Chapter 8. Scheduler in OSStrategy 1: FIFO(FCFS,First Come First Served)Strategy 2 : SJF(Shortest Job First)Strategy 3 : STCF(Shortest Time-to-Completion First)Strategy 4 : Round Robin(时间片轮转)Strategy 5 : Overlap when performing I/O operationStrategy 6 : Multi-Level Feedback Queue Scheduler(MLFQ)Chapter 9. Y86-64: A self-defined ISA9.1 Y86-64 Processor State9.2 Y86-64 Instructions9.2.1 程序终止指令类 halt:0x009.2.2 空指令类 nop:0x109.2.3 寄存器移动指令类9.2.4 直接量-寄存器移动指令类9.2.5 寄存器-内存移动指令类9.2.6 内存-寄存器移动指令类9.2.7 运算指令类9.2.8 跳转指令类9.2.9 调用指令类9.2.10 返回指令类 ret:0x909.2.11 寄存器进栈指令类9.2.12 寄存器出栈指令类9.3 Y86-64 Program Stack9.4 半章小结9.5 CPU Design: CISC vs RISC9.5 CPU Design: Logic Design & HCLHardware Control Language SyntaxArithmetic Logic Unit DesignRegister(Storage) Design9.6 CPU Design: SEQ General9.6.1 General Principle9.6.2 Basic Framework9.6.3 Describe Assembly with Framework9.6.4 Advantages & Disadvantages9.7 Principles of Pipeline9.7.1 Time Analysis: SEQ9.7.2 Time Analysis: N-Way-PipelinedLimitation 1: Nonuniform DelaysLimitation 2: Register OverheadLimitation 3: Data Dependency & Data HazardLimitation 4: Control Dependency9.8 Pipeline Implementation9.8.1 Hardware9.8.2 Resolve Data Hazard: Data Forwarding & Stalling9.8.3 Resolve Control Hazard Part Ⅰ: Predicting the PC9.8.4 Resolve Control Hazard Part Ⅱ: Fix Wrong Predictions9.8.5 Exception Handling in Pipeline9.8.5 Final Implementation9.8.6 Performance Analysis: Metrics
Chapter 8. Scheduler in OS
为操作系统的调度环境作出假设:
Each job runs for the same amount of time
All jobs arrive at the same time
Once started, each job runs to completion
All jobs only use the CPU
i.e., they perform no I/O
The run-time of each job is known
引入调度优劣衡量指标:周转时间,
Strategy 1: FIFO(FCFS,First Come First Served)
Implementation: queue;
消除假设 1:若短时任务排在长时任务之后,则平均周转时间效果很差;
Strategy 2 : SJF(Shortest Job First)
内容:对于同时到达的任务,优先选择总时长小的任务。
作用:(应对假设 1 的消除)缓解了短时任务排在长时任务之后所造成的较差的平均周转时间;
消除假设 2:不同任务到达的时间不一样。如果短时任务出现在长时任务开始后的很短的时间内,那么平均周转时间也很差(一般没有竞争抢占机制,具体请看题目要求);
Strategy 3 : STCF(Shortest Time-to-Completion First)
内容和作用:(应对假设 2 的消除)竞争抢占机制(preemptive),晚到达的短时任务如果执行剩余时间短于长时任务的剩余时间,则进行抢占切换;
添加一个衡量标准:Response Time(反应时间);
the time from when the job arrives in a system to the first time it is scheduled;
STCF 在 Response Time 中,如果恰好各个任务消耗的时间相近,它们无法抢占,但是抢占时间会很大;
Strategy 4 : Round Robin(时间片轮转)
作用:(提升 Response Time)设计时间片(Time slice),每个任务最多只能执行一段时间的代码,超时则切换到其他进程,使用上面的切换策略;
注意点:合理设计时间片长度(10ms),防止频繁的切换操作占用大量资源(switching cost);
与 SJF 策略比较:有利有弊;
消除假设 4:任务可能存在 I/O 操作,耗时操作导致该进程很多时间片空闲;
Strategy 5 : Overlap when performing I/O operation
内容:当发生 I/O 操作时,应用必然调用系统调用,操作系统可以将此任务 block 进入 stopped 状态,并进行 context switch;
作用:在进行 I/O 操作时发生 switch,充分利用 I/O 操作的空隙,进行有效的 overlap;
消除假设 5:任务的运转时间未知,相当于无法比较任务是短时任务还是长时任务(例如交互式任务);
Strategy 6 : Multi-Level Feedback Queue Scheduler(MLFQ)
作用:1. 优化未知任务时长(without a priority knowledge of job length)情况下的周转时间;2. 最小化响应时间(在用户交互式应用中很重要);
如何在没有先验知识的情况下,做出最合适的任务调度?
Learning from history:从系统运行程序的特性中做出猜测(类似分支预测器);
the multi-level feedback queue;
优先级预测队列策略:
Rule 1:任务队列使用多个队列,每个队列的优先级不同,同样队列中的任务优先级相同,优先级高的队列中的任务请求资源时,先于优先级低的任务;
Rule 2:如果两个任务处于同一优先级,则二者使用 Round Robin 策略;
接下来需要考虑优先级的设置和改变问题。
考虑到 workload 同时含有 交互式任务(interactive jobs,CPU 使用时间一般很短,例如用户交互)和 CPU 密集型任务(CPU-bound,CPU 使用时间一般很长,例如矩阵计算,一般对 response time 要求不高);
Rule 3:当一个任务进入系统任务队列时,最先总是放到最高优先级;
Rule 4a:如果一个任务耗尽了一个周期中的所有时间片,那么 CPU 可以认为这个任务更有可能是个 CPU-bound job,那么先降低一个优先级,直到最低优先级;
Rule 4b:如果一个任务没有耗尽一个周期的时间片就释放 CPU 资源,那么 CPU 可以认为这个任务更有可能是一个 interactive job,那么保持在当前优先级;
缺陷:
Starvation:如果有非常多的 interactive jobs 同时运行在最高优先级,那么很有可能导致最低优先级的 CPU-bound jobs 始终无法得到 CPU 资源;
Gaming scheduler attack:一些恶意程序可能利用这个策略,设计占用大部分时间片内容,但在结束前释放 CPU 资源,这样会一直保持最高优先级,并且妨碍其他程序运行;
Programs may change its behavior overtime:一些任务可能在 interactive 与 CPU-bound 的特性间相互转换;
改进
Rule 5(Priority Boost):当某个时间周期 S 后,将所有任务都移动到最高优先级;
好处 1:解决缺陷 1,消除 starvation 现象,保证每个进程都会被调度到;
好处 2:解决缺陷 3,方便 MLFQ 重新评定各个进程的 priority(保证 interactive / CPU-bound 相互转换的程序被分配到合适的优先级);
Refined Rule 4(Better Accounting):任务在当前优先级中的全部运行时间累积计算,以累积的时间长短作为是否降低优先级的评判标准;
好处:解决缺陷 2,故意保留一个时间片剩余时间的程序,如果总 CPU 用时很长,也会被降低优先级;
具体实现:MLFQ 具体的参数是怎样的?怎么落实它的参数?
MLFQ 应该有几个队列(几个优先级)?
时间片长短的设计:每个优先级的任务的时间片长度应该多长?
进行 Priority Boost 的频率应该如何?(既能保证不过度更新浪费资源,又能保证减小 starvation 和 changes in behavior 导致运行效率减慢的可能?)
Tuning 与 微调
针对以上 tuning MLFQ 使其最大化系统性能的过程没有一个固定的最优解。大多数情况需要进行调参、凭借经验取定。
不过有一些通识的点,满足这些点的参数设计一定能够更好提升 MLFQ 的性能:
对于高优先级的任务,分配给其的时间片时间应该更短些为佳;
它们通常较少地使用 CPU 资源,可能是 interactive 类型地任务,切换得更频繁;
对于低优先级的任务,分配给其的时间片时间应该更长些为佳;
它们通常是 CPU-bound 类型任务,分配更长的时间片能够更好地完成任务;
Chapter 9. Y86-64: A self-defined ISA
Y86-64 是由 CMU 教授设计,SJTU 老师改进的一种教学用指令集架构,实际生产中没有处理器使用此架构。
学习它的目的是 更好地了解 CPU 与 ISA 间的关系和实现思路,剥离开复杂的细节,从抽象角度帮助我们理解 CPU 与 ISA、软件之间的交融。
最后,为我们自己设计模拟器(simulator)、汇编器(assembler)、计算机处理器(CPU)打下基础。
9.1 Y86-64 Processor State
我们定义 Y86-64 架构下,用于保存处理器状态(或者说程序执行状态)的由以下部件构成:
15 只寄存器(Registers),每个大小 64 bits(除了不存在
%r15,其他与 x86-64 相同);每个寄存器有独立且唯一的 4-bit ID:
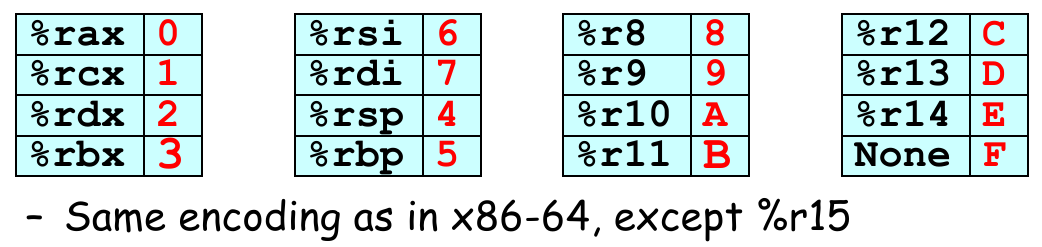
0xF代表不使用寄存器(None),在 Y86-64 中有特殊用途。程序计数器(Program Counter,PC),64-bit size;
Conditional Codes,共 3 个,每个 1-bit(比 x86-64 少 CarryFlag 等 5 个 CC);
OF: Overflow Flag,当且仅当上一次运算出现溢出时设置该位;ZF: Zero Flag,当且仅当上一次运算结果为 0 时设置该位;SF:Negative(Signed)Flag,当且仅当上一次运算结果为负数时设置该位;
Status Code:记录程序运行状态的寄存器,存放一些有含义的数;
AOK: the program is executing normally (Continue).HLT: the processor has executed a halt instruction (Normal exit).ADR: the processor attempted to access an invalid memory address (Segmentation Fault).INS: an invalid instruction code has been encountered (IoT).
Memory:程序内存。简单定义为使用 Byte 索引的存储数组。使用小端序(little-endian)存储;
9.2 Y86-64 Instructions
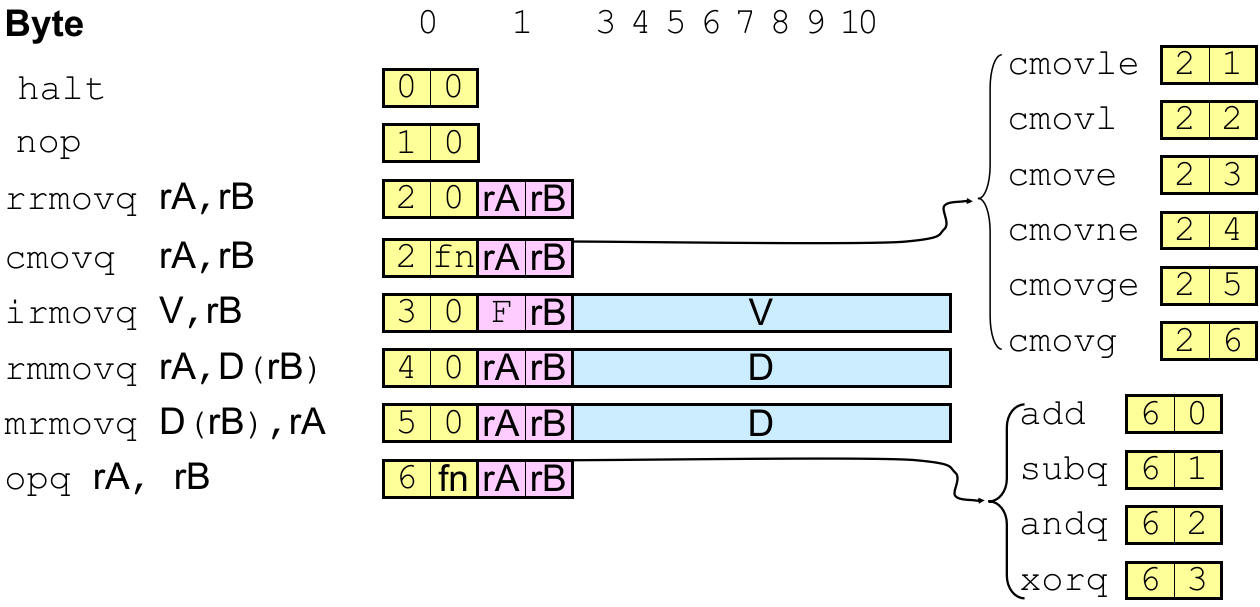
Y86-64 下定义了 12 类处理器指令:

Tips 1. Generic Form & Encoded Representation
Tips 2. Instruction Code (first 4 bits) & Function Code (second 4 bits)
9.2.1 程序终止指令类 halt:0x00
9.2.2 空指令类 nop:0x10
9.2.3 寄存器移动指令类
rrmovq rA, rB:0x20 0x<rA><rB>(看作无条件的 conditional move)
cmov<XX> rA, rB:0x2<X> 0x<rA><rB>
9.2.4 直接量-寄存器移动指令类
irmovq V, rB:0x30 0xF<rB> <V>(2+8 bytes)
9.2.5 寄存器-内存移动指令类
rmmovq rA, D(rB):0x40 0x<rA><rB> <D>(2+8 bytes)
9.2.6 内存-寄存器移动指令类
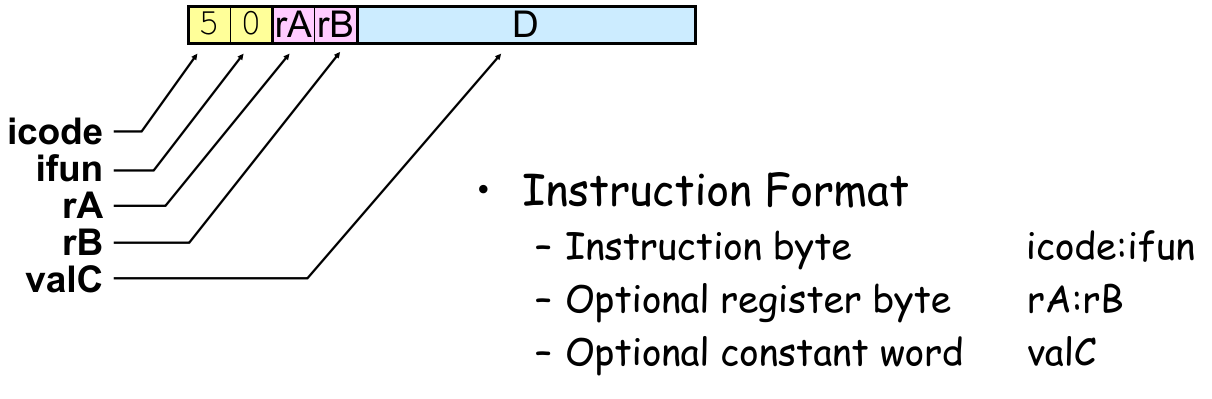
mrmovq D(rB), rA:0x50 0x<rA><rB> <D>(2+8 bytes)
⚠⚠ 在 encoded representation 中,用于存储内存基地址的寄存器(在 9.2.5 和 9.2.6 中都用 rB 表示)ID 必须在目标寄存器 ID 之后! ⚠⚠
9.2.7 运算指令类
<OP>q rA, rB:0x6<X> 0x<rA><rB>
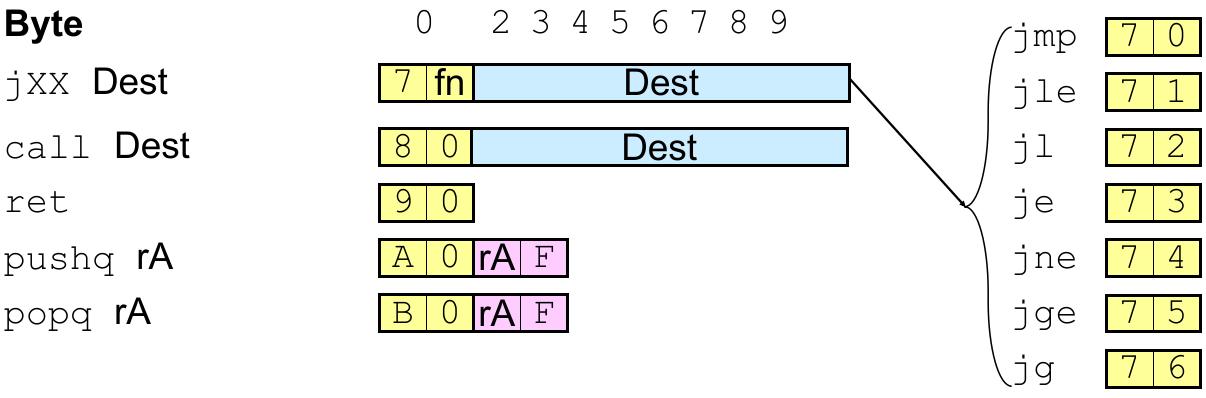
9.2.8 跳转指令类
j<XX> Dst:0x7<X> <Dst>(1+8 bytes)
不支持直接跳转的 PC-relative 表示法,下同。
9.2.9 调用指令类
call Dst:0x80 <Dst> (1+8 bytes)
9.2.10 返回指令类 ret:0x90
9.2.11 寄存器进栈指令类
pushq rA:0xA0 0x<rA>F
(在 9.3 中详细介绍)
9.2.12 寄存器出栈指令类
popq rA:0xB0 0x<rA>F
我们根据上面的定义总结出几点有价值的信息:
Y86-64 指令集是比 x86-64 更精简的变长指令集,但每类指令内的长度固定。
因此,机器在读指令的第一个 byte 后,就能根据指令种类确定当前指令的长度。
条件移动指令存在于寄存器移动指令类,因为它们都是在寄存器间移动数据,它们共享前 4-bit Instruction Code;
只有运算指令类可以隐式改变 Conditional Codes、运算指令也只能操作寄存器,直接量都不行;
9.3 Y86-64 Program Stack
Y86-64 架构下的程序栈与 x86-64 相近,遵循相似的 ABI:
栈地址从高地址向低地址增长;
栈在 Y86-64 中也用于处理 Procedure Call 等工作;
%rsp寄存器仍然用作保存当前栈顶地址;
此外,在 Y86-64 中的两种对栈操作的指令:
pushq rA(0xA0 0x<rA>F):先减小
%rsp(8);再将
rA中的数据存放到%rsp所指的位置;例外:如果
pushq %rsp,那么将先存放旧的%rsp,再减小%rsp;
popq rA(0xB0 0x<rA>F):先从
%rsp指向的地址读取数据到rA;再增加
%rsp(8);例外:如果
popq %rsp,那么先增加%rsp,再读取原来位置的数据;
⚠⚠ 注意,无论是 pushq 还是 popq(读出还是写入)寄存器,寄存器都在 Encoded Representation 的 Function Code 的前 4-bit 内容 ⚠⚠
总之注意三个地方的指令的编写位置:
在寄存器 - 内存间转移的 Load-Store 指令的
rA和rB位置;操作栈指令的
rA与F的位置始终是寄存器位于 Function Code first 4-bit;在直接量 - 寄存器转移的指令中,Function Code 却遵循
F<rA>的规律;
9.4 半章小结


9.5 CPU Design: CISC vs RISC
| TYPE | CISC | Early RISC |
|---|---|---|
| 指令数 | 极多 | <100 |
| 指令耗时 | 差距较大 | 都很少 |
| 指令长度 | 可变长 | 定长 |
| 指令表示 | 一种运算有多种指令 | 仅表示运算最小完备集 |
| load & store | 算术、逻辑运算允许内存-寄存器间 | 算术、逻辑运算仅允许寄存器间 |
| 机器级细节 | hidden | exposed |
| 条件判断 | Conditional Codes | Test Instruction + Normal Registers |
| procedure call | 少量使用 registers,集中在栈上传递 | 大多数交给 registers |
根据上面的线索,我们能总结出 Early RISC 相对于 CISC 的优劣势:
优势在于能够高效结合 Pipeline 技术、编译器开发更简单、更容易学习和通过它理解指令集架构等等;
劣势在于同一高级语言编译得到的更多汇编指令、暴露机器级细节破坏了 ISA 的封装性和程序兼容性等等;
如今,新指令集没法明确地分出它属于哪一种,它们会借鉴两者的特点和原则;
例如这里的 Y86-64:
既采用了 CISC 原则: Conditional Codes、变长指令;
又采用了 RISC 原则: Load/Store Arch、通过寄存器完成 Procedure Call;
9.5 CPU Design: Logic Design & HCL
复习:数字电子电路基础 - 组合时序逻辑电路。例如:
多路相等比较器;
多路选择器(
Multiplexor);
Hardware Control Language Syntax
支持普通逻辑运算符;
选择器:
Out = [s: A;1: B: // Default]
Arithmetic Logic Unit Design
Input: X (8 bytes)、Y(8 bytes);
Conditional Codes:
ZF / OF / SF;Output: Z(8 bytes);
Register(Storage) Design
Latch & Flip-flop
这里只需要知道:某种锁存器在 clock 上升沿写入输入的信号、仅输出写入的信号;
Register File
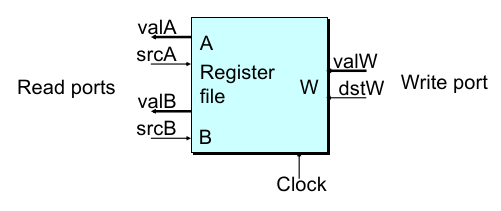
特征:两个读端口(因为指令存在双寄存器操作),一个写端口,时钟引脚控制读写时机;
srcA/srcB表示读取的 register ID(4-bit),valA/valB表示对应的 register 中的值;写端口dstW表示要写入的 register ID,而valW表示要写入的值;Memory
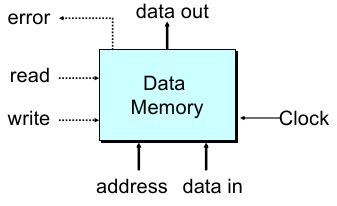
特征:读写端口各一个(因为不允许从内存到内存的操作),
error端口提示非法地址等错误,read、write端口决定当前是读还是写(不会同时出现),时钟引脚控制读写周期;
9.6 CPU Design: SEQ General
本节我们在前几节电路基础、Y86-64 ISA 理论基础上构建 Y86-64 微架构,实现串行(sequential)处理器。
icode不在 0 ~ B 间说明非法指令;
ifun也要检查,不在指令列表中的也需要报错;但
icode:ifunc以后的内容 “编码错误” 不是非法指令,因为 CPU 能够识别,应该属于软件层面的错误。
9.6.1 General Principle
首先要知道,一个汇编指令需要很多步电路操作,所以我们设计时应该遵循如下原则:
采用 Multi-stages Design,即分几步来完成一个汇编指令,思想类似函数包装;
为了更好地利用硬件,不应该为每个指令设计一个电路,而是考虑如何让所有指令共用一套电路。
9.6.2 Basic Framework
本节是上完课后总结的内容,叙述顺序进行了综合。
根据前人的经验,Y86-64 串行处理器设计的 stage 应该分为这几个:
Fetch:从指令内存中读取指令;
该步允许使用的 微架构内容 如下:
值(
var):PC:当前 PC 的值;icode:ifun:组合读入的 Instruction Code & Function Code;rA:rB:组合读入的 寄存器 ID 值存放变量;valC:约定俗成认为是常数存放变量,存放 Displacement、Destination、Immediate;valP:约定俗成认为是下一个完整指令的地址,一般所有指令都要操作这个变量;
表达式(
exp):
Decode:将寄存器值读到变量值中;
该步允许使用的 微架构内容 如下:
值(
var):rA、rB:上步取得的寄存器 ID;valA、valB:新的用于存放寄存器内值的var;%rsp:该步允许直接使用%rsp指代该寄存器内的值;
表达式(
exp):valA/varB <- R[rA/rB/%rsp]:从指定寄存器中取值到某个变量中;
Execute:进行计算地址 / 值的操作;
该步允许使用的 微架构内容 如下:
值(
var):valE:约定俗成存放 ALU 计算结果的var;CC:Condition Code;Cnd:存放本次 Condition Flag(条件是否成立信息)的var;ifun:此处用于判断 Function Code 的条件语义,例如确定CC、确定运算符;
表达式(
exp):valE <- valB/0 + valA/valC/8/-8:将运算结果写到valE中,至于为什么左边是valB/0,右边是valA/valC/8/-8,主要是考虑所有指令后,为了最大程度上复用电路的主意;valE <- valB ifun valA:表示按ifun选择,将valB、valA运算后赋给valE(显然这个表达式是专门为了opq指令的);Set CC:根据运算结果设置 Condition Codes,在 Y86-64 中,只有opq可以使用;Cnd <- Cond(CC, ifun):表示按ifun预期条件、CC当前条件,将是否应该进行的 Condition Flag 赋给Cnd;
Memory:向内存中读 / 写数据;
该步允许使用的 微架构内容 如下:
值(
var):valM:约定俗成用于存放从内存中取出的值;valA / valE / valP:根据代码逻辑可能会用到的var(也是考虑所有指令后,为了最大程度上复用电路的主意);
表达式(
exp):varM中;
Write Back:向寄存器写入数据;
该步允许使用的 微架构内容 如下:
值(
var):varE / varM:根据代码逻辑可能会用到的var(也是考虑所有指令后,为了最大程度上复用电路的主意);rA / rB:本步想要写入寄存器,必须要用到寄存器 ID 值;Cnd:可能会根据 Condition Flag 进行不同动作(例如cmovXX类指令);%rsp:本步允许直接使用此符号指代该寄存器;
表达式(
exp):R[rA/rB/%rsp] <- valE/valM:将指定位置的值赋给指定的寄存器;Cnd ? exp : -:根据 Condition Flag 决定是否执行 本步允许的表达式exp;
PC Update:更新 PC;
该步允许使用的 微架构内容 如下:
值(
var):valP / valC / valM:根据代码逻辑可能会用到的var(也是考虑所有指令后,为了最大程度上复用电路的主意);PC:本步的目的就是改变它;Cnd:可能会用 Condition Flag 决定赋给PC的内容(例如jXX类指令);
表达式(
exp):PC <- var:将各种本步允许的var传给PC;PC <- Cnd ? valC : valP:根据 Condition Flag 决定将何种var赋给PC;
9.6.3 Describe Assembly with Framework
有了上面的知识,我们可以把各个指令对应的微架构过程描述出来了。
rrmovq rA, rB:
x# Fetchicode:ifun <- M1[PC]rA:rB <- M1[PC + 1]valP <- PC + 2# DecodevalA <- R[rA]# ExecutevalE <- 0 + valA // Save line in Write Back (We shouldn't add "valB <- R[rA]")# MemoryNONE# Write BackR[rB] <- valE // No valA in Write Back# PC UpdatePC <- valP
cmovXX rA, rB:
xxxxxxxxxx# Fetchicode:ifun <- M1[PC]rA:rB <- M1[PC + 1]valP <- PC + 2# DecodevalA <- R[rA]# ExecutevalE <- 0 + valA // Save line in Write Back (We can't add "valB <- R[rA]")Cnd <- Cond(CC, ifun)# MemoryNONE# Write BackCnd ? R[rB] <- valE : - // No valA in Write Back# PC UpdatePC <- valP
irmovq V, rB:
xxxxxxxxxx# Fetchicode:ifun <- M1[PC]rA:rB <- M1[PC + 1]valC <- M8[PC + 2]valP <- PC + 10# DecodeNONE# ExecutevalE <- 0 + valC // Save line in Write Back# MemoryNONE# Write BackR[rB] <- valE // No valC in Write Back# PC UpdatePC <- valP
rmmovq rA, D(rB):
xxxxxxxxxx# Fetchicode:ifun <- M1[PC]rA:rB <- M1[PC + 1]valC <- M8[PC + 2]valP <- PC + 10# DecodevalA <- R[rA]valB <- R[rB]# ExecutevalE <- valB + valC# MemoryM8[valE] <- valA# Write BackNONE# PC UpdatePC <- valP
mrmovq D(rB), rA:
xxxxxxxxxx# Fetchicode:ifun <- M1[PC]rA:rB <- M1[PC + 1]valC <- M8[PC + 2]valP <- PC + 10# DecodevalB <- R[rB]# ExecutevalE <- valB + valC# MemoryvalM <- M8[valE]# Write BackR[rA] <- valM# PC UpdatePC <- valP
opq rA, rB:
xxxxxxxxxx# Fetchicode:ifun <- M1[PC]rA:rB <- M1[PC + 1]valP <- PC + 2# DecodevalA <- R[rA]valB <- R[rB]# ExecutevalE <- valB ifun valASet CC# MemoryNONE# Write BackR[rB] <- valE# PC UpdatePC <- valP
jXX Dest:
xxxxxxxxxx# Fetchicode:ifun <- M1[PC]valC <- M8[PC + 1]valP <- PC + 9# DecodeNONE# ExecuteCnd <- Cond(CC, ifun)# MemoryNONE# Write BackNONE# PC UpdateCnd ? PC <- valC : valP
call Dest:
xxxxxxxxxx# Fetchicode:ifun <- M1[PC]valC <- M8[PC + 1]valP <- PC + 9# DecodevalB <- R[%rsp]# ExecutevalE <- valB + -8# MemoryM8[valE] <- valP# Write BackR[%rsp] <- valE# PC UpdatePC <- valC
ret:
xxxxxxxxxx# Fetchicode:ifun <- M1[PC]# DecodevalA <- R[%rsp] // Save line in MemoryvalB <- R[%rsp]# ExecutevalE <- valB + 8# MemoryvalM <- M8[valA] // No valB in Memory# Write BackR[%rsp] <- valE# PC UpdatePC <- valM
pushq rA:
xxxxxxxxxx# Fetchicode:ifun <- M1[PC]rA:rB <- M1[PC + 1]valP <- PC + 2# DecodevalA <- R[rA]valB <- R[%rsp]# ExecutevalE <- valB + -8# MemoryM8[valE] <- valA# Write BackR[%rsp] <- valE# PC UpdatePC <- valP
popq rA:
xxxxxxxxxx# Fetchicode:ifun <- M1[PC]rA:rB <- M1[PC + 1]valP <- PC + 2# DecodevalA <- R[%rsp] // save line in MemoryvalB <- R[%rsp]# ExecutevalE <- valB + 8# MemoryvalM <- M8[valA] // No valB in Memory# Write BackR[%rsp] <- valER[rA] <- valM# PC UpdatePC <- valP
其中有几个要点需要着重掌握:
Memory 中化简了
valB,Write Back 中化简了valA和valC;popq的 Write Back Stage 要保证R[rA] <- valM在R[%rsp] <- valE之后执行并覆盖;电路的结果是充满管线之间的,但是只有时钟上升延才会被写入;
这能解释为什么在
opq rA, rB的 Execute Stage 中,前一步的运算不会影响到Set CC:一个汇编指令执行在一个时钟周期内,一定不会相互影响。
再总结一下以上各个 Stage 实际用到的值情况:
9.6.4 Advantages & Disadvantages
简单,容易实现;
指令无法设计复杂,否则耽误其他指令时间(快指令 等 慢指令);
电路 propagate 需要时间,导致时钟周期无法很快,进而注定了 SEQ 处理器的速度不会很快(前 stage 等 后 stage);
9.7 Principles of Pipeline
Some Ideas:
Multi-Stage Design:和串行处理器的思路一样,分多个独立的 Stage 完成一个 Process;
Move objects through stages in sequence;
At any given times, multiple objects being processed;
我们定义:
从头至尾执行一条指令所需的时间(不讨论 capacity),称为这条指令的 延迟(latency);
单位时间内完成指令的数量(讨论了 capacity),称这个流水线的 吞吐量(throughput),通常的计算方法是 1 / 时钟周期长度 / 承载量(这里 “时钟周期长度” 会受到流水线分级方法的影响);
吞吐量常用单位是
GIPS(每秒千兆条),可以用每 1 ns 内执行的指令数量进行计算。
9.7.1 Time Analysis: SEQ
从之前的串行处理器开始讨论,一条指令执行的耗时情况如下:
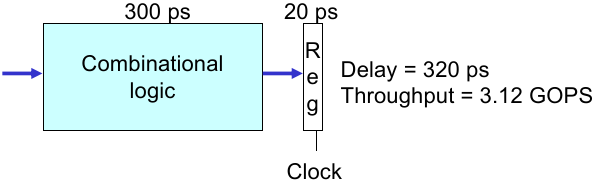
组合逻辑电路在输入后,等到电路稳定需要 300 ps(记作 “Computation Delay”);
时钟上升沿到达后,需要 20 ps 才能确保写入 registers(记作 “Save Delay”);
因此这种情况下,每个时钟周期至少 320 ps;
9.7.2 Time Analysis: N-Way-Pipelined
我们考虑如下流水线的思想,将组合逻辑电路拆成多个 stage,以便使用流水线:
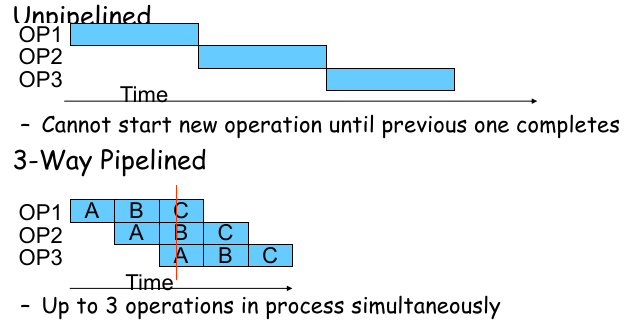
如果将组合逻辑电路按照流水线的 ideas,变为 3-Way Pipelined:
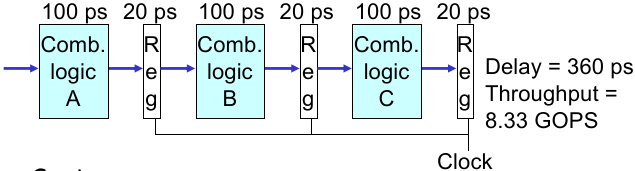
将组合逻辑电路拆分为 3 个独立的 stage(每个 stage 平均 latency 100 ps);
虽然 latency 略微增长(由于寄存器状态切换的时间开销):360 ps,但 Throughput 提升了;
因为根据流水线思想,在一个 operation 穿过一个 stage 后,其他部分就空闲下来,并且状态已经进入中间状态 registers,因此下一条指令可以立即进入;
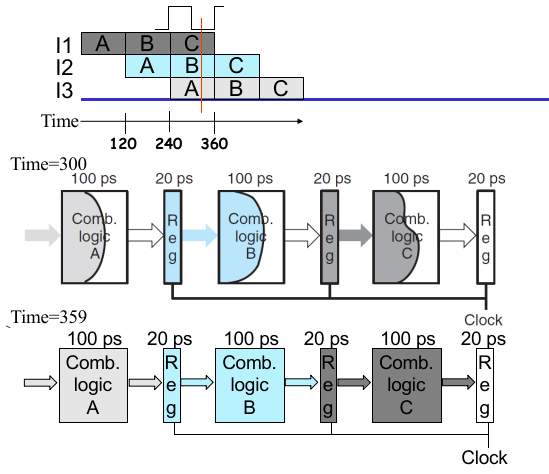
Limitation 1: Nonuniform Delays
但是,我们没有考虑一个重要问题:逻辑电路划分为 stage 后,每个 stage 的 Delay 时长不一致(Nonuniform Delays)。
这个时候,有些耗时短的 stage 就要等待耗时长的 stage,例如:
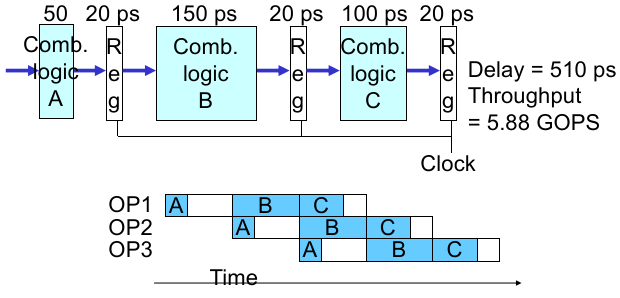
这样我们考虑几个问题:
根据组合逻辑电路的设计,有些部分是无法继续切分的,这就告诉我们无法无限向下切分 stage。假设有一种设计如下,各个部分不能继续切分:
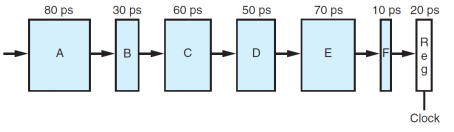
那么,考虑不同 stage 数量下的 CPU 情况:
当 stage 数量为 2 时,最好的划分方法是
A B C | D E F,这个时候总latency = 190 * 2 ps = 380 ps,throughput = 1 / 190 * 1000 GIPS = 5.26 GIPS;当 stage 数量为 3 时,最好的划分方法是
A B | C D | E F,这个时候总latency = 130 * 3 ps = 390 ps,throughput = 1 / 130 * 1000 GIPS = 7.69 GIPS;当 stage 数量为 4 时,最好的划分方法是
A | B C | D | E F,这个时候总latency = 110 * 4 ps = 440 ps,throughput = 1 / 110 * 1000 GIPS = 9.09 GIPS;当 stage 数量为 5 时,最好的划分方法是
A | B | C | D | E F,这个时候总latency = 100 * 5 ps = 500 ps,throughput = 1 / 100 * 1000 GIPS = 10 GIPS;当 stage 数量大于 5 时,
throughput不可能比 5 个 stage 更好了,因为最大不可分割的单元已经达到 80 ps 了,意味着再增加 stage,不仅不会提升 throughput,还会延长 latency;
于是我们能得到结论:
最大的 throughput 不一定是在最大的 Stage 切分数取得,而是取决于 最大的、不可分割的部分耗时 + 寄存器状态写入的 latency;
Limitation 2: Register Overhead
另外,当我们将过程切分成更多的 stage 后,loading registers 所占的时长比例愈发的大,这是我们所不希望的。
Limitation 3: Data Dependency & Data Hazard
既然使用流水线,就不可避免要考虑前后 stage 的依赖问题,例如 前一条指令的结果是后一条指令的运算数(数据依赖)、前一条指令决定后一条指令的执行位置(控制依赖)。
对于数据依赖而言:
xxxxxxxxxxirmovq $50, %raxaddq %rax, %rbxmrmovq 100(%rbx), %rdx因此,这三条指令在流水线上的时间顺序必须是这样的,才能保证运算结果的正确性:
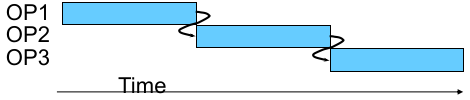
但是,这样又没法使用流水线,因此可以采用 中间插入其他指令 的方式缓解这种问题,具体会在实现的时候进一步讨论:
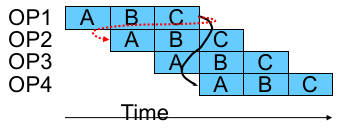
Limitation 4: Control Dependency
同样,对于控制依赖:
xxxxxxxxxxloop: subq %rdx, %rbx jne targ irmovq $10, %rdx jmp looptarg: halt
于是,我们分析了实现流水线的优势、可能遇到的问题。接下来我们会在实现的介绍中,依次解决上面的几个顾虑。
9.8 Pipeline Implementation
首先同样,根据前人的经验,我们作出如下强调:
SEQ+ Implementations:将
PC UpdateStage 的工作移动到 Fetch Stage(根据上一条指令的寄存器结果得到当前指令的 PC),而 PC 不再存在一个真实寄存器中,因为只需要根据上一条指令的寄存器状态就能计算 next PC(变成了组合逻辑电路)。至此形成经典 5 级流水线的逻辑电路基础;New Fetch:
Select current PC;
Read instruction;
Compute incremented PC.
Naïve PIPE Implementation:先忽略 Control / Data Hazard,只用
nop解决;Pipeline Feedback
9.8.1 Hardware
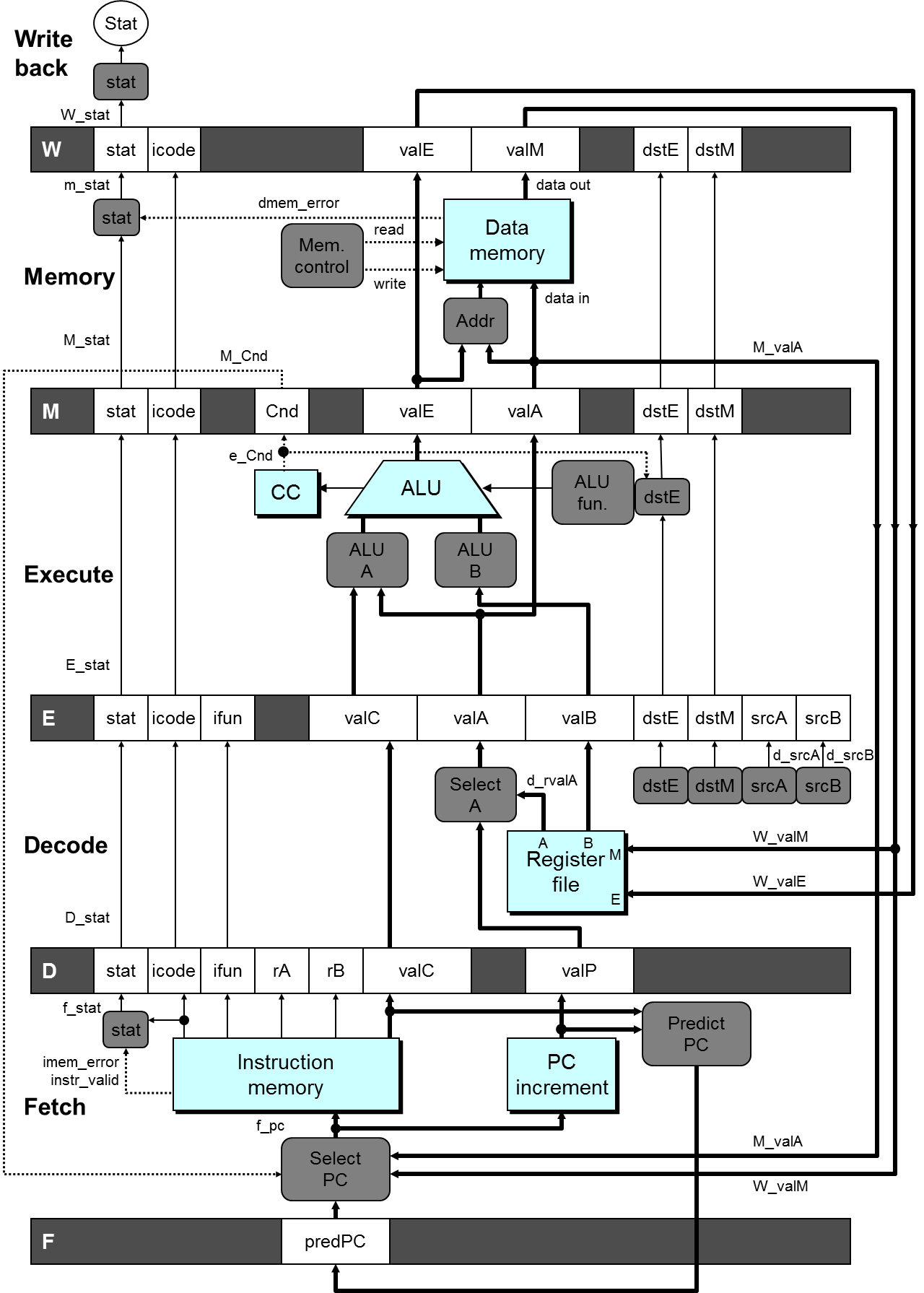
有几点值得注意;
和 SEQ Implementation 不一样,每个 stage 间多了要保存的状态寄存器;
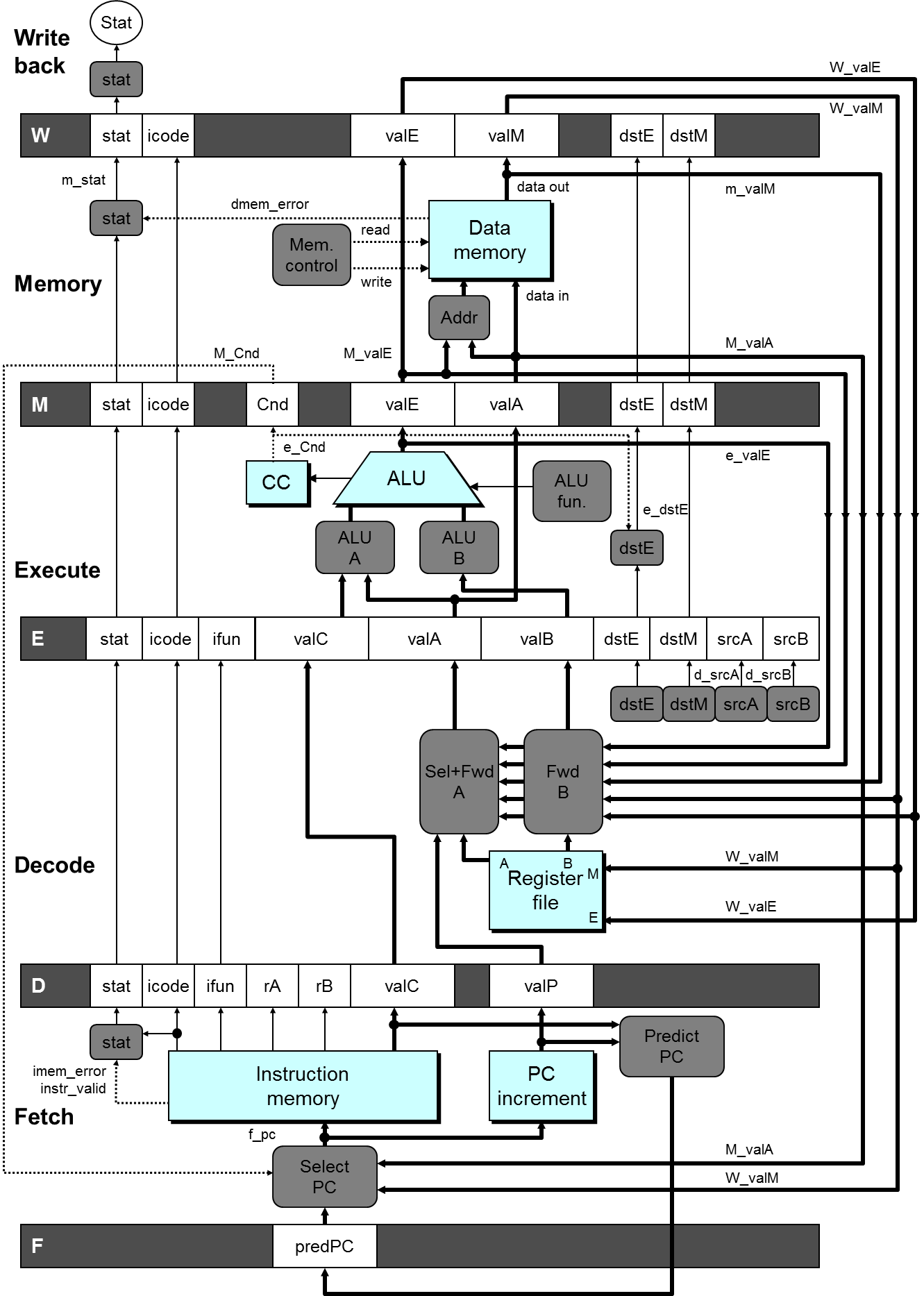
小写字母前缀表示当前 stage 阶段由控制逻辑块生成的数据,大写字母前缀表示流水线寄存器的一个字段(从上个 stage 接受的数据);
例如:
D_stat表示 Decode Stage 接受上个阶段的状态输入值,m_valA表示 Memory Stage 计算出的valA值;Fetch 部分增加了 用于猜测下一条指令的寄存器
predPC;Decode 部分增加了
Select A部件,原因是:现象:只有 call 指令会在 memory 阶段用到
valP,只有 jump 指令会在 execute 阶段用到valP(准确说是“携带”)。这两种指令都不需要用到寄存器 A;还有一点是我们已经将 PC Update 转移到 Fetch 中,在 Fetch 阶段本身就有 Predict PC 部件。这样valP在其他场合也不需要传播到 Fetch 阶段之外的场合去;作用:减少控制信号和寄存器的数目。即可以将这两个控制信号合并。
那么这个 implementation 是如何解决 Data / Control Hazard 的?
9.8.2 Resolve Data Hazard: Data Forwarding & Stalling
首先对于 Data Hazard,主要的问题是:Read-after-write(write 在 read 后面则不会出现问题)。
可能引发这个问题的指令有:opq、ir/rr/mr/rm movq、popq。
例如对这样几条汇编而言:
xxxxxxxxxx# demo-h0.ys0x000:irmovq $10,%rdx0x00a:irmovq $3,%rax0x014:addq %rdx,%rax0x016:halt直接考虑 5 个 stage 流水线形式进入会出现问题,如下左图:
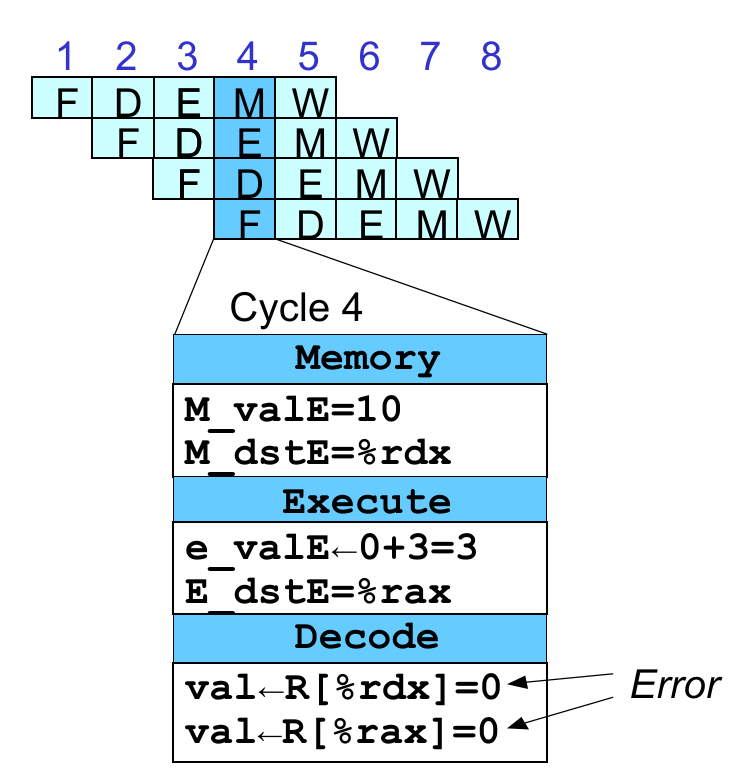
因为在第 3 条指令在 Decode 阶段会读取紧邻的前两条指令计算结果,而前两条指令此时正处于 Memory 和 Execute 阶段,都没有到 Write Back 阶段,这时存在 read-after-write dependency,读取数据一定是错误的。
第一种尝试方法是之前提到的 插入 nop(Naïve Design);
一般如果 Fetch 读入一个改变下一个指令所用寄存器的指令,那么等到该指令更改寄存器位于 Write Back Stage,前后相差 3 个 stage,因此在有 Data Hazard 的两指令间插入 3 个 nop就能解决问题,如上右图。
考虑一下,如果只插入 2 个
nop,那么第三条指令只能读到%rdx中正确的值,因为第二条指令还在 Write Back 阶段没有结束;如果只插入一个
nop,那么两个寄存器正确的值都读不到!
虽然这种解决方法非常简单,可以由编译器、硬件处理器,甚至开发者来解决。但是弊端是 这会严重拖慢流水线速度。因此我们得想办法尽可能让底层硬件解决这个问题。
第二种尝试方法是 stalling(拖延住);
这种方法是在 CPU 执行指令时实时进行的,具体以例子说明。假设有个程序在 Y86-64 编译器上编译后长这样:
xxxxxxxxxx# demo-h2.ys0x000:irmovq $10,%rdx0x00a:irmovq $3,%rax0x014:nop # 先考虑简单的情况,假设这中间有两条完全无关、不会出现 data dependency 的指令,0x015:nop # 我们假装它们就是 nop 来讨论 # Bubble0x016:addq %rdx,%rax0x018:halt我们根据上一种方法的分析可知,现在 0x016 位置上的指令仍然无法读到正确的 %rax,还需要再等一个 clock 才行。这个时候,我们在 0x015 和 0x016 之间插入一个 “Bubble”。
这个 Bubble 不会在汇编代码中出现,而是 CPU 进行了以下操作:
向
0x016指令(依赖未取得的指令)所在的 Stage(Decode)输入状态寄存器发送 Stalling 信号,暂停一个 clock 不允许被修改;在向
0x016指令之前的所有 stage(这里只有 Fetch)的输入状态寄存器发送 Stalling 信号(防止后来的指令 “撞到” stalling 寄存器上消失);由于
0x016指令只是状态寄存器定住了,不正确的信号仍然会向前传递,因此 CPU 还要 将前进到 Execute Stage、但没来得及修改 CC 和 后继状态寄存器的错误指令的icode修改为1,表示nop,使它彻底失去作用;
这种 “将其他指令的 icode 改为 1 使其成为 nop” 的动作所产生的不在汇编码上的 nop 就叫 bubble。
这样从 0x015 后的所有指令都会暂停一个 clock,等待 0x00a 指令写入寄存器。
这种方法只是将插入 nop 的工作移交给了硬件,没有解决速度上的问题。
第三种尝试方法是 data forwarding(利用 feedback paths 将后面的结果给到前面的 decode stage);
就是说,我们让最终结果未出现前,让正确 / 可能正确的值先通过传输线传递给读的 decode 阶段;这个方法能实现,主要是因为 能读到信号要早于写入信号(前者在一个 Clock 开始的一段时间后就可读到,而后者则需要这个 Clock 结束)。
例如:
irmovq在 Fetch 阶段就一定可以得到正确的值,后面的任意 stage 都能找到值;opq在 Execute 阶段后期一定可以得到正确的值,后面的任意 stage 都能找到值;ret在 Memory 阶段结束一定可以得到正确的值;
但是 Feedback Paths 不会出现在 Fetch 阶段,因为太早了,后面的指令没进入 Decode 阶段前很难使用这个结果。
一般用 feedback paths 去解决 data hazard,主要作用在 Decode 阶段,因为这个阶段才可能会用到没有写入的寄存器值。
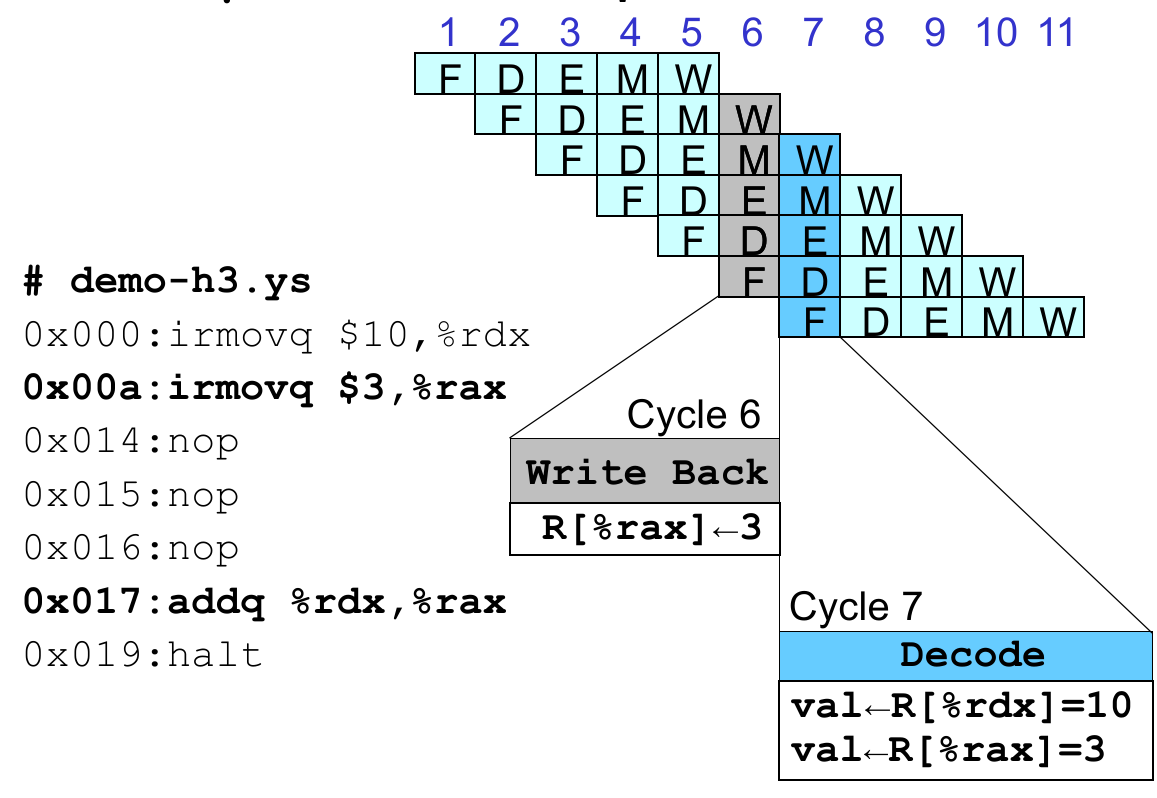
再考虑简单的情况,假设 0x00a 和 0x016 之间有两条无关的指令,就假设为 nop:
xxxxxxxxxx# demo-h2.ys0x000:irmovq $10,%rdx0x00a:irmovq $3,%rax0x014:nop0x015:nop0x016:addq %rdx,%rax0x018:halt这个时候 %rdx 能正确读到,如果我们把 Write Back 阶段的 W_valE(0x00a 的 Write Back Stage 状态寄存器值)通过 feedback path 将信息告诉 Decode Stage 呢?比如在这种情况下,我们把 W_valE 接给 valB,就能够读到正确的值了。
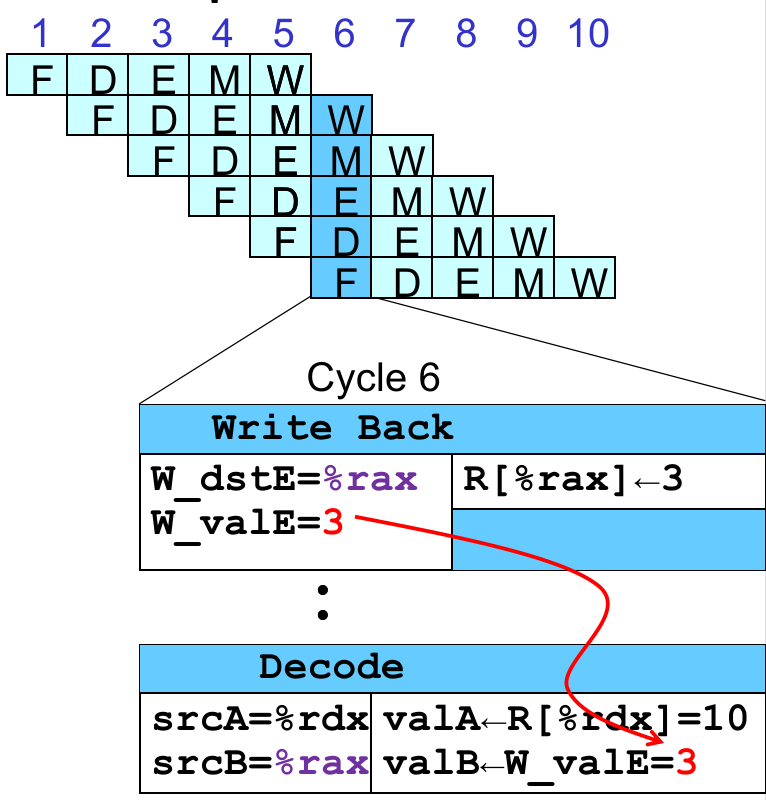
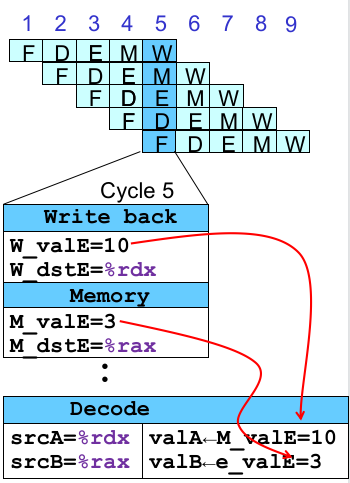
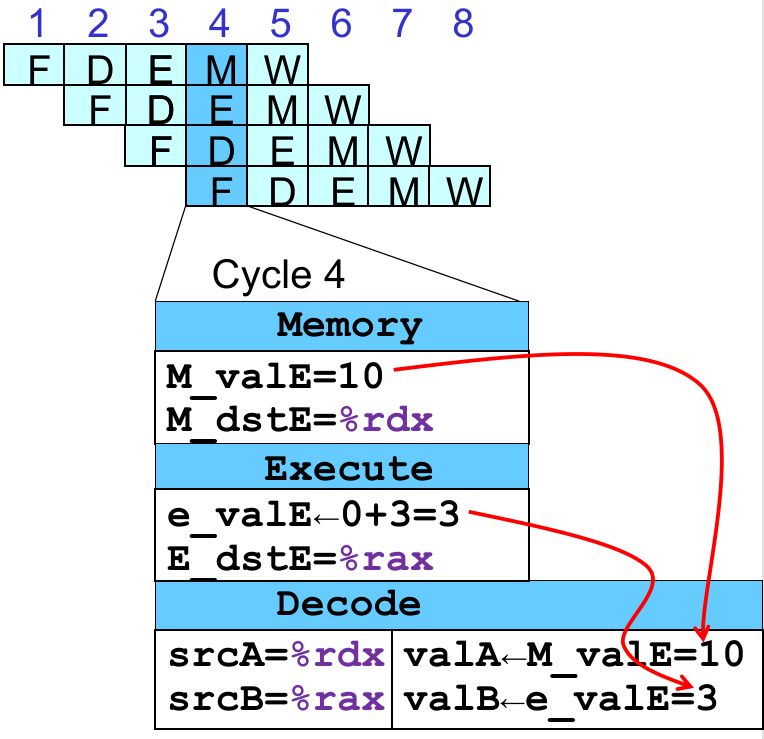
那我们乘胜追击,假设中间只空 1 个 nop 呢?这个时候产生 %rax 的值还在 Memory 阶段!没事,因为 irmovq 的结果在 Fetch 阶段就知道了嘛,我们把 M_valE 的值给它;
然后另一个寄存器也无法获取正确的值,就类似上个情况的 “从 Write Back 阶段 W_valE 到 valA“ 接线就行。如上中图所示。
太好了,更极限一点的话,irmovq 写和 opq 读指令不隔 nop,是否也能用 data forward 解决?
同样是可以的:在上一条指令处于 Execute Stage 时,我们直接将运算结果 e_valE 给 valB。来的及吗?之前都是给状态寄存器(在 Clock 开始前就等待在外),这次给结果值(Clock 开始后一段时间才能稳定),是来得及的。因为 Deocde 阶段可以等,直到这个 Clock 快结束才得到都是没问题的。如上右图。
更进一步考虑,假如上面的指令不是
addq %rdx,%rax,而是addq %rax, %rbx(前两条指令也对应变),那么寄存器情况是不是一样能这么做?
于是我们发现,只要多加几个 feedback paths,就能解决以 irmovq / opq 为首的 RAW-Dependency 问题,不需要插入 Bubble 或者 nop。我们将这个成功经验拓展到其他指令上,再总结一下:
首先我们可以从这些位置提前得到寄存器的结果(Forwarding Sources):
Execute Stage 的计算结果
valE(e_valE);不能比这个早,因为上面我们讨论
irmovq只是一种情况,有些指令例如opq必须等到 Execute 结束才能拿到正确的值。Memory Stage 的状态寄存器
valE、valM(M_valE、M_valM);Write Back Stage 的状态寄存器
valE、valM(W_valE、W_valM);
其次,我们需要判断是否应该接受 forwarding data,即分情况选择 valA、valB 的来源。哪些情况应该和平常一样直接使用寄存器的值,哪些时候又应该选择 Forwarding Sources。
为了分情况选择,我们向电路里加入了两个逻辑电路用于选择不同情况下 valA 和 valB 的取值,纠正 data hazard 问题:
这种 data forwarding 方法看似解决了问题,并且无需使用 bubble 和 nop,但是它还是没有考虑完全。
我们上面讨论的情况 “以 irmovq 写、opq 读为首的 RAW-Dependency” 有个前提是,直接相邻的两个存在 data dependency 的指令,所使用的有依赖的数据产生阶段不能晚于 Execute Stage,因为直接相邻说明只间隔了一个 stage。
那么可能构成 data dependency 的指令中(opq、ir/rr/mr/rm movq、popq),有一类是没法在 Execute Stage结束前拿到结果:从 memory 中取值的 mrmovq、popq。它们必定要等到 Memory Stage 结束才能取到值!
我们将 “在取 Memory 后,立即使用此值” 的行为称作 “Load / Use Hazard”,这种情况使用 Data Forward 是无法纠正寄存器的读错误。我们必须要借助前面介绍的 Bubble 让这种连续 Load / Use 分开一个 Cycle。
于是,Y86-64 针对 Data Hazard 的解决方法总结如下:
对于一般的连续两条指令(分开的就更好办)数据依赖,我们可以直接使用 Data Forwarding 设计的 Feedback Paths,选择正确的值就能纠正;
对于 Load / Use Hazard(连续的从内存读、使用),我们需要在使用 Data Forwarding 的同时,向 Execute 阶段插入一个 Bubble(同时要将 Decode 和 Fetch stall 住一个 Clock 防止指令损失),以将 Load 和 Use 指令分开一个 Cycle;这两种方式结合的方法就叫 load interlock(加载互锁)。
9.8.3 Resolve Control Hazard Part Ⅰ: Predicting the PC
其次,针对 Control Hazard 的解决方案也是 Feedback Paths。根据指令的特点,有几种数据能决定 next PC:
Next Instruction for most cases(
valP,一定可以预测正确);Call destination(
valC,一定可以预测正确);Branch information,由有条件的
jmp指令触发,可能预测正确;Return point,由
ret指令触发,地址位于内存,几乎一定不可预测;
所以可以根据这些寄存器中的值进行预先推测,猜测可能下一步可能的指令地址。
由于上一条指令在 Fetch 之后就要读下一条指令了,所以猜测的可靠性不能保证。
如果猜测错误,就需要恢复到猜测前的状态(如何实现?后面提及)。
对应这几种数据的特点和成功率,我们相应的有猜测策略:
对于前两种情况而言,我们直接选择 Fetch 阶段得到的或者计算出的
valC / valP,一定不会出错;对于 Conditional Jumps,我们总是猜测可能是寄存器
valC中的地址(即赌本次跳转条件一定成立)。为什么?原因有 2 条:
因为大量数据统计在 60% 的情况下的条件是成立的(Unconditional 和 Conditional Jump 只是
ifun的区别;还有while、for循环翻译成的jmp跳转的概率更大);携带
valP和valC的电路设计的复杂程度不一样。人们发现选择valC时电路更简单;
也可以通过一些数据分析的手段来精确这个过程;
另外,我们还需要知道这次猜测是否正确,如果猜测错误还需要进行恢复。我们可以将
M_Cnd(Memory stage 计算得出的 Cnd flag)、M_valA(Memory 阶段存储的valP,因为有 Select A 所以放在这里)两个值通过 Feedback Paths 回接给 Select PC,让它判断是否该相信predPC;对于 Return 而言,几乎一定无法预测,那么就彻底不预测,也就是不使用 Predict PC,和其他情况一样默认
valP;最终的纠错阶段就是真正的返回地址被取出的时候(Write Back state registers);
现在,我们根据猜测策略,将各种情况下 Next PC 的猜测值全部汇总到 Select PC 原件,让这个逻辑电路根据情况判断正确的下一条指令是什么,如下图。
9.8.4 Resolve Control Hazard Part Ⅱ: Fix Wrong Predictions
但是有个问题,我们按照上一节的猜测策略暂时得到了可能的下一条指令的执行位置,我们又如何在得到结果后发现、修复错误的猜测结果呢?
ret 指令的结果数据在 Memory 结束、Write Back 状态寄存器才能知道,jmp 类指令的结果数据也要在 Execute 结束、Memory 状态寄存器才能知道。这两种指令紧邻的下一条指令在 Fetch 时(哪怕有 Data Forward)也没法得知结果,怎么办?
根据猜测策略,jmp 直接先猜测按照 valC 跳转,但是检查 M_Cnd 时,jmp 已经向前前进了 2 个 Stage 了(Fetch Finish -> Execute Finish),如果 M_Cnd 指示符合跳转条件,那么继续执行没有问题,但是如果出错,应该怎么办?我们发现检查 M_Cnd 的时候,中间两个指令分别在 Decode 起点、Execute 起点,还有下一条指令刚要进入 Fetch 阶段 —— 即便 jmp 错误,当前也并没有产生影响(如更改 CC、写入下一个 stage 的状态寄存器)。因此很好解决:
jmp 如果发现 M_Cnd 指示不应该跳转,说明预测错误,立即进行以下措施:
由于
jmp以后的错误指令只有两条(位于 Decode 和 Execute 开始阶段),并且没产生影响,只需要在时钟上升沿时将它们的icode改为1(nop),就能解决错误执行的问题;同样是上升沿阶段,将
M_Cnd给到 Fetch 阶段,这个时候 Fetch 阶段就能读到正确的下一条指令;
所以就算 jmp 预测错误,有了上面的措施,也就浪费 2 个 Cycles 而已,不会造成执行语义错误!
再来看 ret 的跳转错误如何修复。
根据策略,ret 不会做猜测(一般行为遵从 Predict PC 拿到的 valP),直接接着这条指令向下读。但是 ret 和 jmp 不一样,不能按照原来 feedback paths 解决,因为 ret 拿到结果 W_valM 要到 Memory Stage 结束,而这个时候 ret 向前前进了 3 个 Stage,紧跟 ret 的指令 Execute 已经执行结束 —— 也就是说,错误的指令改变了 CC 和后续状态寄存器,这是不允许的!
你可能会问,我们能不能早一点拿到
valM,比如m_valM?不行,因为m_valM产生在 Clock 很后面的阶段(尤其是从内存读),Clock 时钟来不及。
因此,我们只能采取 填充 3 个 Bubbles 的方法,避免出现错误:
当 CPU 检测到
ret指令结束 Fetch、进入 Decode Stage 时,立即向 Fetch Stage 发送 Stalling 信号,不允许 Fetch Stage 的状态寄存器被写入;为什么处理
ret需要把 Fetch Stage Stall 住?因为任由 fetch stage 向下取的话,可能取到非法指令,改变了状态(stat)信息,给后面增添判断的麻烦,所以索性 stall 住。将输出到 Decode Stage 的
icode改为nop的;重复以上两个措施共 3 个 Cycles,直至
ret结束 Memory Stage;
这样,当 ret 结束 Memory Stage 时,时钟上升延会推动正确的返回地址数据到 Write Back Stage 的状态寄存器 W_valM 中,此时利用 Select PC,在 Fetch 阶段就能读到正确的下一条指令的地址了。
所以,无论如何,ret 后面总是要被 CPU 追加 3 个 bubble 的空隙。
综上,根据我们的猜测策略 和 修复措施,Select PC 的工作逻辑应该是这样的:
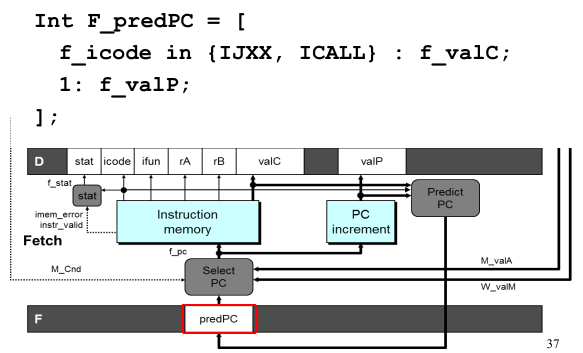
xxxxxxxxxxint f_PC = [#mispredicted branch. Fetch at incremented PCM_icode == IJXX && !M_Cnd : M_valA;#completion of RET instrucitonW_icode == IRET : W_valM;#default: Use predicted value of PC1: F_predPC];
当我们发现之前一条指令是
jmp类,并且条件有效时,选M_valA(即原封不动的valP值);当我们发现之前一条指令是
ret时,意味着 Memory 结束、发送给 Write Back 的状态寄存器才是正确的地址(W_valM);其他的情况选择
F_predPC(也就是 Fetch 阶段自己算好的valP)。
最后,总结一下 Y86-64 是如何解决 Control Hazard 的问题的:
对于一般指令(不含
jmp、call、ret),只要让 Select PC 默认读valP(在 Fetch 阶段就计算好的)就行,此后也无需检查、不存在 Wasted Cycles,因为下一条指令的位置一定是正确的;对于
call指令,只要将 Select PC 默认读valC(在 Fetch 阶段就读到的)就行,此后也无需检查、不存在 Wasted Cycles,因为下一条指令的位置一定是正确的;对于
jmp指令,读到时默认跳转valC,继续执行,但在 2 个 Cycles 后检查M_Cnd,正确就什么都不做,不正确就将中间两条错误指令改为nop,Fetch 阶段自动会读入正确地址。这种情况总共浪费 2 个 Cycles;对于
ret指令,读到时不作猜测,默认valP,但是当ret进入 Decode Stage 时,Stalling Fetch Stage,并且将传给 Decode 的指令的icode改为nop的,持续 3 个 Cycles。这样 Fetch 就能通过W_valM读到正确的下一条地址。这种情况一定浪费 3 个 Cycles;
9.8.5 Exception Handling in Pipeline
在之前的章节,我们介绍了 x86-64 的 Exception Control Flow,它是 OS 与硬件配合改变执行流的动作。
如果在 SEQ 设计中,我们只需更改 PC 寄存器即可。但是在 Pipeline 设计中,我们需要清理一些寄存器的值、某些 stage 的状态寄存器,才能转到指定的 ECF 地址。主要的步骤如下:
打断当前程序执行流;
根据出现的事件,填入 Exception Table Base Register,找到 Exception Table 对应的 Exception Handler 地址,跳入新的执行流;
(可能)回到原来的执行流;
我们这里先只考虑 同步异常(Synchronous Exceptions)。
那么可能导致同步异常的硬件层面原因有:
halt指令;指令请求错误的指令地址 / 数据地址;
非法指令;
为了处理问题,我们还要讨论错误可能发现的位置:
能在 Fetch Stage 检测的 Exceptions:
jmp $-1:jmp非法地址;.byte 0xFF:非法指令;halt:程序终止;
能在 Memory Stage 检测的 Exceptions:
rmmovq %rax, 0x10000000000(%rax):非法内存地址;
但是,pipeline 的设计导致一些奇怪的情况:
Situation 1. 异常检测顺序倒置:代码的执行流中两个错误,但是后一条错误发现时间(Fetch Stage)在前一条错误发现时间(Memory Stage)之前。导致后一条指令会先报错;
Situation 2. 不应该触发的异常:异常的代码不在程序执行流内(例如 halt 以后不全是 0,有没擦干净的乱码;或者 jmp 的另一个不会执行的分支),但是 CPU 仍然可能读入并报错;
你可能会想,我们要模仿 SEQ,先检测到错误没事,只要我们在这条指令完全结束后(该指令到 Write Back Stage 结束)再报出错误,就能避免上面两种情况的发生。但这样做可能引发另一类问题:
Situation 3. 异常指令的 Side Effect:错误指令和正常指令一起在流水线中向上传播,可能会导致 CC 被错误地修改(例如在错误指令后面的指令不应该被执行,但是它仍然更改了 CC,这会影响 Dump 的数据);
综合以上的情况,我们总结出了解决方案:
类比 Program Status,在每个 stage 的状态(除了 fetch)寄存器中加入
stat寄存器,表示当前指令的执行情况。AOK表示指令正常,ADR表示指令访问错误地址,HTL表示halt终止指令(方便阻止halt以后的指令的执行),INS表示非法指令;Fetch Stage 或 Memory Stage 如果能检测出错误,那么就设置到下一个阶段的
stat寄存器;其余阶段(Decode、Execute)直接传递stat寄存器;即:当异常出现时,仅仅设置状态寄存器(stat),其他正常;
如果异常到达 Memory 阶段,则为了防止错误指令影响状态寄存器或 CC,进行以下措施:
对于非法指令,接下来向 Memory 阶段插 bubbles:即对于非法的内存操作,不允许写入内存;
立即关闭之后的 Execute 阶段写入 CC;
如果异常到达 Write Back 阶段,则将该阶段 stall 住,抛出错误(只有在 Write-Back 阶段被触发,保证异常触发的顺序)。
检查
W_stall的条件,只需要检查W_stat就行,不需要管m_stat;最后打断当前执行流:
将 next PC 值 / 触发异常的指令 PC 压入栈中(通常和 exception
stat一起传递);使用事先固定在 ISA 中的 Exception Handler Address 跳转到 handler 中执行。
9.8.5 Final Implementation
我们将前几节的 Pipeline 设计的思想和注意要点结合起来,考虑设计一个 Y86-64 pipeline 处理器的最终版本。
9.8.6 Performance Analysis: Metrics
Clock Rate
CPI (Cycles per instruction): On average, how many clock cycles does each instruction require?
其中
比如我们利用 Metrics 的指引进行优化:Speculation Execution in Fetch Logic;
考虑 PIPE CPU 的关键路径:
我们发现 increment 阶段是关键路径上较大的部分,它要等待 regids、valC 结果,然后执行 64-bits 的加法运算(最多 +10),所以我们可以先将前 60 bits 的数据 +1(同时保留不加、+1 的数据),然后另一部分仅仅是 4 bits 数的相加,这样可以节省串行进位加法所耗费的时间,如下图所示:
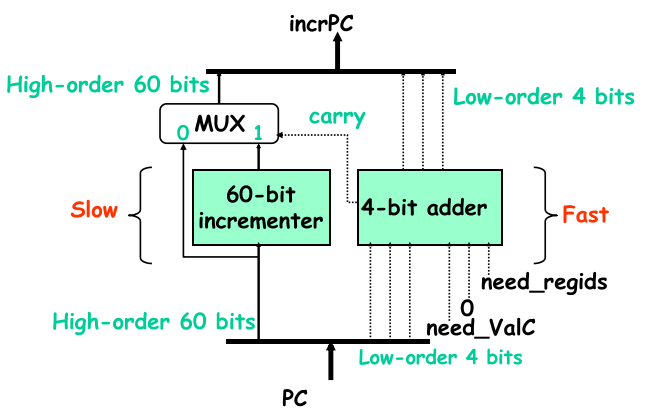
这样指令总体的速度都会快上一些。