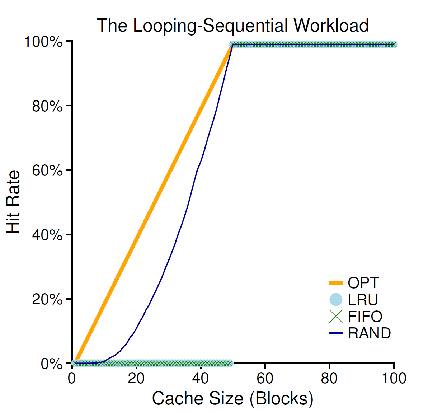
我们注意到,这里 Random 策略显著地更加有效,也证明了我们之前说 “不会受到某些 corner case 的业务情况影响” 的优点。正因如此,TLB 的缓存大多数采用的是这种简单有效的策略。
讨论了上面的一些情况,我们还是发现,在页访问的业务逻辑下,不经常出现 loop sequential 的情况,因此决定采用 LRU 的策略。但是我们如何实现 LRU 呢?
如果要做 LRU,那么就需要各个页打上时间戳,并且需要按时间戳排序。但是 OS 中有上万个页表,平均情况大致映射 4 GB 数据。而无论是打很多时间戳(空间占用),还是要遍历一遍页表(时间占用)对 OS 和硬件而言都是是不可接受的。于是人们想出了一种算法来逼近 LRU 的效果:Clock Algorithm;
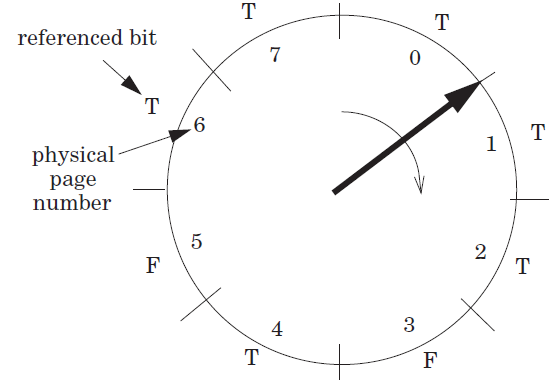
还记得之前介绍的多级页表结构吗?
在硬件层面,保留了 A bit(access bit),相当于给每个页都留了一个 “最近一轮是否访问过” 的标记。将物理页号环形组织,想象有个指针从某个位置出发遍历:
如果访问了一个存在 cache 中的内容,设置该 access bit 为
True;如果出现 swap in / page in,并且没有 evict,那么在钟面空闲区域放一个物理页号,并置 access bit 为
True,将针臂移动到该位置后面的位置;如果出现 evict 时,从指针的当前位置开始按指定方向转动:
如果某个物理页号对应的 access bit 为
True(有效),那么说明最近一轮已经访问过这个页,不对它做 evict,并且把它重置为False(无效);如果某个物理页号对应的 access bit 为
False,那么说明最近一轮没有访问这个页,就决定 evict 这一页。完成后置上True的 access bit;
我们发现 “针臂” 和 access bit 的操作不同步。这主要是因为 “针臂” 是 OS 维护的,在出现 swap in / page in 才会更新;而 access bit 是硬件维护,只要访问了就会更新。
这个缓存策略还有一些补充的措施:
对于写缓存,采取 write back 策略。看到上面的 dirty bit 了吗?当决定 evict 这个页时,会再检查这个页是否被写过(dirty bit 是否有效),如果这个页
MAP_SHARED并且是文件背景页(MAP_FILE),那么在 evict 时还会被持久化起来;我们知道,上述信息是存放在页表中的。那么既然硬件设备(MMU)一次翻译中,只看页表项、只改一个页表项的 reference bit,那么我们怎么知道物理页是否被访问过?
有些同学可能会疑惑,这不是和页表的
Pbit 一样吗?只要知道页表项的物理地址不就行了?其实不然。因为页表中记录的是虚拟页和物理页的映射,程序访问的是虚拟页,所以页表中的 Reference Bit 指定的是虚拟页是否访问。而可能这个物理页被共享了,因此有其他虚拟页可能也指向它,万一其他指向物理页的 PTE 标记没有访问过呢?应该听谁的?
很简单,再为物理页维护一个映射到同一个物理页的
PTE的地址列表。想看这个物理页是否访问过,就无需遍历所有进程的页表,只需遍历维护的PTE列表,就知道究竟有没有访问过。这种方法被称为 Reverse Mapping;
这个列表维护在哪里?实际上在物理页的某个区域(比如物理页的头部),和 OS 的实现有关。对 Linux 而言,这种信息存放在
struct page结构体中;页表自身也在一个物理页上,它自己是否可以 evict?
除了第一级页表不可以(不然没有
CR3从哪里找页表初始位置?),其他几级理论上可以。VMA 是否可以被 evict?
可以。VMA Struct 和页表一样,存放在 Kernel 的 Page 中。结合之前的多级页表,存放 VMA 的地方就是每个进程页表的最下端。所以 VMA 被 evict 的操作和普通页一样,就是 Kernel Page 的一部分放到磁盘中,如上图所示。 如果 VMA 被 evict,假设下次触发了 Page Fault,那么只要 Page Fault Handler 不被 evict,OS 还是会去 VMA 的物理地址找 VMA 的内容,这个时候,发现 VMA 的地址是 invalid(但是 VMA 对应的 PTE 一定会被填上磁盘地址),再触发一次 Page Fault 把 VMA 从磁盘上读出来就行了。
OS Kernel 自己可以不可以被 evict?
理论上部分可行,上面提到过。但 OS 通常不会这么做。
而且像 Page Fault Handler 这样的内存区域就一定不能被 evict。
为此,OS 在 Kernel 所在的物理页上打上不能被 evict 的标记(和 reverse mapping 一样放在 OS 管理物理页的数据结构中)。
除了上面的策略,OS 在进行页的换入时,还会考虑另一个策略:clustering(grouping)。也就是说,OS 会设置两个水位线(low/high water mark):
当空闲物理页数量少于低水位线时,则 OS 对 page eviction 的操作会立即进行;
当空闲物理页数量多于高水位线时,OS 对 page eviction 的操作会停止,或暂缓;
OS 还会采取一些措施,来防止频繁地换页造成性能抖动:
admission control:让一些低优先级、或者后台重要程度低的进程挂起,减少调度机会。这样做可以减小 working set 的大小,起到缓解 thrashing 的作用;
out-of-memory killer:在很多 OS 上,都会在物理页严重不足时强制关闭一些不重要的进程(OS 评分)。这个行为在不同 OS 和应用场景下,其行为有所区别(例如移动端 OS、桌面端 OS、服务器 OS 等等,人们会根据业务场景来选择)。
Chapter 17. Network
17.1 Foundation for Network: Hardware-level
MAC 地址的目的:区分 LAN 中机器身份;
交换机(数据链路层):存放 MAC 地址与端口表;
因此数据包前放一个数据链路层的头部(包含 源 MAC 和 目标 MAC);
使用广播的方式建立交换机内的 MAC 与端口表。
高于 LAN 一层的接口:路由器(网络层),连接和管理各个 LAN;
采用 IP(Internal Protocol)在软件层面标识各个机器;
为什么要引入 IP?因为 MAC 地址没法方便使用(前后缀都有其他含义了);
区分局域网和公网、将 LAN 和 WAN 分割开,区分局域网内不同子网 IP;
同一个子网(LAN)内共用子网 IP 前缀,可以使用 mask 计算出来,被称为 子网掩码;
默认网关:路由器在任意一个子网内呈现的 IP(可以不一样);
路由表:在路由器中的表,将 子网(掩码)与 路由端口联系起来(这样能够判断是否在同一子网中);
路由表生成算法比较复杂,有自动生成的部分,也有人工配置的部分。在计算机网络中介绍。
现在,发送是通过 IP 进行,但是具体在数据链路层需要知道 MAC 地址,这个信息是与 IP 绑定在一起了。每个客户机上都保存了一份 ARP 表(关联子网 IP 地址 和 MAC 地址)。
ARP 表是通过 ARP 协议广播完成的。
上面介绍的都是一个局域网内的网络传输机制,仅涉及局域网中的 IP(其内的 IP 命名使用 DHCP 或其他软件协议完成,可变),或者称为私网 IP。不涉及公网 IP。
实际上存在公网和私网的转换(公网相当于许多子网集群组成的网络),需要通过 NAT(Network Address Translation)等机制完成。但是在 CSAPP 中用不到,无需进一步关注,感兴趣学习计算机网络。
在公网 IP 中,建立了 DNS(Domain Name Server),将公网 IP 与 域名(字符串)联系起来。
17.2 Network Usage: System & Application Level
系统级别,想要将网络包发给某个进程,需要指定 “端口”(port),一个端口对应一个进程(服务);
综上,应用想要与另一个应用建立连接,只需要指定网络层协议(IPv4/IPv6,公私网都行)、端口、传输层协议(TCP / UDP)就行。
17.2.1 Socket Interface
Socket 对 OS 来说是连接的一端,对 Linux 使用者来说,与普通文件无异。
数据结构定义如下:
xxxxxxxxxx/* Internet address */struct in_addr { uint32_t s_addr; /* 32-bit IP address */ };
/* IP socket address structure */struct sockaddr_in { uint16_t sin_family; /* 网络层协议簇 (AF_INET = IPv4) */ uint16_t sin_port; /* 端口 */ struct in_addr sin_addr; /* 网络层协议地址 */ unsigned char sin_zero[8]; /* Padding */};
/* 注:还有 sockaddr_in6 存放 IPv6 信息 */
/* 注:还有 sockaddr_storage. sockaddr_storage 和 sockaddr_in 之间的关系是,sockaddr_storage 是一个通用的套接字地址结构体,可以用来存储任何协议族的套接字地址信息,而 sockaddr_in 是用于表示 IPv4 地址的特定结构体。在实际编程中,通常可以使用 sockaddr_storage 来保证程序的通用性,而在需要处理特定协议族的地址时,可以将其转换为相应的特定结构体,如 sockaddr_in */
/* sockaddr 结构体是个历史遗留问题:当时C语言没有void*,为了让connect, bind,accept等函数的参数接收任意类型的sockaddr, 定义了struct sockaddr *//* Generic socket address structure */struct sockaddr { uint16_t sin_family; /* Protocol family */ char sa_data[14]; /* address data */};Connection
将指定 网络层协议、port、传输层协议 转换为 程序可用的
sockaddr结构体。主要用来查找任何能连接的 socket 信息(hints存放查找条件)。
xxxxxxxxxx
struct addrinfo { int ai_flags; /* Hints argument flags */ int ai_family; /* AF_INET / AF_INET6 */ int ai_socktype; /* SOCK_STREAM / SOCK_DGRAM / SOCK_RAW */ int ai_protocol; /* 0: socket address with any protocol can be returned */ char *ai_canonname; /* Canonical hostname */ size_t ai_addrlen; /* Size of ai_addr struct */ struct sockaddr *ai_addr; /* Ptr to socket address structure */ struct addrinfo *ai_next; /* Ptr to next item in linked list */};
/* 作用:将人类可读的 IP+port+protocol 转换成程序可用的 addrinfo(链表形式存放了 sock 协议信息和 sockaddr 结构体) *//* hints 只需要填写前面 4 字段即可 */int getaddrinfo(const char *host, const char *service, const struct addrinfo *hints, struct addinfo **result);// Returns:0 if OK, nonzero error code on error
void freeaddinfo(struct addinfo *result);// Returns:nothing
/* 如果 getaddrinfo 返回了非零值,那么可以用这个函数查看报错信息 */const char *gai_strerror(int errocde);// Returns: error message
ai_flags 是个 16 进制掩码,可以取:
AI_NUMERICSERV(表示查找时需要指定端口,即service参数放的是端口,而不是服务名);AI_ADDRCONFIG(表示根据当前系统是否配置了 IPv4/IPv6 来返回可用结果。例如一台只支持 IPv4 的机器,如果传入了这个参数,那么不会返回 IPv6 可用的 socket,防止connect/bind出错);AI_NUMBERICHOST(表示传入的是数字 IP,而不是字符串 hostname);AI_PASSIVE(表示选择在监听状态的 socket,而不是查找连接的 socket);
ai_family 指定查找的 socket 遵循的网络层协议(AF_INET IPv4,AF_INET6 IPv6,AF_UNSPEC 任何协议);
ai_socktype 指定查找的 socket 遵循的传输层协议(SOCK_STREAM TCP、SOCK_DGRAM UDP、SOCK_RAW 仅作为文件);
ai_canonname:一个指向规范主机名(如果设置了AI_CANONNAME标志)的指针。不常用。
ai_protocol 常用 0 作为接受任何协议号;
ai_addrlen 保存了维护的 sockaddr 结构体的大小;
将程序可用的
sockaddr结构体转换为用户可读的 网络层协议、Port、传输层协议。主要用来查看当前操作的 socket 的信息。
xxxxxxxxxxint getnameinfo(const struct sockaddr *sa, socklen_t salen, char *host, size_t hostlen, char *service, size_t servlen, int flags); // Returns:0 if OK, nonzero error code on error/* 这个函数也能用上面介绍的 gai_strerror 来获取错误信息 */sa 和 salen 参数不解释。就是之前我们获得的 sockaddr 结构体以及结构体大小信息;
host 是外部提供给这个函数的 buffer,hostlen 表示外界给的 buffer 的大小;
service 也是外部提供给这个函数的 buffer,不再赘述;
flags:用于指定一些标志,影响解析的行为。常见的标志包括:
NI_NUMERICHOST:表示如果无法解析主机名,则将地址转换为数值格式的字符串。NI_NUMERICSERV:表示如果无法解析服务名,则将端口号转换为数值格式的字符串。NI_NOFQDN:表示不要解析全限定域名。NI_NAMEREQD:如果无法解析主机名,则返回错误。……
flag常用前面两个值;
于是 socket 程序总体的业务逻辑如下图所示:
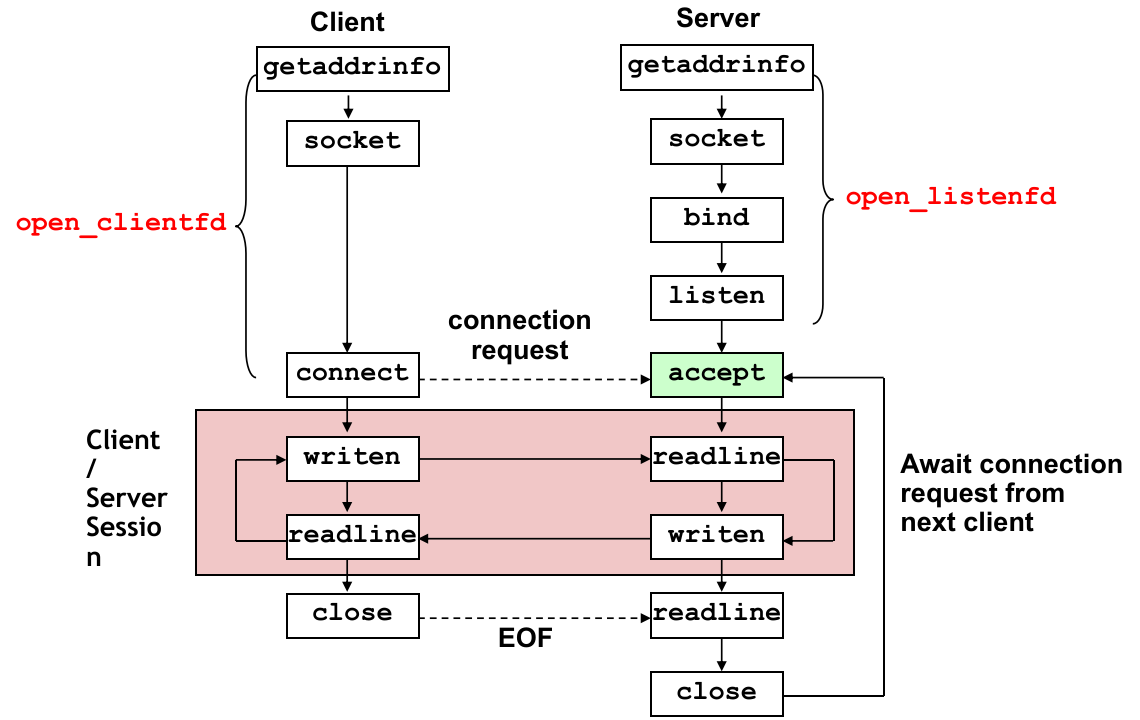
17.2.2 Details of RIO Package
本节详细解释 RIO 包的原理和作用。
网络套接字文件(socket)和普通文件读写都有短读的问题,那么为什么不直接用已有标准的 fread/fwrite 来操纵文件呢?实际上,二者还是有些区别的。
在网络套接字方面,写的问题不大,和普通文件的写一样。由于 RIO 包基于操作系统的 read 接口,因此不可避免地会受到信号中断的影响(触发中断后 read/write 错误并设置 errno 为 EINTR),所以 RIO 包对于写的唯一包装就是:循环写(防止短写)直至写完,中途如果出现 EINTR 则当前轮写入不算,而且不需要写缓存:
xxxxxxxxxxssize_t rio_writen(int fd, void *usrbuf, size_t n) { size_t nleft = n; ssize_t nwritten; char *bufp = usrbuf;
while (nleft > 0) { if ((nwritten = write(fd, bufp, nleft)) <= 0) { if (errno == EINTR) /* Interrupted by sig handler return */ nwritten = 0; /* and call write() again */ else return -1; /* errno set by write() */ } nleft -= nwritten; bufp += nwritten; } return n;}在读的方面,网络套接字文件就比普通的文件麻烦一点。注意到读网络套接字可能被以下因素中断:
中断
read触发EINTR。这个时候读失败需要让nread作废(0),然后重新从上个位置开始读;其他原因导致
read错误。这个时候无法恢复错误;读到
EOF:注意,这是和普通文件读不一样的情况:可能是网络时延问题,剩余部分没有传递完全。即下一次再读这个文件可能就有数据了;
可能是真正结束了,这个结束是由用户传入要读的字节数来定义的。
对于前两种情况,和写操作差不多处理就行,但是最后一种情况不行——因为网络原因,除非读够用户指定的字节数,否则遇到 EOF 不应该认为真正读到文件末尾了。因此 RIO 包的读操作需要阻塞!
为了解决前面两个问题,我们先使用一层没有读缓冲的函数包装一下:
xxxxxxxxxxssize_t rio_readn(int fd, void *usrbuf, size_t n) { size_t nleft = n; ssize_t nread; char *bufp = usrbuf;
while (nleft > 0) { if ((nread = read(fd, bufp, nleft)) < 0) { if (errno == EINTR) /* Interrupted by sig handler return */ nread = 0; /* and call read() again */ else return -1; /* errno set by read() */ } else if (nread == 0) break; /* EOF */ nleft -= nread; bufp += nread; } return (n - nleft);}这个函数会对各种外部中断处理(帮助在 EINTR 出现时循环、其他错误抛出),但是没有针对网络套接字完善(因为遇到 EOF 的处理是直接短读,普通文件是没问题的,但套接字不行),因此需要外部自行处理;
RIO 包的另一个做法是使用一个内置的 buffer 结构读,并且读到内置 buffer 中,规定:
用户要读的
n小于内置 buffer size 时,直接从文件读 buffer size 的数据(填满 buffer),遇到短读EOF也只是填到 buffer 中返回,不作循环;用户要读的
n大于内置 buffer size 时,也是读 buffer size 的数据,把读到的数据复制出去(短读也存在);
这样做是不够的,因为短读没有解决,但是这个包装解决了有 buffer 情况下的 EINTR 和其他中断的问题:
xxxxxxxxxxstatic ssize_t rio_read(rio_t *rp, char *usrbuf, size_t n){ int cnt;
while (rp->rio_cnt <= 0) { /* Refill if buf is empty */ rp->rio_cnt = read(rp->rio_fd, rp->rio_buf, sizeof(rp->rio_buf)); if (rp->rio_cnt < 0) { if (errno != EINTR) /* Interrupted by sig handler return */ return -1; } else if (rp->rio_cnt == 0) /* EOF */ return 0; else rp->rio_bufptr = rp->rio_buf; /* Reset buffer ptr */ }
/* Copy min(n, rp->rio_cnt) bytes from internal buf to user buf */ cnt = n; if (rp->rio_cnt < n) cnt = rp->rio_cnt; memcpy(usrbuf, rp->rio_bufptr, cnt); rp->rio_bufptr += cnt; rp->rio_cnt -= cnt; return cnt;}在这个基础上,我们为了彻底解决网络套接字随时 EOF 的问题,在含有 buffer 的 rio_read 基础上包装了一个必须等待用户指定的字节数 n 全部读完的函数 rio_readnb,它同时解决了两个问题:
套接字文件随时
EOF短读。这个函数会阻塞等待,一直调用rio_read从套接字中读取直至读够n个字节;rio_read内置大小不足的问题。假设用户指定的n比内置 buffer 更大,那么这个包装函数会一直从内置 buffer 取数据给用户 buffer。
这样一定能保证 rio_readn 返回时,除非出现无法恢复的 read 错误,用户 buffer 一定会被填入 n 字节的套接字内数据(可能会通过阻塞来达成这个目的)。
正因如此,这个 RIO 包不应该用在普通文件上:因为假设文件内容长度小于用户指定的 n,rio_readnb 会永远卡死,除非外部进程 / 线程添加了内容。
rio_readlineb 和 rio_readnb 思路一样,只不过它会以 \n 和用户给定的 maxline 作为结束判据。
17.3 Web Server
Chapter 18. Concurrency
18.1 Overview
应用级并发非常有用:
响应 asynchronous exception;
多处理器并行计算;
访问慢 I/O 设备加速;
用户界面交互程序(interactive jobs);
网络服务器与多客户端连接;
程序并发的实现手段:
多进程(借助 OS Context Switch 造成的 interleave),已在前面介绍,本章不再赘述;
多线程;
I/O 多路复用;
然而,写并发程序很难。主要是因为:
人们的思维是串行的。很难想到并发事件的所有可能组合;
并发程序的常见问题,这是并发程序所不可避免的:
data races(数据冒险)、deadlock(死锁)、starvation(并发饥饿);
18.2 Thread
18.2.1 Introduction to Thread
Rules:
Each thread has its own logical control flow (sequence of PC values);
Each thread shares the same code, data, and kernel context;
Each thread has its own thread id (
TID);A thread is either
joinableordetached:joinable: MUST BE reaped by main thread (DEFAULT);detached: Resources are automatically reaped on termination.
POSIX API:
xxxxxxxxxx/* Compile option: -lpthread / -pthread */
/** * Create a new thread * * @param[out] thread Output the tid of the new thread * @param[in] attr The attribute options of the new thread (NULL for default) * @param[in] start_routine The thread function wrapper in (void*)(*)(void*): * - Function input: void* Input arguments * - Function output: void* Return information * (if start_routine returns, it will implicit call `pthread_exit`) * @param[in] arg The arguments for `start_routine` * * @return 0 if success, `errono` if error(s) occurred (Now `thread` undefined). */int pthread_create(pthread_t *restrict thread, const pthread_attr_t *restrict attr, void *(*start_routine)(void *), void *restrict arg);
/** * Join the main thread with the child thread. * The main thread can: * - wait && get the return result of the child thread; * - reap the child thread * * @warning Try to join a detached thread will cause UNDEFINED BEHAVIOR! * * @param[in] thread The specific thread with tid * @param[out] retval The return value of the thread * - If NULL is passed, do nothing; * - If child thread is canceled, then pointed to PTHREAD_CANCELED * - If child thread return something, then set retval point to it. * * @return 0 if success, `errono` if error(s) occurred. */int pthread_join(pthread_t thread, void **retval);
/** * Get the TID of the calling thread. */pthread_t pthread_self(void);
/** * Detach the current thread from main thread. * The status of the thread: Joinable -> Detached * * @warning Try to detach a detached thread will cause UNDEFINED BEHAVIOR! * * @param thread The specific thread * @return 0 if success, `errono` if error(s) occurred. */int pthread_detach(pthread_t thread);
Compared with Process:
| Metrics | Thread | Process |
|---|---|---|
| Own Logical Control Flow | ✅ | ✅ |
| Concurrency | ✅ | ✅ |
| Context Switch | ✅ | ✅ |
| Memory Isolation (Virtual Memory) | ❌ | ✅ |
| Overhead (Create & Reap) | ~10 K Cycles | ~20 K Cycles |
对于并发(Concurrency)而言,Thread 也可以。这主要是因为 OS 也会给 Thread 提供 Context Switch。不同的 thread 虽然会共享虚拟内存(内存条硬件),但是不会共享 CPU 中的状态。因此:
对于单核机器而言,多线程的 concurrency 和多进程一样,依靠 Context Switch 切换;
对于多核机器而言,在 OS 的调度下,一个进程多线程可以被分配到多个核上,实现真正意义上的并行(parallelism);
Memory Sharing 造成的 Unintentional Sharing 有哪些情况?
参数传递使用值传递:
xxxxxxxxxx/* ... other codes ... */int test = 0; /* local variable */pthread_create(&tid, NULL, routine, &test);/* ... other codes ... */上面的代码向子线程传递了 栈上的局部变量,可能造成子线程访问一个已经做其他用途的内存空间(因为没法预测 context switch 所做的顺序、长度)。
正确做法是对不同线程,在堆上分配一个新的空间,并给子线程传递;
18.2.2 补充:Memory Sharing & Isolation of Thread
你可能开始疑惑,线程究竟有哪些数据能相互共享、哪些数据是线程自己私有的?
回忆一下,一个进程的虚拟内存中有哪些成分?
内核态空间(即 OS Kernel):进程虚拟内存的顶部位置,被 OS 保护起来,含有 PCB(进程控制块);
进程控制块中含有:
进程 ID;
进程的 PC 值;
进程的 CPU 寄存器状态;
进程的文件描述符表(file descriptor table,每个 entry 指向一个进程打开的文件的 file structure);
进程的内存管理区域:例如页表、内存限制数据等等;
进程信息结构体,包括子进程的
PID等信息,可能组织成队列或者其他数据结构;进程状态,例如 Ready、Running、Waiting、Dead 等等;
进程间通信信息,例如信号(block/pending bit vector)、内部 flags;
进程优先级信息;
进程调度状态(和进程状态不同),例如 Ready、Suspend、Traced 等等;
用户态空间(包括
.text/.data、heap、stack 等等):
现在告诉你,其实 OS Kernel 中还含有一块数据结构,称为 TCB(Thread Control Block,线程控制块),Kernel 中可以有多个 TCB,因为可以有多个线程。一个 TCB 包含以下数据:
进程中一个线程的 ID(
TID);进程中一个线程的 stack pointer(SP,一个线程只是占用一块栈帧而已,甚至其他线程可以用指针访问);
进程中一个线程的 PC;
进程中一个线程的状态(线程的状态有 5 种:running, ready, waiting, start, done);
进程中一个线程的 CPU 寄存器状态;
指向该线程所依附的进程的 PCB 的指针;
上面的 PCB 和 TCB 在 OS 管理进程(例如 Context Switch)的过程中扮演重要角色。
所以,这下你清楚了吧?
线程共享的数据就是 TCB 中不单独存储的、内存中的数据。有:文件描述符表、页表、所在进程的所有信息、全部的用户态空间;
线程不共享的数据就是 TCB 中存放的数据。有:各种线程信息、SP、PC、CPU 寄存器值。
对于共享的数据,我们需要关心的是文件描述符以及栈上的数据传递问题:
文件描述符 被一个进程的全部线程共享。产生一个线程后,指向 file structure 的 file descriptor 不会增多。也就是说,一个线程操作文件描述符(创建、关闭、写入、读取等)都会影响其他线程;
全局变量 定义在
.data/.bss段,因此一个进程的所有线程共享同一份全局变量。对这个变量的更改会影响其他所有线程;静态局部变量 定义在
.data/.bss段,因此一个进程的所有线程共享同一份静态局部变量。对这个变量的更改会影响其他所有线程;普通局部变量 被编译器管理在栈帧上,因此每个线程各自在栈上持有一份局部变量的实例。
例如下面这段程序:
xxxxxxxxxxvoid *thread(void *vargp);
char **ptr;
int main(){ int i; pthread_t tid; char *msgs[N] = { "Hello from foo", "Hello from bar" };
ptr = msgs; for (i = 0; i < N; i++) pthread_create(&tid, NULL, thread, (void *)i); pthread_exit(NULL);}
void *thread(void *vargp){ int myid = (int)vargp; static int cnt = 0;
printf("[%d]:%s(cnt=%d)\n", myid, ptr[myid], ++cnt);}main函数中的局部变量i、tid、msgs指针数组,都由编译器管理,存放在main的栈帧上;全局变量
ptr未初始化存放在.bss段,被其他所有线程共享;由于在主线程开始时,
ptr = msgs,因此ptr指向了main栈帧的一个局部变量,msg“被迫共享”;
静态局部变量
cnt存放在.bss段(初始化为 0),因此也被所有线程共享,但是由于主线程没有访问到cnt的手段(例如指针位置),因此正常情况下看起来只有子线程共享。局部变量
myid由编译器管理,存放在各个线程自己的栈帧上;
特别地,我们将 “变量线程共享” 定义为:一个变量 x 被多个线程共享,当且仅当多个线程至少可以对同一个 x 的实例(内存地址)引用。
所以,上面的例子中,msgs 是共享的(即便它位于 main 栈帧)、ptr 是共享的、cnt 是共享的;
而 i/tid/myid 都不是共享的。
18.2.3 Semaphores: 线程间信号量
现在看起来我们只要知道了线程间变量共享的情况、知道了在线程间参数传递的危险性,不就可以正确地编写多线程程序了,对吗?
可惜的是,还有一个相当严重的问题。我们现在知道了不同线程有变量共享的情况,似乎没啥问题,但问题是各个线程是并发的,执行先后顺序是不确定的。那如果它们同时操作共享在内存上的变量会发生什么?
你可能会说,没问题啊?操作就是啦,反正最后结果不是共享在内存上咯。
问题在于,线程只是共享了内存,而没有共享 CPU 状态。
再加上程序对内存的更改并不直接在内存上完成:在汇编中可以看到,大致经历了 load(从内存到 CPU 寄存器)、update(在 CPU 寄存器内更新数据)、store(将 CPU 寄存器数据写回内存)这 3 步。
如果一次 Context Switch 恰好在 Load + Update 和 Store 之间出现,并且切换到的同一进程、另一个线程正好要读同一个内存,这就会发生 脏读(dirty read)。
回忆数据库的知识,如果两个连接对同一个记录进行查询、更改,如果没有事务的保护,可能出现脏读、不可重复读、幻读这 3 种情况。
这里的情况出现的原因和线程访问共享变量道理是一样的。
线程访问共享变量也会遇到:脏读、不可重复读(程序中不存在变量增删的情况)。
根据程序的局部性原理、context switch 的随机性,出现这种情况几乎是必然的。我们一定要避免这种情况的发生!
怎么避免?我们首先要讨论上面 “脏读”、“不可重复读” 出现的准确时机。
我们简化一下讨论的情形,假设我们讨论 “两个线程向全局变量累加一亿次” 的情形:
xxxxxxxxxx
void *count(void *arg);
/* shared variable */unsigned int cnt = 0;
int main(){ pthread_t tid1, tid2;
pthread_create(&tid1, NULL, count, NULL); pthread_create(&tid2, NULL, count, NULL); pthread_join(tid1, NULL); pthread_join(tid2, NULL);
if (cnt != (unsigned)NITERS*2) printf("BOOM! cnt=%d\n", cnt); else printf("OK cnt=%d\n", cnt); exit(0);}
/* thread routine */void *count(void *arg){ int i; for (i = 0; i < NITERS; i++) cnt++; return NULL;}我们可以将 thread routine 中的操作分成之前说的 load、update、store 3 步:

接下来,我们引入一种更清晰的表述各阶段执行顺序的图:process graph,来描述可能的并发情况。
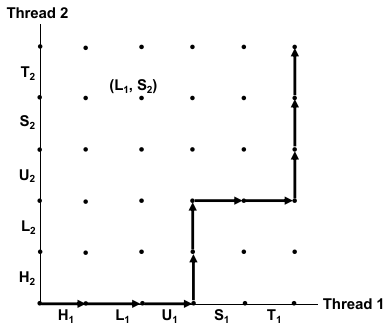
一个 process graph 描述了并发线程的离散的执行状态空间(discrete execution state space);
坐标轴正方向指明了一个线程的指令执行顺序(sequential order);
H、T分别代表了在 load/update/store 关键步骤前后,与要访问内存无关的执行逻辑。
图中的每个点表示了同一时间,各个线程的执行状态;
例如,
图中的一条迹(trajectory)代表了一种可能的执行顺序;
迹 仅能向右、向上两个方向:由指令执行顺序决定;
迹 不能沿对角线方向:即便是多核,也几乎不可能让两条指令真正意义上同时执行,总有先后关系。
那么,“脏读”、“不可重复读” 的执行先后序列在这幅图中怎么表示?
显然,在 load / update 间、update / store 间任意一个间隙出现 context switch,都会发生脏读的情况。于是,我们将 load-update-store 规定为 critical section,这 3 个操作需要是原子性的,否则就会出现问题。
而被 critical section 围住的状态区域称为 unsafe region,一切经过 unsafe region 的执行序列(迹)一定会发生脏读:
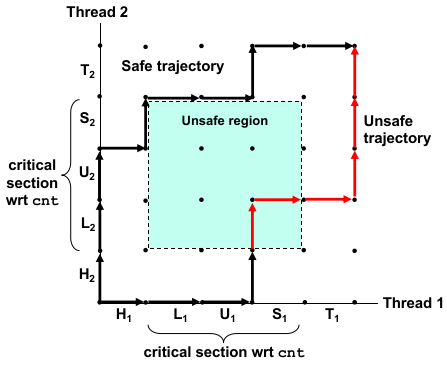
表述出了这种情况,我们就可以想办法解决:不允许程序执行序列进入 unsafe region,就可以避免脏读情况的发生。图灵奖得主 Dijkstra 就设计了一种方法:semaphores(线程间信号量,原意是火车信号灯)。
他定义,semaphore 就是一个用于同步信息的非负整型。并且定义了 2 个针对 semaphore 的操作:
P 操作(荷兰语
Proberen,test),其语义如下:xxxxxxxxxxP(s):while s == 0:wait()s--V 操作(荷兰语
Verhogen,increment),其语义如下:xxxxxxxxxxV(s):s++
这两个操作会绝对保证原子性(期间不发生 context switch)。
这可以做些什么呢?这可以保证限制资源访问者的数量。意味着,同一时间,如果 s 减为 0,那么执行 P 的程序将一直等待下去,直至另一个并发的程序调用了 V 让 s 增加。
这个效果就相当于调用 V 的程序 “唤醒了” 正在等待 semaphore 的另一个程序。另一个程序在等到 semaphore 前,绝不继续执行,就像给下面要执行的代码 “上锁” 了一样。
如果我们让 s 初始化为 1,并且在操作 cnt 的前后加上 P(等待 semaphore)、V(释放 semaphore),就像这样:
xxxxxxxxxx/* thread routine */void *count(void *arg){ int i; for (i = 0; i < NITERS; i++) { P(s); cnt++; V(s); } return NULL;}我们会惊喜地发现,所有 unsafe region 区域的 semaphore 都是 -1!因为我们限制 semaphore 是非负整数,因此 unsafe region 永远不可达,相当于在 unsafe region 周围建立了一个围墙。彻底解决了访问不安全的问题:
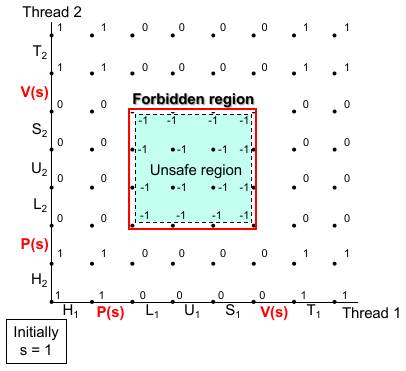
如果我们改变 s 的初始值会发现它的意义:s 的初始值限制了 能同时访问在 semaphore 保护下的代码 并发执行的线程数量。
而 s = 1 的情况比较常见,就是只允许一个线程并发执行受保护的代码(在上面的例子中,就是 cnt++ 改变内存变量的代码)。
这个情况下,semaphore 被称为 binary semaphore。
Binary Semaphore 和 互斥锁(
mutex)有些微妙的区别。Mutex 相比 binary semaphore 增加了所有权的概念,一只锁住的 Mutex 只能由给它上锁的线程解开,只有系铃人才能解铃。Mutex 的功能也就因而限制在了构造 unsafe region 的 “围墙” 上。
Binary semaphore 则可以由任一线程解开。比如某进程读取磁盘并进入睡眠,等待中断读取盘块结束之后来唤醒它,而这种情况 Mutex 是解决不了的。
这是因为 semaphore 的语义有两个功能:保护资源 + 通知。除了限制资源并发数量,semaphore 的释放还能通知等待 semaphore 的线程。
Mutex 相较 semaphore 的优势在于,Mutex 职责更单一,语义更清晰,实现的效率稍微高一点。
那么怎么用 semaphore 呢?在 POSIX 标准中,C 库里有这些方法:
xxxxxxxxxx
/* 设定 s 的初始值,也就是允许并发执行被保护代码的线程数量 *//* pshared 表示是否与其他进程共享这个 semaphore;通常设置为 0 表示不共享 * 共享方法使用 fork,父进程的 semaphore 可以被子进程所使用 */int sem_init(sem_t *sem, int pshared, unsigned int value);int sem_wait(sem_t *s); /* P(s) */int sem_post(sem_t *s); /* V(s) */这些 P/V 操作的原子性由 OS 保证。
18.2.4 Applications of Semaphore
我们引入了 semaphore 成功解决了线程的并发访问内存数据的问题。
那么哪些典型的情况会出现 “并发访问内存数据” 呢?也就是说,semaphore 的使用场景有哪些?
先考虑一个经典模型:生产者-消费者模型。
Producer-Consumer Problem
假设有两个线程,一个是产生数据的线程(称为生产者),另一个是读取数据的线程(称为消费者),它们交换数据的方式是通过访问内存中的一段共享 buffer 来实现的:
生产者向共享 buffer 中插入产生的数据,并且提醒消费者;
如果共享 buffer 中全是未读(未被消费)的数据,那么生产者挂起等待,直至有空位为止;
消费者从共享 buffer 中读取未读的数据,从 buffer 中拿走,并通知生产者;
如果共享 buffer 中没有新的数据,那么消费者挂起等待,直至有新的数据为止;
对于 1-element buffer 而言,我们只需要维护 2 个 semaphores:一个提示 buffer 空(让 producer 用 P 等待这个信号量),另一个提示 buffer 满(让 consumer 用 P 等待这个信号量);
对于 N-element buffer 而言呢?思路需要转变一下。
首先先确定 buffer 的结构。因为有 N-element,因此我们选择循环队列的方式存放 N 个元素。在结构体中保存
buf本身、n(最大容量)、front/rear(前后索引,指向当前队头元素、队尾元素);其次,我们需要确保 producer、consumer 线程中只有一个可以访问 buffer 的指针(例如
front/rear),于是使用 binary semaphoremutex对 buffer 加锁;这里在语义上应该使用 Mutex 而不是 Semaphore,因为:
有所有权关系(谁加的锁语义上就应该谁解开);
不需要计数和通知。这个任务已经委托给下面的
slots和items了;
再次,我们需要两个能计数的信号量通知 Producer、Consumer 队空、队满的情况,让它们分别用
P等待。因此需要slots和items两个信号量;
Readers-Writers Problem
资源访问互斥问题的一种泛化。
假设还是有两个线程,一个线程只读对象(称为读者),另一个线程只写对象(称为写者)。
这种模型是读者-写者模型,广泛应用于航线监测系统、多线程 web proxy 缓存系统等等场景。
我们根据线程可能出现并发写内存的问题,判断 同一时刻只能有最多一个写者访问特定的对象,但是可以有任意多个读者读对象,因为只是读内存不会造成并发的问题。
那么现在有两种解决方案:
Favors Readers:只要有读者,那就优先读者,写者需要等待到没有读者后写;写者间采用普通队列方式等待;
优势:read throughput 很高;
劣势:但如果读的频率很高,可能造成写者饥饿的情况;
Favors Writers:只要有写者,那就优先写者,读者需要等待到没有写者后读;读者间采用普通队列方式等待;
优势:write throughput 很高;
劣势:但如果写的频率很高,可能造成读者饥饿的情况;
以 Favors Readers 为例,我们可以这么设计:
定义一个描述当前读者数量的变量:
readCnt,可以知道当前是否有线程在读;对应地,需要保护
readCnt,因此加入 Mutex 来保护readCnt;由于资源对象只会因为 Writers 改变,所以为资源上一把 Binary Semaphore
w;这里不能使用互斥锁。因为只要存在 Readers 时,就要保护资源不被 Writers 更改,那么根据语义,就要第一个读者进入时为资源加锁禁止 Writers 更改,直到最后一个读者结束后才为资源释放锁。
这个时候 “锁” 没有所有权的概念,可以由不同线程操作,核心作用就是通知 Writers 当前有人读,不能写。所以这里只能用 Binary Semaphore,而不能用 Mutex;
在一个 Reader 进入时,首先要获得
readCnt锁来改变当前readCnt,然后检查自己是否为第一个 reader,如果是,那么拿到wsemaphore(等待之前正在进行的 writer,阻塞后面的 writer);然后释放readCnt锁并且读;结束时再获得readCnt锁并更新,如果自己是最后一个读者,那么释放wsemaphore 允许后面的 writers 继续进行;
如果是 Favors Writers 呢?情况有些不同。和 Readers 不一样,Writers 本身还要等待之前正在进行的 Writers,直到它们结束任务。所以我们需要这么设计:
只要当前有 Readers,Writers 就不能进行。所以需要记录当前 Readers 数量,记为
readers;只要当前有 Writers,Readers 和其他 Writers 都不能进行。所以记录当前 Writers 数量,记为
writers;只要当前有正在等待写入的 Writers,Readers 就不能进行(因为 Favor Writers),所以还要记录当前等待的 Writers 数量,记为
waiting_writers;最后,任何时刻只能有一个线程修改以上的数据,所以还应该定义一个 Mutex
mutex来保护以上数据;那么在读者进入时:读者需要先获得
mutex(需要获得的原因是,这个 Reader 要读当前的统计数量,阻止其他 Readers 和 Writers 改变),然后再看waiting_writers和writers来了解当前的写者、等待的写者的数量。如果任意一个不为 0,则读者不能进行任何操作。所以读者应该放掉读统计量的mutex、放掉 CPU 资源等待(usleep)一段时间,再检查,直至没有waiting_writers和writers,这个时候开始读(增加readers后释放mutex)。结束读后再获得mutex,减去readers再释放mutex;在写者进入时:写者先获得
mutex,再看当前readers和writers的数量,如果任何一个不为 0,那么这个写者就应该进入等待状态(增加waiting_writers)并释放mutex、释放 CPU 资源等待,直到readers和writers都为 0,开始写(增加writers后释放mutex)。结束写后获得mutex,减去writers再释放mutex;
18.2.3 补充:GDB 多线程调试和多进程调试
多线程:注意,GDB 断点默认对同进程所有线程同时生效。
info thread:查看当前所有线程信息;set scheduler-locking replay (default):调试某个线程时,如果遇到断点,其他线程一起挂起,继续则一起继续;set scheduler-locking on:调试某个线程时,锁定并发调度器。只有当正在调试的线程触发断点时,才完全不允许其他线程执行;set scheduler-locking off:不锁定并发调度器,这意味着会模拟真实的线程并发场景:即调试某个线程时,其他线程正常执行(但是断点会生效,如果其他线程运行到断点,会调度到遇到断点的线程上);
以上 3 种
scheduler-locking如果没遇到断点(gdb 没向总体进程发信号),那么所有线程该怎么跑怎么跑。thread <n>:切换到指定线程编号上调试;thread apply all <command>:向所有线程执行 GDB 指令;thread apply <n1> [n2 n3 ...] <command>:向指定的线程执行 GDB 指令;
多进程:
info inferiors:查看当前所有进程信息;set follow-fork-mode parent(default)/child:调试多进程时,如果出现fork,默认优先进入什么进程调试;set detach-on-fork on (default):在调试多进程时,按照follow-fork-mode设定的值进入指定进程调试,其他进程不受断点影响;set detach-on-fork off:在调试多进程时,按照follow-fork-mode设定的值进入指定进程调试,但是其他被创建的进程立即挂起在原地;inferior <n>:切换到指定进程调试;
18.3 I/O Multiplexing
Motivation: 一个程序同时对键盘、网络网卡设备的输入监听;
在不使用多进程、多线程的情况下,可以采用 I/O 复用(逻辑并发):
利用系统调用让 OS 帮我们选当前唤醒的输入设备;
xxxxxxxxxx
/** * 该函数会阻塞监听指定的 readfds 列表中所有文件,直至列表中任一个文件能够被 read(不是 EOF) * * @param[in] maxfd 最大监听的数量(`readfds` 有几个 bit 位) * @param[in/out] readfds 所有要监听的 file descriptor 列表(每个 bit 代表对对应的 fd 进行监听),最大默认 `FD_SET_SIZE` bits; * 也是结束监听时能读 fd 的返回值。 * 只需要了解前两个参数,后面 3 个配置参数一般填 NULL */int select(int nfds, fd_set *_Nullable restrict readfds, fd_set *_Nullable restrict writefds, fd_set *_Nullable restrict exceptfds, struct timeval *_Nullable restrict timeout);当 readfds 中存在能读的 fd,那么将能读 fd 位置置为 1,其他位置为 0,并返回当前能读的 fd 数量。
为了方便操作,C 提供了一系列操作这个 readfds 的宏:
xxxxxxxxxx/* clear all bits in fdset. */void FD_ZERO(fd_set *fdset);/* clear bit fd in fdset */void FD_CLR(int fd, fd_set *fdset);/* turn on bit fd in fdset */void FD_SET(int fd, fd_set *fdset);/* Is bit fd in fdset on? */int FD_ISSET(int fd, *fdset);于是使用 select(I/O Multiplexer)编写简单的逻辑并发程序的主要步骤如下:
设定感兴趣的
readfds,在循环中调用select;在
select返回后验证响应的fd,并对应地处理;
对于复杂的 I/O 复用的场景,例如 I/O 复用以提升网络服务器性能的场景,我们需要:
维护一个已连接的文件描述符池,并且在无尽循环中 使用
select进行以下操作:监听
listenFd的活动(有连接请求到达就会触发);这种情况下,创建新的连接,并将连接加入已连接的描述符池中;
监听已连接的文件描述符池中的每个文件,客户端有发送消息就触发;
这种情况下,对该文件进行相应的响应处理;