Chapter 10. The Memory Hierarchy10.1 Storage Technologies & Trends10.1.1 Random-Access Memory (RAM)10.1.2 Nonvolatile Memories10.1.3 Traditional Bus Structure Connecting CPU and Memory10.2 Locality10.3 Conclusions for 10.1 & 10.210.4 Memory Hierarchy & Idea of CachingChapter 11. Cache Memories11.1 General Cache Organization11.2 Read Cache11.2.1 Direct-Mapped Cache Simulation11.2.2 E-Way Set Associative Cache Simulation11.3 Write Cache11.4 The Hierarchy of Cache Memories11.5 Performance Impact of Cache11.5.1 Writing Cache Friendly Code Ⅰ11.5.2 The Memory Mountain11.5.3 Writing Cache Friendly Code Ⅱ - Rearranging loops to improve spacial locality11.5.4 Writing Cache Friendly Code Ⅲ - Using blocking to improve temporal locality11.5.5 Cache Performance SummaryChapter 12. Program Optimization12.1 Goals of Optimization12.2 Limits to Compiler Optimization12.3 Generally Useful Optimizations12.3.1 Constant Folding12.3.2 Dead Code Elimination12.3.3 Common Subexpression Elimination12.3.4 Code Motion12.3.5 Inlining12.3.6 Strength Reduction12.4 Obstacles for Compiler to Optimization12.4.1 Optimization Blocker #1: Procedure Calls12.4.2 Optimization Blocker #2: Memory Aliasing12.5 Machine-Dependent Optimization12.5.0 Data-Flow Representation: Machine-level Profiling12.5.1 Branch Misprediction Recovery12.5.2 Scheduling12.6 Summary
Chapter 10. The Memory Hierarchy
本章将介绍系统的内存分层架构。
之前几章,我们对于内存的理解就是一个很大的字节数组,可以用地址作为下标进行访问。但事实上,真正的计算机的存储系统背后的设备层次结构设计远比这层抽象要复杂。
正是计算机的存储系统的层次结构对有限、离散资源的管理和抽象,才能让程序的内存看起来呈现出这种线性的数组结构。本章就来讨论计算机存储系统背后的层次结构。
10.1 Storage Technologies & Trends
在正式学习存储系统的层次结构前,有必要稍微弄清楚底层硬件的情况。
10.1.1 Random-Access Memory (RAM)
当前大多数人所熟知的 “内存” 的一部分就是随机访问存储器(RAM),它具有以下的特征:
RAM 是个存储元件,I/O 吞吐速率快于绝大多数硬盘固件/磁盘(称为 “外存”);
RAM 常常被打包放在 CPU 芯片中;
RAM 中每一个基本的存储单元被称为 单元胞(Cell),一个单元胞中存放 1 bit 数据;
很多个 RAM 芯片共同工作,组成了计算机的 主存(主存储器)。
RAM 分为 2 类,它们之间根据存储单元胞的实现方式来区分:
SRAM(Static RAM),静态随机存储器;
DRAM(Dynamic RAM),动态随机存储器;
Trans. per bit Access time Needs refresh? Needs EDC? Cost Applications SRAM 4 or 6 1 × No Maybe 100 × Cache Memories DRAM 1 10 × Yes Yes 1 × Main memories, frame buffers 注:
Trans. per bit表示每 bit 需要多少根晶体管,EDC指电子数据捕获。从上面这张表可以得知,SRAM 比 DRAM 成本高很多,因为 SRAM 的每个储存单元胞都更加复杂。正因如此,SRAM 的访问速度远远快于 DRAM,因此常被用在 Cache Memories(高速缓存器)中(成本也是高速缓存通常大小比较小的原因之一)。
Needs EDC 的含义是指,必须用一定的电压作用在存储单元胞的两端,否则一断电就会丢失电荷,数据也会丢失(又称 Volatile Memories)。这也是 RAM 需要插电用的原因(当然,如果把它从电源上拔下后迅速扔进液氮中,可以保留其中数据,因为电荷散失速度可以忽略)。
DRAM 被广泛应用于主存、图形显卡的 帧缓存(frame buffer)中。
10.1.2 Nonvolatile Memories
ROMs
除了 RAM,计算机存储系统中另一类存储器是 非易失性存储器,它们在计算机断电后仍然能保存数据。请回忆数电中介绍的几种电子元件:
ROM(Read-Only Memory,只读存储器),出厂时就编程完成,通常电路烧在板子上不可更改;
PROM(Programmable ROM,可编程只读存储器),只能对电路编程一遍;
EPROM(Erasable PROM,可清除可编程只读存储器),可以被特殊作用清除电路信息(UV / X-rays);
EEPROM(Electrically Erasable PROM,电驱动可清除可编程只读存储器),可以使用电路、电子清除其中信息,但只能反复清除重写 100,000 次。
它们的电路结构想必各位脑海中都非常清楚对吧?
其中,大家所熟知的 闪存(Flash Memory),就是许多 EEPROM 元件组成的。
Tips. 计算机存储系统中的主存包括了 ROM 和 RAM,但闪存作为 ROM 的一种,也是现代最常用的 ROM,也可以和机械硬盘一起被用在外存中。
这些 ROM 的作用很广泛,主要有以下几个方面:
普通 ROM 常被用作重要的、不应该被更改的数据的存储,例如 BIOS(存储计算机系统启动时的指令 + boot 引导程序)、Controllers for disks(硬盘控制器)、Network Cards(网卡)、Graphics accelerator(图形加速器)、Security subsystem(安全子系统);
它们(闪存)还会被用在 固态硬盘(SSD,Solid State Disk,代替转圈易坏的机械硬盘,用在笔记本电脑、手机、mp3 播放器、平板等设备,系统会把 SSD 看成机械硬盘)中;
机械硬盘
除了 ROM 一类的非易失性存储器,还有 外存(外部存储器)也是非易失性存储器。我们这里介绍有代表性的机械硬盘:
结构包括传动臂、SCSI 连接口、盘片、盘片轴……
硬盘中包含一系列盘片(platter),每个盘片有两个面,每个面上涂有磁性材料,并且存在一圈圈同心圆(concentric rings),被称为 磁道(tracks),每个磁道包含若干 扇区(sectors),扇区之间会有空隙间隔(gaps),一个扇区通常的大小是 512 bytes;
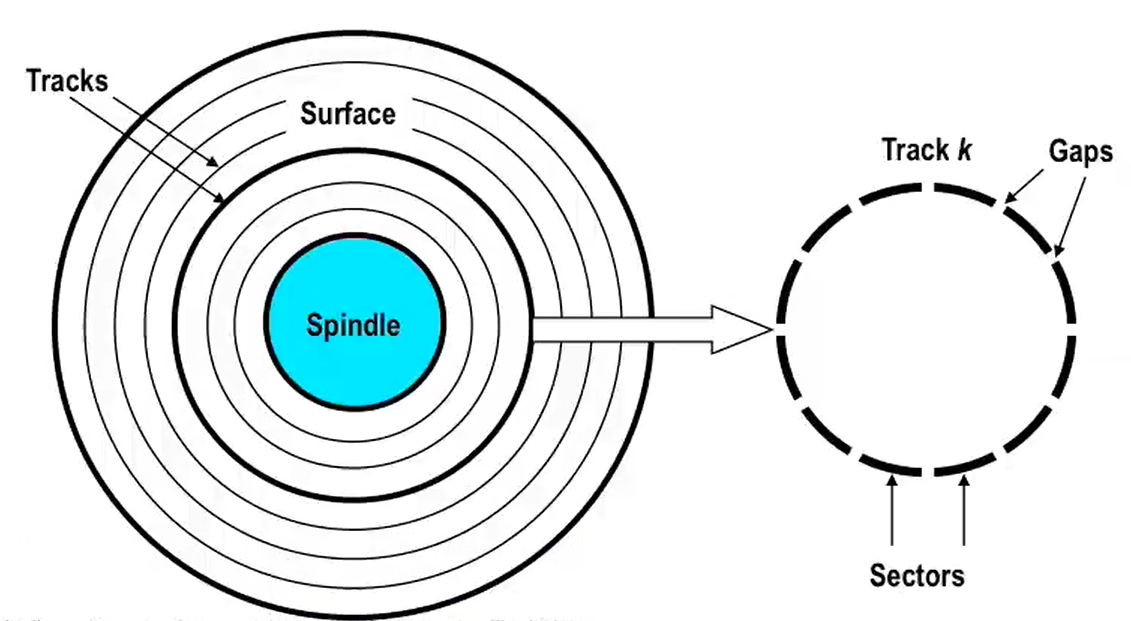
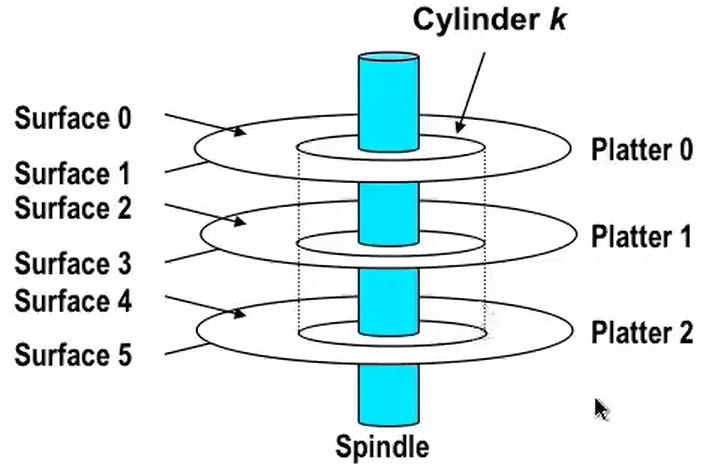
盘片轴(spindle)连接一系列盘片,每个盘片相同位置对齐的磁道称为 Aligned tracks,在垂直方向组成一个圆柱,这个相同位置的磁道所组成的元素称为 柱面,数据按照不同柱面进行存储,同一柱面的数据连续(为啥按柱面存?因为方便机械臂访问)。
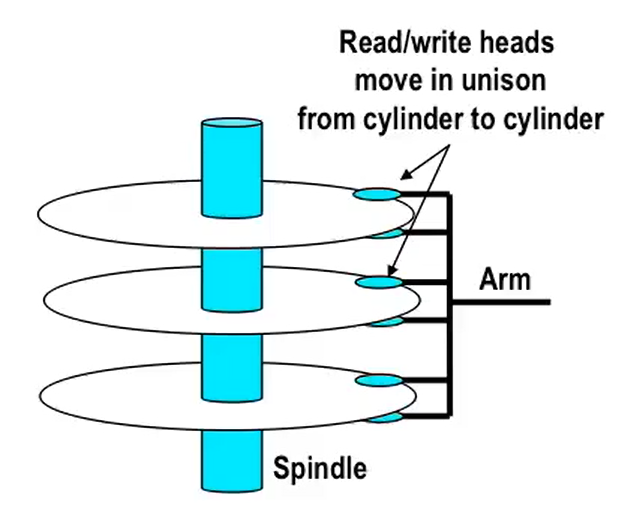
传动臂悬浮在盘片上方,隔着一层薄薄的空气。其末端读写头可以感知编码位的磁场变化;
机械磁盘内置电子设备,用于控制传动臂的移动等操作,其驱动程序一般存于 ROM 中;
机械性质决定了机械硬盘的读写速率慢于 RAM 和 ROM;
硬盘承载量取决于 数据记录密度(recording density,1 inch 磁道段中能存放多少 bit 信息)、磁道密度(track density)、面密度(Areal density,前面二者的乘积);
⚠ 易错点警告:对于硬盘来说,它的承载量单位 GB 是特殊的:1 GB =
Bytes,这与之前我们见到的衡量二进制数据大小的单位 GiB(其简称也叫 GB,1 GiB = Bytes)是不一样的。 这么说就明白了:承载量单位应该分开来看:1 G | B,1 吉 (Giga) =
; 而衡量二进制数据大小的单位是个整体: 1 | GiB,GiB 本身是 gibibyte(giga-binary byte),是 byte 单位的
倍; 最常见的是计网的考题:1 MB/s 在 1 s 内传输的数据量略小于 1 MB,因为承载量速率单位 1 MB/s 是
Bytes / s,而数据大小 1 MiB 是 Bytes;
在很早以前的机械硬盘中,每个磁道的扇区数目固定,这会导致大量的空间浪费。所以现代的机械磁盘将许多磁道划分为一个个不相交子集,称为记录区(recording zones):
每个处于同一记录区中的磁道含有相同的扇区数,它取决于最内侧磁道;
每个记录区中的磁道的扇区数不同,越靠近内圈的记录区中磁道的扇区数越少;
因此我们使用平均扇区数 / 磁道数来计算承载量;
如下图,阴影部分为一个记录区,含有许多扇区数相同的磁道:
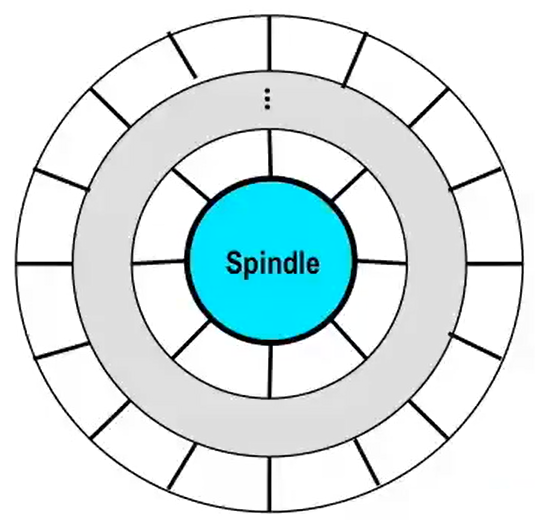
题型:计算磁盘承载量
承载量 = 每个扇区的 byte 数(通常 512 bytes)× 一个磁道中平均扇区数 × 一个盘面中的磁道数 × 一个盘片上表面数目(对三维生物来说=2)× 每个磁盘的盘片数;
机械硬盘借助悬浮在盘面上方的传动臂进行读取,许多传动臂在磁盘同一半径处读写,其搜索读取读取速度取决于三个因素:寻道时间(一般最长,大约 3~9 ms)、旋转延迟、传输时间。
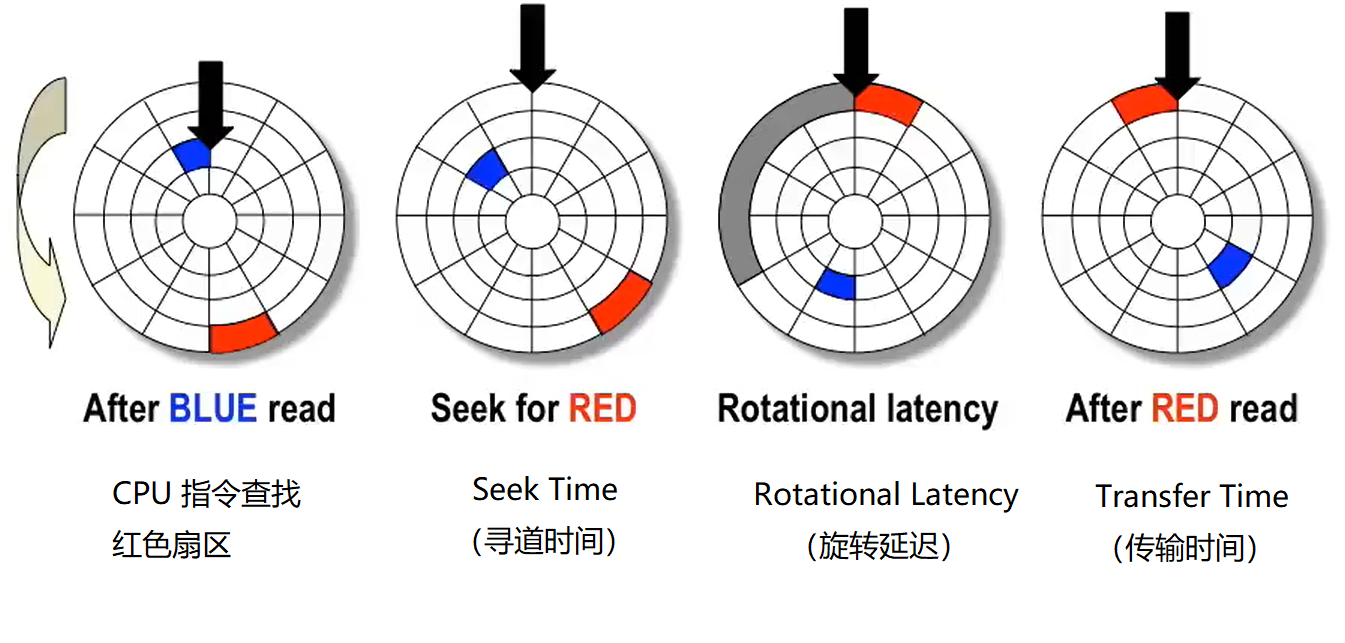
关于数据访问的耗时,有一些数字可以了解一下:
一般情况下机械硬盘的 寻道时间 > 旋转延迟 ≈ 4 ms >> 传输时间;
机械硬盘访问扇区的第一个 bit 耗时最多,其他几乎不耗时;
SRAM 访问 8 bytes 数据平均需要 4 ns,DRAM 需要 60 ns,而机械磁盘比 SRAM 慢 40000 倍,比 DRAM 慢 2500 倍;
硬盘(机械 / SSD)的逻辑块(Logical Disk Blocks):现代硬盘提供了一个面向 CPU 的更简单的抽象。硬盘的可用扇区被抽象为一组 b-sized 的逻辑块(编号从 0 开始);
每个逻辑块是扇区大小的整数倍(跳过 gaps),最简单的情况下,一个逻辑块就是一个扇区;
磁盘控制器来保持从物理扇区到逻辑块之间的映射(间接层面、抽象层面);
这允许磁盘控制器保留一部分 柱面(前面提到的存储信息按照同心磁道组成的柱面) 不进行映射,作为 备用柱面。
当某一柱面上的一个扇区损坏,那么磁盘控制器可以直接将数据复制到备用柱面,然后磁盘就能继续正常工作。
这就是为什么磁盘的 “格式容量”(formatted capacity)比实际容量小。
固态硬盘
固态硬盘作为一种更新的、用来代替机械磁盘的外存形式,其控制器接口和机械磁盘一样,所以 CPU 一视同仁,不过它的速度介于 DRAM 和 机械硬盘之间。
其内部全部由闪存构建,并且由一个固件(firmware)称为闪存翻译层(flash translation layer)充当控制器(其作用和机械硬盘的磁盘控制器相当);
数据在 SSD 中是以 页(page) 为单位从闪存中读取和写入的。页的大小 512 KB ~ 4 KB,块(block,和之前提到的 CPU 所认为的逻辑块不同,下面解释)一般包含 32 ~ 128 页,取决于 SSD 实现的技术;
这里所说的 “块” 为啥和之前的 “逻辑块” 不同?
首先明确,这是个术语重叠的现象。这里的 SSD 中的 “块” 是闪存的性质导致的。目前技术下闪存的数据擦除是成块成块擦除,这意味着一次会同时擦除多个页。因此,人们把闪存一次擦除的一组页集合称为 “块”。
因此,想要修改某个块中的某个页,需要 将该块全部擦除(之前应该复制到其他位置) / 找到一个已被擦除的块 才能写入;
现代的闪存翻译层中实现了很多专有算法,能够延长 SSD 的使用寿命,例如缓存技术。
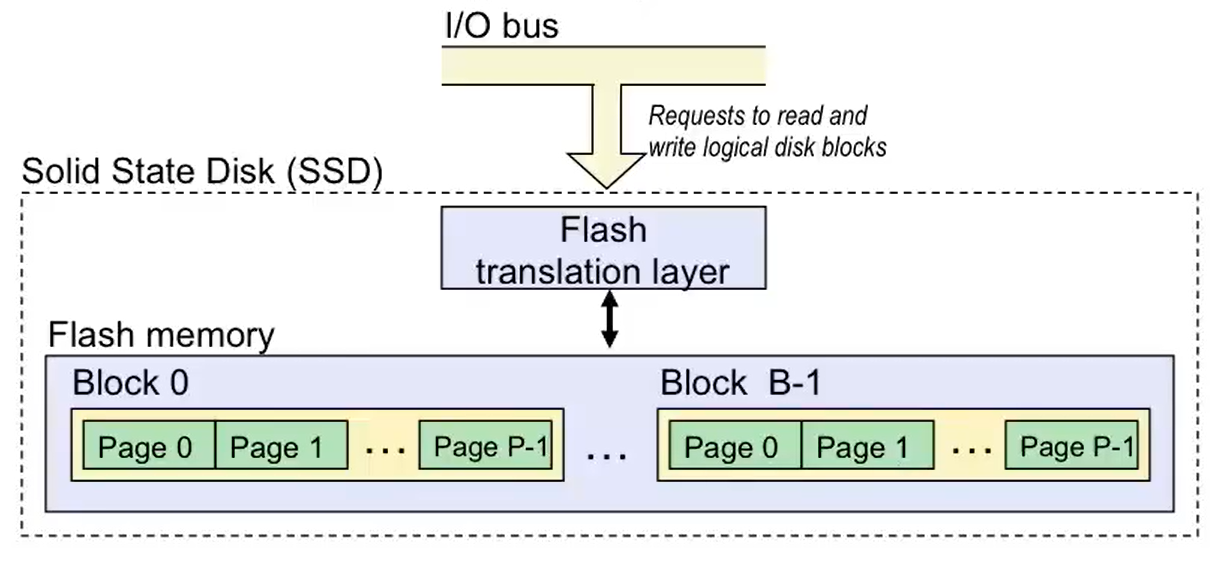
固态硬盘的读写效率大致是 随机访问 300 MB/s 左右,顺序访问 500 MB/s 左右(Intel SSD 730 的数据),可以说在计算机的存储系统的层次结构中,随机访问总是比顺序访问更耗时。其中 SSD 写入速度都略低于读取速度,这是因为闪存写入前需要擦除原先数据。总的来说,SSD 的访问速度大约比机械硬盘快 10 倍左右。
其实,SSD 和机械硬盘各有优劣,相较于机械硬盘,SSD 具有以下特征:
(优势)没有机械移动,更快、耗能更低、更结实(较不易摔坏),适合用在便携设备中;
(劣势)可能磨损,但问题不大,一般生命周期中可以写 100 PB+ 的数据(足够用多年);
最后看一下各种存储介质和 CPU 时钟频率的关系:
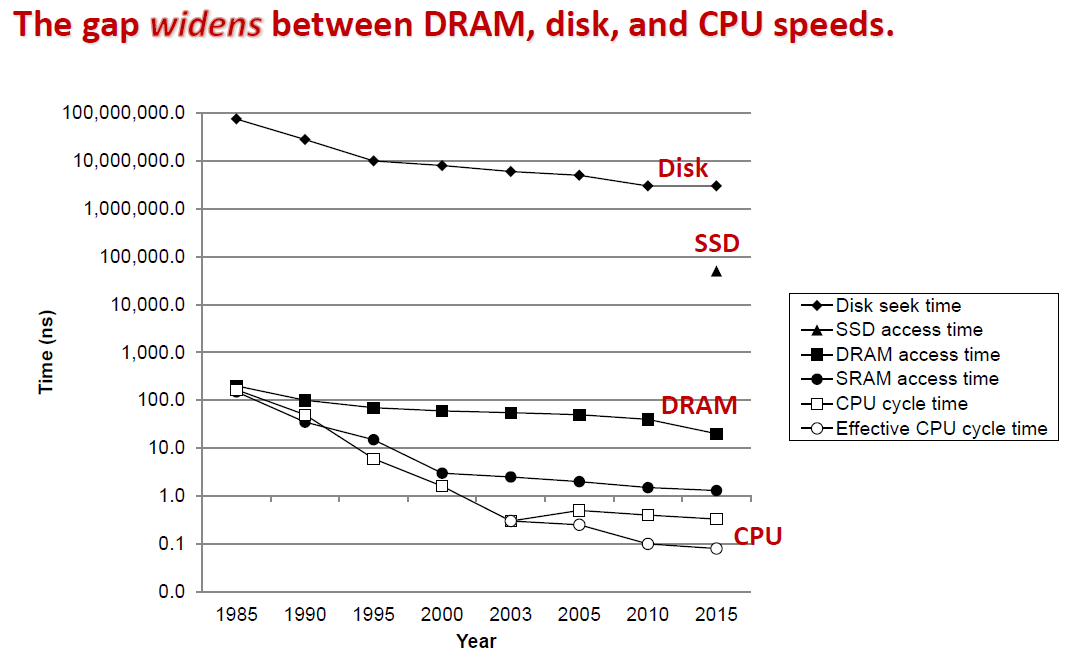
2003 年,CPU 设计达到性能能源瓶颈,其发展从增大时钟频率转向增大 CPU 内核数。
10.1.3 Traditional Bus Structure Connecting CPU and Memory
说完计算机存储系统的硬件,那么它们是怎么与 CPU 建立连接,进而抽象出 “内存空间” 和 “存储空间” 的呢?
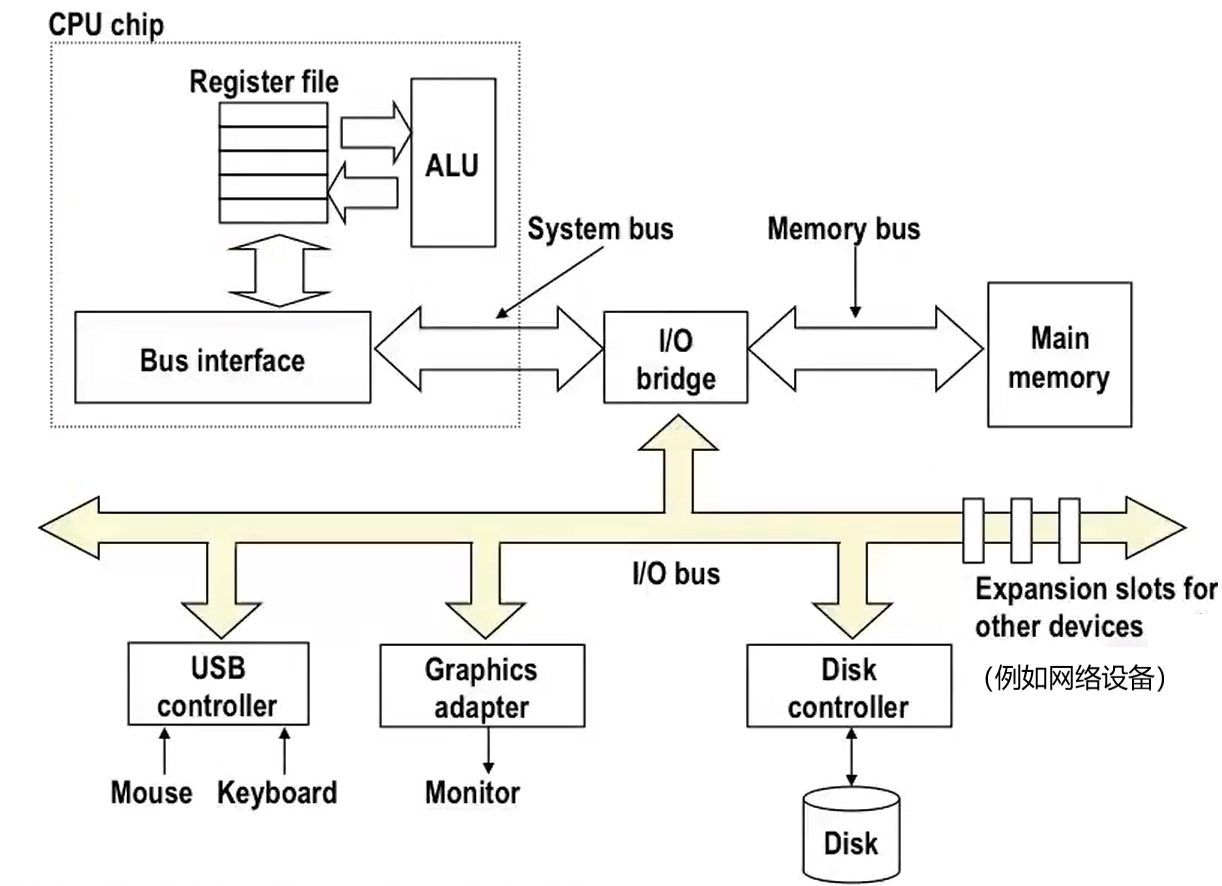
其中 I/O 桥是另外的一些芯片组,另一些芯片的集合。
CPU 访问主存
上面的图仅仅是比较简单粗略的抽象,不要较真。在比较老的计算机架构中(因为现代系统有专有的总线设计,非常复杂),采用 总线(bus)来连接 CPU 和主存的,数据通过总线在主存和 CPU 间来回传输。并且总线通常与其他多种设备共享。
正常情况下,CPU 中的 ALU 根据汇编机器指令只需访问最近的寄存器就行;如果指令要求它访问内存,那么 ALU 会交由总线接口(Bus Interface)去从主存中取出相应位置的数据。
大家可以思考一下,在上面这幅图中,movq %rax, $A (A 为内存地址)和 movq $A, %rax 应该如何形象表示?
大家不难发现,寄存器离 CPU 很近,所以访问速度很快,通常在 3 个时钟周期左右就能读写到值。但是内存(图中 Memory Devices 芯片组)离 CPU 相当远,中间的步骤相当多,所以对内存读写所消耗的时间大约是对寄存器读写耗时的 100 倍左右。这就是计算机内存系统引入所发现的其中一个性能损耗。
CPU 访问外部设备(以外存: 磁盘为例)
再来看 I/O 总线(I/O Bus),它将各个设备与 I/O 桥连接,使得外部设备能和主存一样被 CPU 访问。I/O Bus 看起来是一条线,可实际不是如此。因为在老式的计算机中,它被称为 PCI 总线(广播总线),主干连接到各个设备,任何设备只要更改其上的数据,其他设备就能发现。
但现代的 I/O 总线并不是一条线了,它采用了 PCI Express 的总线结构,并不像上面画的一样,它是 点对点地连接两个设备,实现不同(我们不会深入讨论),但提供的功能就像图上画的一样。所以可以把 I/O Bus 看作一组电子线路即可。
其中 Disk、Mouse、Keyboard、Monitor 等设备使用细双箭头,表示它们不是焊在主板上,而是插入主板上的控制器(adapter、controller)来连接。
考虑如果 CPU 想要访问某个磁盘设备的某个扇区,那么会进行如下步骤:
CPU 生成一个三元组(triple):指令(read / write)、逻辑块编号、该块中的数据要放到哪个内存地址中(CPU 先从磁盘读入内存,再从内存读入 CPU 寄存器,反方向亦然),并且当前线程的程序暂停执行(如果是 I/O 阻塞的话),等待数据传输;
三元组通过总线接口、I / O 桥、I / O 总线传给磁盘控制器;
磁盘控制器通过读取与该逻辑块对应的任何扇区(一个逻辑块可能包含很多扇区)读入磁盘缓存;
磁盘控制器取得总线控制权,并且将数据通过 I/O 总线、I/O 桥和内存总线直接送往指定内存地址,而无需将数据传给 CPU;
数据传输结束后,磁盘控制器借助 “I/O 总线 - I/O 桥” 从新的通路(不经过总线接口)直接用电信号触发 CPU 的某个引脚,这个信号代表一种中断(interrupt),通知 CPU 该扇区已被复制,此时暂停的程序继续执行;
10.2 Locality
无论是 8.1.2 中介绍的各自存储介质在物理层面上的性能约束,还是 8.1.3 中介绍的数据读取流程上的性能限制,都是计算机存储系统需要解决的重要问题,否则,在硬件上计算机就难以继续提升运行速度了。
其实,弥补 CPU 和内外存读写速率之间差距的机制之一就是程序的基本属性之一:局部性(locality)。
局部性原则:程序倾向于使用 “内存地址接近或等于最近使用过的数据/指令地址的” 那些数据和指令。
原文:Programs tend to use data and instructions with addresses near or equal to those they have used recently.
这个原则来源于程序编写的逻辑——当程序访问到某个内存地址上的数据,那么在不久的将来,有很大的可能程序会访问该数据项或者附近的数据项。
这种局部性有两种表现形式:
时间局部性(Temporal Locality):最近引用的存储器位置可能在不久的将来再次被引用;
空间局部性(Spatial Locality):如果访问了一个存储器的位置,那么有很大可能在将来会访问一个临近的位置;
例子:识别代码中的局部性
sum = 0;for (int i = 0; i < n; ++i)sum += a[i];return sum;这串代码中,有对数据的引用(Data references,转为汇编后会引用数据,通常只要有变量就有数据的引用)。
例如上面的数组
a,其元素在内存上连续,索引 i 每自增一个单位就访问一下(称为 stride-1 reference pattern),属于空间局部性;上面的变量sum在循环的每次迭代中都会被引用,属于时间局部性;还有对指令的引用(Instruction references),例如循环中每一次都会执行循环体的内容,属于时间局部性;再比如程序代码顺序执行,本身就属于空间局部性。
不同编写方法的代码,其局部性不同。这就需要开发者训练观看的能力。举一个很简单的例子:
xint sum_array1(int a[M][N]) { int i, j, sum = 0; for (i = 0; i < M; i++) for (j = 0; j < N; j++) sum += a[i][j]; return sum;}
int sum_array2(int a[M][N]) { int i, j, sum = 0; for (j = 0; j < N; j++) for (i = 0; i < M; i++) sum += a[i][j]; return sum;}我们考虑对数据的引用,回忆 6.1 中对于 Nested Array 的内存排列的知识,数组数据连续排列且行优先,所以我们发现,使用 sum_array2 方式遍历数组,其数据相距距离很远,这意味着程序的局部性差于 sum_array1。而事实上,sum_array2 也真的会比 sum_array1 慢一个数量级;
例题:请修改以下代码,使得它满足 stride-1 reference pattern(即更优的程序局部性)
xxxxxxxxxxint sum_array_3d(int a[M][N][N]) {int i, j, k, sum = 0;for (i = 0; i < M; i++)for (j = 0; j < N; j++)for (k = 0; k < N; k++)sum += a[k][i][j];return sum;}
10.3 Conclusions for 10.1 & 10.2
没错,前面两节全部在为存储系统的层次结构做准备,之后我们才开始正式讨论 Memory Hierarchy。在此之前,我们先小总结一下前面的内容。
在本章开始,我们认识了计算机存储系统在硬件层面的两大组成:主存和外存。主存由 RAM(又分为 SRAM 和 DRAM)组成;外存则是硬盘(又分为机械硬盘、SSD)、可移动磁盘为主。
广义的内存包括:主存(RAM)、全部 ROM、Cache(高速缓存存储器);
我们紧接着比较了 SRAM 和 DRAM 的特征、异同,以及它们所使用的场合;对于 ROM,我们了解了不同的 ROM 类型,还有闪存的定义。
在外存方面,我们详细介绍了机械磁盘的物理结构(磁盘控制器、盘面、柱面、磁道、扇区、记录区、承载量计算、访问耗时分析、逻辑块),并类比出功能相同、实现不同的固态硬盘物理结构(闪存翻译层、页、块)。
于是,我们从上面存储介质的物理结构中分析并得出 其数据访问模式的性能限制和优劣。
最后,我们分析了 CPU 访问主存 和 CPU 访问外存 的情况和流程,从中我们得知了在内存读取的流程中也存在着性能的限制或者说损失。
基于这些物理结构的限制,我们讨论出代码结构层面能够在一定程度上弥补这些性能鸿沟的性质:局部性。我们根据 存储设备的物理结构 和 数据存放的方式,可以设计写出更符合程序局部性的代码,这在一定程度上可以缓解 CPU 和内存之间访问的性能差距。
而观察代码的局部性,就需要对数据在内存中的 layout,还有储存设备的工作原理有一个很好的认识,这就是前几章、前几节的内容。
这些存储介质的物理特性,和程序的局部性相辅相成,相得益彰,为人们提供一种 “怎样设计存储系统” 的建议和信息。
接下来,我们将基于这些存储介质的物理性质,讨论在其上所建立的层次结构,和这些层次结构是如何抽象硬件,尽可能地为上层的计算机软件提供更连续完整的资源的。
10.4 Memory Hierarchy & Idea of Caching
下图是计算机存储系统的一个层次结构图。
其中,寄存器是访问速度最快的存储结构,它在每个 CPU 时钟周期内都可以直接访问到(大小最小、数量很少、价格最贵、速度最快);
接下来的是由 SRAM 组成的高速缓存存储器(Cache Memory),也处于 CPU 芯片内部,既不是主存,也不是寄存器;大小虽然是 MB 级,但已经比寄存器大多了。其中 3 层 Cache Memory 的具体结构将在下一章进行深入讨论;
再向下是 DRAM 组成的计算机的主存,一般你能看到的 “内存条” 就是它的组合结构,也是普通人经常说的 “内存”(狭义内存),一般从几个 G 到 几十 G 不等,程序运行内存(或者说后面要提到的虚拟内存)就是它的一部分;
最底层的像本地硬盘结构,甚至云端存储结构,空间一般都很大,但访问效率低下。
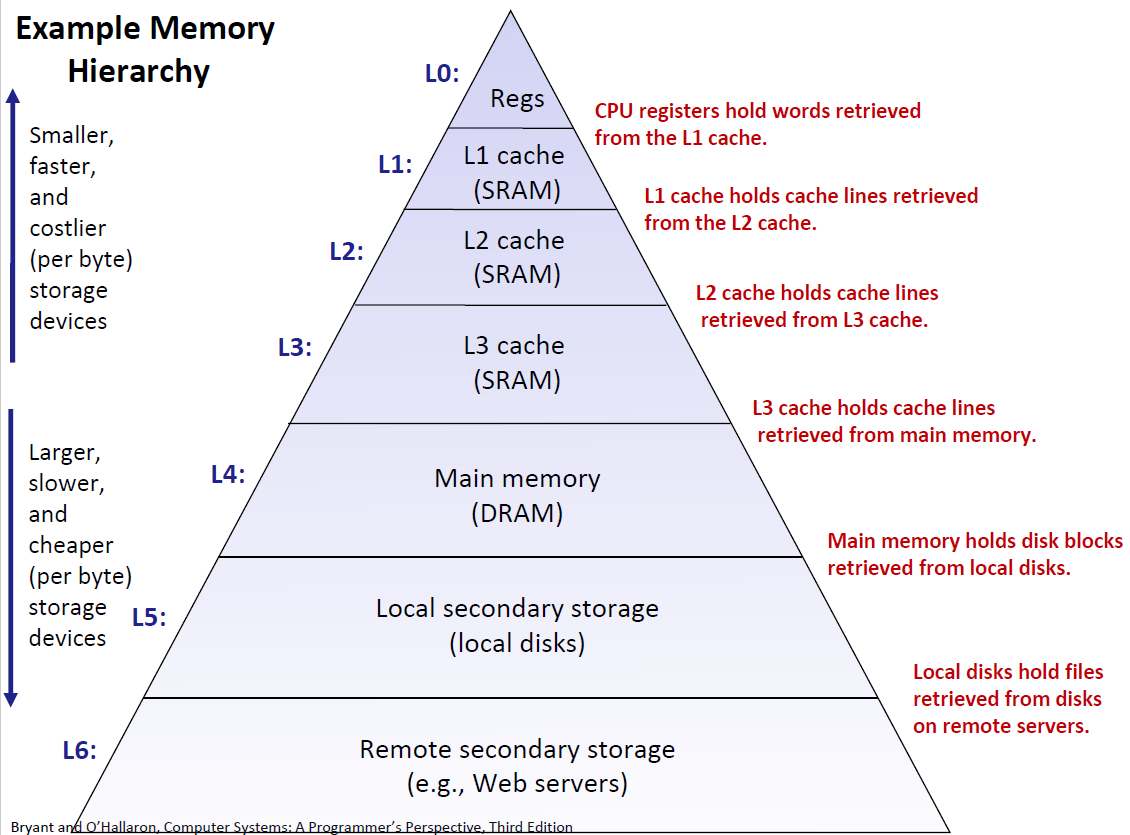
设计的核心:在 Memory Hierarchy 中,每一层都包含着从下一层所检索的数据(例如 CPU 寄存器保存着从 L1 高速缓存中取出的数据,依此类推);
这样设计的原因是为了充分利用各个层级资源的特征,将整体数据访问效率最大化(底层是极大的数据池,却能够以极快的速度进行访问)。
这么做之所以有效,是因为 缓存思想(Caching)的存在。
这里所说的缓存,不是高速缓存存储器(Cache memories),而是一种思想。作为一个更小、更快的存储设备,充当更慢设备中数据的暂存区域、能更快访问的数据子集。例如,主存 可以看成是本地硬盘的 缓存,这样一旦从磁盘获取数据,就无需在磁盘上访问它,在上一个层级内存中访问,速度得到提升。依此类推,缓存的思想在 Memory Hierarchy 中逐级传播。
第 k 层更快、更小的存储设备,就是第 k+1 层更慢、更大存储设备的 缓存。
在真实场景中,每当程序访问一个不在缓存设备(第 k 层)中的数据,都会从第 k+1 层检索,并复制到第 k 层缓存起来。这是因为,根据程序的局部性,相较于第 k+1 层的设备,会更经常访问第 k 层设备中的数据,这就是 Memory Hierarchy 能最大化数据访问效率的原因。
在详细介绍高速缓存存储器(狭义的 Cache)前,我们简单介绍一下缓存的实现,因为缓存思想存在于存储层次结构的每一层。
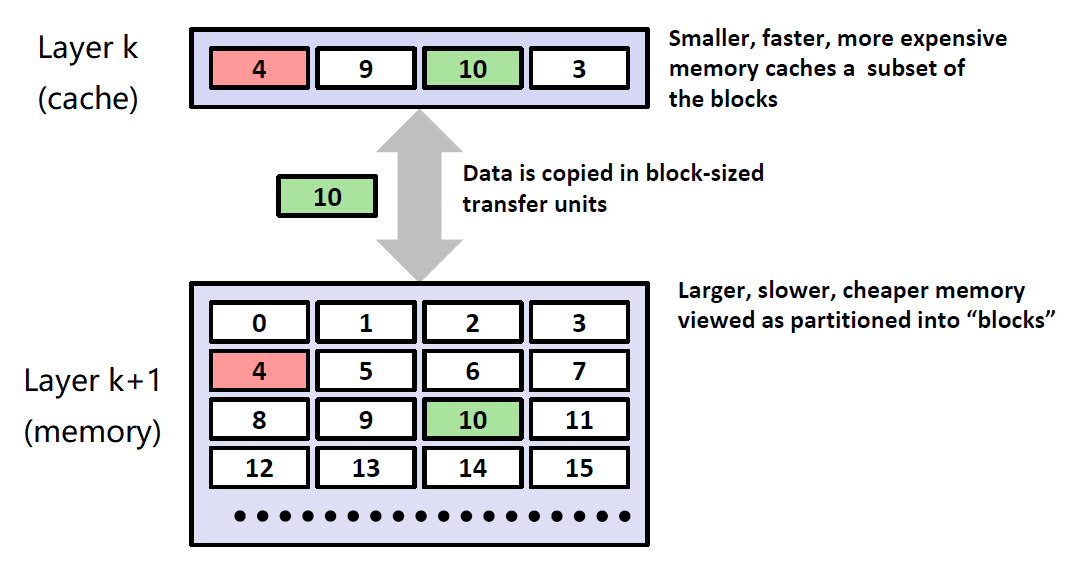
储存数据的下层设备的空间(k+1 层)通常被分为一个个固定大小的块(blocks),缓存设备和下层设备间传输的数据以块为单位进行。
如果第 k+1 层是 Web 云端存储介质,那么 blocks 通常以文件形式传给磁盘(第 k 层,缓存设备);
如果第 k+1 层是主存,那么 blocks 可能是以某个特定大小的数据块传给高速缓存存储器(第 k 层,缓存设备);
……
在任意时间点,第 k 层的缓存设备中的数据都是第 k+1 层设备数据的一个子集。
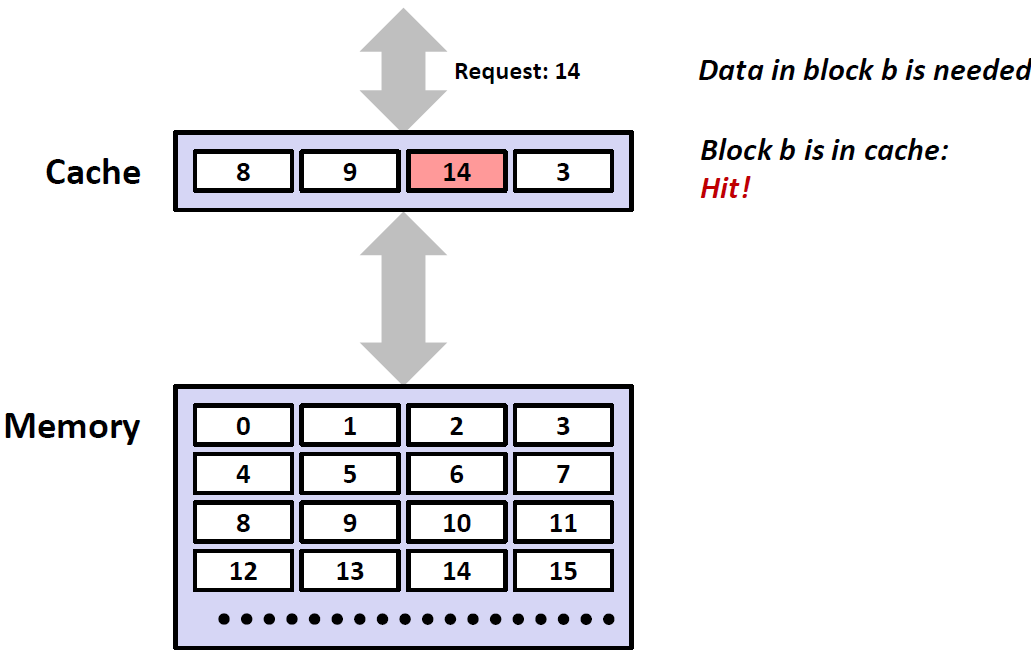
对于 CPU 请求一个位于第 k+1 层的某个位置的数据这种情况,则 CPU 会先去层级最高的设备中寻找(假设找到第 k 层),则有两种情况:
如果恰好找到了(假设请求如下图绿色块 14 的数据),那么 CPU 就直接从缓存(第 k 层)中读走这个数据,无需向下请求数据,总体提升了效率。这种情况称为 Cache Hit(缓存命中);
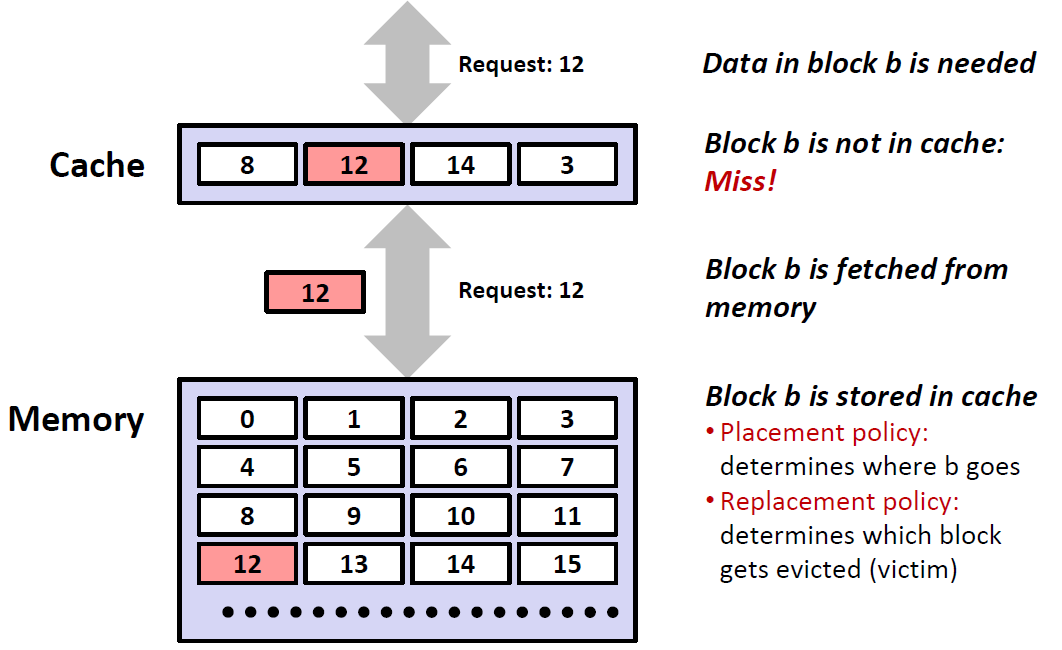
如果没有找到,那么 CPU 就需要从更下一层取得此数据块,并将它存放在缓存设备中。这种情况称为 Cache Miss(缓存不命中);其本身又分为 3 个类型:
Cold(compulsory)Miss:缓存为空,所以 Miss,不可避免;
Capacity Miss:由于较小的缓存空间而导致的不命中,通常是因为程序的工作集大于缓存空间所致。可以由增大缓存空间而减少;
工作集(working set):当前不断被程序访问的块,也即活跃的缓存块(active cache block);
Conflict Miss:由于大部分缓存设备(尤其硬件缓存)必须设计的比较简单,它限制了缓存块的放置位置(例如第 i 块必须放在
i mod sizeof(Cache)的位置,很类似 hash table 的碰撞),这与缓存实现方式有关,也在下一章进一步讨论;
最后,我们总结一下缓存在存储系统各层级的实现情况:
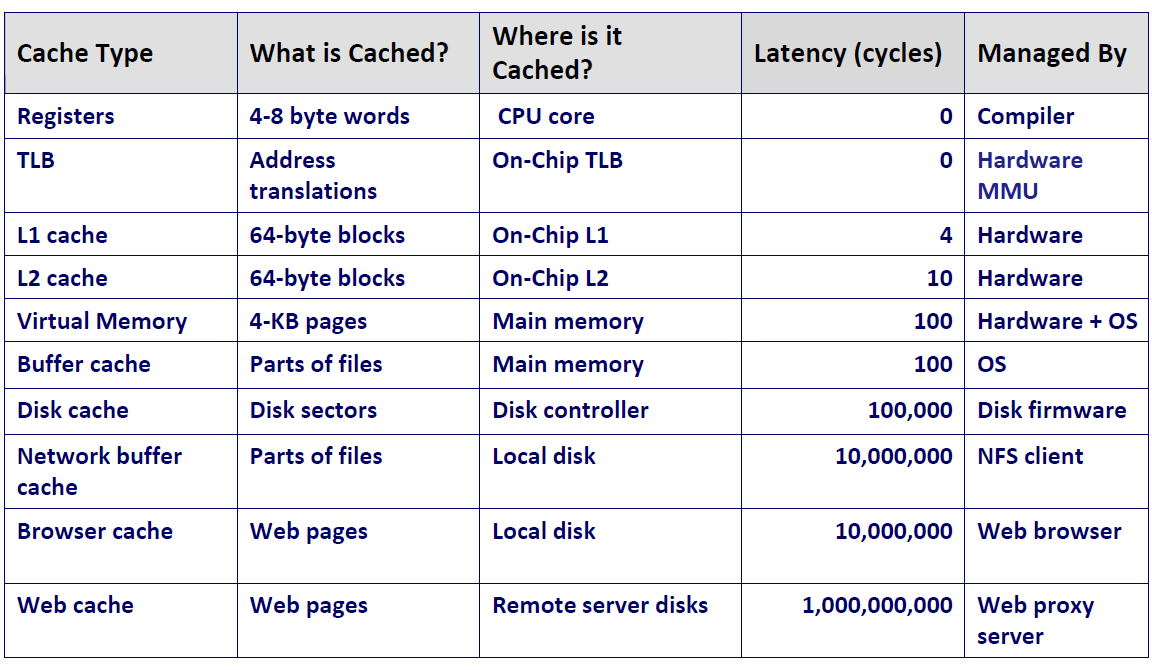
注:TLB(Translation Lookaside Buffer,后备缓冲)是一个在虚拟内存中使用的缓存,是虚拟地址翻译为物理地址的翻译过程的缓存;
需要注意的是,各个层级的缓存究竟是由谁实现和管理的,这是缓存思想的一个重点,也能解释早在第 3 章的疑问——汇编代码中找不到管理高速缓存存储器的代码 的原因。
例如,当寄存器看作缓存设备时,是编译器决定用哪个寄存器、用多少个寄存器(怎么用的 conventions 是 ABI 决定的);
综上,缓存思想存在于计算机系统的几乎每个用到数据 I/O 的地方。
下一章将讨论 Memory Hierarchy 中一个具体的部分 高速缓存存储器,来深入了解缓存思想。
Chapter 11. Cache Memories
本章讲述 Memory Hierarchy 缓存思想中的重要一个体现:高速缓存存储器(Cache memories),它介于寄存器和内存之间,充当缓存设备的角色。
回忆上一章的内容,高速缓存器本质上是一种由 SRAM 组成的、由硬件直接管理的小型缓存存储设备:Cache memories are small, fast SRAM-based memories managed automatically in hardware.
它一般封装于 CPU 芯片中,几乎和寄存器距离 CPU 核心同样近(只是由于电路存取特性导致其慢于寄存器),存储主存中被频繁引用的数据块。
11.1 General Cache Organization
那么硬件是如何管理高速缓存存储器中的数据,在 CPU 需要的时候进行寻找呢?我们首先需要借鉴层次架构中一般的缓存模型,它们共同有一种缓存的管理方式和 layout;
首先,缓存本身就需要极速,这意味着设计缓存机制必须以非常严格且简单的方式去组织缓存模型,便于各个设备层级间进行查找。于是人们设计了下面的缓存数据组织形式:
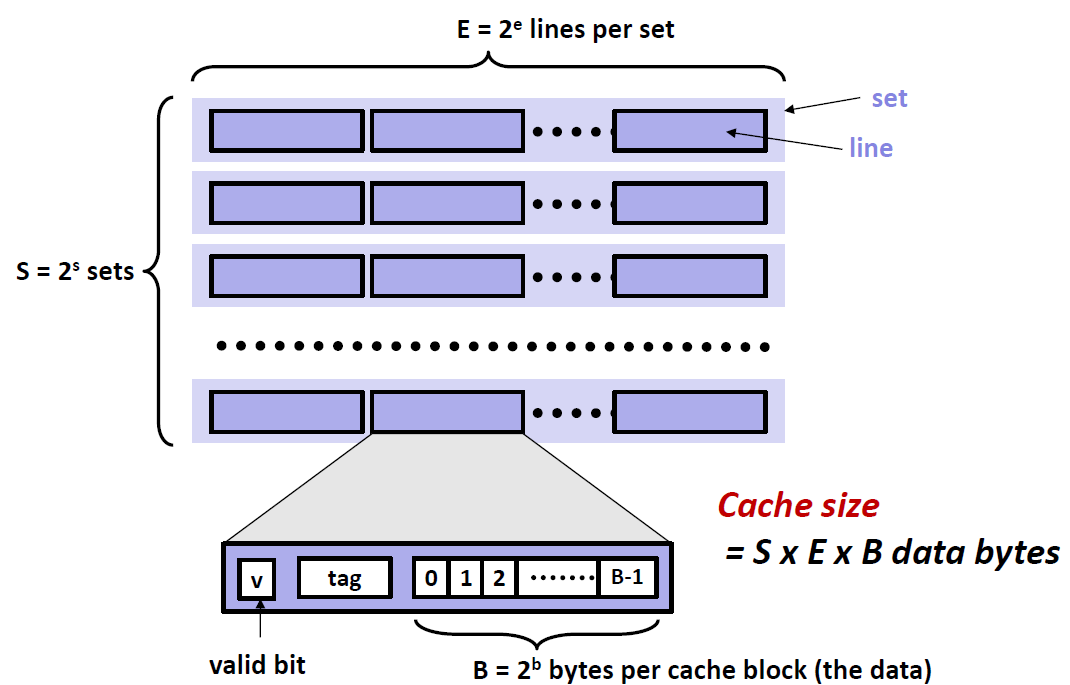
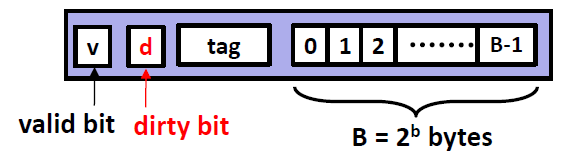
缓存空间中一般包含
valid bit 指示当前缓存数据行中的数据实际上也真实存在于下层的存储介质中,可以直接使用(例如第一次打开机器的时候,这些数据区块位置上是随机 bits,因此这些 valid bit 会提示数据区块无效);
tag 位(标记位)编码了这串数据位于下层存储介质的位置,在 CPU 搜索时有用;
为何无论是组数、数据行数还是每个数据行中的字节数都是 2 的幂次呢?这是一个非常重要的点。因为,缓存空间按照 内存地址的数码的各个位 来直接对应该内存数据应该存放的位置。这个比较抽象,后面的例子就会慢慢理解。
其中高速缓存块的大小 不包含 Tag 和 valid 部分,也就是说,高速缓存的大小
11.2 Read Cache
那么缓存是如何被读取的?详细数据结构(和具体存储设备有关)又是什么样子的?
实际上,程序在运行中可能请求了下层存储介质中某个位置的数据,我们以高速缓存存储器和主存间查找数据的关系为例。步骤如下:
假设程序指令要求引用主存中虚拟内存的某个地址(设为
X)的数据,那么 CPU 会向高速缓存存储器请求X地址下的值;这个请求的地址会被 高速缓存存储器 直接用来查找缓存存放的位置(即这个地址的数据存放在)。其中
X会被 高速缓存存储器 解析成如下图所示的结构(这就是为什么上面的S、E、B都是 2 的幂。看着这张图你能想明白吗?还不能明白的话,后面会有更具体的例子):
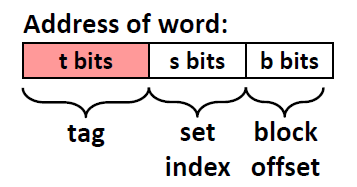
高速缓存存储器 首先 extract
X中 s bits 的set index(缓存组索引)看作为 unsigned int,用它找到缓存空间中特定的组(和数组索引很像);高速缓存存储器 接着并行检查(依赖于硬件电路的检查机制)该组中所有的数据行,将 tag 字段与每个数据行中的 tag 进行比较。如果找到了相同的 tag,那么再检查 valid bit 是否指示有效。所以会出现以下情况:
情况一:该组的数据行中不存在 tag 与
X一致的行,说明请求的数据块不在缓存中(Cache miss);情况二:该组的数据行找到了 tag 与
X一致的行,但 valid bit 指示无效,说明请求的数据块无效,当前也不在缓存中(Cache miss);情况三:该组的数据行找到了 tag 与
X一致的行,并且 valid bit 指示有效,Cache hit!
如果是 cache hit,那么extract
X中 b bits 的block offset,从该数据行的数据区块开头地址加上这个 offset,将得到的地址再数据行中剩余部分规定大小读出,直接传给 CPU,结束查找过程;如果是 cache miss,那么高速缓存存储器会放弃查找,将原本的请求地址
X传给下一级存储设备(主存),那么查找工作交给主存(重复上面类似的步骤)。注意,当主存找到数据向上提交时,再次给到高速缓存存储器,将数据放在高速缓存存储器的应该是X的位置缓存起来(通常会覆盖相同位置的其他数据),然后高速缓存存储器再将数据向上提交给 CPU;
总体呈现出 “逐层向上缓存数据,逐层向下查找数据” 的形式。
11.2.1 Direct-Mapped Cache Simulation
下面详细解释上面的步骤。为了便于理解,我们首先从简单的情况讨论,当每一个缓存组只包含一个数据行的情况,这种情况被称为 “直接映射”(Direct-Mapped Cache Simulation):
假设某个机器的内存空间大小 M = 16 bytes(可以用 4-bit digit 代表地址),缓存空间中含有 4 个组(S = 4),每个组含有一个数据行(E = 1),每个数据行含有 2 bytes 的数据区块(B = 2)。
在数据区块中,block offset 的长度为 1 byte(b = 1,因为数据区块只有 2 bytes,一般有
现在程序开始运行的时候,分别请求内存地址(
现在,高速缓存存储器中的所有数据行的 valid bit 都是 0(假设 0 代表无效,1 代表有效),并且开始接受 CPU 请求内存地址
首先,00,所以在 set 0(第 0 组)中寻找;然后,将 set 0 的 tag 比较(是随机数),再看 valid bit 是 0,所以 cache miss(cold miss),如下动画(本人不会 Acrobat Animate,比较粗糙):
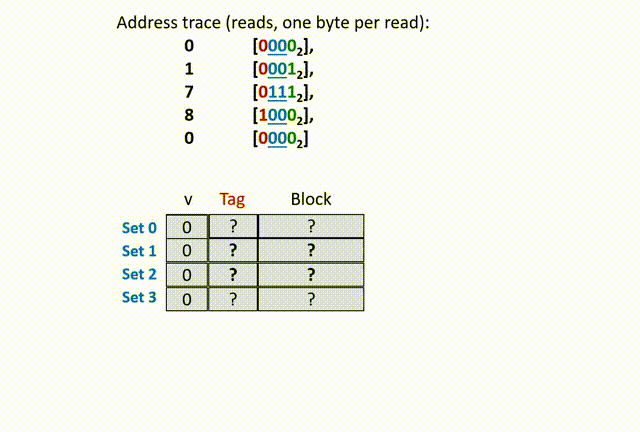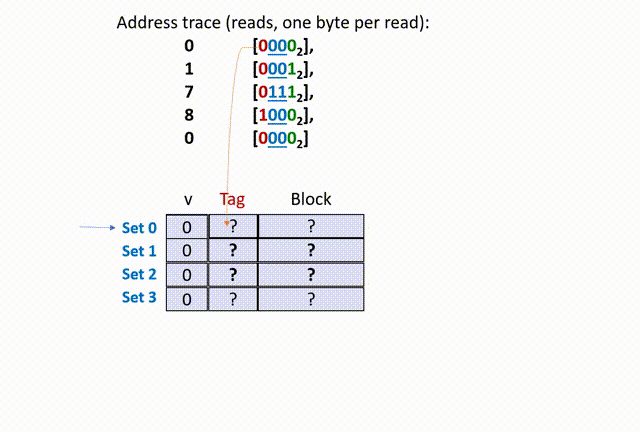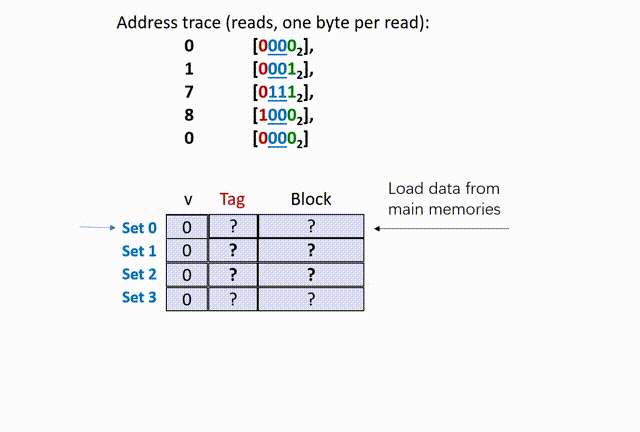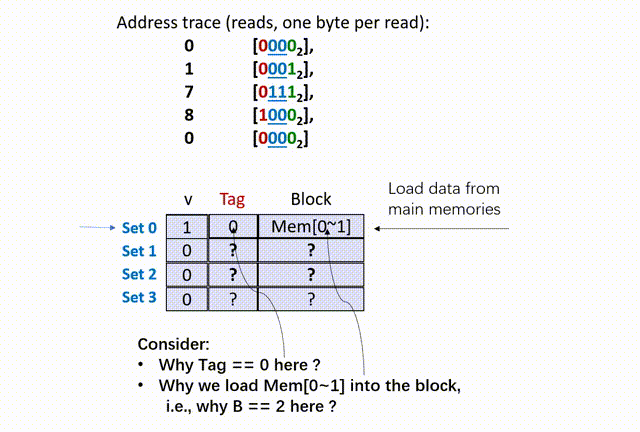
思考两个问题,第一个,为什这里的 tag 是 0 ?这是因为,我们在给定的 set offset 下(组相同),前面的 t bit(t=1)的 tag 位只是用来区分数据行的,借助了原内存地址 X 的前 t bits 数据而已,没有实际意义。
第二个,为什么这里要从 main memories 中同时读入 0、1 地址的数据?也就是说,为什么设定 B == 2 呢?这是因为,除去 set offset 的 2 bits、tag 的 1 bit,剩下内存地址 X 数码还有 1 bit 留给 block offset,因此 X 只能在该组的数据行中索引 2 bytes 的数据。
细细体会上面的话,你会发现这就是缓存空间如此设置、X 如此解析的原因(这里设计的和 IEEE 浮点数表示法一样巧妙,不容易用语言描述)。
好了,又有同学会好奇了,既然这些索引本身没有意义,只是借助了原地址的数码,那为什么设计缓存索引的人一定要 set index 在中间、tag 在最前面、block index 在最后面呢?
这个问题非常有水平,这和二进制数码的变化方式有关。我们这里就分析对比 2 种解释 X 地址的方式:
Middle Bits Indexing:就是上面的
X的结构,Tag 在前、Set index在中间、Block index在最后;High Bits Indexing:
Set index在前、Tag 在中间、Block index在最后;
我们接下来将缓存空间的组标为不同颜色,再把内存中将要分配到哪一组的数据块填上相同的颜色,发现结果如下:
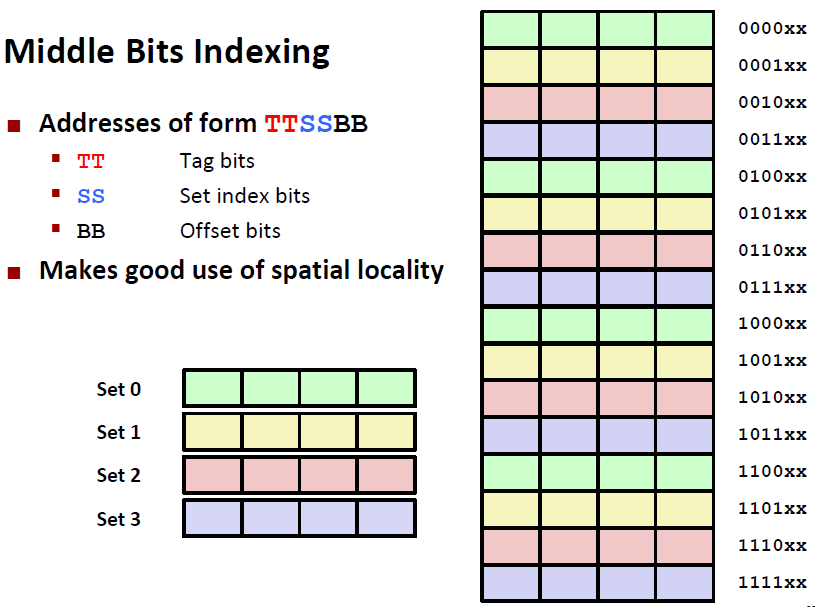
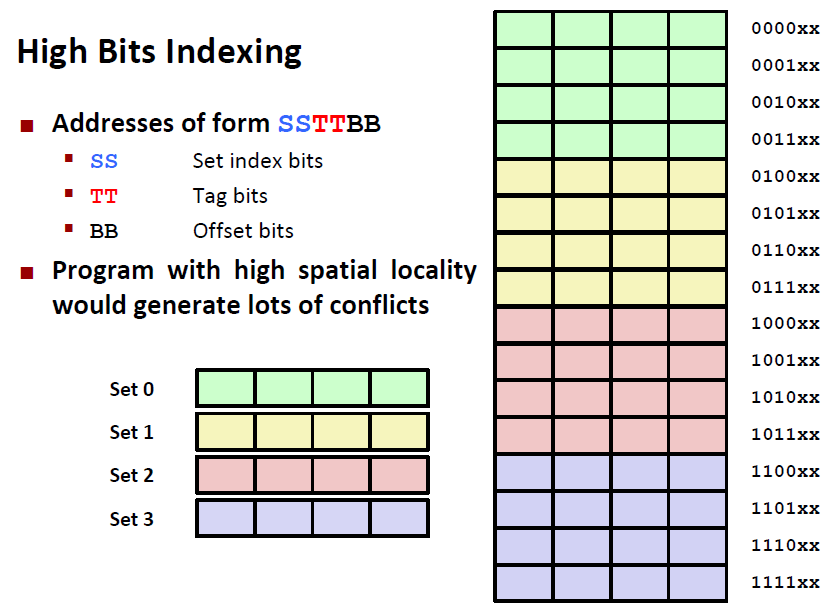
我们发现,如果用 high bits indexing,那么内存地址相近的内存区域很容易被分配到相同的缓存组中,根据空间局部性,这样做会导致发生 conflict miss 的概率大大增加。所以,在缓存效率上,middle bits indexing 是优于 high bits indexing 的。其他情况同理。
这就是设计者们为什么要如此设计内存地址 X 在缓存中的这种解析方法。
继续看接下来的过程动画:
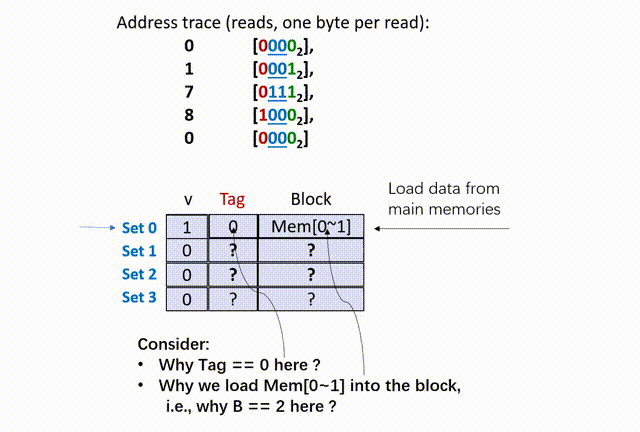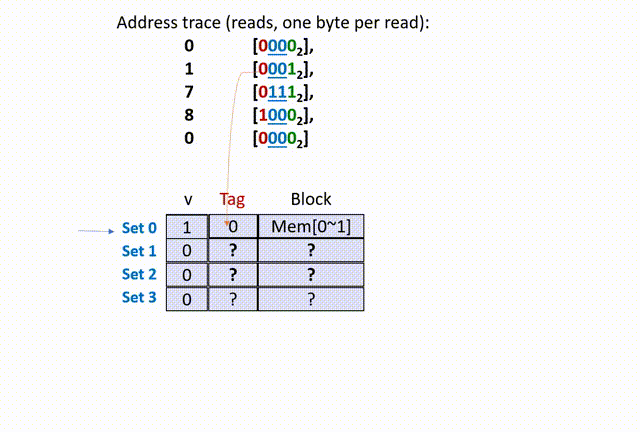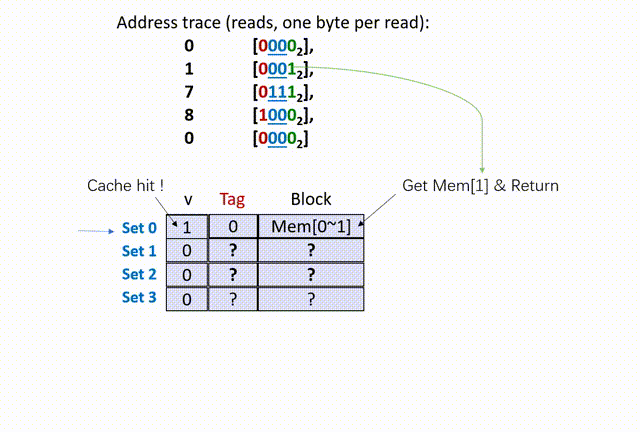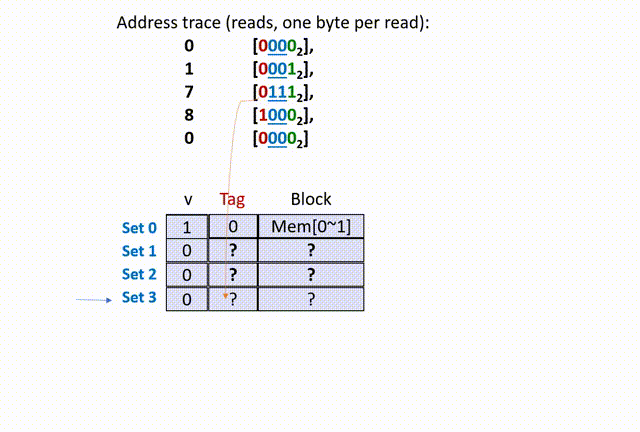
我们发现,5 次访问中,有高达 4 次的 cache miss。后面 2 次的 cache miss 都是 conflict miss,完全能够由 提高每组的数据行数(E 的大小)来避免。因此,缓存结构中 E 的大小越大越好(也就是每组中的数据行越多越好)。但是我们前面提到,一个组中各个数据行使用并行比较,这个操作依赖硬件的多路判断——也就是说,E 越大,硬件电路越复杂,硬件越贵。所以真实计算机硬件中会进行取舍,选择一个特定的 E 值。
当代(21 世纪初)市面上的常见的单组中数据行数目取值
E = 8,最大有E = 16,是 Intel 的 16 路相联 L3 三级缓存。
事实上,B(数据区块的大小,block size)也是越大越好,因为越大越可以利用局部性,提升缓存命中概率。但 B 受限于两个因素:一是硬件成本(例如 Cache memories 由 昂贵的 SRAM 组成),二是块复制的时间代价,因为如果想要把很大的数据区块从内存挪至缓存中,也是一个不小的开销。
综合上面的考虑,设计者真正确定缓存空间各个参数的步骤如下:
确定合适的数据区块(就是在数据行中的那个字段)大小
B(通常被称为固定的缓存高级设计参数。Intel 一般 64 bytes);根据实际应用场景和硬件成本情况确定大致的缓存空间总大小(也是固定的缓存高级设计参数之一);
根据硬件和实际情况确定数据组的关联性(associativity,即一个数据组中有多少数据行)
E;由 1、2、3 就能计算出大致的缓存数据组数(
S)。
最极端的情况是 全相关联高速缓存(Fully Associative Caches),缓存空间中只有一个组(
S = 1,所有数据行在一个组中),这个时候如果能够并行比较,那么缓存效率是极高的。但是通常由于上述原因,我们大多数时候只能在软件级别的缓存 或者 在主存和硬盘之间的缓存模式(因为硬盘读取时间开销很大,值得我们使用复杂算法来获得更高的缓存效率,我们在“虚拟内存”一章会讨论)中找到这种组织形式。
11.2.2 E-Way Set Associative Cache Simulation
除了直接映射,还有一个稍微复杂点的例子,当不改变上面例子中的缓存空间大小,讨论每个缓存组包含 2 个数据行的情况,这也被称为 “2-Way Set Associative Cache(2 路相连高速缓存)Simulation”。
这个时候 tag 变为 2-bit,set index 变为 1-bit,block index 还是 1-bit;
我们有类似上面 Directed-Mapped Cache Simulation 相近的步骤,如下图:

注意到一点,当关联性大于 1 的时候,同一个数据组中可能不同的数据行的 tag 可能是相同的,那么当我们想要覆盖数据的时候,就涉及到了选择覆盖的问题,它可以通过设计算法来完成。
根据局部性原理的逆定理(通常成立),如果一个数据长时间不被引用,那么它在未来的某个时间也不太可能被引用。所以,最常见的算法是 “最近最少使用” 策略(Least Recently Used Strategy),这种算法一般不需要额外的 bit 存储数据,只是从硬件层面跟踪在缓存中数据的使用频率(如按序保存虚拟时间戳),确保无效的数据行最先被覆盖,然后是使用频次更低的数据先被覆盖。
助记:
b位不同,s,t位相同,也位于同一个组中;每
11.3 Write Cache
事实上,真正要更改某些数据恐怕比读数据更难,因为我们的缓存机制通常会产生多份数据的复制品。例如层级从低到高:硬盘、主存、L1 / L2 / L3 高速缓存,其中可能包含了同一份数据的副本。
于是在程序要求修改内存(仍然以 高速缓存存储器 和 内存 这对存储同样有 2 种情况 write-hit 和 write-miss:
如果遇到 write-hit(要写的内存数据就在缓存设备中)的情况,由于数据分布特殊性,那么有两种处理方法:
Write-through:立即将数据写入缓存(即覆盖当前行)并主动刷新(flush)到内存;
优势:内存始终是缓存的镜像,二者数据同步;
劣势:从 CPU 到 内存,时间开销必然很大;
Write-back:先把数据写入缓存,但不立即刷新,直到下一个数据要覆盖这个数据行的时候,才更新到内存中(defer write to memory until replacement of line,只是尽可能推迟了写入内存的时间);
优点:如果数据的 dirty bit 指示没有被污染时,那么覆盖这一行就不用执行 write 操作;
特点:这种方法需要一个标记(dirty bit),用来指示当前数据和内存中是否相同,即是否有被修改过;
劣势:必然存在 write-miss 现象,因为如果修改的内存数据不在缓存中,那么就需要与内存交互;
如果遇到的是 write-miss,那么也有 2 种方法(和 write-hint 是对称的操作):
Write-allocate:写分配,在 write-miss 后,先将原数据从内存读入缓存,转换为 write-hit 的情况,再 write-back(仅修改缓存 + dirty bit);
No-write-allocate:直接写入内存,不加载到缓存(缓存中没有这个数据所在的数据行,因为本来就是 write-miss);
一般情况下,由于对称性,人们一般选择 “write-back + write-allocate” 或 “write-through + no-write-allocate” 的策略中的其中一对(根据实际情况);
11.4 The Hierarchy of Cache Memories
讨论完了缓存读写的具体的逻辑实现,我们再来看看实际上硬件是如何对应这些实现的。同样以 高速缓存存储器 为例。到目前为止,我们都假设计算机系统中只有一个高速缓存存储器的缓存空间,但是实际上,早在前面第 8 章中就介绍了,一般计算机中有 L1、L2、L3 3 类 Cache memories。它们在硬件上是如何设置和协调的呢?
以 Intel Core i7 芯片为例,它的高速缓存层次结构如下:
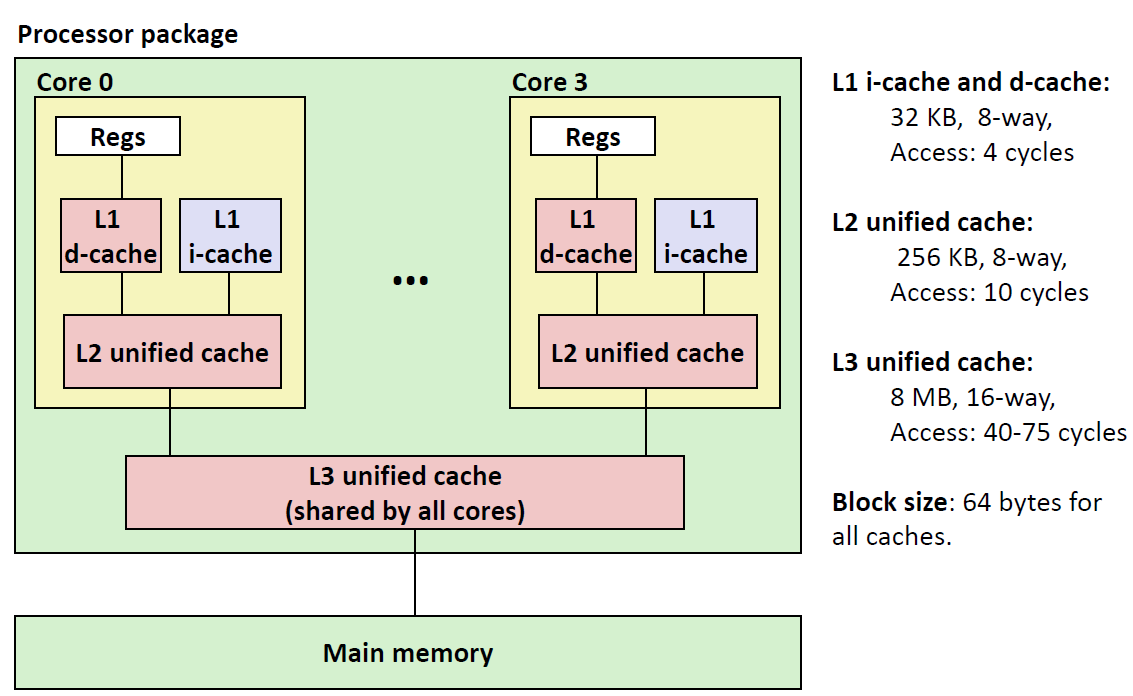
如图,一般情况下,现代 CPU 有 4(桌面系统)/ 8 ~ 12(服务器类系统)个核,每个核可以各自并行,独立执行各自的指令流,每个处理器内核可以包含各自的通用寄存器(位于存储系统层次结构 L0).
在其中,每个核还会有 2 种 L1 Cache。其中一种是 d-cache(data cache,1 级数据高速缓存器),另一种是 i-cache(instruction cache,1 级指令高速缓存器)。它们的读取时延(4 个时钟周期)仅次于寄存器,正因速度和成本的关系,它们的大小非常小,只有约 32 KB;它们的关联性一般是 8 路(一个缓存组中有 8 个数据行);
在 L1 Cache 的下一层是 L2 Cache(L1 和),只有一种联合的高速缓存器(unified cache,同时包含某个核的数据和指令的缓存),读取速度稍慢(10 个时钟周期)于 L1 Cache,也是 8 路关联性,不过大小稍微大一点,有 256 KB;
再下层的 L3 Cache 不在 CPU 的核内,是被所有核心所共享的联合高速缓存存储器。8 bytes 大小、16 路关联性,但访问时延长达 40 ~ 75 个时钟周期;
它们间的关系和之前所说的各个层级的缓存设备一模一样,都是 “逐层向上缓存数据,逐层向下查找数据”。
根据这些实际的物理结构,我们考虑一下高速缓存存储器的性能和损耗情况。我们建立如下的衡量指标(Cache Performance Metrics):
Miss Rate: cache memories 不可避免的会发生 cache miss,这就是 cache memories 性能可能产生损耗的原因之一;
定义:缓存未命中次数 / 总访问次数( = 1 - hit rate);
一般情况下,L1 Cache 的 未命中率在 3 ~ 10%,L2 Cache 在 1% 左右,和缓存大小紧密相关(如此低的 Miss Rate 得益于 程序局部性);
Hit Time:虽然有时缓存成功命中,但从缓存的数据行中传输到处理器中仍然需要时间。
定义:从检查标志位,到 hit 直接返回 block 中的缓存数据所需时间;
Miss Penalty:由于 Miss Rate,从内存传输到缓存和 CPU 中通常会花费更多时间;
定义:从检查标志位,到 miss、从内存读取数据,直到数据传回 CPU 所需时间;
一般情况下从主存中读取数据大约花费 50 ~ 200 个时钟周期(如果在其他的存储系统的层次中,花费可能大得多);
事实上,这些一次两次看似影响不大的 Cache miss 和 hit,对系统性能影响相当大!数学证明表明,99% 的 hit rate 的系统性能比 97% 的 hit rate 对应的系统性能迅速 2 倍!
主要是因为 miss penalty 很大,miss rate 的权重远大于 hit rate 的权重。因此我们通常看 miss rate 而不是 hit rate;
那么我们分析之前的 cache 参数对性能的影响:
cache 总大小影响:增大同时 提高命中率,但增加 hit time;
block size (
associativity (
11.5 Performance Impact of Cache
11.5.1 Writing Cache Friendly Code Ⅰ
考虑上一节惊人的缓存性能的情况,我们确实应该写出一些 Cache Friendly 的代码,这是优化代码性能的一个重要方面。在分析了缓存的特性和程序局部性之后,我们可以这样来充分利用高速缓存带给程序的性能提升:
关注经常被调用的函数中执行次数最多的内层循环的性质,积极对它进行算法层面优化;
尽量使用重复的变量引用,而不是很多的全局变量(利用了时间局部性,减少 cache miss 的可能);
它和 第 15. 章的 CSE 优化不冲突,后者是尽量避免 Memory Alias;
尽量使用 stride-1 reference patterns(或者说程序循环的步长尽量小,尤其是逐个访问数组元素,这就将 cache block 的优点发挥了出来,利用了空间局部性,减小 cache miss 的可能);
总结:我们分析缓存的组织原理和特性,是进一步定量地(如上面的指标)去体现、印证程序局部性的概念。
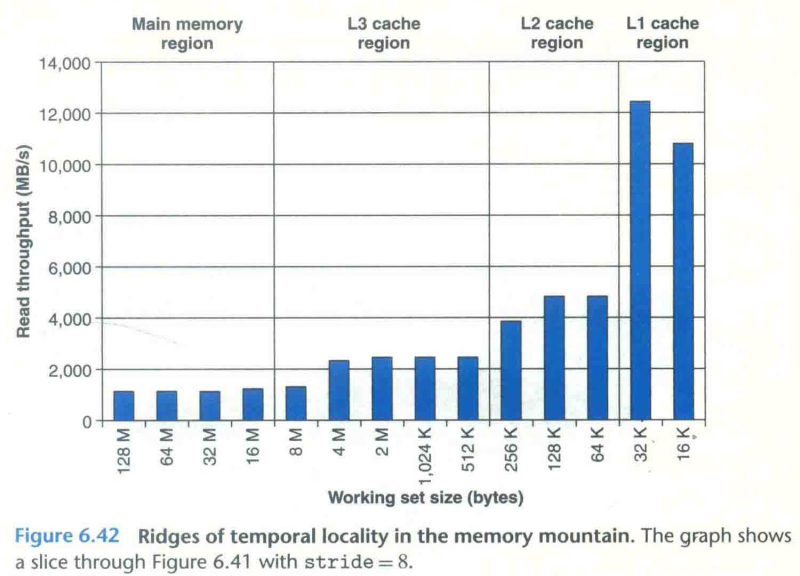
11.5.2 The Memory Mountain
之前简单地对缓存组成的分析,让我们看到了关注缓存能够对程序带来较显著地性能影响。那么这节我们更深入地去探究缓存对程序性能的影响。
首先引入一个概念:
Read throughput(吞吐量,或者说 read bandwidth,读带宽):单位时间内从内存中读取数据的最大字节数,单位 MB/s;
于是,我们可以绘制一个 时间局部性、空间局部性 关于 机器吞吐量的三维坐标图(存储器山),以此展示缓存对程序性能的重要影响。
其中,我们以访问数组的程序为例。我们将遍历数组的步长作为衡量程序空间局部性的指标(步长越大,空间局部性越小),将一次读取数组元素数量作为衡量程序时间局部性的指标(一次取出的数据越多,访问到相同地址数据的机会越小,时间局部性越小);
如图:
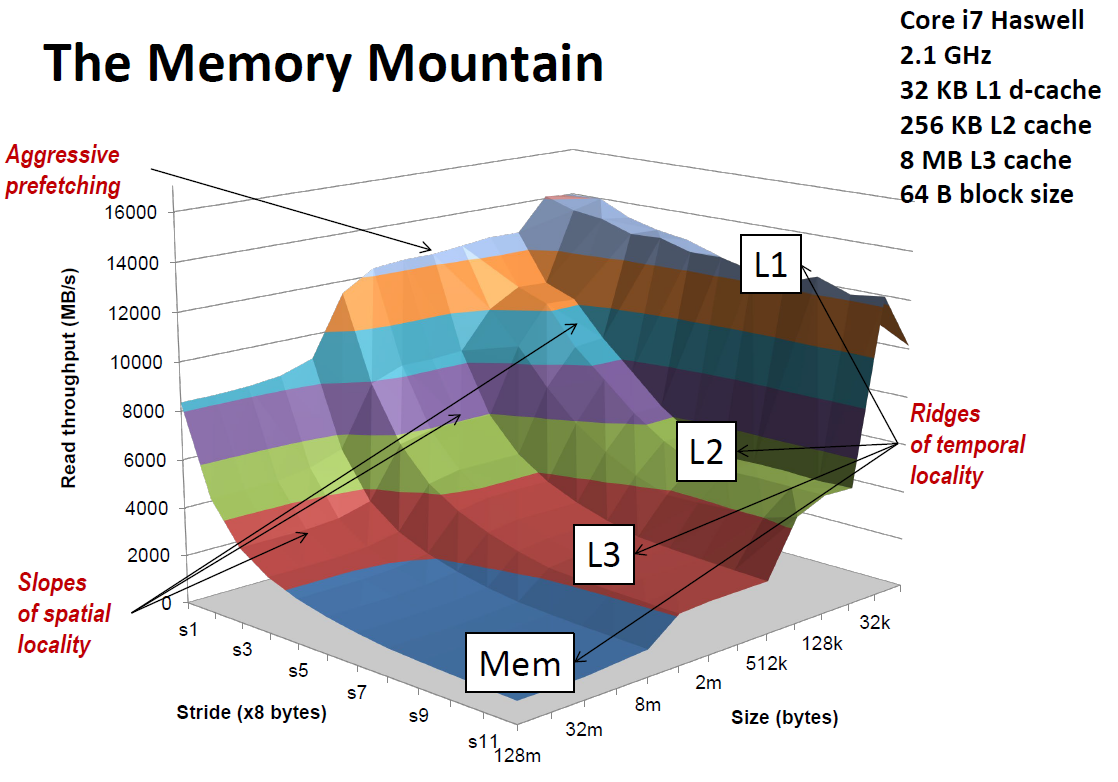
我们从读取数据量 size 的方向看图,会发现 memory mountain 有一个个像山脊一样的结构,这恰好对应了从 L1 到 Memories 的数据引用的平均性能(小的数据量更有可能在每次遍历时放在同一个缓存的 block 中,发生 cache miss 的机会就更小,只需要依靠更接近寄存器层级的缓存设备就能得到答案);
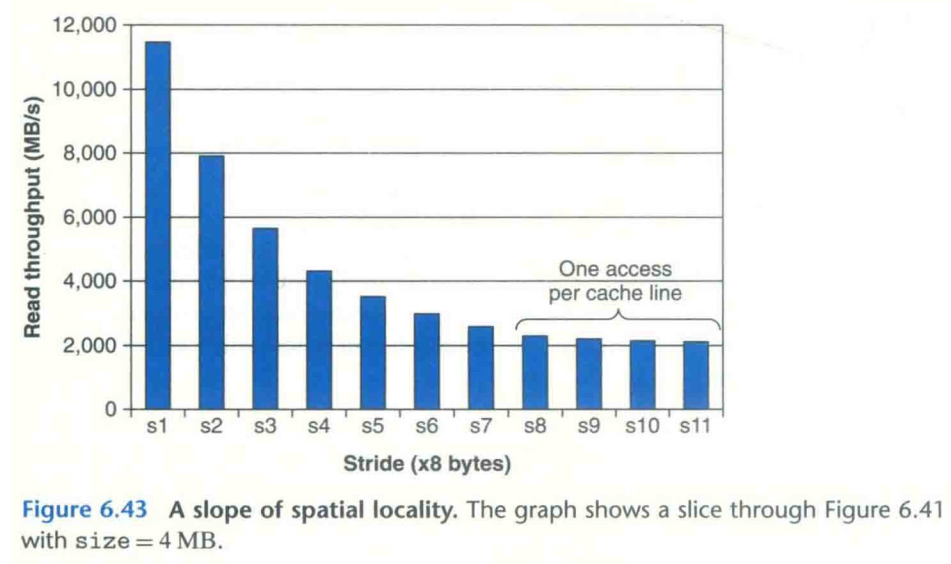
而从数组访问步长 stride 的方向看图,会发现随着步长的增加,整体有一个负向的斜率。而随着步长大到一定程度,负向的斜率趋于平缓,这是因为步长大过了缓存 block size,导致几乎每次都会存在 Cache miss,就很难得到缓存的增益了。
11.5.3 Writing Cache Friendly Code Ⅱ - Rearranging loops to improve spacial locality
借助上面对于 memory mountain 的进一步分析,我们还可以想到更多的具体利用缓存来优化程序性能的方法。
例如,我们以矩阵乘法运算为例,我们假定以下的条件:
N × N 方阵,元素为 double(8 bytes)类型;
那么按照正确的一般矩阵相乘的方法,总单位运算次数
事实上,计算的一般方法有许多种(但都是 结果矩阵
首先来对不同策略的矩阵乘法分析 Miss Rate:
前提假设
机器缓存空间的 块大小(
B)为 32 Bytes(能够一次性放下 4 个 double 数据);矩阵维度
N非常大(缓存空间的总大小不足以装下矩阵的多个行;
分析方法:检查内层循环的函数访问模式(因为外层循环次数不可避免);
由于运算的方式固定,我们可以通过更换内外层循环顺序(共
在分析前,先再次回顾一下 C 中数组的 memory layout:
二维数组的至少每一行的数据空间是 contiguous 的,并且行优先(row major);
stride-1 逐个访问数组行的方法最能利用 spacial locality,它的
stride-1 逐个访问较大数组列的方法完全无法利用 spacial locality,因为 每一列同一行的元素一定不在同一个缓存数据块中(之前已经假设 “缓存空间的总大小不足以装下矩阵的多个行”),因此 miss rate = 1(100% cache miss);
情况 1:先固定 i(A 的行),再固定 j(B 的列),最后遍历 k(A 第 i 行每一列、B 第 j 列每一行)
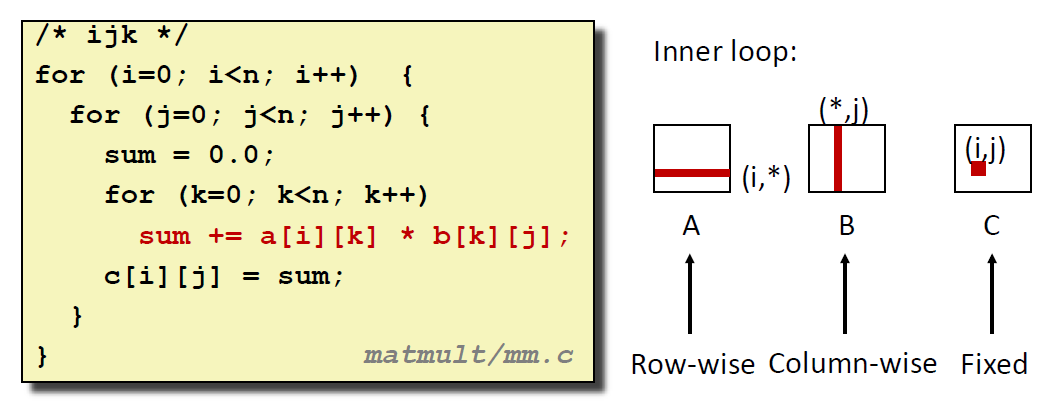
这种情况下,对每一个最内层循环:
每次要求从内存中取出 A 矩阵的同行相邻元素,miss rate = 8 / 32 = 0.25;
每次要求从内存中取出 B 矩阵的同列相邻元素,miss rate = 1;
每次要求从内存中取出 C 矩阵的一个元素,所以对单个元素而言 miss rate 近似为 0;
ℹ 平均每次内层循环约加载 2 次数据,存储 0 次,cache miss 次数 1.25 次;
这种情况与 jik 顺序的情况相同;
情况 2:先固定 k(B 的行),再固定 i(A 固定位置 第 i 行 第 k 列),最后遍历 j(C 的第 i 行每一列)
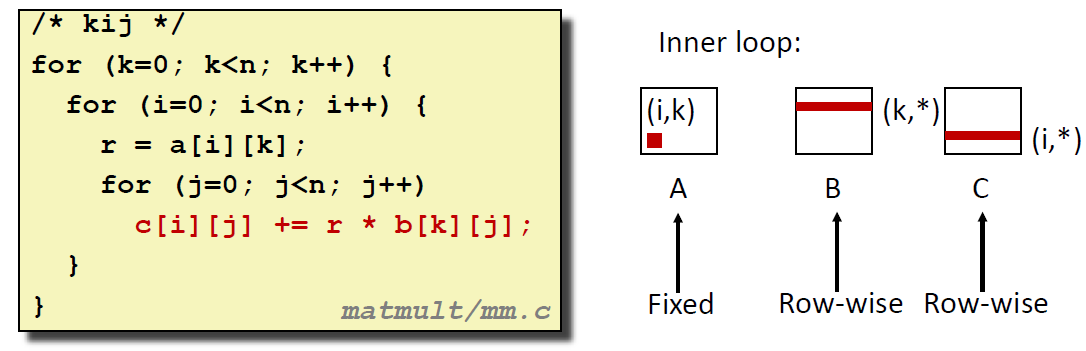
这种情况下,对每一个最内层循环:
| Op Matrix | A | B | C |
|---|---|---|---|
| Miss Rate | 0.0 | 0.25 | 0.25 |
ℹ 平均每次内层循环约加载 2 次数据,存储 1 次,cache miss 次数 0.5 次;
这种情况与 ikj 顺序的情况相同;
情况 3:先固定 j(C 的第 j 列每一行),再固定 k(A 的第 k 列),最后遍历 i(固定 B 遍历 C 的 列)
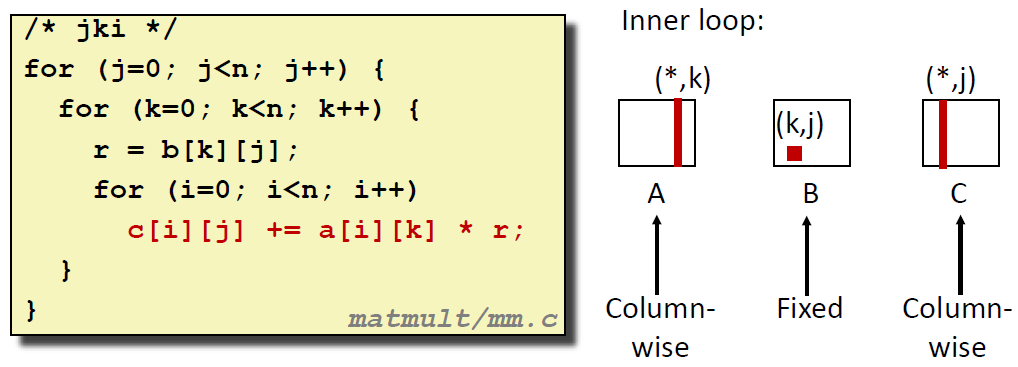
这种情况下,对每一个最内层循环:
| Op Matrix | A | B | C |
|---|---|---|---|
| Miss Rate | 1.0 | 0.0 | 1.0 |
ℹ 平均每次内层循环约加载 2 次数据,存储 1 次,cache miss 次数 2.0 次;
这种情况与 kji 顺序的情况相同;
综合上面的三种情况,我们进行实际的测试,发现结果如我们所料:
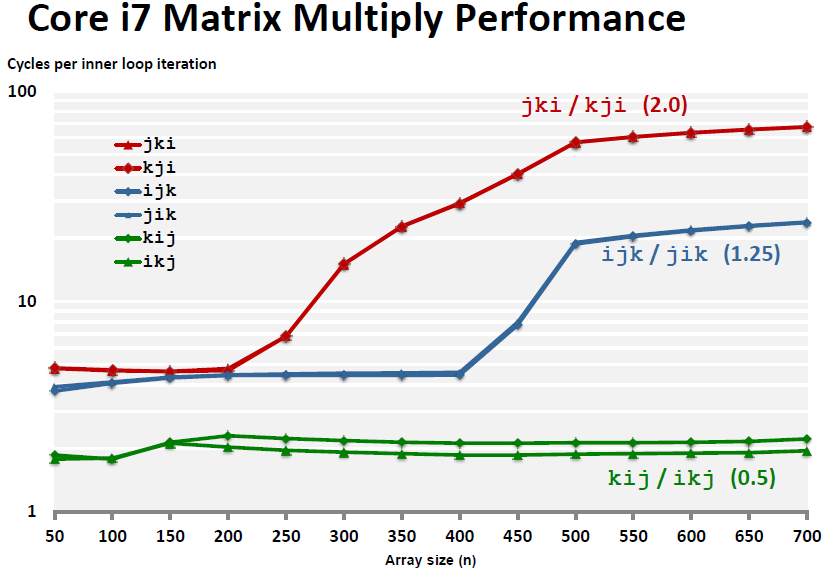
事实证明,kij/ikj 遍历方法(固定 A / B 的位置,遍历剩下一个运算矩阵的行,来得到结果矩阵的行)是最能利用 cache memories 的优势的方法,而我们最常用的 ijk 方法却不是最好的方法。
11.5.4 Writing Cache Friendly Code Ⅲ - Using blocking to improve temporal locality
上一节的例子主要以矩阵乘法为例,从提升空间局部性的层面来充分利用缓存、提示程序缓存效率。本节将从另一个角度——提升程序时间局部性来讨论如何写出缓存友好的代码。
再举一个针对矩阵乘法的例子。
xxxxxxxxxxc = (double *) calloc(sizeof(double), n*n);
/* Multiply n x n matrices a and b */void mmm(double *a, double *b, double *c, int n) { int i, j, k; for (i = 0; i < n; i++) for (j = 0; j < n; j++) for (k = 0; k < n; k++) c[i*n + j] += a[i*n + k] * b[k*n + j];}对于上面的乘法而言,我们作如下假设:
机器缓存空间的 块大小(
B)为 64 Bytes(能够一次性放下 8 个 double 数据);矩阵维度
N非常大(缓存空间的总大小不足以装下矩阵的多个行;
在这种情况下,最内层的循环中,每一个循环的 cache miss 平均次数为:
我们在每次内存循环取矩阵乘法的
改为:
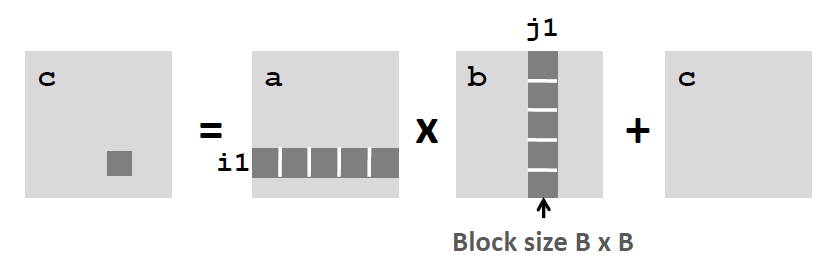
即计算代码改为:
xxxxxxxxxxc = (double *) calloc(sizeof(double), n*n);
/* Multiply n x n matrices a and b */void mmm(double *a, double *b, double *c, int n) { int i, j, k; for (i = 0; i < n; i+=B) for (j = 0; j < n; j+=B) for (k = 0; k < n; k+=B) /* B x B mini matrix multiplications */ for (i1 = i; i1 < i+B; i1++) for (j1 = j; j1 < j+B; j1++) for (k1 = k; k1 < k+B; k1++) c[i1*n+j1] += a[i1*n + k1]*b[k1*n + j1];}这个时候我们再次分析 cache miss 的情况。
假设选取的
每一个 sub-block(子块)内部的 cache miss 数量:
每一次行循环的 cache miss 数:
总的 cache miss 数:
总而言之,这样的改进并没有根本上提升算法的时间复杂度,但是它却能确确实实地减少常数级别的 cache miss 数量(
为什么能够引起如此大的常数优化呢?主要是以下原因:
我们在选取 block 的时候,相当于加载了一个地址上更相邻的、之后能被反复使用的变量,因为我们缩小了矩阵乘法的
输入数据
11.5.5 Cache Performance Summary
在 11.5 节中,我们通过几个例子了解到,虽然我们无法显式控制 cache 的存储方式,但是通过对于程序局部性的分析,我们可以更高效地利用 cache,从而提升程序允许效率。这主要可以从两个方面下手:
使用 stride-1 reference pattern、关注内层循环的步长和方式,以提升程序的空间局部性;
多次使用相同的局部变量、分块访问,以提升程序的时间局部性;
Chapter 12. Program Optimization
One of the themes for this chapter:
去除程序不必要的工作、编写编译器友好代码、提升运行速度;
利用机器代码特性,针对特定机器对程序优化;
编译器无法理解一些内容,例如 int 数据类型可能只用到相当小的范围、procedure call 究竟是什么意思,等待。编译器只是针对一些特定情况,对照 “cookbook” 进行有选择地优化。其遇到复杂或者特殊情况的 “保底” 方案是不对代码进行优化。
初始思路:查看程序汇编代码哪些地方没被优化,找到对应的源码部分进行重写,直至重构成编译器友好代码(只要不过度牺牲程序可读性就行)。
12.1 Goals of Optimization
Minimize number of instructions
避免重复计算;
避免不必要的计算;
避免较大计算量的操作(例如乘、除);
Avoid waiting for memory
尽量将数据和运算过程放在 register 中,而非内存中;
使用 cache-friendly 的方式访问内存;
尽早从内存加载数据,并且加载次数越少越好;
Avoid branching
不要写出不必要的判断结构;
写成让 CPU 容易预测分支的代码(流水线);
尽量解开循环,分摊分支的开销;
Make good use of locality & cache: 写出程序局部性良好的代码、充分利用缓存机制(10.2 & 11.X);
12.2 Limits to Compiler Optimization
无法优化算法的渐进时间复杂度;
绝不会改变程序语义、行为;
编译时仅仅分析每个函数一次(inline 函数除外);
目前 Whole-program analysis ("LTO") 比较受欢迎,尽管开销很大;
无法很好地针对运行时的输入内容进行优化
可能出现最坏情况,尤其是面对非法输入的时候;
12.3 Generally Useful Optimizations
本部分的优化技巧不针对特定的编译器或者处理器,具有普适性。
绝大多数编译器在一定的优化等级下,都能优化本节的情况,但是我们应该学习这些方法。
注:一个能看到优化过程的网站:COMPILER EXPLORER
根据 12.1 中的目标,我们可以整理出一些常见的情况,这些情况下编译器能够优化,或者说具有普适性的优化策略,主要有以下两类:
Local Optimizations (work inside a single basic block)
Constant folding(常数折叠)
Strength reduction(计算强度削减)
Dead code elimination(死代码剔除)
Local CSE(Local Common Subexpression Elimination,局部的相似子表达式复用)
……
Global Optimizations (process the entire control flow graph of a function)
Loop transformations(循环结构转换)
Code motion(代码移动)
Inlining(内联化)
Global CSE(全局的相似子表达式复用)
这章仅仅叙述它们的思路,不涉及具体实现,因为具体实现就涉及到编译原理(AST 语法树等知识);
12.3.1 Constant Folding
常数折叠的方法主要有以下几个方面:
直接运算代码中的常数表达式
xxxxxxxxxxlong mask = 0xFF << 8;// 优化为:long mask = 0xFF00;直接运算一切可以常量化的表达式,例如针对常量调用的库函数、常量输入等
xxxxxxxxxxsize_t namelen = strlen("Harry Bovik");// 优化为:size_t namelen = 11;
12.3.2 Dead Code Elimination
死代码删除方法的思路主要来源于 12.1 中的 “Avoid Branching” 和 “Minimize number of instructions”,分为以下几种情况:
删除语义上不可能执行到的代码(无效代码):
xxxxxxxxxxif (0) { puts("Hello, 0"); }if (1) { puts("Hello, 1"); }// 改为:puts("Hello, 1");删除结果被覆盖的代码(也是无效代码):
xxxxxxxxxxx = 23; x = 42;// 改为:x = 42;
这类优化方式看起来很蠢,但也很重要,因为有时候这些死代码不容易被肉眼识别,或者在编译器进行其他优化过程中,在语义树上出现了,那么就需要这种方法来清理。
12.3.3 Common Subexpression Elimination
CSE 的思路就是根据 AST 树的特征,约去重复计算,从而降低运算量,例子如下:
xxxxxxxxxx/* 此处展示的是 Local CSE */
up = val[(i-1)*n + j];down = val[(i+1)*n + j];left = val[i*n + j - 1];right = val[i*n + j + 1];
// 可以改为:long inj = i*n + j;up = val[inj - n];down = val[inj + n];left = val[inj - 1];right = val[inj + 1];xxxxxxxxxxnorm[i] = v[i].x * v[i].x + v[i].y * v[i].y;
// 改为:elt = &v[i];x = elt->x;y = elt->y;norm[i] = x * x + y * y;12.3.4 Code Motion
I.e., reduce frequency with which computation performed(也是降低代码重复运算频率,不过是在 global 范围进行)
If it will always produce same result(这种改动语义不变);
Especially moving code out of loop(常见于将代码移出循环结构,但为了保持语义,要求移动的代码在每次循环中的结果不变);
Example:
xxxxxxxxxxvoid set_row(double* a, double* b, long i, long n) {long j;for (j = 0; j < n; j++)a[n*i + j] = b[j];}// 改为(将 n*i 这个与循环无关的变量提出循环,避免重复运算):void set_row(double* a, double* b, long i, long n) {long j;int ni = n * i;for (j = 0; j < n; j++)a[ni + j] = b[j];}
12.3.5 Inlining
I.e., copy body of a function into its caller(s);
对于一些短的、计算开销小的非递归函数,即便编程人员不指定 inline 关键字,编译器也应该识别到并且内联操作。这样做的好处有两点:
消除函数调用的栈帧分配开销;
为其他许多优化方法创造条件。例如,对代码中的一些函数内联,可以被编译器找到例如 dead code elimination、constant fold 的机会;
这是个例子:
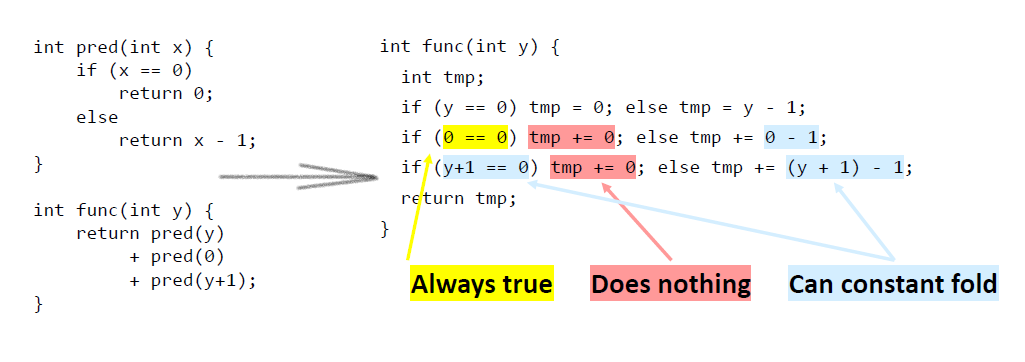
缺点:
这种优化方法在某些情况下(内联函数很长、开销很大)会导致整体代码空间占用变大、速度降低;
对调试工具、profiling 工具不友好;
12.3.6 Strength Reduction
I.e., replace costly operation with simpler one.(计算量减小)
可以用移位、加法尽量代替乘法、除法(优化的比例取决于不同的机器);
12.4 Obstacles for Compiler to Optimization
现在反过来看,有哪些操作会阻碍编译器优化?
阻碍编译器优化的原因之一就是期间调用了其他函数,这样 gcc 可能就无法识别到优化方法。还有一个主要原因就是 “内存别名” 的存在。
12.4.1 Optimization Blocker #1: Procedure Calls
典型例子:
xxxxxxxxxxvoid lower(char* s) { size_t i; for (i = 0; i < strlen(s); i++) if (s[i] >= 'A' && s[i] <= 'Z') s[i] -= ('A' - 'a');}可以注意到,循环判断条件中有一个函数 strlen(s),我们都知道这是计算字符串长度的函数。但是编译器不知道,它认为这个函数有可能在每次循环中,返回值可能改变,所以不会把它优化为一个常数,而是保持每次循环判断时,都重新调用 strlen(s)。
可是,strlen(s) 的复杂度是
所以,正确的做法是,先把 strlen(s) 算出来。更好的主意是,干脆不使用 strlen(),因为判断字符串结束原本就是能在循环中发现的情况,并且把数组索引改成指针取值,这样还能再节省常数时间:
xxxxxxxxxxvoid lower(char* s) { while (*s != '\0') { if (*s >= 'A' && *s <= 'Z') *s -= ('A' - 'a'); s++; }}回过头来,为什么绝大多数的编译器没法优化这种 procedure calls 的情况?主要有几点原因:
Procedure may have side effects; 就像前面说的,编译器不知道运行这个 procedure 会不会改变当前环境中其他变量的值,所以不敢贸然改变 procedure 运行顺序;
Procedure 会出现重载、重写的情况,这些函数有不同版本,可能分布在不 同文件中,只有编译结束,链接的时候才知道最终用的函数是谁。对于虚函数而言,甚至要在运行时才知道调用的是哪一个同名函数;所以更不敢随意判断某个 procedure 的作用,也就无法解决上面的问题;
如果全面分析所有同名 procedure,并且找到它们的含义、作用,那么编译开销过大,非常不现实;
综上,编译器一般的做法是将 procedure 看作一个黑盒,行为不确定,所以一般不会优化它的执行顺序。因此,开发者应该清楚意识到函数的作用,并且重视它执行的位置对代码性能的影响。
12.4.2 Optimization Blocker #2: Memory Aliasing
先看示例:
xxxxxxxxxx/* Sum rows is of n x n matrix a and store in vector b */void sum_rows1(double* a, double* b, long n) { long i, j; for (i = 0; i < n; i++) { b[i] = 0; for (j = 0; j < n; j++) b[i] += a[i*n + j]; }}上面的代码看起来性能上没什么问题,大多数人都会如此实现代码。但是我们看看对应的 x86-64 汇编码:
xxxxxxxxxx# sum_rows1 inner loop.L4: movsd (%rsi,%rax,8), %xmm0 # FP load addsd (%rdi), %xmm0 # FP add movsd %xmm0, (%rsi, %rax, 8) # FP store addq $8, %rdi cmpq %rcx, %rdi jne .L4我们发现,小小的 b[i] += a[i*n + j] 竟然有两次对内存的操作(从内存读到寄存器,计算后再写回内存),为什么会这样?为什么不直接在内存中计算?
这是因为 Memory Alias(内存别名)在 C 中是允许的。比如,如果我这么调用 sum_rows1:
xxxxxxxxxxdouble A[9] = { 0, 1, 2, 4, 8, 16, 32, 64, 128 };
double* B = A+3;
sum_rows1(A, B, 3);那么,第二参数 B 就是 A 的一部分的内存别名,也就是说,程序有两个指针指向一块内存地址,这样的话,在每次 B[i] = 0 后,就会改变 A 的内容,从而改变求和的值。因此编译器仍然不敢直接优化。
问题在于,我们知道这个函数的作用是数组列求和,我们不会传入两个内存别名。但是编译器不知道——因为要检查所有的 memory alias 开销也非常大,所以编译器默认程序中都存在内存别名。
所以解决方法是,我们暗示编译器这里不会有内存别名导致循环中数组值的更改:在求和时不直接加到 b 中,而是以临时局部变量存储,求和循环结束后同一赋值给 b,这样在一次求和循环中编译器就不会重复从内存读取信息了:
xxxxxxxxxx/* Sum rows is of n x n matrix a and store in vector b */void sum_rows1(double* a, double* b, long n) { long i, j; for (i = 0; i < n; i++) { double val = 0; for (j = 0; j < n; j++) val += a[i*n + j]; b[i] = val; }}这样内层求和循环的汇编码就变得简单了:
xxxxxxxxxx# sum_rows1 inner loop.L10: addsd (%rdi), %xmm0 # FP load + add addq $8, %rdi cmpq %rax, %rdi jne .L10实际上,内存读写仍然是耗时大头,所以改写后性能提升不会非常明显。
对开发者而言,应该习惯于在循环前引入一些局部变量(Accumulate in temporary),尤其是含有数组索引的循环,这样能够暗示编译器按照没有内存别名的情况处理。
总结一下就是:
多使用临时局部变量来存放中间值,尤其是在循环中;
使用更严格的关键字,例如
int[]好过int*来让编译器知道不会有 memory alias;
上面的几种优化技巧都是比较简单和零碎的,不宜死记硬背,应该贯通在实践当中。下面从另一个角度考虑优化问题。
12.5 Machine-Dependent Optimization
这类优化取决于处理器机器和系统,根据汇编处理方式进行优化。
表面上与机器无关的优化方法都考虑得差不多了,但在机器层面还有一些优化的方法。为了考虑这些方法,我们需要先了解机器的简单组成和基本运作原理。下面是上个世纪末的处理器的大概的设计样式:
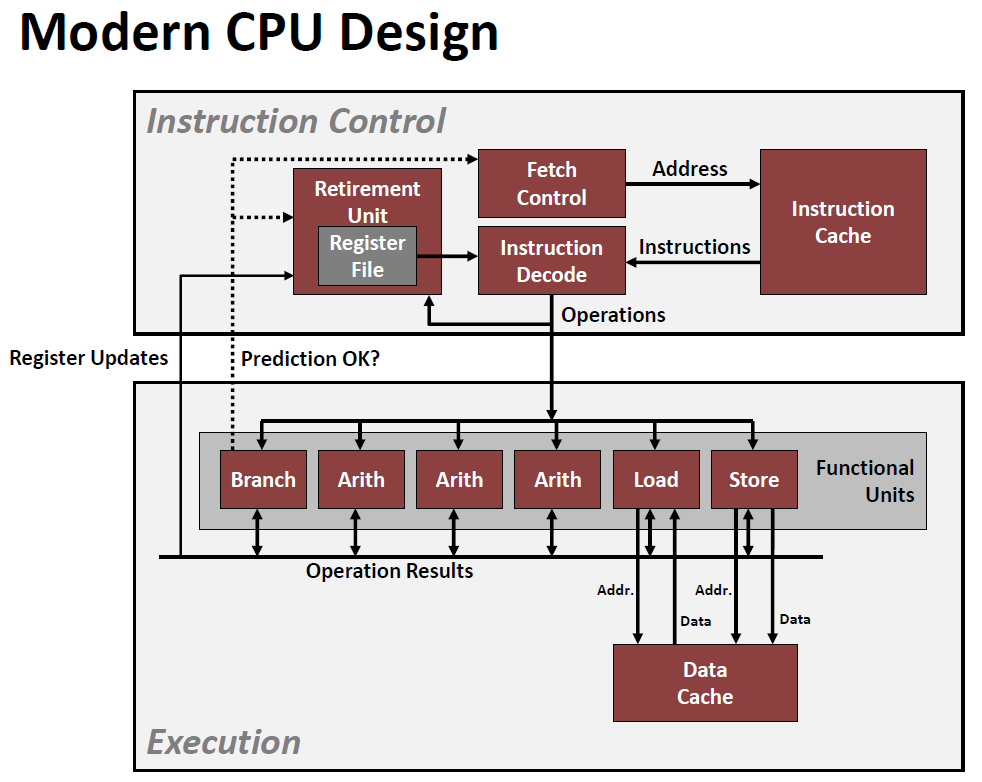
底层机制过于复杂,一般人短时间内几乎不可能理解,所以这里仅仅浅浅介绍一下。
CPU 执行代码时,借助了多种方法和技术,构建了健全的硬件设施,使得其执行指令的速度远远快于一条一条读取执行的速度。其中一种技术被称为 “超标量乱序执行” 技术(super-scalar out of order execution),它的思路可以理解为:CPU 一次性读入大量机器指令,再将顺序的指令拆开,发现逻辑上某两句间不相互依赖,于是 CPU 可以不按顺序、尽可能多地同时执行这些代码。
Superscalar(超标量)
每个时钟周期执行多个操作;
指令级并行(CPU 自主发现指令间依赖关系,并行执行没有依赖关系的指令);
Out-of-order execution(乱序执行)
Instruction Control Unit (ICU): Fetch / Decode / Write Back; Execution Unit (EU): Execute / Memory;
Fetch Control: Branch Prediction(比 Y86-64 的更高级) + Speculative Execution;
Instruction Decode
指令的这种特性被称为 指令级并行性(instruction level parallelism);
上图的 Instruction Control 展示了 CPU 如何从高速缓存中抓取指令,并放入运算单元的。注意,这里所有的操作都使用缓存和寄存器,因为其他储存介质(包括内存)都太慢了。
上面在一个时钟周期中处理、执行多条指令的处理器被称为 Super-scalar Processor,它们通常一次性获取一串指令流,并动态地进行调度和执行。它的好处是 充分利用了代码中的指令级并行性,所以大多数现代 CPU 都是超标量的,并且现代 CPU 的执行模型也几乎都是乱序执行的模型。
现代 CPU 的策略是乱序执行,固然非常复杂,比之前讨论过的按序执行的流水线(pipelining) 更复杂。
流水线的基本思想是,处理器将每个计算分解为一系列不同阶段,每个阶段都有一个专用硬件可以独立完成。于是,当一个计算阶段的硬件空闲下来时,就可以接受下一个数据的计算工作。
其中,除法运算无法被分解在流水线上进行,一次操作 3 ~ 30 个时钟周期,所以是一个昂贵的操作。
这些并行性都是单个 CPU 的单核的并行性,不涉及多核并行。
总的来说,在机器层面上,程序的优化上限有两点:
Latency Bound: 当 一系列指令被执行时必须按照严格的顺序进行 时,也就是说后一条指令依赖前一条的结果,此时程序的性能会受到限制。这种瓶颈(data dependency)限制了指令级别的并行性(没有 Y86-64 的 data forwarding);
其计算方法就是,一条指令 / 操作 最原本的 latency 时延,与承载量无关;
Throughout Bound:处理器的运算单元所能达到的最大承载量(computing capacity,通常与对应运算单元数目、运算单元种类有关),这也是程序性能的最终上界。
接下来,借助流水线的知识,我们再分析一下现代处理器内部各个模块是如何进行协作的,以便我们针对特定机器进行优化。
对于现代处理器,主要就分为以上的两个部分:Instruction Control Unit & Execution Unit。其中 Instruction Control Unit 的主要结构如下:
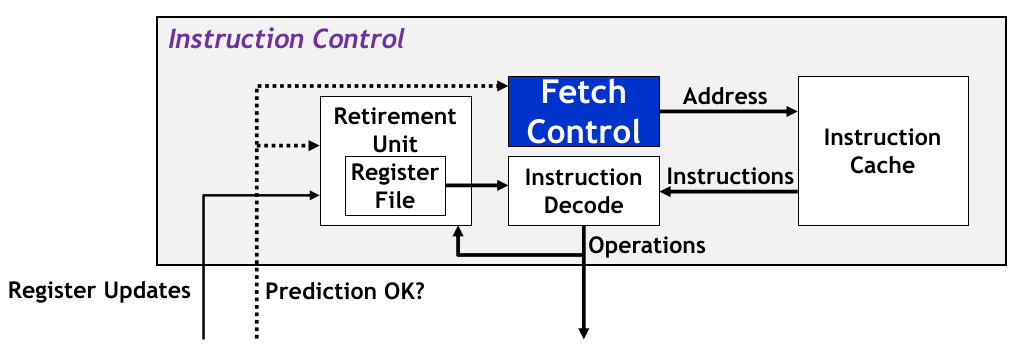
对于 Fetch Control Logic,采用的技术就类似在流水线中介绍的 Branch Prediction + Speculative Execution;
前者(branch mis-prediction)表示一种预测下一条指令位置的技术(是否选择分支的策略、预测目标分支的策略);后者(speculative execution)表示在分支预测后,还没有确定是否正确就立即取出预测位置的指令进行执行。如果后面检查出现错误,则恢复到原先的状态;
对于 Instruction Decoding Logic,它的工作就有些不一样。为了充分利用指令集并行资源,该逻辑块:
将传入的指令数据继续分解为 primitive instructions,每个 primitive instruction 都存在更简单的算术、加载、存储的任务,例如:
xxxxxxxxxxaddq %rax, 8(%rdx)|vload 8(%rdx) -> t1addq %rax, t1 -> t2store t2, 8(%rdx)下一步,为了方便交给下面的 Execution Unit 进行并行运算,中间存在一个 寄存器重命名 的步骤(后面再描述具体原因),根据原本一条指令所对应的 primitive instructions 用到的临时寄存器,按使用依赖关系对版本进行编号,例如:
xxxxxxxxxx.L25: # Loop:vmulsd (%rdx),%xmm0,%xmm0 # t *= data[i]addq $8, %rdx # Increment data+icmpq %rax,%rdx # Comp to data+lenjne .L25 # if !=, goto Loop|vload (%rdx.0) -> t.1mulq t.1, %xmm0.0 -> %xmm0.1addq $8, %rdx.0 -> %rdx.1cmpq %rax, %rdx.1 -> cc.1jne-taken cc.1
而 Execution Unit 部分的主要结构如下图所示:
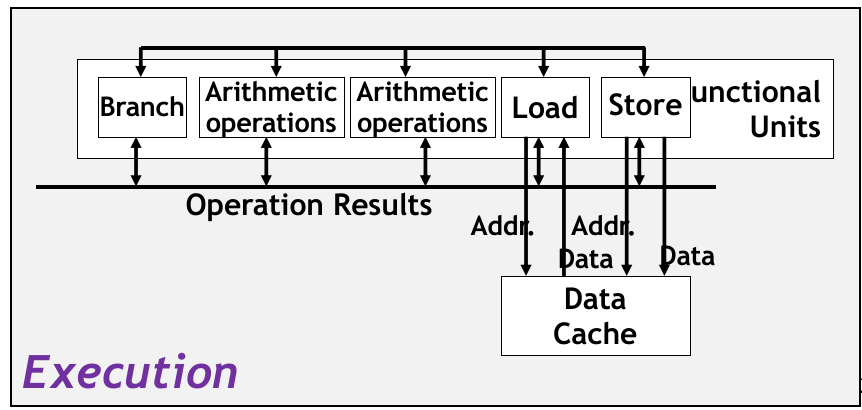
我们发现这里存在很多单独的运算单元,可以从 ICU 部分接收更多指令(
Data Cache 是存放最近访问的 / 临时的数据的地方。遵循 Memory Hierarchy,支持 EU 运算单元的快速存取,稍晚些时候会根据情况向 ICU 的 register files 以及 memory 写入数据。
此外,Branch 模块不是用来运算某个分支是否应该跳转,而是用来计算分支预测是否正确。若预测错误,则 Branch 会通知丢弃该分支中执行得到的所有数据(利用 ICU 中的 Retirement Unit 不允许错误数据写入,并通知 Data Cache 标记无效数据),否则保留数据并写入;
同时,ICU 中的 Retirement Unit 跟踪当前过程所有正在执行的指令,确保数据存取符合 sequential 语义。大致逻辑如下:
当一个指令被 decode,它的信息会被放入一个 FIFO 队列中,直到两种情况之一才会从队头出队:
Retirement Unit 发现该指令的所有 primitive instructions 被执行完,并且所有涉及通向该指令的 branch prediction 都是正确的,这条指令才会被 “retired”,结果写入程序寄存器中;
如果 Retirement Unit 发现该指令途中某个 prediction 是错误的,那么这个指令会被 “flushed”,计算结果会被抛弃,不会写入寄存器中。
注:上图所描述的 “Arithmetic Operation” 单元是被特化来执行整型、浮点型的不同组合的运算的(就是说,这些单元能执行多种不同操作,例如既能整型运算又能浮点型运算)。这样不致于程序对硬件资源的利用率不好。
那么,“乱序执行” 技术如何实现?很简单,在 ICU 的 Instruction Decode Logic 给出
为了加速一条指令到另一条指令的结果传送,处理器引入了一个机制,就是提到的 “寄存器重命名”。这些信息被共享在 renaming table 中(如上图下方的一条长横线)。当运算单元接到
注:这个表维护每个寄存器
与更新的重命名版本标记 之间的关系。 这个表只包含未 “退役” 的寄存器条目。如果指令在表中没找到某个寄存器,那么说明值在寄存器文件中,需要的指令这时才会向寄存器文件请求查找。
每当 Branch 确定了分支结果后,才会通知 retirement unit 将正确的分支上运行的结果写入寄存器。这个时候也会重整 renaming table;
等待某个版本
这个 renaming table 就避开了 Y86-64 中的 control hazard,即便 branch prediction 还没有验证、不能更改程序寄存器,也依然能临时存放一些计算好的数据。
最后,为了定性分析其中的运算效率,我们定义:
Issue Time(发送时延):一个
Latency(延迟):在一个
latency 的计算与 capacity 无关,只与这个指令运算本身的时间有关。
Capacity(硬件承载量):一个处理器对于某种运算,运算单元的数量。
Max Throughput(最大吞吐量):
Throughput Bound(吞吐量界限):最大吞吐量的倒数,描述了 执行一条指令在吞吐量的限制下,需要的时间界限;
Latency Bound(延迟界限):等于延迟本身。描述了 顺序执行一条指令(就是延迟的限制下)的时间界限。

如上图,我们从
Intel Core i7 Haswell处理器的指标可以发现,Add / Multi 在 Latency >= 1 的情况下,仍然有 Issue Time = 1,说明内置了流水线技术。并且,可以通过 Latency 反推流水线有多少个 stages。我们还发现,divider 没有内置流水线,因为 Issue Time = Latency Time,这说明了一个除法运算不能被分割成多个 stages,必须等待前一个计算完成才能继续计算下一个;
同时,不同种类的除法运算(如数据类型)耗时不同,相同点是耗时很长。
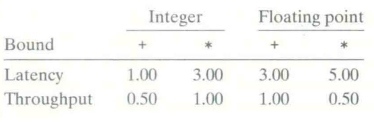
这个图的数据就是由上一个图的信息得到的。所有运算的 latency 对应上面硬件限制的 latency time;Throughput 则是由 Capacity / Issue Time 得到的。
但是,虽然整型加法有 4 个运算单元,但是 Throughput 只有 0.5,主要是因为处理器最多只有 2 个 load 单元。
12.5.0 Data-Flow Representation: Machine-level Profiling
在利用我们已有对于 Modern Processor 的认识来 tuning 程序前,我们还要掌握一种分析机器指令级运算效率的图:Data-Flow 图。
它展现了不同操作间数据的 dependency 是如何限制执行顺序,并形成关键路径的。这个关键路径就是该组机器指令的执行时间下界。
以一个结构体数据类型为例:
xxxxxxxxxx/* data structure for vectors *//* we can use different declarations for data_t */typedef struct { size_t len; data_t *data;} vec;其中的一个函数是:
xxxxxxxxxx/* Retrieve vector element and store at val. */int get_vec_element(vec* v, size_t, idx, data_t* val) { if (idx >= v->len) return 0; /* Out of range. */ *val = v->data[idx]; return 1;}对这个函数进行基准测试(Benchmark Computation):
测试函数:
xxxxxxxxxxvoid combine4(vec* v, data_t* dest) {long i;long length = v->len; /* 将可能重复计算的部分提出循环 */data_t* d = v->data;data_t t = IDENT;for (i = 0; i < length; i++) /* 不使用额外的 procedure 来重复检查 v->len */t = t OP d[i];*dest = t; /* 不直接在循环内给数组赋值,使用 local variable */} /* 暗示编译器没有 memory alias */我们将使用不同数据类型(
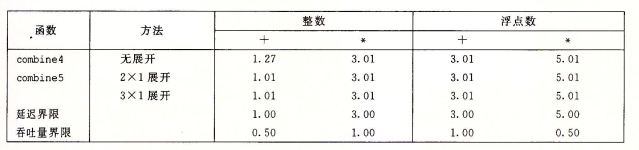
data_t分别是int、long、float、double),针对不同运算和值(OP分别是+、*,IDENT分别是 0、1);测试指标:CPE (Cycle Per Element)
Convenient way to express performance of program that operates on vectors or lists.
在这里,CPE 就是一个时钟周期中的进行
OP运算的次数,总时长指标T = CPE * n + Overhead(这里 overhead 就是 n = 0 时的基础开销);tips: 在检查代码性能时,不应该以真实时间做单位(例如 nanosecond),应该使用处理器内部时钟周期作为单位更有用。因为开发者无法控制处理器频率,但是可以控制并衡量操作的时钟周期。
生成的机器指令如下:
xxxxxxxxxx.L25: # Loop: vmulsd (%rdx), %xmm0, %xmm0 # Multiply acc by data[i] addq $8, %rdx # Increment data+i cmpq %rax, %rdx # Compare to data+length jne .L25 # If !=, goto Loop其对应的 primitive instructions 及 data-flow diagram 如下:
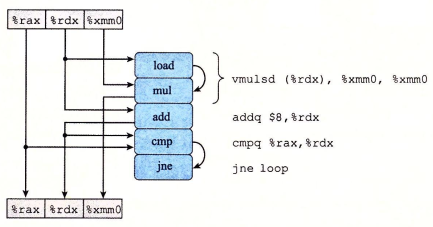
我们能将这个 loop 中使用到的寄存器进行分类:
read-only:只作为这个 iteration 的源值,例如这里是
%rax;write-only:只作为这个 iteration 的目的地,这里没有;
local:这个 iteration 内部使用的寄存器(运算单元随取随用),比如这里的
CC;loop:既作为这个 iteration 的写目的地,又作为下个 iteration 的源值,例如这里的
%rdx、%xmm0;
我们发现,loop 类寄存器的操作链决定了这个 data-flow 的关键路径(因为循环不依赖的寄存器可以并在其他步骤同时执行)。
由此可以将 loop 类寄存器涉及的路径抽取出,根据依赖关系画出新的 data-flow:
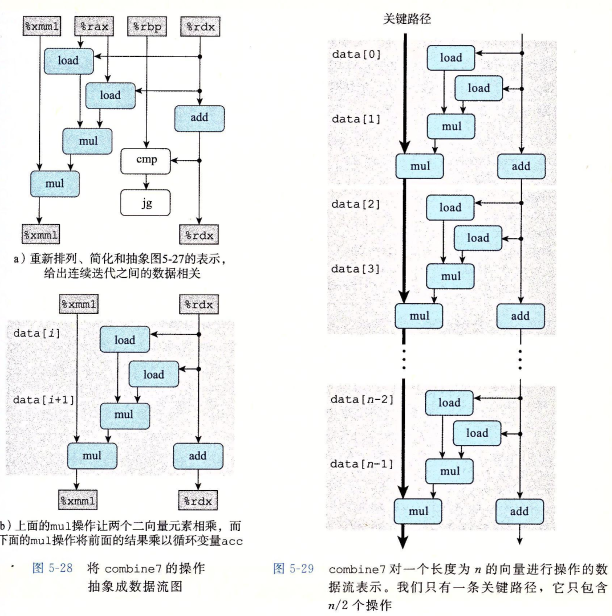
结合实验数据可知,这条链就是限制程序性能的关键。
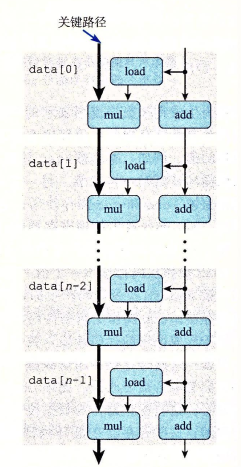
现在我们尝试一些措施将循环 “展开”(unrolling loop),例如每个循环进行两个数组操作:
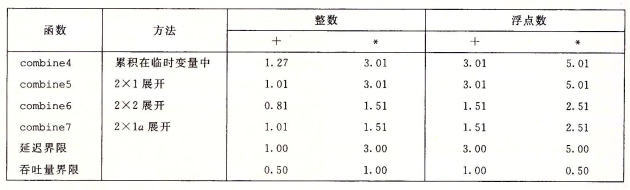
xxxxxxxxxxvoid combine5(vec* v, data_t* dest) { long i; long length = v->len; long limit = length - 1; data_t* d = v->data; data_t t = IDENT; for (i = 0; i < limit; i+=2) t = (t OP d[i]) OP d[i+1]; /* Loop Unrolling (2x1). */ *dest = t;}发现性能结果更加接近 Latency Bound:
分析编译器生成的汇编代码可知,原来在一个周期中的两条运算指令的 Load 被提到前面的位置上,相当于右图:
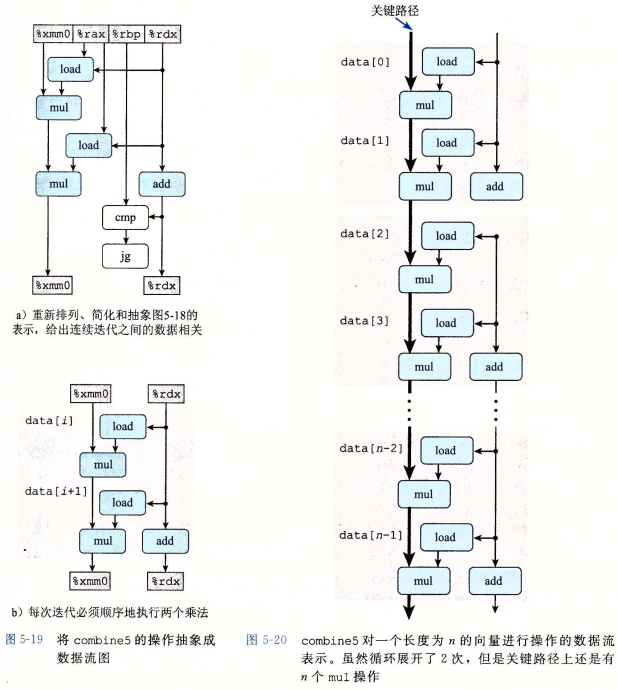
由于这些乘法运算仍然前后依赖,所以尽管我们进行 unrolling loop 来减小每个 iteration 造成的开销,仍然无法超过 latency bound。
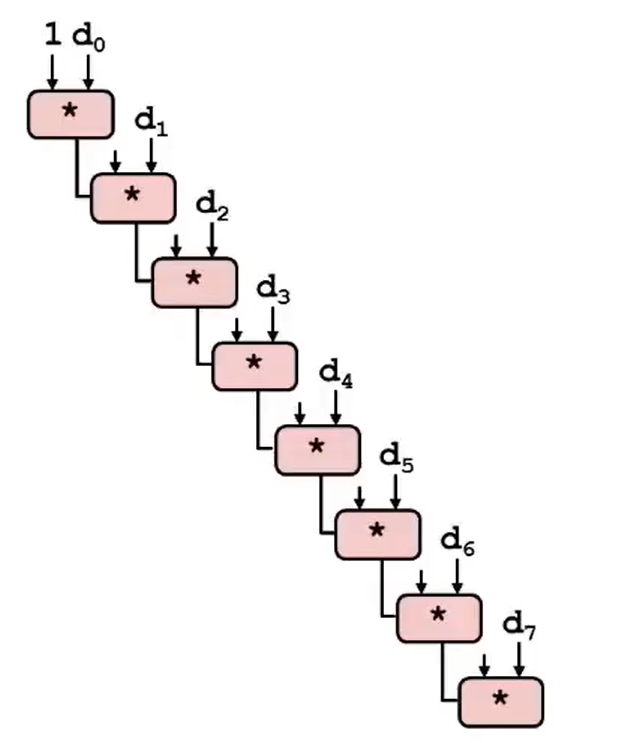
那么,如果我们使用 多个循环累计变量(Separate Accumulator,奇偶元素分开计算,最后合并),就能手动提高并行性:
xxxxxxxxxxvoid combine6(vec* v, data_t* dest) { long i; long length = v->len; long limit = length - 1; data_t* d = v->data; data_t x0 = IDENT; data_t x1 = IDENT; /* Combine 2 elements at a time. */ for (i = 0; i < limit; i+=2) { x0 = x0 OP d[i]; x1 = x1 OP d[i + 1]; } /* Finish any remaining elements. */ for (; i < length; i++) x0 = x0 OP d[i]; *dest = x0 OP x1;}再次绘制 data-flow 图会发现,关键路径变为 2 条,意味着关键路径长度被缩短,解释如右图:
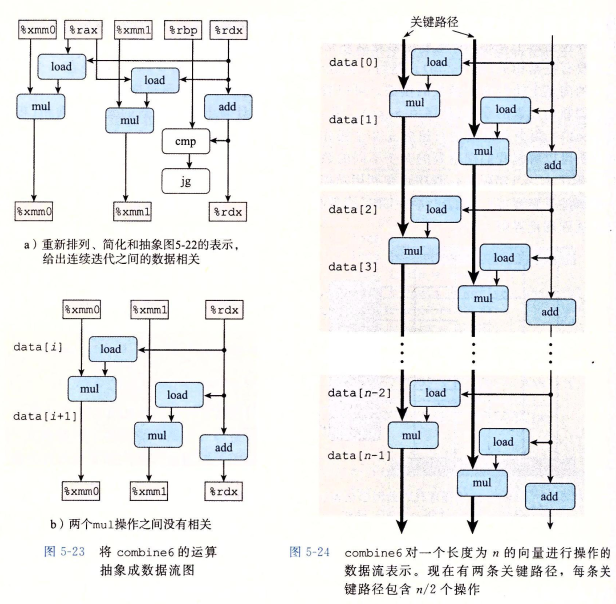
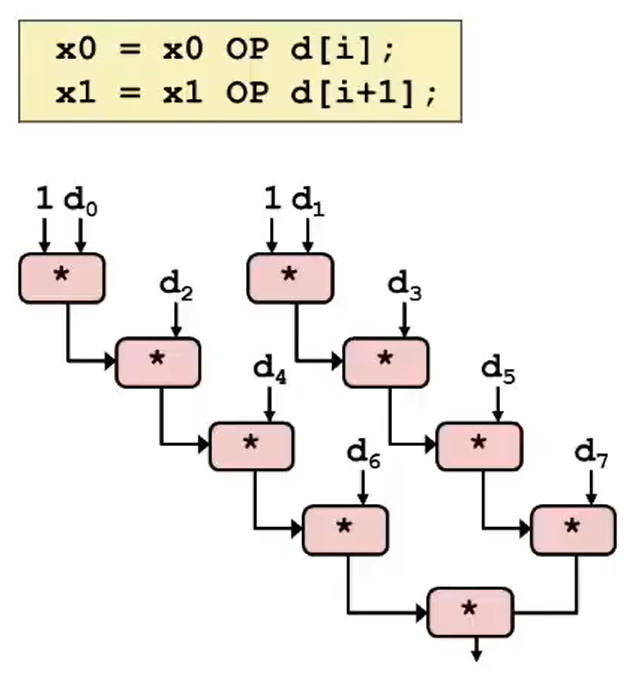
再换一种方法,如果我们更换运算结合的顺序(被称为 Re-association Transformation):
xxxxxxxxxxvoid combine7(vec* v, data_t* dest) { long i; long length = v->len; long limit = length - 1; data_t* d = v->data; data_t t = IDENT; for (i = 0; i < limit; i+=2) t = t OP (d[i] OP d[i+1]); /* re-association */ *dest = t;}我们也能发现,两条乘法指令的依赖关系改变了:每两条乘法指令只有一条在关键路径上:
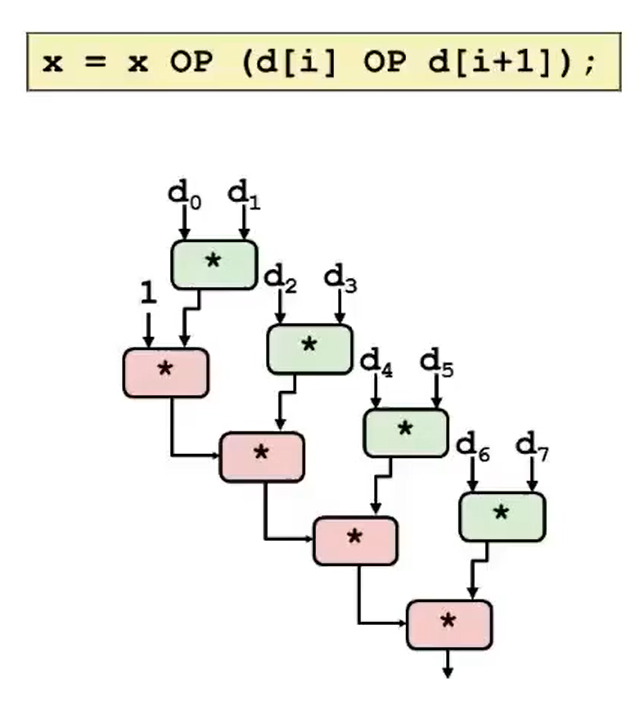
这两种方式(separate accumulator、re-association)都能大幅度缩短关键路径,让程序性能突破 latency 瓶颈,接近吞吐量:
如果 separate accumulator 展开 10 次,就能更大限度利用机器资源。
但是,无论是 unrolling loop,还是 separate accumulator,都有一个界限:register spilling(寄存器溢出)。如果中间步骤展开过多,超过了已有寄存器数量,这时处理器会用内存来代替,反而会降低运行效率。
此外,之前我们提到了尽管整数加法有 4 个器件,但 throughput 不会超过 0.5,是因为 load/store 的约束。而我们之前看到的例子中,load 似乎不在关键路径上(因为之前的 load 只依赖于索引 i)。其实,load/store 操作也会和之前的 multiply 一样成为某些程序的关键路径,例如链表程序:
xxxxxxxxxxtypedef struct ELE { struct ELE *next; long data;} list_ele, *list_ptr;
long list_len(list_ptr ls) { long len = 0; while (ls) { len++; ls = ls->next; } return len;}汇编:
xxxxxxxxxx.L3: addq $1, %rax movq (%rdi), %rdi testq %rdi, %rdi jne .L3这个时候加载的结果决定下一条操作的地址时,load 指令(movq 的其中一个
除了 load,store 也会成为关键路径的一环。来看两个例子:
xxxxxxxxxx// func1void clear_array(long* dest, long n) { long i; for (i = 0; i < n; i++) dest[i] = 0;}
// func2void write_read(long *src, long *dst, long n) { long cnt = n; long val = 0; while (cnt) { *dst = val; val = (*src) + 1; cnt--; }}func1 的 CPE 能达到 1.0,很好解释,是因为 store 暂时不影响寄存器值(前面提到 pending write 到 renaming table),不会产生数据依赖,因此可以完全流水线化,这也是最佳情况(throughput bound)。
但是 func2,如果 src != dst,那么 CPE 约为 1.3;但是如果 src == dst,那么 CPE 上升到 7.3(下降了 6 个 cycles)!这可以用 data-flow 分析出。
先写出汇编代码:
xxxxxxxxxx.L3: movq %rax, (%rsi) movq (%rdi), %rax addq $1, %rax subq $1, %rdx jne .L3movq %rax, (%rsi) 会被分解为两条 primitive instruction:s_addr(计算目标内存地址,由单独的运算单元完成)、s_data(数据 store)。
如果 store 的数据依赖于前一步的 load(read-write dependency),那么根据汇编代码可以画出:
其中
movq
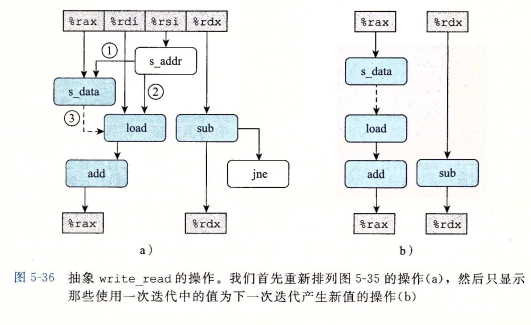
如果 src != dst,那么箭头 3 不存在,关键路径将是 sub(CPE 约 1.3);
如果 src == dst,那么箭头 3 的依赖关系就存在,关键路径就是 s_data -> load -> add(CPE 约 7.3)。
此外,还有一些在机器层面影响性能的其他因素:
12.5.1 Branch Misprediction Recovery
我们在 4.2.2 中提到过,机器层面的分支预测技术(Branch Prediction)就是为了让 CPU 流水线的效率得到充分利用而诞生的。在很多情况下,如果我们不使用条件移动的话,那么在分支预测错误的时候,很有可能整个流水线的指令和数据全部需要重新载入,这将耗费大量的运算资源和时间。
所以第一个思路就是从降低 Branch Misprediction Penalty 方面着手。首先了解一下分支预测技术的大概原理是啥。分支预测技术在早期使用的是简单的 heuristic:向后分支(backwards branches)经常是判断(if),向前分支(forwards branches)经常是循环(loop)。我们可以通过一些算法跟踪这些分支(尤其是循环)的历史行为,如果它经常通过某一分支,那么以后预测该分支的可能性会大一点。
这种预测方法在有些代码中效果显著,但是另一些代码(例如强数据依赖、强随机数据)中效果极差,甚至导致更多的 Branch Misprediction Penalty;
因此接近这个方面问题的可能途径如下:
减少分支结构的数量:
Transform loops(尽量转换、消除不必要的循环)
Unroll loops(下面介绍)
Use Conditional Moves(4.2.2)
使得分支更容易被分支预测器预测
为循环中的数据排序(需要权衡)
尽量避免间接的分支结构(因为间接分支基本上都没有预测依据)
函数指针判断跳转
虚函数运行时判断跳转
这里介绍一下 unroll loops 的思路。unroll loops 就是将循环中的代码成倍数展开,达到均摊 Branch Misprediction Penalty 的目的。同时,这种方法还能为其他的优化方法创造条件(例如 CSE、Code Motion、Scheduling 等)。方法的示例如下:
xxxxxxxxxxfor (size_t i = 0; i < nelts; i++) A[i] = B[i]*k + C[i];
// 改为:for (size_t i = 0; i < nelts - 4; i += 4) { A[i ] = B[i ]*k + C[i ]; A[i+1] = B[i+1]*k + C[i+1]; A[i+2] = B[i+2]*k + C[i+2]; A[i+3] = B[i+3]*k + C[i+3];}但这种方法有两个明显的缺陷,一是如果过度展开,会增长代码长度,同样会影响性能。所以需要根据数据量进行权衡;二是在某些循环中,依赖 i 进行判断的场合,这种展开就不适用了。
12.5.2 Scheduling
在上面的流程中,除了 Branch Misprediction Penalty,还有一种会影响 CPU 运算性能的情况——数据读取和写入。I/O 操作的开销一直是处理器设计者头疼的地方,尽管现在有高速缓存器来进行弥补,但数据的存取在运算过程中还是尽量能少就少。
因此,将源代码中读取、写入的部分和运算的部分分开(最好在运算前就读入所有必需的数据、在所有运算后才写入必要的数据),能够让处理器的性能发挥到最大(这个优化也可以由编译器完成)。这种方法就称为代码调度(Scheduling)。
例如 12.5.1 中的代码还可以继续优化:
xxxxxxxxxxfor (size_t i = 0; i < nelts - 4; i += 4) { B0 = B[i]; B1 = B[i + 1]; B2 = B[i + 2]; B3 = B[i + 3]; C0 = C[i]; C1 = C[i + 1]; C2 = C[i + 2]; C3 = C[i + 3]; A[i ] = B0*k + C0; A[i+1] = B1*k + C1; A[i+2] = B2*k + C2; A[i+3] = B3*k + C3;}同样,这样的操作对于有些情况也不适用,比如在一些业务逻辑下,读取操作必须在一群算数运算之间出现。
12.6 Summary
本章讲述了一些程序优化的基本思路,主要从两个方向描述。
一个是与机器无关方向的优化小技巧,而这些技巧也常常会内置在编译器中,成为编译工作的一个部分。它们大致可以分为以下几类:
局部的优化:例如 常数折叠、计算强度减小(通过更换运算符实现)、死代码剔除、局部的相近表达式复用消除;
全局的优化:例如 循环结构转换、代码移动(减少不必要的运算)、内联化、全局的相近表达式复用消除;
在这个方面,我们考虑了相反的情况——什么样的编码会阻碍编译器帮助我们进行上面的优化。
Procedure Calls:我们应该在代码设计时,充分考虑函数调用的位置对于性能影响;
Memory Alias:尤其是在循环结构中,多使用局部变量暂存中间结果,或者使用更严格的关键字;
这都在提醒我们编码时,能尽早确定的定值,尽量存在局部变量中,以防编译器认为中间存在变数,而不敢于进行优化。
另一个是与具体机器有关方向的优化技巧(但是目前世界上的机器种类就这些,所以理论上也有一定的普适性,例如 ARM 架构和 x86 架构都能使用这种优化来提升性能),编译器不一定会帮你做这些优化,这是因为这些方法有着各自的局限性。
我们分析了现代 CPU 的结构特性,找到了 3 处可以进行优化的地方,一个是分支预测的部分,一个是代码中的 I/O 调度,另一个是运算顺序和方法。
首先我们了解了分支预测器的原理和性质,我们发现想要弥补 Branch Misprediction Penalty,就需要从两个方面入手:
让它少预测点,就少错一点(减少分支结构)。这方面的方法大致有 循环转换、unrolling loops 和 conditional moves(回想之前的 General Condition Translation);
提升它预测的正确率。依从分支预测器的原理,我们可以让每次产生的分支判断的结果有迹可循。总的来说,我们可以通过为需要的判断数据排序(局限性强)、减少编码一些难以预测的结构(例如函数指针判断、虚函数)。
在 I/O 调度方面我们发现,CPU 频繁地从高速缓存器中读入和写出数据也会降低程序性能,因此在编码过程中写出能够让汇编码中读内存次数越少的源码越好。因此,这里的重要建议是将源代码中读取、写入的部分和运算的部分分开(最好在运算前就读入所有必需的数据、在所有运算后才写入必要的数据)。
本章最后以一个计算例子说明,通过分析关键路径,使用 Re-association Transformation、Separate Accumulator 来让更多的乘法运算并行起来。
当然,当我们利用以上技术(例如 loop unrolling)优化到一定程度后,其他方面的问题就变成了关键路径上的问题。例如 unrolling 过多时,发生 register spilling(寄存器用完了,开始使用内存)影响性能。

最后介绍一个优化的规则:Amdahl‘s Law
当能优化的部分优化到极限后,加速比极限为
也就是说,我们应该在优化时找关键路径、找 hot spot(热点位置)。这就是 profiling。
当今的 profiling 工具有哪些?Unix 上有 gprof、perf,它们的思路是 random sampling,间隔一定时间进行指令中断,统计函数执行的次数、统计当前调用栈(可以发现调用关系、递归情况),用频率代表出现总时长占比。