AEA Cheatsheet
AEA CheatsheetChapter 1. Miscellenous1.1 Cookie & Session1.2 Java Spring Bean 实例池1.3 数据库连接设置Chapter 2. 异步通信:Message Queue2.1 同步通信 versus 异步通信2.2 Kafuka2.2.1 Kafka 的高性能2.2.2 Kafka 的高可扩展性2.2.3 Kafka 的高可用性2.2.4 Kafka 的持久化 & 过期策略2.2.5 Kafka Consumer Group2.2.6 ZooKeeper & KRaft2.2.7 Kafka Serializers & Deserializers2.2.8 实践:如何使用 Kafka?Chapter 3. Web Socket3.1 Definitions3.2 Coding WebSocket3.3 WebSocket Encoder & Decoder3.4 STOMP over WebSocketChapter 4. SQL 数据库进阶:事务4.1 Definitions of Transaction4.2 Problems of Transaction for Database I: Isolation4.2.1 Conflicts4.2.2 Isolation Level4.2.3 Implementations of Isolation in DB I: Locks4.2.4 Implementations of Isolation in DB II: MVCC4.2.5 Implementations of Isolation in DB III: Scheduling4.2.6 补充:Design Pattern of Locks4.3 Problems of Transaction for Database II: Atomicity & Consistency4.3.1 Rollback & Faults Recovery4.3.2 Implementation of Atomicity & Consistency in DB: LogsA. 事务故障 / 系统崩溃补充:数据库日志的实现方式4.4 Problems of Distributed Transaction in Different Database (Atomic)4.5 Transaction in SpringChapter 5. SQL 数据库进阶:优化5.1 索引5.1.1 Overview5.1.2 Implementations5.1.3 MySQL 何时会使用索引5.1.4 列索引优化前缀索引聚簇索引全文索引稀疏索引 (Sparse Index)空间索引 (Spatial Index)多列索引(复合索引)内存索引Hash 索引降序索引5.2 主键优化5.3 外键优化5.4 数据库结构优化5.4.1 数据大小5.4.2 MySQL 数据类型5.5 数据库多表优化5.5.1 MySQL 如何管理 Open/Close Tables5.5.2 数据库数量限制调优数据库/数据库表的数量数据库表的大小数据库表的列数和行的大小5.6 InnoDB 表优化5.6.1 InnoDB 存储效率优化5.6.2 InnoDB 事务优化5.6.3 InnoDB 载入大量数据时优化5.6.4 InnoDB 查询优化5.6.5 InnoDB Disk I/O 优化5.6.6 InnoDB DDL 操作优化5.7 MEMORY 表优化5.8 Buffering and CachingChapter 6. 数据库备份与恢复6.1 备份和恢复的类型6.2 实践6.3 备份和恢复的策略Chapter 7. 数据库分区7.1 Types of Partitioning7.1.1 RANGE Partitioning7.1.2 LISTING Partitioning7.1.3 HASH Paritioning7.1.4 KEY Partitioning7.2 Subpartitioning7.3 How About NULL in Partitions?7.4 Partitioning Management7.5 分区与表 的交换Chapter 8. NoSQL8.1 Why we need it?8.2 MongoDB8.2.1 DefinitionsDocumentCollectionDatabase8.2.2 Indexing8.2.3 ShardingReasonsShard & Chunks8.3 Neo4J8.3.1 Definitions8.3.2 Data Model8.3.3 Storage Mechanism8.4 Log-Structured Database日志结构数据库中的读放大和写放大8.5 Vector Database8.5.1 Basic Concepts8.5.2 ANN Search Algorithms8.5.3 Similarity Measurement8.6 Timeseries DatabaseChapter 9. Concurrency Control9.1 Thread in Java9.1.1 Usage9.1.2 Synchronized Methods9.1.3 Reentrant Synchronization9.1.4 Atomic Access & Keyword volatile9.1.5 Dead Lock, Starvation, Live Lock9.1.7 Immutable Objects9.1.8 High Level Concurrency ObjectsLock ObjectsExecutorsConcurrent CollectionsAtomic VariablesVirtual ThreadsChapter 10. Memory Caching10.1 Background10.2 Memcached10.3 Distributed KV Store10.4 Redis10.4.1 为何需要?10.4.2 缓存读写策略10.4.3 缓存 Evict 策略10.4.4 缓存击穿 & 缓存雪崩Chapter 11. Full-text Searching11.1 Lucene11.1.1 Concepts11.1.2 Metrics11.1.3 Core Classes11.1.4 Searching Procedure11.1.5 Java Example11.1.6 Field 域类型11.1.7 维护索引11.1.8 Tokenism & Analyzers11.1.9 Advanced Search11.1.10 Similarity SortChapter 12. RESTful Web Service12.1 SOAP & WSDL12.2 RESTful Web Service12.2.1 Definitions12.2.2 Principles of REST12.2.3 Design Standards of RESTful API12.3 ConclusionChapter 13. Revisit: Microservices13.1 注册中心 & 微服务网关13.2 微服务雪崩13.3 微服务保护Chapter 14. HTAP14.1 Business Logic14.2 SolutionsChapter 15. Data Lake15.1 Concepts15.2 Evolution History15.3 Data Source 从哪来?Chapter 16. Cluster16.1 Why Cluster?16.2 Load Balance16.3 MySQL 集群和 Nginx Load Balance Policies16.4 Proxy & Reverse ProxyChapter 17. Cloud Computing & Edge Computing17.1 MapReduce17.2 Distributed File System17.3 Google BigTable: KV Store 鼻祖17.4 Summary: Components of Cloud OS17.5 Definitions of Edge ComputingChapter 18. GraphQL18.1 为什么需要 GraphQL?18.2 GraphQL Grammar18.3 GraphQL with Spring BootChapter 19. HadoopChapter 20. Spark20.1 Overview20.2 Spark Components20.3 Spark RDD (Resilient Distributed Dataset)20.3.1 Definitions20.3.2 RDD Operations20.3.3 RDD Partition20.3.4 RDD Dependencies20.4 Spark's Usage20.5 流式处理 & 批处理 & 流批一体架构Chapter 21. StormChapter 22. HDFS22.1 Definitions22.1.1 Design Assumptions: environments22.1.2 ArchitectureComparison between Improved NFS & HDFSInteraction ModelInterface22.2 Operations22.2.1 Reading a file in GFS22.2.2 Writing a file in GFS22.3 Features22.3.1 Safe Mode22.3.2 Rack Awareness22.3.3 Robustness & Fault ToleranceChapter 23. HBaseChapter 24. Hive24.1 Definitions & Meanings24.2 特性 & 与关系型数据库比较A. Scalability and PerformanceB. Data ModelC. Concurrency and Transaction (OLTP) SupportD. Data Processing TypeE. Data Storage24.3 再谈数据湖、数据仓库Chapter 25. Flink25.1 Scene25.2 The States of Flink25.3 Watermarks of Flink25.4 The Architecture of FlinkChapter 26. AI26.1 Full-Connected NN26.2 分类神经网络构建26.3 CNN26.4 TLP26.5 RNN & LSTM26.6 ChatGPT & Transformer
Chapter 1. Miscellenous
1.1 Cookie & Session
核心问题是什么呢? Http协议是一种无状态的协议!也就是说,每次请求都是独立的,服务器并不知道你是谁,你上次请求的信息是什么。
所以,怎么解决这个问题呢?
Cookie:客户端浏览器用来保存用户信息的一种机制;当我们通过浏览器进行网页访问的时候,服务器会将一些数据以cookie的形式保存在客户端浏览器上,当下次客户端浏览器再次访问该网站时,会将 cookie 数据发送给服务器,服务器通过 cookie 数据来辨别用户身份。(cookie 存的是 kv 键值对)
Session:表示一个会话,是属于服务器端的一种容器对象;
默认情况下,针对每个浏览器的请求,server 都会创建一个 session 对象,生成一个
sessionId,用于标识该 session 对象,同时将sessionId以 cookie 的形式发送给客户端浏览器;客户端浏览器再次访问该网站时,会将 cookie 数据发送给服务器,服务器通过 cookie 数据来辨别用户身份,从而找到对应的 session 对象,如果找不到,就会创建一个新的 session 对象。
1.2 Java Spring Bean 实例池
"对象池"(Object Pool)是一种设计模式,它是一种用于管理和重用对象实例的机制,以提高性能和资源利用率的方式。对象池通常用于减少创建和销毁对象的开销,特别是在对象的创建成本较高或频繁创建和销毁对象可能导致性能下降的情况下。 在 Java 中,对象池通常是一个集合,用于存储和管理多个对象实例。当需要使用对象时,可以从对象池中获取一个可用的对象,而不是每次都创建新的对象。一旦使用完成,可以将对象返回到对象池中,以便稍后重用,而不是立即销毁它。
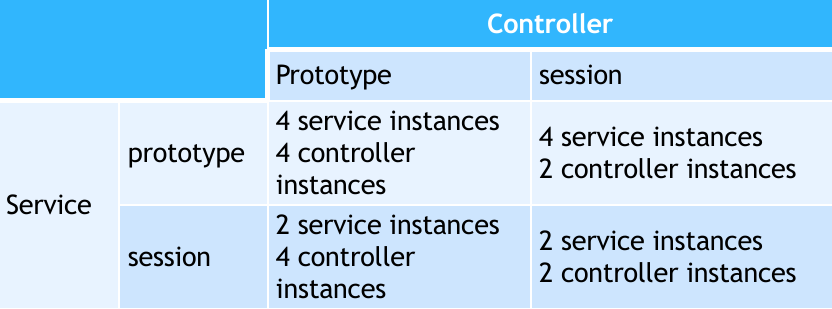
实例池的数量一定有上限的,不可能运行每一个用户上来都能创建一个对象,否则请求频率较高的时候内存直接爆炸。假设我们只能创建两个对象,这样内存就不会爆炸了。那是怎么服务于多个用户呢?
假设 A 用户来了,我们创建一个实例 A',然后 B 来了创建一个 B',现在实例池满了;
C 来了之后,根据 LRU Algorithm,把 A' 从内存里面换出落盘,然后创建一个 C 的实例;
这个过程就称为 Java 实例的 swap in 和 swap out;使用类似页表换入换出的方式,实现服务超过当前实例数量的 clients;
因此,系统尽量要无状态的,减少或集中有状态的服务(否则需要创建多个 Bean 实例)。
两次调用不会相互影响(不会改变系统状态),或者说幂等的。
比如说我们要统计一个网站在线用户的数量,这样所有用户公用的一个域就是count:反应用户数量,这样就是无状态的(这个状态是公用的,不是每个用户都有一个);
如果是每个人来了以后,每个人的对象都不一样,那么就是有状态的。但是有状态的就需要针对每个用户单独存储,占用空间,所以尽可能的少或者避免。
在 Java Spring 中,管理 Bean 实例创建策略的注解是
@Scope(Bean 作用域),它可以管理 Bean 实例的生存周期以及可见性:
Singleton(单例): 这是 Spring 默认的作用域。在单例作用域下,Spring IoC Container 对一个类型只创建一个 bean 实例,并在应用程序的整个生命周期内重用该实例。这意味着每次请求该 bean 时,都会返回相同的实例;
Prototype(原型): 在原型作用域下,每次调用(invoke)涉及该 bean 的类型时,Spring IoC Container 都会创建一个新的 bean 实例。这意味着每次请求都会返回一个不同的实例;
Request(请求): 这个作用域适用于 Web 应用程序,每次 HTTP 请求(不管是否来自同个客户端 / 会话)都会创建一个新的 bean 实例,每个请求之间的实例不共享(位于
AppContext);Session(会话): 类似于请求作用域,但在 HTTP 会话的整个生命周期内创建和维护一个 bean 实例。不同用户的会话之间的实例不共享(位于
AppContext);Application(应用级别):在
ServletContext的整个生命周期内创建和维护一个 bean 实例(位于AppContext);WebSocket:在
WebSocket的整个声明周期内创建和维护一个 bean 实例(位于AppContext);Custom(自定义): 您还可以定义自定义的作用域,以满足特定需求。要使用自定义作用域,您需要实现 Spring 的
org.springframework.beans.factory.config.Scope接口,并将其配置到Spring容器中。
1.3 数据库连接设置
连接池(Connection Pool)是一种用于管理和重用数据库连接、网络连接或其他资源连接的技术,旨在提高应用程序性能和资源利用率。连接池通过维护一组已创建的连接实例,并在需要时分配这些连接,以减少创建和销毁连接的开销。
这里的连接池本质是一个线程池,里面是一大堆线程。
以下是连接池的工作原理和好处:
工作原理:
初始化连接池: 在应用程序启动时,连接池会初始化一定数量的连接实例,这些连接可以立即使用。
连接分配: 当应用程序需要使用连接时,它向连接池请求一个连接。连接池会检查是否有可用的连接实例,如果有,则分配一个给应用程序。
连接使用: 应用程序使用连接执行数据库查询、网络通信或其他操作。
连接释放: 当应用程序完成连接的使用时,它将连接释放回连接池,而不是立即关闭连接。连接池会重新标记这个连接为可用状态。
假如要支持10万用户,需要在连接池里面配置多少数据库连接?
连接池的建议计算公式为:
理论依据:
一般情况下处理器存在超线程技术,一个 Core 上可以并行运行两个线程;
在 I/O 操作过程中 CPU 一般会出现空闲状态,因此加上能够同时进行 I/O 操作的有效磁盘数;
超出建议的连接数后,过多的连接数反而会导致很多无意义的 context switch,提升了 switch overhead,降低 CPU 资源利用率;
因此我们可以说,数据库连接数只与机器资源有关,与外部的连接情况无关。
Chapter 2. 异步通信:Message Queue
2.1 同步通信 versus 异步通信
同步通信的缺陷:
代码通常是紧耦合的,可扩展性差,并且多与软件 / 平台 / 语言相关;
当模块内部需要相互交流时,要维护的接口 API 数量会爆炸式上升;
性能堪忧。相较于相同项目实现的单体架构,同步调用方式会多出网络等待时间,以及阻塞时延;
没有请求消息 buffer,当接口忙碌时会出现错误(然后数据丢失);
通信不是 replayable 的,过于依赖请求响应模型(好处:易于编程,坏处:不可靠);
异步通信的优势:
模块间进一步解耦(发布者和订阅者间无需知道相互之间的信息,data-driven);
可拓展性强(scalable),添加实例无需更改代码;
异步性能有明显提升;
故障隔离(最终一致性保证),确保消息能正确发送 或者 出错时及时按策略处理(可靠性);
缓存消息,实现流量削峰填谷;
系统对等性(A message system is a P2P facility),所有端都可以收发消息,降低维护 API 数量;
异步通信缺点:无论是消息还是异常,都通过异步通信,并且通信实现编码比较麻烦。
2.2 Kafuka
一个开源的分布式事件流处理中间件,以发布订阅模式进行事件处理。
Kafuka 基于日志(Log)管理消息。
这里的 “日志” 是一种仅追加(append-only)的数据结构,常用于捕获有序事件序列。
仅追加的好处是顺序写,充分利用磁盘特性,提升写的性能(Logged-Structure Merge Tree 就是利用这种特性的键值存储系统);
现在将 Kafuka 想象成一种消息队列,然后消费者利用记录的 offset 读取队列中的消息,能消费多少是多少。
2.2.1 Kafka 的高性能
那么 Kafuka 如何应对并发量更高的场景?
为了提升消息队列的吞吐量,可以将队列分类为多个队列,每个队列对应一类消息。“一类消息” 就被称为一个 topic;
生产者按 topic 向对应队列投递消息,消费者则针对性地按 topic 订阅,大大减小一个队列的压力;
但是如果这样做还不够呢?
Kafuka 将每个 topic 拆成多个 partition,多个消费同一个 topic 的消费者就可以消费不同的 partition,继续提升队列吞吐量;但是不同 partition 不保证消费消息的先后顺序(原理:利用 hash 随机拿到 topic 中的 partition 下标,负载均衡地投递和消费),但每个 partition 内是有序的;
其中,一般可以对单个消息指定 key,key 可以确保相同的 key 被放到同一个 partition 中,确保必要的数据是有序的;
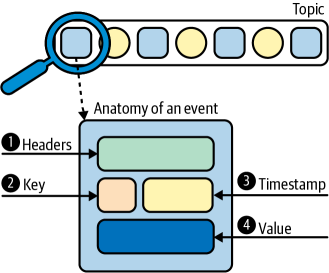
详细消息体组成如下:
2.2.2 Kafka 的高可扩展性
单个机器的性能总归是有上限的,我们需要提供可扩展性(scale 到其他机器上)。
Kafuka 通过将同个 topic 中的不同 partition 分配到不同的服务节点上。不同 MQ 服务节点位于不同物理机器上,这些节点被称为 broker,多个 brokers 组成了 Kafuka cluster;
2.2.3 Kafka 的高可用性
我们解释了 Kafuka 实现应对高 QPS 情况、高可扩展性的要求,不过还没有保证高可用性。
设想一种情况,如果 Kafuka cluster 的某个 broker 挂掉了,如何保证消息不会丢失?
和大多数解决可用性的分布式系统一样,直接采用主从的 replicas 副本,主称 leader,从称 follower;leader 同时承担生产者写和消费者读的请求,follower 仅同步 leader 的消息作为备份,并且 leader 和 follower 保证异地亲和性(不在同一 broker 上确保集群容灾);
这样当一个 leader 挂掉后,从同一个 partition 的 followers 中重新选举出 leader 服务,然后在之后的一段时间内补充 replicas 数量;
2.2.4 Kafka 的持久化 & 过期策略
到目前为止,数据全部位于内存。但是需要考虑最坏情况:所有 broker 全部挂掉,这样难道数据就丢失了吗?
所以为了保证高可用性和数据安全,还需要将数据持久化到磁盘中。问题是磁盘的容量有限,持续写盘总有一天会爆满,因此我们需要指定消息的保留策略(retention policy)。常见的保留策略可以是:磁盘大小超过一定比例、消息放置超过一定时间。
2.2.5 Kafka Consumer Group
目前还有个问题,现在读消息队列的方式还是通过消息队列中的 offset 方式来读,但是如果多个消费者想访问一个 partition,那么它们将不得不共用一个 offset,首先是降低并发性能,其次是不灵活,没法满足不同的消息消费需求。
所以 Kafuka 的 partition 引入了消费者组(consumer group)的概念,让同一个消费者组内维护一套针对各个 partition 的 offset,实现更加灵活的消息订阅;
2.2.6 ZooKeeper & KRaft
在分布式系统中,有很多状态需要维护,比如说,之前我们提到多个 brokers 有几个挂了、哪些 partition 需要重新选举 leader、具体怎么选举,消费组的 offset 给谁维护,等等。这些状态一般可以用分布式协调组件完成。其中 Apache ZooKeeper 就是一种选择。
但是 ZooKeeper 的开销相当大,在一般小规模的分布式应用上很不划算,因此人们开发出轻量级的协调算法 KRaft,现已广泛应用在多种分布式系统中。
2.2.7 Kafka Serializers & Deserializers
和 RabbitMQ 一样,我们可以自定义序列化方式:
xxxxxxxxxxspring kafka producer bootstrap-serverslocalhost9092 key-serializerorg.apache.kafka.common.serialization.StringSerializer value-serializerorg.springframework.kafka.support.serializer.JsonSerializer consumer bootstrap-serverslocalhost9092 auto-offset-resetearliest properties spring json trusted packages'*' key-deserializerorg.apache.kafka.common.serialization.StringDeserializer # 注:这里更常用的是 org.springframework.kafka.support.serializer.JsonDeserializer # 这里为了展示选择的多元性选择了 ByteArray 的解码器,意味着 Listener 端需要以 ByteArray 接收 value-deserializerorg.apache.kafka.common.serialization.ByteArrayDeserializer2.2.8 实践:如何使用 Kafka?
先介绍 Spring + Gradle 引入:
xxxxxxxxxxdependencies { implementation 'org.springframework.kafka:spring-kafka'}我们再介绍使用 KRaft 启动并管理 Kafuka 集群(而非 ZooKeeper):
启动单个 broker:
首先使用
bin/kafka-storage.sh random-uuid生成 cluster ID;创建 Kafka 日志目录
bin/kafka-storage.sh format -t <cluster ID> -c config/kraft/server.properties;启动服务
bin/kafka-server-start.sh config/kraft/server.properties;
至此单个 broker 已经成功启动并且使用;
启动 Kafka Cluster:
一般情况下 cluster 由 docker compose / Kubernentes 管理;这里介绍手动启动方式,理解后就能放到这些管理工具中。
使用上面同样的方法获取 cluster ID,不过注意同一个 cluster 需要使用同一个 cluster ID 确保之后能成功连接;
在多台服务器 / 物理节点上配置
config/kraft/server[N].properties;注意,node.id、listeners端口(如果 cluster 在一台机器上)、logs.dir需要不同(N标号可有可无,但如果在一台机器上则需要不同);分别启动服务:
bin/kafka-server-start.sh config/kraft/server[N].properties;
下一步介绍如何在 Spring Boot 中编码使用 Kafka:
和 RabbitMQ 类似,在 Consumer 类中:
声明 Consumer Listener:使用
@KafkaListener(id: String, topics: String | String[], groupId: String);groupId指定 Consumer Group;声明 消息队列 Topic(和 RabbitMQ 在 Consumer 端声明交换机、队列的道理一样):在
@Configuration类(自动注入)中定义@Bean,返回NewTopic对象;其中NewTopic对象使用TopicBuilder构建;TopicBuilder重要构建方法:.name(String)设定 topic 名称、.partition(int)设定分区建议、.replicas(int)设定主从副本数;
在 Producer 类中:
使用 KafkaTemplate<TopicType,DataType>.send(topic: String, data: Object) 来发送数据;
也可以使用 KafkaTemplate.send(topic, key, data),不过接收时需要 CustomerRecord<KeyType,ValType> 来处理;
Chapter 3. Web Socket
3.1 Definitions
一种全双工(full-duplex)的应用程序协议,基于 TCP 传输层协议(意味着需要 handshakes)。
它能帮助 Web Application 摆脱传统的 HTTP 请求-响应式通信模式,使通信方式更灵活。
Server 段需要在注册服务时发布 endpoints,然后 Clients 通过 endpoints 的 URI 连接 server;
包含两个部分:handshakes & data transfer;
Clients 和 Server 可以在连接建立时互相发送消息,使用
Sec-WebSocket-key(client)和Sec-WebSocket-Accept识别连接是否可以建立;
其中 WebSocket URI scheme:ws://<host>:<port>/[path](SSL 加密 wss);
3.2 Coding WebSocket
创建一个 endpoint 类(继承于
Endpoint类型),并向ServerEndpointConfig注册它:xxxxxxxxxxServerEndpointConfig.Builder.create(<Endpoint>.class, <path String>).build();实现 endpoint 的生命周期方法(如
onOpen、onMessage、onError、onClose);有两种方法可以实现,一种是原生实现,例如:
xxxxxxxxxxpublic class EchoEndpoint extends Endpoint {public void onOpen(final Session session, EndpointConfig config) {session.addMessageHandler(new MessageHandler.Whole<String>() {public void onMessage(String msg) {try {session.getBasicRemote().sendText(msg);} catch (IOException e) { ... }});}}或者是简洁的 annotation 实现(无需继承):
xxxxxxxxxx("/echo")public class EchoEndpoint {public void onMessage(Session session, String msg) {try {/* 获取当前 endpoint 维护的所有已打开的 session *//* 但是客户端很多时,需要想办法使用多线程/多进程处理 */for (Session sess : session.getOpenSessions()) {if (sess.isOpen())sess.getBasicRemote().sendText(msg);}} catch (IOException e) { ... }}/* 可以根据发送消息类型重载多个方法 */public void binaryMessage(Session session, ByteBuffer msg){ System.out.println("Binary message: " + msg.toString()); }public void pongMessage(Session session, PongMessage msg) {System.out.println("Pong message: " +msg.getApplicationData().toString());}}向 endpoint 中添加业务逻辑;
在前端添加相应的请求代码,将 endpoint 应用在一个 Web Application 中;
下面用一个例子说明:
假设有一个需要实时显示股票信息的 Web Application,我们先定义后端的 Endpoint:
xxxxxxxxxx("/stock")public class StockEndpoint { /* 使用可并发的队列 */ static Queue<Session> sessionQueue = new ConcurrentLinkedQueue<>(); /* 定义发送方式 */ public static void send(double price, int volume) { /* 手动格式化为字符串 */ String msg = String.format("%.2f,%d", price, volume); try { for (Session s: sessionQueue) { s.getBasicRemote().sendText(msg); log.debug("Sent: {}", msg); } } catch (IOException e) { log.error(e.toString()); } } public void openConn(Session session) { /* 手动管理 session 队列 */ sessionQueue.add(session); log.info("Connection opened with {}", session.getSessionId()); } public void closeConn(Session session) { sessionQueue.remove(session); log.info("Connection closed with {}", session.getSessionId()); } public void errorHandler(Session session, Throwable t) { sessionQueue.remove(session); log.error("Connection error: ID {}", session.getSessionId()); log.error("Connection error message: {}", t.toString()); }} 然后定义 WebListener 以及用于定时触发的工具类 ReportBean(用于后端 Web Application 处理定时任务):
xxxxxxxxxx// file: StockListener.javapublic class StockListener implements ServletContextListener { private Timer timer = null; public void contextInitialized(ServletContextEvent event) { timer = new Timer(true); timer.schedule(new ReportBean(event.getServletContext(), 0, 1000)); event.getServletContext().log("The report task is added"); }}
// file: ReportBean.javapublic class ReportBean extends TimerTask { private ServletContext context = null; private Random random = new Random(); private double initPrice = 100.0; private int volume = 300000; public ReportBean(ServletContext context) { this.context = context; } public void run() { context.log("Task started"); price += 1.0 * (random.nextInt(100) - 50) / 100.0; volume += random.nextInt(5000) - 2500; StockEndpoint.send(price, volume); context.log("Task ended"); }}然后在前端完成对应任务:
xxxxxxxxxxexport default function MainPage() { const [price, setPrice] = useState("--"); const [volume, setVolume] = useState("--"); useEffect(() => { var wsocket; function connect() { wsocket = new WebSocket("ws://localhost:8080/stock"); wsocket.onmessage = onMessage; } function onMessage(event) { /* 手动解码 */ var arr = event.data.split(","); setPrice(arr[0]); setVolume(arr[1]); } connect(); return () => { wsocket.close(); } }, []); return <> <h1>WebSocket Stock Display</h1> <table> <tr> <td width="100">Ticker</td> <td align="center">Price</td> <td id="price" style="font-size:24pt;font-weight:bold;">{price}</td> </tr> <tr> <td style="font-size:18pt;font-weight:bold;" width="100">TestStock</td> <td align="center">Volume</td> <td id="volume" align="right">{volume}</td> </tr> </table> </>;}我们可能还需在此基础上继续改进,例如定制消息的编解码过程,将这段业务逻辑从 WebSocket 连接中解耦出来,还能实现代码复用。这个时候就需要我们定义 WebSocket 的 encoder 和 decoder 了;
3.3 WebSocket Encoder & Decoder
实现 Encoder.Text<T>(文本消息)或 Encoder.Binary<T>(二进制消息)其中一个接口:
注:解码器就是
Decoder.Text<T>和Decoder.Binary<T>;
xxxxxxxxxxpublic class MessageATextEncoder implements Encoder.Text<MessageA> { public void init(EndpointConfig ec) { }
public void destroy() { }
public String encode(MessageA msgA) throws EncodeException { // Access msgA's properties and convert to JSON text... return msgAJsonString; }}xxxxxxxxxxpublic class MessageTextDecoder implements Decoder.Text<Message> { public void init(EndpointConfig ec) { } public void destroy() { } public Message decode(String string) throws DecodeException { // Read message... if ( /* message is an A message */ ) return new MessageA(...); else if ( /* message is a B message */ ) return new MessageB(...); } public boolean willDecode(String string) { // Determine if the message can be converted into either a // MessageA object or a MessageB object... return canDecode; }}然后在 @ServerEndpoint(value = <path>, encoders = {}, decoders = {}) 中指明添加的编解码器,并使用 Session.getBasicRemote.sendObject() 发送;
接受端的 onMessage 函数参数除了 Session 以外,还需要适配解码器输出的数据类型。
3.4 STOMP over WebSocket
我们现在知道如何在 Web Application 中使用 WebSocket 了,但如果有更高阶的需求呢?例如,如果我想模仿发布-订阅模式对一类 clients 发送消息,或者说为 WebSocket 添加一个含 topic 的消息队列的高级包装,应该怎么办?可以考虑使用 STOMP 来完成这个需求。
后端以 Java Spring 为例,先引入依赖:
xxxxxxxxxxdependencies { implementation 'org.springframework.boot:spring-boot-starter-websocket'}其内置了 STOMP(simple/stream text oriented message protocol 流式文本定向消息协议),这种协议基于 Web Socket 规范了简单的面向文本的消息传输的方案/机制。
然后对于前端需要引入:
xxxxxxxxxxnpm install stompjs sockjs-client @types/sockjs-client加入项目的方法分几步:
配置 Web Socket Endpoint 以及 STOMP 的 broker 信息:
xxxxxxxxxxpublic class WebSocketConfig implements WebSocketMessageBrokerConfigurer {public void configureMessageBroker(MessageBrokerRegistry config) {/* 设置 in-memory 的 WebSocket 消息传输队列的 path */config.enableSimpleBroker("/topic");/* 设置 WebSocket 处理前端主动请求的 path 前缀 */config.setApplicationDestinationPrefixes("/app");}public void registerStompEndpoints(StompEndpointRegistry registry) {/* 设置 WebSocket STOMP 监听服务运行在哪个 endpoint 下 */registry.addEndpoint("/websocket-endpoint").withSockJS();}}配置 Web Socket 消息处理方法(WebSocket 处理前端主动请求的方法体):
xxxxxxxxxxpublic class MessageHandler {/* 接受前端主动请求的 path 地址(不包含前缀) */("/send")/* 从后端要将处理好的消息放到消息传输队列的指定 path 上 */("/topic/messages")public Message sendMessage(Message message) {return new Message("Hello, WebSocket!", "System");}}最后在前端编写代码,例如主动请求后端并通过订阅 STOMP 消息队列(这种订阅的方式是 STOMP 规定的),来接收后端传来的消息,并且通过设定的端口主动向后端发送 WebSocket 请求:
x/* 使用 sockjs-client 库传入 WebSocket endpoint 以方便之后建立连接 */var socket = new SockJS('/websocket-endpoint');/* 基于当前 WebSocket 配置创建 STOMP 客户端 */var stompClient = Stomp.over(socket);/* 根据 STOMP 协议建立连接,配置订阅函数(指定后端发消息后的 handler) */stompClient.connect({}, function (frame) {stompClient.subscribe('/topic/messages', function (message) {var messagesList = document.getElementById('messagesList');var listItem = document.createElement('li');listItem.textContent = message.body;messagesList.appendChild(listItem);});});/* 主动向后端发送消息的函数 */function sendMessage() {var messageInput = document.getElementById('messageInput');stompClient.send('/app/send', {}, messageInput.value);messageInput.value = '';}
上面就是大致的接口和使用方法。不过这些接口还可以有一些使用经验技巧,能够完成一些特殊的需求。例如:
实现实时消息传递:无论是从前端传来的消息,还是后端向前端发送的消息,都能呈现在前端。这可以通过新建一个 STOMP 消息 topic / 新建请求 endpoint 来解决;
实现群发消息(消息队列广播):更改
StompEndpointRegistry的 Delivery Mode 即可:xxxxxxxxxxpublic void configureMessageBroker(MessageBrokerRegistry config) {config.enableSimpleBroker("/topic");config.setApplicationDestinationPrefixes("/app");config.setBrokerDeliveryMode(MessageBrokerRegistry.BrokerDeliveryMode.BROADCASTING);}这样后端发往
/topic/*的消息会被广播到所有客户端。
Chapter 4. SQL 数据库进阶:事务
4.1 Definitions of Transaction
定义:事务是一系列必须全部成功完成的操作,否则每个操作中的所有更改都将被撤消。事务以提交或回滚结束。
目标和意义:它的目的很简单,也非常重要:通过确保成批的操作要么完全执行,要么完全不执行(包装原子操作),来维护数据库 / 应用程序数据 / 其他分布式状态的完整性 和 一致性。
因此事务具有原子性、一致性、隔离性(函数隔离)、持久性,四者合称 ACID。
讨论范围:以数据库为首的 Resource Manager(后面介绍)在持久化资源时的行为。
事务的特性 ACID:
Atmoic:事务是一个原子操作单元,要么操作完全不执行,要么全部执行;
Consistent:事务开始前和结束后,确保系统状态是一致的;
注:“确保系统状态的一致性” 主要指:
确保不会有的状态是处理后的,而有的是处理前的;
施加的所有数据约束在事务执行前后必须得到满足,不能被破坏;
Isolated:执行数据操作的系统提供一定的隔离机制,确保事务不受外部并发操作影响 而 “独立” 执行;
举例:两个不同事务并行执行,二者修改同一状态数据。这个时候在任一事务内部,不会出现某一状态不修改就改变的情况;
Durable:事务提交的修改是持久化的。这确保事务一旦 commit,哪怕系统故障也能保持。
操作:
事务(transaction):需要定义一个事务 从哪里开始,到哪里结束;
回退(rollback)指撤销指定事务的过程,通常回滚到前面某个检查点,或者事务开头;
提交(commit)指将未落盘的事务处理的状态 / 结果写入数据库表(持久化);
4.2 Problems of Transaction for Database I: Isolation
考虑一个问题,有没有可能多个事务操作一个数据状态?
这个问题一般出现在数据库中,因此特别地,下面的问题都在讨论数据库的事务处理。
肯定是有的。这样就可能会发生数据读写的问题:
4.2.1 Conflicts
脏写(dirty write):两个事务写同一个数据,造成数据不一致性;
此级别连最基本的并发保护都没有,现实中不可能有数据库允许这么设计。
就是 “写写冲突” 导致脏写:

脏读(dirty read):一个事务读到另一个事务修改后但未提交的数据。如果 “另一个事务” 撤销了修改操作,就会造成数据不一致性;
就是 “写读冲突”、 导致脏读、脏写:

不可重复读(unrepeatable read):一个事务在另一个事务修改记录的操作前后读的结果不一致(同一个数据的修改);
就是 “读写冲突” 导致不可重复读:

幻读:一个事务在另一个事务添加、删除记录的操作前后查找的结果不一致(数据记录的增删);
问题的严重性从上到下依次减弱。
在 MySQL 中,使用的默认事务引擎是 InnoDB,可以用于处理大量短期事务(尤其适合的扁平事务)。那么 MySQL 是如何解决以上的问题的呢?
注:扁平事务 Plain Transaction,这种事务通常的操作周期很短,比较少发生回滚事件。
4.2.2 Isolation Level
在事务引擎中存在 4 个事务隔离级别:
| Isolation Level | Dirty Read | Unrepeatable Read | Phantom Read |
|---|---|---|---|
| Read Uncommitted | YES | YES | YES |
| Read Committed | NO | YES | YES |
| Repeatable Read | NO | NO | YES |
| Serializable | NO | NO | NO |
Read Uncommitted:在这个隔离级别下,事务引擎允许一个事务读到另一个事务未提交的更改,性能最好,但麻烦最大(没有采取任何隔离措施,3 个问题都存在);
Read Committed:在这个隔离级别下,事务引擎只是不允许一个事务读到另一个事务未提交的更改,解决了脏读,但是仍然会出现不可重复读、幻读的问题;
Repeatable Read:MySQL InnoDB 默认的事务隔离级别。在这个隔离级别下,事务引擎提供给单一事务的数据是保持不变的(即第一次读的结果会像被缓存起来一样);
Serializable:强制事务串行化,读取每一行数据都加锁。此隔离级别下会严重影响性能。但是在一些连幻读都不允许的场合下有用。
隔离级别的性能从上到下依次降低,但是处理问题的有效性依次上升。
数据库使用方应该根据业务场景进行 trade off,最后在数据库连接上说明配置;
4.2.3 Implementations of Isolation in DB I: Locks
现在我们考虑,数据库如何实现这些隔离级别。
其实,数据库和普通程序在处理数据并发问题的思路是类似的:加锁。
我们记两个同时发生的事务 A、B,共同访问资源 R。现在有几种锁 / 措施可以选择:
read lock:读锁,事务 A 加这个锁,则未提交前:A 在读 R 时,B 无法写 R(可以防止 A 出现 Unrepeatable read。但如果 B 不加锁,B 就会 unrepeatable read);
write lock:写锁,事务 A 加这个锁,则未提交前:仅 A 在写 R 时,B 无法写 R,但 A 和 B 都可能发生脏读(读到这个脏数据);
exclusive write lock:互斥写锁,事务 A 加这个锁,则未提交前:仅 A 在写 R 时,B 既无法读、也无法写 R(可以同时防止 A、B dirty read);
snapshots:数据快照,每个事务开始前创建一份当前的数据快照;可避免 3 种隔离问题,但可能导致数据不一致,需要额外处理;
于是利用上面的措施,我们尝试实现这些隔离级别:
如果多线程同时操作一个数据,不作任何隔离措施,MySQL 数据内存缓存共享(因为同进程)、硬盘也共享。此时出现脏写及其他所有问题。这个时候可以通过给写的记录加 long duration write lock(可读);加锁后是 Read Uncommitted,会出现 dirty read;
如果多线程同时操作一个数据,不共享内存数据,并且给该数据加读锁+写锁(read & write lock,只能读,释放前不能写)。这就是 Read Committed 级别,另一个线程可能出现 unrepeatable read;
另一个线程可能看到数据是 A 状态,等下一时刻可能就读出 B 状态了;
如果多线程同时操作一个数据,不仅不共享内存,而且给该数据加互斥写锁(不能读不能写)。这就是 Repeatable Read 级别,但当前线程可能出现 phantom read;
一个线程如果在事务中途修改其他记录,那么另一个线程在事务中查询记录的结果就不一样了;
如果多线程同时操作一个数据,不仅不共享内存,而且给:
这个数据所在的整个表加互斥写锁(称 “表锁”);
或给适用于某种查询条件的记录加互斥写锁(称 “谓词锁”);
或为每个事务创建 snapshot + 版本管理和后处理。
这就是 Serializable 级别;
4.2.4 Implementations of Isolation in DB II: MVCC
除了用锁实现隔离级别,以 MySQL 为首的数据库大多还使用 MVCC 的机制。
4.2.5 Implementations of Isolation in DB III: Scheduling
两个事务如果真的要同时操作一个数据,就一定需要报错吗?能否通过某些手段正确地完成双方的并行操作?
事实上真正的数据库想要实现隔离环境下的并发,不仅仅依赖于锁,还可以使用合适的调度策略来完成。
或者我们可以从另一个理论层面表达:“是否真正需要报错”。我们现在从理论层面探究:什么时候并发处理会出错(不可串行化调度)、什么时候可以通过适当的调度策略实现完美高效的并发(可串行化调度)。
为了更好地解释并发控制过程中,数据库对事务的处理流程,首先引入一个概念:调度。调度为事务的并发过程中,决定事务中每个操作的执行顺序。
为了方便讨论,我们将所有操作抽象为读、写操作(使用读写序列描述事务执行过程)。例如更新:read(X) -> offline edit(X) -> write(X);
这样数据库调度问题,就是数据库决定哪一种读写序列是正确的。
考虑一次场景的两种调度:

第一种调度恰好是事务的串行执行,因此被称为 “串行调度”;第二种调度是某一种(没有锁措施)事务的并发执行,被称为一种 “并发调度”;
我们定义哪些事务能够通过适当的调度实现高效并发:
给定一个并发调度
可串行化调度的数量十分巨大,且难以校验,数据库中一般通过找到可串行化调度的子集(充分条件),即找到能够提前确认是可串行调度的并发调度,进而提升调度效率;
再考虑一个例子:

这种事务场景下,我们找到了(存在)一种并发调度方案(4)使得它与串行调度方法的结果是一致的,因此我们认为这个(4)调度方案是可串行化的调度(就是说,这种并发的调度可以实现和串行化一样的效果)。
那么如何判断一个调度是否可串行化?如何实现可串行化调度(也就是用性能好的并行调度实现串行化的效果)?就像前面介绍的,我们一般通过充分条件找容易验证的方案:
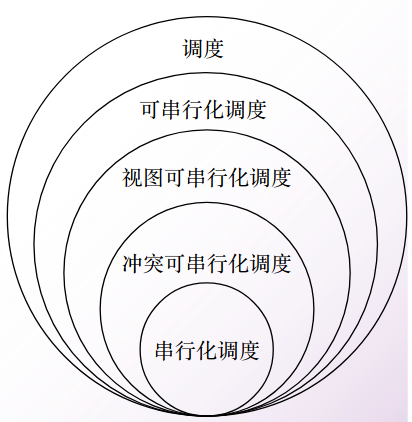
终态可串行化:如果两个调度方案的结果一致,则一定是可串行化的调度;
例如,我们上一章在 Serializable 的实现中,“为每个事务创建 snapshot + 版本管理和后处理” 就是一种通过 “先执行” 的方式,来在试探可串行化性。如果不可串行化则向一方发出异常,或者其他解决方案。
冲突可串行化:直接判断调度方案的操作间是否冲突。不冲突则一定是可串行化调度;
视图可串行化:判断事务操作流程是否一致(初始化读、读写顺序、最终写的一致性),一致则是可串行化调度;
其属性关系如下:
这里讨论一下 “冲突可串行化” 的判断方案:操作交换。我们定义:交换事务相邻两操作的顺序,如果不改变最终结果相同,则称这是一次等价交换(两个调度是等价的)。并且,如果调度
这相当于建立了一个等价类。就像你在解线性方程组,初等行变换不会改变最终结果,因此 “初等行变换” 是秩等价变换。
另外,我们在实际进行交换操作时,可以通过判断交换后是否会产生上面的 3 种冲突(写写冲突、写读冲突、读写冲突)。
根据交换等价以及 冲突可串行化调度的定义,我们直接有结论(通过等价类理解):若冲突可串行化调度
因为这个保序性,由离散数学的理论,我们可以借助拓扑排序描述等价类间互不可等价交换的关系,称 “优先级图”。若调度
数学上可以证明:这个图有环等价于
这也是可串行化调度中,最容易代码实现、并验证的一种。因此多数数据库采用这种方式,结合 2PL(2-phase lock)来实现事务隔离机制。
另一个是视图可串行化调度,它的条件更宽松,因此也能识别更多的可串行化调度,但是它的计算难度更大。
这种情况有可能是 “盲写”。也就是某个事务的写直接覆盖了共享资源上一个写,期间不存在读操作。如下:
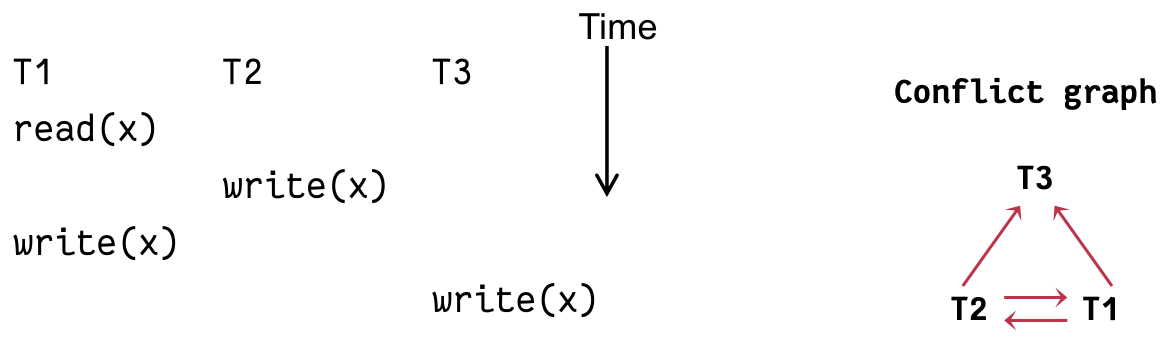
也就是这时 T1 -> T2 边可以被 “擦掉”。或者说,这三个事务本质上是可串行化的(视图可串行化)。
但识别这个事没有好的方法,只能穷举,因此我们说冲突可串行化更容易判断。
4.2.6 补充:Design Pattern of Locks
以上的隔离级别在数据库中自行帮我们实现。实际上,事务的锁还可以有其他的设计模式。
例如实现 Repeatable Read 级别时,数据库使用 exclusive write lock 锁定正在写的记录,这就是一种悲观锁。不过我们也可以使用乐观锁来实现这个目的。
数据库访问中,这几类锁(或者说设计模式)能充分利用现有的知识,提高数据的访问效率:
乐观离线锁(Optimistic Offline Lock):如果使用的 workload 的访问模式中,读远多于写,这个时候可以乐观地认为一个数据很少需要保护(写回的概率很低,那么写回冲突的概率会更低)。所以这种锁不会真的锁定数据,而是:
完全开放数据读的请求;
应用写数据时,规定应该先读入应用内存,在其中做完修改操作(离线写),最后再提交更改给数据库;
在每一个记录后追加版本号的字段,初始为 0,由数据库本身控制;数据库在真正写之前检查应用写数据中的版本号和这条记录当前版本号是否一致。只有一致才允许写入,并且自增版本号;否则向写的一方抛出错误;
悲观离线锁(Pessimistic Offline Lock):如果使用的 workload 访问模式中,写多于读,这个时候悲观地认为一个数据被离线地读走,很可能是正在进行写操作。所以这种锁是真的锁,在一条记录被读走的时候上锁,其他任何线程来访问(读 / 写)这条记录都会抛出错误;
上面讨论的是在一条记录 / 一个表的层面的锁可以如何设计。如果我想跨表锁住整片对象呢?
粗粒度锁(Coarse-Grained Lock):在锁住一条记录的同时,一同锁住与其关联的其他记录 / 对象(跨表加锁)。粗粒度锁也分悲观和乐观:
乐观粗粒度锁的实现方法,可以是让关联的记录对象全部持有一个共享的版本对象。在成功更新任一记录时就自增这个版本号,能实现目标效果;
悲观粗粒度锁的实现方法,可以是让关联的记录对象全部持有一个共享的版本对象,并且在一个线程读走这个对象任一字段时,给这个版本对象上细粒度互斥写锁。这样下一个线程读关联字段后会发现共享的版本对象无法读取并抛出错误。
举例:
网上书店下达订单的过程,适用于乐观离线锁。大部分人在浏览书籍,只有少部分人真正正在下订单,而且修改的是各自购物车 / 订单的数据,很少买同一本书,冲突的概率会更低;
记录用户访问次数的过程,适用于悲观离线锁。在没有缓存的情况下,用户每访问一次几乎都会触发一次写操作,如果用乐观锁,那么频繁的错误处理会降低事务的效率。
4.3 Problems of Transaction for Database II: Atomicity & Consistency
4.3.1 Rollback & Faults Recovery
讨论完数据库如何实现隔离性之后,我们再讨论一下数据库如何实现事务的原子性和持久性。或者说:数据库是如何实现事务回滚、故障恢复的。
故障类别:
事务故障(原子性可能破坏):数据库事务因为资源冲突或者死锁等原因导致执行失败;
系统崩溃(原子性和持久性可能破坏):数据库自身或操作系统的故障导致数据库进程意外退出;
磁盘故障(持久性可能破坏):数据因为磁盘(其他非易失性存储)损坏导致无法被读取;
自然灾害(持久性可能破坏):自然灾害对数据库系统所在的环境造成了彻底性破坏。
补充:系统的高可用指标
通用高可用指标:
平均故障间隔时间 MTBF(Mean Time between Failures):系统在两相邻故障间隔期内正确工作的平均时间;
平均恢复时间 MTTR(Mean Time to Repair):系统平均从故障中恢复需要的时间;
平均损坏时间 MTTF(Mean Time to Failure):系统出现损坏的平均时间;
数据库容灾指标:
恢复点目标 RPO(Recovery Point Objective):业务系统在系统故障后所能容忍的数据丢失量;
恢复时间目标 RTO(Recovery Time Objective):业务系统所能容忍的业务停止服务的最长时间;
4.3.2 Implementation of Atomicity & Consistency in DB: Logs
为了应对上面的问题,一般情况下数据库的应对机制概括如下:
| 问题类型 | 出现频率 | 对事务的影响 | 解决思路 |
|---|---|---|---|
| 无故障下事务回滚 | 高 | 原子性 | 单机数据库恢复 |
| 事务故障 | 较高 | 原子性 | |
| 系统崩溃能重启 | 中等 | 原子性/持久性 | |
| 系统崩溃不能重启 | 低 | 持久性 | 一主多备 |
| 磁盘故障 | 低 | 持久性 | 数据多副本 |
| 自然灾害 | 极低 | 持久性 | 异地多机恢复 |
我们详细讨论数据库针对上面的情况作出的具体解决方案:
A. 事务故障 / 系统崩溃
先定义一些概念:
脏页:内存页面已更新,磁盘页面未更新;
刷脏:将内存脏页刷到磁盘;
原因:可能是 操作系统中止/软件故障、死锁等等。
考虑下面的例子:
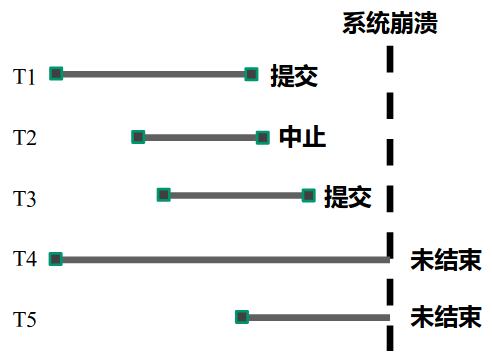
T1 和 T3 在崩溃前已经提交了事务。是否说明不会有问题了呢?
不一定。在 T1/T3 提交事务后,不一定会完成落盘(分布式系统更需要考虑这个情况)。如果崩溃时没有落盘,就需要 重做(redo,以保证持久性);
同样的道理,T2 如果在进行事务时,存在落盘操作(可选的策略),但是在中止(回滚)事务后、崩溃前没有来得及重新刷盘(恢复数据,以保证一致性),则也需要 重做;
T4/T5 在崩溃时刻并没有结束事务,则考虑它们是否落盘,如果落盘了就一定需要回滚当前事务已做的部分(恢复到进行事务前的状态,以保证原子性);不落盘就皆大欢喜。
针对上面的策略,我们已经发现了有几种不同的刷盘策略了:
为了保证原子性,未结束事务可以采取两种刷盘方式:
NO-STEAL(非窃取):未结束事务不能将脏页写入磁盘;
优点:不存在原子性问题,这样一举解决 T2、T4、T5 可能存在的关于原子性的隐患;
缺点:事务执行过程中不能刷新磁盘,因此必须占有较大的缓冲区空间,不利于多个事务的并发执行;
STEAL(窃取):未结束事务能将脏页写入磁盘;
优点:增大多个事务的并发能力,提升消息吞吐量;
缺点:影响原子性,需要回滚(考虑上面的 T2/T4/T5 的情况);
为了保证持久性,已完成事务可以采取两种刷盘方式:
FORCE(强制):已完成事务强制将脏页写入磁盘,这也是为了保证持久性大家最常想到的;
优点:不存在持久性问题,解决 T1/T3 的关于持久性的问题隐患;
缺点:每次事务提交都必须刷新脏页,消耗大量 IO 读写资源;
NO-FORCE(非强制):已完成事务不强制将脏页写入磁盘,影响持久性,需要重做(优缺点与 FORCE 相反);
最终,“重做” 交给一个文件结构 redo log(重做日志)、“回滚” 交给另一个文件结构 undo log(回滚日志);
| Aspects | FORCE(事务提交强制刷盘) | NO-FORCE(事务提交非强制刷盘) |
|---|---|---|
| NO-STEAL(执行期间不刷盘) | ❌ redo log & ❌ undo log | ✅ redo log & ❌ undo log |
| STEAL(执行期间可刷盘) | ❌ redo log & ✅ undo log | ✅ redo log & ✅ undo log |
补充:数据库日志的实现方式
那么在众多策略中,MySQL 这种主流的数据库管理系统采用的是什么策略?
答案是 STEAL 配合 undo log + NO-FORCE 配合 redo log(刷盘时机:全部异步刷盘);
注:刷盘时机设计
数据库关闭时,缓冲区中的所有脏页需要写回磁盘;
缓冲区中的数据页面已经满了,如果需要继续读入数据页面,就必须将被替换的脏页写回磁盘;
数据库会设置一个单独线程定时刷脏(全量 / 增量);
知识补充:日志、数据库日志、预写日志
日志是日志记录(log record)的序列,也是一种数据结构。所有的日志内容顺序写入磁盘,写入后不会修改(即不会随机写),能保证高效的写入效率。正因为这个特性,所以才有学者提出 LSM Tree(Log-Structured Merged Tree)作为一种高效键值存储数据结构;
数据库日志是数据库系统内一系列执行事件的记录,它与数据库事务是密切相关的,事务的执行过程会反映在日志中,数据库可以通过对日志的分析实现对事务的回滚(原子性)或重做(持久性);
预写日志(Write Ahead Log),即日志先于数据写入硬盘。这样可以确保在系统崩溃重启后有效恢复。
数据库日志的共性是:
都会对事务开始、提交和中止进行记录(
都需要满足预写日志(WAL)的条件。例如 undo log 需要在事务执行期间的刷盘动作前写回、redo log 需要在事务提交落盘前写回;
按照我们上面对数据库日志的需求来讨论:
Undo Log(回滚日志):
结构:
产生时机:当事务
write(X))时产生;作用:实现事务回滚;
Redo Log(重做日志):
结构:
产生时机:和 Undo Log 一样在
write(X)时产生;作用:实现事务重做;
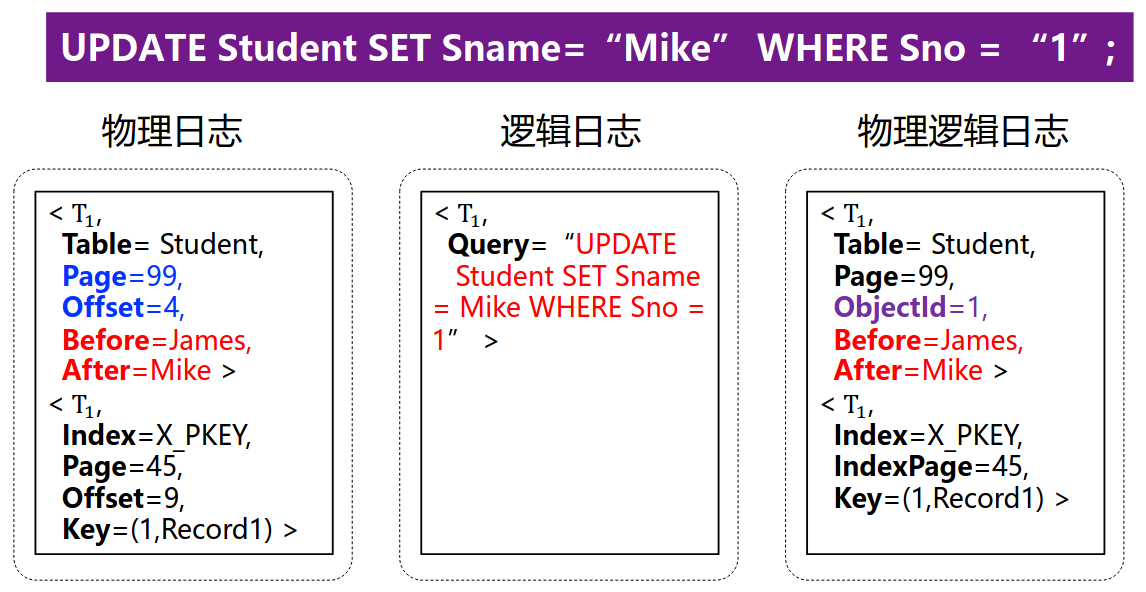
除了按照 undo/redo 的功能区分日志,为了进一步了解这些日志本身的实现,还需要从日志性质上分类并讨论:
逻辑日志:记录事务中高层抽象的逻辑操作(例如:例如小明的年龄由20改成21);
物理日志:记录数据库中数据项的具体物理变化,例如针对某个数据项,其存放的真实物理参数(如物理磁盘位置、数据结构偏移量等)一系列变化:

物理逻辑日志:一种结合了物理日志和逻辑日志的混合描述方法。包含了数据页面的物理信息,但是页面以内目标数据项的修改信息则是以逻辑方式记录(例如:第100个页面(物理)的小明年龄值由20改成21(逻辑));
比较一下 3 种日志:
其实无论从哪个方面分,数据库日志评判的 3 个重要性质,分别是:
幂等性:一条日志记录无论执行一次或多次,得到的结果都是一致的;
失败可重做性:一条日志执行失败后,是否可以重做一遍达成恢复目的;
操作可逆性:逆向执行日志记录的操作,可以恢复原来状态(未执行这批操作时的状态);
我们再借助这 3 条特性来对比这 3 种日志:
| Aspects | 解析速度 | 日志量 | 可重做性 | 幂等性 | 可逆性 | 应用场景 |
|---|---|---|---|---|---|---|
| 物理日志 | 快 | 大 | ✅ | ✅ | ❌ | redo log |
| 逻辑日志 | 慢 | 小 | ❌ | ❌ | ✅ | undo log |
| 物理逻辑日志 | 较快 | 中 | ✅ | ❌ | ❌ | undo log |
逻辑日志不具备幂等性:执行两次日志中的插入动作,状态会不断改变;
逻辑日志也不具备失败可重做性:因为数据库有索引设置。如果在操作
INSERT X附近系统崩溃,并且只对索引产生影响,但数据页面是正常的,但逻辑日志中会记录INSERT X,这会导致数据重做后不一致;逻辑日志具备可逆性:将记录的高级操作反过来执行就能达到撤销操作的目的;
因此逻辑日志不能用来作为 redo log,只能作为 undo log(回滚);
物理日志不具备可逆性:无法处理数据项位置变化的情况。例如 Database 中的 B+ 树结点分裂导致数据页面页号出现变动、并且数据偏移量还可能因为后续数据的插入而变动。这样就不能像逻辑日志一样反过来执行;
物理日志具备幂等性:是因为在重做时,哪怕是
INSERT操作也是向同一物理位置写同样数据,因此是幂等的;物理日志具备失败可重做性:即便数据库有索引,并且崩溃导致索引和数据页面不一致,但按照记录的物理位置从初始状态一步步重做插入,一定能还原到相同状态;
因此逻辑日志一般用于 redo log;不能用于 undo log;
另注:物理逻辑日志用于回滚时,特别是索引页面分裂,可通过页面前后指针来完成回滚;
具体实现方法:
NO-STEAL + FORCE: shadow copy 算法;
STEAL + FORCE:基于 undo-log 的恢复算法;
不需要考虑事务重做(no redo);
在故障后恢复 / 事务回滚时,需要:
反向扫描 undo-log,找到所有未完成的事务(没有 commit/abort 闭合 start 块的事务);
对每一个未完成的事务,按日志中的顺序从后到前,一步步执行抵消的操作(使用
在执行结束抵消操作后,写入该事务中止的日志(
STEAL + FORCE 方法的局限性:
每次事务提交都需要强制刷盘,造成随机页面读写多,性能差;
难以实现主备数据同步;
NO-STEAL + NO-FORCE:基于 redo-log 的恢复算法:
不需要考虑事务回滚(no undo);
事务提交时将日志刷盘;
在故障后恢复,需要:
正向扫描 redo-log,找到所有已完成的事务;
如果已 Commit 的事务已经刷盘,可以不用重做。后续通过 checkpoint 检查点机制来判断是否刷盘,从而可以实现刷盘的事务不需要重做;
如果遇到未 Commit / abort 的事务,也可以不用重做;
如果已 Commit 的事务未刷盘,则进行下一步;
重做这些已完成的事务的每一步骤,写入日志;
写入未完成事务结束的日志;
NO-STEAL + NO-FORCE 方法的局限性:
事务并发受限:事务执行期间不能刷盘,那么 buffer 满了后就需要等待;
一个提交的事务和一个未提交的事务都改了某个页面,请问是否应该将这个页面刷盘呢?
STEAL + NO-FORCE(最终方案):基于 redo/undo log 的恢复算法;
在故障恢复时,需要:
反向扫描 undo log、正向扫描 redo log,出现没有闭合的
<T start>则判定为未完成事务、反之是已完成事务;重做阶段:在正向扫描 redo log 后按序将已完成(标注重做)的部分再次执行(重放历史)、未完成部分插入
<T abort>;撤销阶段:在反向扫描 undo log 后将未完成(标注回滚)的部分撤销执行,并插入
<T abort>。
补偿日志机制:为了防止在恢复过程中再次崩溃而不知晓恢复的进度,人们设立 “补偿日志”,每次执行 undo 日志记录后,数据库需要向日志中写入一条补偿日志记录(compensation log record,CLR),记录撤销的动作,也就是实现了 undo 日志的 redo,记录已经 undo 的日志,保证 undo 不被重复执行;
检查点机制:数据库的日志会随着事务的执行不断变长,这会使恢复时间也相应地变长,需要压缩日志大小来降低恢复的时间。人们因此设计了一种检查点(checkpoint)机制,检查点定义了一个脏页刷盘的时刻,要求检查点之前的日志记录对应的缓冲区数据页面修改已经刷新到磁盘。这样:
在检查点之前完成(commit/abort)的事务不需要处理;
在检查点之后 commit/abort 的事务需要重做;
所有未完成的事务(不含commit/abort)需要回滚;
4.4 Problems of Distributed Transaction in Different Database (Atomic)
这里我们继续讨论数据库事务。上面关于事务隔离性、原子性和持久性的解决方案还算好懂,那么我们能说完全掌控事务了吗?
可惜没有。有一类重要并且比较困难的事务:分布式事务,它尤其难以保证 ACID。为什么?主要是因为我们上面的措施大多是都是针对单个数据库中执行的事务。
如果是在多个数据库(多个数据源)中的操作组成的事务,我们想保证这个事务的原子性就比较困难,因为事务的 Part A 在一个物理节点上完成,Part B 在另一个物理节点上故障了,那 Part A 是很难感知到另一个物理节点的 Part B 的故障的。
为了保证分布式事务的原子性,人们提出了 Two-Phase Commit 的机制。在分布式事务提交前,实现了 two-phase commit 的事务管理框架会做两件事:
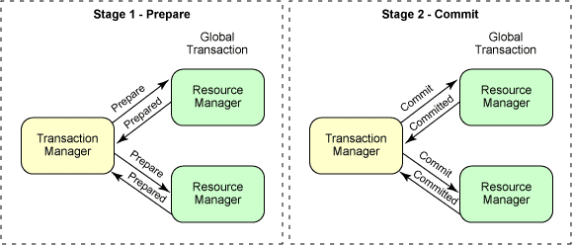
事务管理框架会分别向多个数据源发送检查申请。只有所有数据源都为事务准备就绪,才会进入下一阶段;
事务管理框架接着逐一质询多个数据源 “事务是否可以提交”,并采取一票否决制:任何一个数据源需要回滚时,事务管理框架会决定全局事务全部回滚;
只有当事务管理框架在质询结束、确定决策,并且回复各个数据源,各个数据源才能继续进行提交或回滚操作;
注:Resource Manager 不仅仅指数据库。只要是支持事务的系统,在这里都可以称为 Resource Manager。例如邮件服务器、消息中间件等等。现在我们讨论的事务可以从数据库事务抽象为一般 Resource Manager 的事务。
好,这里考虑最坏情况。如果第 3 步发送决策信息时网络中断了:
假设
能提交、 需要回滚,然后事务管理框架在向 或 发送回滚信息时与 的连接掉线了,导致 事务超时。 注意,因为事务的隔离级别造成的性能消耗,所以一般情况下事务总是设定了超时时间。事务超过超时时间后会对提交和回滚操作进行猜测。
所以在
超时后,如果 猜测应该进行事务提交(有概率猜错),就会造成不一致性,并且事务原子性失效。 这种错误概率相当小(因为可以做重连等补救措施),但很难避免:如果你要更强的校验机制,那就会降低性能以及可用性。这也是分布式系统的 CAP 问题。
又由于日志中会体现超时的警告,因此可以后续人为地修复数据一致性。
所以总结:分布式事务的 Two-Phase Commit 协议不能避免 stage 2 网络或其他原因引发的启发式错误,进而导致的数据不一致性。分布式事务始终是有概率出错的。
Sidebar:在 Spring 框架中,Spring IoC Container 如果发现同一个事务内部操作了两个不同的数据源,则会被判定为一种分布式事务,进而使用 Two-Phase Commit 协议,不需要在业务逻辑层面进行适配。
另外,请注意区分 Two-Phase Lock 和 Two-Phase Commit。前者作为 Lock 可以是帮助实现数据库事务隔离性的一种方法;后者是分布式事务原子性的保证协议。
4.5 Transaction in Spring
总结:
| Propagation Type | 当前线程存在事务 | 当前线程不存在事务 |
|---|---|---|
| REQUIRED_NEW | ❗️挂起,创建新的,结束后恢复 | ✅ 创建新事务 |
| REQUIRED | ✅ 加入当前事务 | ✅ 创建新事务 |
| SUPPORTS | ✅ 加入当前事务 | 🚫 没有动作 |
| MANDATORY | ✅ 加入当前事务 | ❌ 抛出异常 |
| NOT_SUPPORTED | ❗️挂起,不创建新的,结束后恢复 | 🚫 没有动作 |
| NEVER | ❌ 抛出异常 | 🚫 没有动作 |
注意,以上注解如果针对 Method,那么会在方法的生命周期两端进行(方法进入、方法退出)检查。
Chapter 5. SQL 数据库进阶:优化
SQL Engine 会将 SQL 通过 Query Plan 进行类似编译优化的步骤再执行;
SQL 会将通过 Query Plan 得到的查询结果缓存(cache);
优化思路如下:
数据库表的结构是否恰当?更具体地:
每一列的数据类型(Number 使用 Integer 8 bytes 还是 String 11 bytes?Char 还是 Varchar?);
是否对正确的列建立合适的索引?
对 title / author / price 哪种数据建立索引更有利于查询?
是否使用合适的存储引擎?
例如 MySQL 中支持事务的引擎 InnoDB 和并发性能好的引擎 MyISAM;
每个表是否有合适的行格式?
是否动态:还是以 Char/Varchar 为例,究竟是节约空间、牺牲查询性能,还是将表构建得更规则,空间换时间?
是否进行压缩:数据库很多记录前面一部分列都相同,能不能就存一份?
使用什么锁机制?使用什么隔离级别?
如何在内存中为缓存配置合适大小?
硬件级别优化:
系统级瓶颈优化:
磁盘读写(SSD / HDD);
磁盘寻道性能;
CPU 频率;
内存带宽;
还有注意平衡可扩展性和性能:
例如使用了 MySQL Dialect 特有的 SQL 语句,就应该注释标明。
5.1 索引
5.1.1 Overview
在 SQL 中,索引就是适当地排序数据,以加快搜索的速度。并且,索引是按照列(数据项)来建立的。
建立索引可以对不是 UNIQUE 的列。
MySQL 中,索引也是一个文件,如果是基于 B+ 树的引擎,那么一个索引的 block 中可能含有若干个树的结点。例如,B+ 树的 1 个结点放一个 block 中,那么读一个结点可以排除结点分叉数量的分支数,大大增大了查找速度。
有一些情况下不适合使用索引,比如从本身的性质上说,可能有如下问题:
索引改善检索操作的性能,但降低了数据插入、修改和删除的性能。因为在执行这些操作时,DBMS 必须动态地更新索引;
在数据源上插入、删除、更新数据,会导致对应的 B+ 树索引出现变动,例如结点分裂、合并等行为。
并非所有数据都适合做索引。
取值不多的数据(如州)不如具有更多可能值的数据(如姓或名),能通过索引得到那么多的好处;
较小的表维护索引带来的代价甚至大于直接 scan 这个表;
索引数据可能要占用大量的存储空间(排序结果需要存起来);
B+ 树本身有较大的空间开销,数据量小的情况下,甚至浪费了空间。
适用索引的场景:
数据过滤和数据排序。如果你经常以某种特定的顺序排序数据,则该数据可能适合做索引;
经常按某列为标识查找数据;
索引还需要管理员定期检查。索引的效率随表数据的增加或改变而变化。许多数据库管理员发现,过去创建的某个理想的索引经过几个月的数据处理后可能变得不再理想了。最好定期检查索引,并根据需要对索引进行调整。
5.1.2 Implementations
其实 MySQL 中不仅可以用 B/B+ 树来实现普通索引。例如:
稀疏索引:R-trees 查询 key 范围的索引;
Hash 索引:Memory tables(视图等内存中的数据结构)支持 hash indexes;
倒排索引:InnoDB 在 Full-text indexes 中采用 inverted lists(倒排索引表);
聚簇索引(cluster index):索引的顺序和数据存储的顺序完全一致的索引
5.1.3 MySQL 何时会使用索引
快速查找与 WHERE 子句匹配的记录;
如果表有多列索引,query plan 可以使用索引最左侧的任何前缀查找记录;
用 JOIN 从其他表中检索记录;
查找特定索引列
key_col的MIN()或MAX()值;对表进行排序或分组,如果排序或分组是根据可用索引的 leftmost prefix 进行的(例如,
ORDER BY key_part1, key_part2);在某些情况下,可以对查询进行优化,以便在不查阅数据行的情况下检索值;
5.1.4 列索引优化
前缀索引
使用 index prefixes 在建立索引时更快。并且越短越好,因为一个 block 中可以盛放更多的记录。
可以只对一个列的前
xxxxxxxxxxCREATE TABLE test (blob_col BLOB, INDEX(blob_col(10)))对于索引前缀的长度:
对于使用 REDUNDANT 或 COMPACT 行格式的 InnoDB 表,前缀长度最多可达 767 字节。对于使用动态或压缩行格式的 InnoDB 表,前缀长度限制为 3072 字节。对于 MyISAM 表,前缀长度限制为 1000 字节。
如果搜索词超过了索引前缀长度,索引将用于排除不匹配的行,并检查剩余行是否可能匹配。
聚簇索引
索引的顺序和数据存储的顺序完全一致的数据存储方式叫做聚簇索引(又称 “主键索引”)。在 InnoDB 中,如果采用聚簇索引,那么表数据文件本身就是按 B+Tree 组织的一个索引结构,而且是以每张表的主键构造一颗 B+ 树,同时叶子节点中存放的就是表的行记录数据,也将聚集索引的叶子节点称为数据页。
作为 InnoDB Table 的存储结构,只要有主键哪怕不建索引也是有一个主键索引。
相对的是次级索引(secondary index,或 “辅助键索引”),一般是用户建表时指定的非主键的索引。这种索引建立的新 B+ 树,叶结点只放这个索引的键(列)以及对应的主键。所以查询时需要拿着主键二次查询才能找到记录,这就是 “次级索引” 名字的由来。

聚簇索引性能好的原因是顺序读。
因为索引记录的位置和存储的位置在顺序上是一样的,这样方便查找和读取。并且聚簇索引尤其适合按主键范围查找。例如:某个节点有多个子节点,从第一个节点到最后一个节点排出来顺序是依次递增的时候,这样显然在查找一个范围的时候就非常快,可以按照顺序来读取磁盘。
聚簇索引的缺点是,
聚簇索引的更新代价比较高,如果更新了行的聚簇索引列,就需要将数据移动到相应的位置。并且,在插入新记录或者更新时如果页满了,可能导致 “页分裂” 的问题;
插入速度严重依赖于插入顺序,按照主键进行插入的速度是加载数据到 InnoDB 中的最快方式。如果不是按照主键插入,最好在加载完成后使用
OPTIMIZE TABLE命令重新组织一下表;聚簇索引可能导致全表扫描速度变慢,因为可能需要加载物理上相隔较远的页到内存中(需要耗时的磁盘寻道操作)。
全文索引
MySQL 也支持全文索引的索引。MySQL 的 InnoDB 和 MyISAM 都支持针对 Char/Varchar/Text 列的索引。
只有当 entire column 和 column prefix indexing 不支持时才会使用。
MySQL 还针对单个 InnoDB 表的某些类型的 FULLTEXT 查询进行了优化。具有以下特征的查询尤其高效:
只返回文档 ID 或文档 ID 和搜索排名的 FULLTEXT 查询;
按得分降序排序匹配行并应用 LIMIT 子句取前 N 条匹配行的 FULLTEXT 查询;
FULLTEXT 查询只检索与搜索词匹配的行的
COUNT(*)值,不需要其他 WHERE 子句。将 WHERE 子句编码为WHERE MATCH(text) AGAINST ('other_text'), 不加任何> 0比较操作符;
稀疏索引 (Sparse Index)
稀疏索引是相对于密集索引而言的,我们前面讨论的索引都是密集索引。
密集索引和稀疏索引的区分在与是否为每个索引键的值都建立索引,简单来说就是比如有一列的值 1、2、3、4、5、6、7,密集索引的做法是为这 7 个值都建立索引记录,那么就有 7 条索引记录;
而稀疏索引的做法是将这个 7 个值分组,1、2、3 和 4、5、6 和 7 分为不同的 3 组,取这三组中最小的索引键值作为索引记录中的索引值。
这两种索引都要通过剪枝来确定数据位置,不同的是密集索引,只需要找到叶结点就能确定准确的数据位置,而稀疏索引则需要先定位到目标结点后,从起始位置继续查找,以此定位具体的偏移量。
这两种不同的索引实现,一种建立了索引值与数据位置的 1:1 的关系,一种建立了索引值与数据位置 1:n 的关系。在大多数场景密集索引查询效率更高,在大多数场景稀疏索引占用空间更小。
总结与密集索引相比的优点:
节省存储空间,因为索引条目较少;
适用于顺序扫描和范围查询。
缺点:对于精确查找的效率较低,因为需要扫描更多的数据块。
空间索引 (Spatial Index)
对于空间索引,MySQL 的 InnoDB 和 MyISAM 引擎都支持 R-Tree 数据结构来存放索引。
那么什么时候会用 R-Tree 来建立空间索引呢?答案是碰到高维数据的时候。举个例子:
xxxxxxxxxx-- MySQL SPATIAL INDEX 会使用 R 树来索引 coordinates 列,从而加速空间查询CREATE TABLE locations ( id INT PRIMARY KEY, name VARCHAR(100), coordinates POINT, SPATIAL INDEX(coordinates));从这个例子注意到,空间索引对高维数据的临近查询比较友好。
多列索引(复合索引)
对使用多列的索引,MySQL 支持组合索引(composite indexes)。例如:
一个索引可以包括最多 16 个列;
对于某种 data type,可以按照组合索引只索引前几个 column;
多列索引的优势:
建立三个单独的索引比建立一个复合的索引要浪费空间,B+树的叶子节点存储要索引的值还有一个指向 硬盘的位置,而建立三个单独的索引,就需要三个树,叶子结点存储的同理,也就是说建立复合索引相 对来说更好。而且调整一棵树的速度比调整三棵树的效率显然要快的;
哪些查询 pattern 适合使用 multiple-column indexing?
涉及所有列的 queries;
涉及前 N 个列的 queries;
例如这么建索引:
xxxxxxxxxxCREATE TABLE test ( id INT NOT NULL, last_name CHAR(30) NOT NULL, first_name CHAR(30) NOT NULL, PRIMARY KEY (id), INDEX name (last_name,first_name));这种查询就能用上(只有一定先判断 last_name 再 first_name):
xxxxxxxxxxSELECT * FROM test WHERE last_name='Jones'; SELECT * FROM test WHERE last_name='Jones' AND first_name='John'; SELECT * FROM test WHERE last_name='Jones' AND (first_name='John' OR first_name='Jon'); SELECT * FROM test WHERE last_name='Jones' AND first_name >='M' AND first_name < 'N';而这种查询就没法用上:
xxxxxxxxxxSELECT * FROM test WHERE first_name='John';SELECT * FROM test WHERE last_name='Jones' OR first_name='John';也就是必须是 leftmost prefix of the indexes;
值得注意的是,即便某次查找用上了复合索引,也不代表对每一列的筛选条件都能真正利用这个索引。这很抽象,我们用一个案例解释一下:
假设数据库中一个表包含:{ a: int(PK); b: int(PK); c: int };
然后 MySQL 对两个主键自动建立复合索引,我们记为 PRIMARY_IDX;
我们手动对 b, c 建立复合索引(b 先 c 后),记为 NEW_IDX,我们讨论:
当筛选条件使用
a = 10 AND b = 7 AND c > 1时:两个复合索引
PRIMARY_IDX和NEW_IDX都是可用的;EXPLAIN可以看到使用到的索引键长度(key_len)为 8;因为这里直接使用a, b的联合主键索引能找到唯一记录,c > 1仅作为筛选条件,不再使用索引;
当筛选条件使用
a = 10 AND b > 7 AND c > 1时:两个复合索引都是可用的(对两个索引来说都是按顺序的 leftmost prefix);
EXPLAIN可以看到使用到的索引键长度为 8;因为这里使用a = 10和b > 7,两个列的复合索引键长为数据结构的长度和;已经可以确定记录集合(获得的结果不再是 B+ 树结果),再通过c > 1的筛选,没有再使用索引了;
当筛选条件使用
b = 7 AND c > 1时:只有
NEW_IDX是可用的;EXPLAIN可以看到使用到 d 的索引键长度为 8;此时使用b, c复合索引(另一棵 B+ 树);
当筛选条件使用
b > 7 AND c > 1时:只有
NEW_IDX是可用的;EXPLAIN可以看到使用到的索引键长度为 4;这时虽然用了b, c联合主键,但是只能对第一个出现的范围查找索引生效。主要是因为范围查找后不再是一个 B+ 树,而是一个 B+ 树集合,再对每个 B+ 树中筛选c > 1就没法利用索引了,只能顺序扫描遍历,因此只用到复合索引中的一列而已。
内存索引
MySQL 默认使用 Hash Indexes,不过也支持 B-Tree;
Hash 索引
比较一下 Hash Indexes 和普通 B+ 数索引的异同:
B-Tree Indexes 可以在对一列使用
=, >, >=, <, <=, BETWEEN这些操作符,以及不含 wildcard / 其他列 的LIKE操作符;Hash Indexes 主要用于判等性(单值)的 operators 例如
=, <>,远远快于 B-Tree Indexes。因此像 KVStore 这样的系统都依赖于这种索引。但是有以下问题:其他的范围性操作符均不支持,如
<;不支持顺序。不能用于加速
ORDER BY操作;
降序索引
指定让索引存储的键值降序摆放(因为有建索引后 ORDER BY XXX DESC 的需求,不用 descending indexes 会造成性能 penalty);
倒序索引还可以支持 multiple-column indexes 的混合升降序的优化(表事先定义一些索引方法);
5.2 主键优化
有几条策略:
当没有明显主键可以选择时,用自增主键;
在 InnoDB 中,主键的查询、排序的性能会相当地好;
如果使用随机生成的值作为 primary Key,也尽量前缀一个类似时间戳的递增的成分(如果允许的话);
一是考虑 InnoDB 聚簇索引的性质;
二是因为连续递增的 primary key 在 B+ 树上相邻,获取时顺序读,而且可以利用空间局部性,降低 disk I/O;
另外,有一种热门的问题,“究竟选 Java UUID 还是自增主键?哪个更好?”
这里涉及 UUID 和自增主键的选取问题。
UUID 的优势:
全局唯一性:通过不同算法生成,几乎能够保证在全球范围内的唯一性,从而避免了多台机器之间可能发生的主键冲突问题。
不可预测性:随机生成的 UUID 很难被猜测,因此在需要保密性的应用场景下非常适用。
分布式应用:由于可以在不同的机器上生成 UUID,因此可以被广泛应用于分布式系统中。
存储空间较大:UUID 通常以字符串形式存储,占用的存储空间较大。
UUID 的劣势:
不适合范围查询:由于不是自增的,不支持范围查询。新生成的 UUID 可能会插入到已有数据的中间位置,导致范围查询时出现数据重复或漏数据的情况。
不方便展示:UUID 通常比较长,且没有明确的业务含义,因此不太适合在系统间或前台页面进行展示。
查询效率低下:
在 UUID 列上创建索引会导致索引大小增加,从而影响缓存命中率,增加磁盘 I/O 需求,同时也增加了查询时的内存开销。
当使用 UUID 进行排序时,新生成的 UUID 通常会插入到叶子节点的中间位置,导致 B+树的频繁分裂和平衡操作,进而影响查询性能。
自增主键的优势:
存储空间节省:ID 为数字,占用的位数比 UUID 小得多,因此在存储空间上更加节省。
查询效率高:ID 递增,利于 B+Tree 索引的查询效率提高。
方便展示:ID 较短,方便在系统间或前台页面进行展示。
分页方便:ID 连续自增,有利于解决深度分页问题。
自增主键的劣势:
分库分表困难:在分库分表时,无法依赖单一表的自增主键,可能导致冲突问题。
可预测性:由于 ID 是顺序自增的,因此具有一定可预测性,存在一定的安全风险。
可能用尽:自增 ID 可能是 int、bigint 等,但它们都有范围限制,可能会用尽。
性能问题:在数据迁移期间,如果使用自增主键,数据库可能会产生额外的性能开销。这可能是由于重新计算主键值或更新相关索引所致。这可能会导致数据迁移过程变慢。
5.3 外键优化
如果一个表有很多列,而您要查询的列有很多不同的组合,那么将不常用的数据分割成单独的表,每个表只有几列,并通过复制主表中的数字 ID 列将它们与主表关联起来,可能会比较有效。
这样,每个小表都可以有一个主键,以便快速查找数据,而且可以使用 JOIN 操作只查询所需的列集。
根据数据的分布情况,查询可能会执行较少的 I/O,占用较少的缓存内存,因为相关列都集中在磁盘上。(为了最大限度地提高性能,查询会尽量少从磁盘读取数据块;只有几列的表可以在每个数据块中容纳更多行)。
5.4 数据库结构优化
Look for the most efficient way to organize your schemas, tables, and columns.
Minimize I/O, keep related items together, and plan ahead so that performance stays high as the data volume increases.
这首先从设计好的数据库开始,能让团队写出更高性能的代码,并让数据库可以承受 application 的迭代和修改的需求。
5.4.1 数据大小
从数据大小的角度,尽可能减小 table 在磁盘上占用大小。这能影响到一个事件内磁盘 I/O 的总体效率,并且总体内存占用少、索引占用也少。
优化 Table Columns:尽可能使用最小、最精简有效的类型。例如对于小一点的整型,使用
MEDIUMINT比INT节省 25% 空间;尽可能使用 NOT NULL:
在《高性能 MySQL》中指出,可 NULL 列需要额外的空间来说明这个值是否为 NULL(在 MyISAM 引擎中一列 1 bit);
难以优化引用可空列查询,它会使索引、索引统计和值更加复杂(需要在读取时测试一些值是否为 NULL),降低效率;
容易自己写出错误,即
NOT IN、!=等负向条件查询在有 NULL 值的情况下返回永远为空结果;
如果语义上实在需要 NULL,可以保留。只是要避免默认全是可空的情况。
优化行格式:创建表时指定合适的 row format;
COMPACT、DYNAMIC、COMPRESSED 这些方式通过牺牲 CPU 在某些操作上的性能换取更低的存储开销;
例如使用一些 variable-length character set(utf8mb3/4 之类的)时,可以降低
CHAR类型列的存储开销;会通过 stripping trailing spaces 的方式减小存储开销;
REDUNDANT:意味着
CHAR(N)就会占用N倍的 charset 大小;许多程序是用 single-byte utf8 characters 来写,所以这种配置大部分情况下都是浪费空间;
FIXED:每列固定长度,在一些场景下能加速查找或其他操作的性能,但可能造成一些空间浪费;
if you do not have any variable-length columns (VARCHAR, TEXT, or BLOB columns);
you want to have fixed length rows even if you have VARCHAR columns;
优化索引:设计表时建立合适的索引;
尽量少地创建索引,只对能提升查询性能的列索引。虽然索引提取很简单,但是维护会损耗插入和更新操作的性能。并且不是所有情况都适合;
如果经常组合特定的列查询,则对这些列建组合索引,而不是分别索引;
主键索引应该越短越好。这样:区分每一列的速度更快、block 存放更多更易 cache;并且在 InnoDB 表中 primary key columns 会在 secondary index entry 中重复,所以为了整体的存储效率应该短一点;
注意到 UUID 和 自增主键的选取中也提到此条。
一个比较长的字符串列,更有可能有 unique prefix。因此仅对这些列的 prefix 索引(参见 “前缀索引”),好处包括但不仅限于检查更快、更容易 cache;
优化 JOIN 操作:决定是否放在一个表,还是分两个表,需要时再 JOIN;
在某些情形下(例如 dynamic-format table 中)分成两个表(smaller static format)搜索速度更快;
在需要 JOIN 的表中尽量用一个相同信息和类型的列(如外键),方便 JOIN 操作;
尽量将列名起得简练一些(考虑到兼容性、SQL JOIN 查询便捷性);
标准化:
考虑遵循第三范式,减少数据冗余性;
如果性能比空间、维护多份重复数据的开销更重要,则可以适当放宽范式条件;
5.4.2 MySQL 数据类型
针对数值类型数据优化:当数值和字符串都能描述数据时,优先数值。因为它的存储效率更高,传输、处理和比较成本更低;
针对字符/字符串型数据优化:
选择 binary collation order(二进制规则顺序),能加快比较、排序的速度;
query 比较不同 columns 时,尽量避免字符串;如果不能,也要保证使用的是同一个 character set 和 collation;
对于小于 8KB 数据,应使用 Binary Varchar 而不是 BLOB;
因为如果表没有 BLOB 类型的 column,GROUP BY 和 ORDER BY 子句可以生成临时表格,并利用 memory engine 加速;
如果一个表的 string column 不经常被查询,考虑将它们拆分出另一个表,并且必要时 JOIN;
因为可以提升每个 block 的记录数量,提升 cache 数量,减小 disk I/O 次数。并且定长 row 利于查找优化;
针对 BLOB 类型优化:
包含大量 textural content 的 BLOB 首先需要压缩;
考虑将 BLOB 分出另外一个表,甚至分到其他存储设备上,来降低单条记录的查询成本;
比起在 query 中直接比较很长文本的相等性,应该计算 hash 存在单独一列中用于比较;
5.5 数据库多表优化
5.5.1 MySQL 如何管理 Open/Close Tables
对于数据库中的很多表而言,MySQL 需要对这些表进行管理,让不同的 client(connections)都能获得比较快的速度。
有一种方案是和 OS 的 File 一样,在内存中管理 File Descriptor 和 Open File Table,后者可以在所有进程间复用。
在 MySQL 中,每个表可能在不同的 connections 中都打开过,因此当你执行 mysqladmin status 发现 open tables 数量多于实际表数时也不要疑惑。
由于 MySQL 是多线程程序,为了让多个 client 访问的 table 不至于冲突(尤其是事务冲突),会有 锁 和 MVCC 来管理修改操作。其中对每一个 session 而言都有一个独立的 open table,以防止数据依赖,达到空间换时间的效果。
对于 MyISAM 引擎的表来说,每个打开的数据文件还需要多存一个 file descriptor。
我们一般通过配置信息来影响数据库效率:
table_open_cache:与max_connections有关。如果max_connections = 100,则最多与 100 个 client 建立连接,按一个连接中任意查询中最多关联到的表的个数N来计算,应该设置table_open_cache = 100 * N,还要考虑到为临时表以及文件(Internal Temporary Table / Files)预留一些 file descriptors;具体什么时候产生临时表/临时文件,请参考官方文档 Internal Temporary Tables - Oracle;
以上二者同时影响 server 最大能打开的文件数。设置过大超过 OS 处理能力或者 file descriptor 限额,会导致性能下降、不稳定甚至错误(refusing connections or failing to perform queries);
MySQL 会在如下场合关闭 opened table(必要时写回):
evict:cache 满了,但是 client 尝试打开一个不在 cache 中的表;
full 情况下的 evict 策略:
对没有线程使用的表,采取 LRU 抛弃策略;
如果所有表都被使用中,则临时扩大一下 cache(由 “too many idle tables” 策略回收);
too many idle tables:cache 中包含超过
table_open_cache数量的表,并且该表没有被任何线程使用;flush tables:当 FLUSH 操作进行时;
由上面的策略,我们可以侧面看出,如果 MySQL 的 table_open_cache 设置偏少,会出现以下现象(可以作为检查的方案):
检查 Open tables 数据非常大(远大于设定值),并且从数据库刚启动时就快速增长,而此时 FLUSH 操作并不多。
同时,MyISAM 这样保留 open tables 还是有弊端的。主要是拿空间换时间,而且可能过犹不及。
Disadvantages:
open tables 过多的话,打开、关闭、创建操作性能下降;
select 如果同时关联很多表,则没法很好地利用空间局部性(主要是 workspace 不够大,会频繁 cache evict);
5.5.2 数据库数量限制调优
数据库/数据库表的数量
MySQL 默认不限制数据库和数据库表的数量。
数据库的物理上限为底层文件系统的最大目录数(for databases);
数据库表的极限除了受到文件系统的 “文件(for tables)数量限制”,还受存储引擎自身限制。如 InnoDB 最多支持 40 亿张表;
数据库表的大小
MySQL 最大表大小默认不限制,取决于文件系统单个文件大小。
一旦出现达到表最大大小的情况,MySQL 会抛出 full-table error,主要原因如下:
磁盘可能满了;
达到底层文件系统的单个文件大小上限;
例如 Windows 系统上的 FAT/vFAT 文件系统最大支持 4GB 文件,这种文件系统显然不适合用于运行大型 MySQL 数据库;
如果使用的是 MyISAM 存储引擎,则可能是超过了 internal pointer size 默认允许的空间(256 TB);
回想一下 MyISAM 的主键索引使用的是指针;
MyISAM 引擎允许数据和索引文件最大 256 TB,当然可以人为设置这个限制,限制的上限是 65536 TB;
如果使用的是 InnoDB 存储引擎,则可能是表对应的 tablespace file 达到大小极限了;
Tablespace File 是 InnoDB 中用于管理一个或多个数据表以及相关的索引的数据的文件。
根据配置主要有 3 类:System tablespace、File per tablespace、General tablespace;
包括但不仅限于:
InnoDB data dictionary.
DoubleWrite Buffer.
Change buffer
Undo Logs.
以及表本身数据、索引数据。
可以通过分多个 tablespace files 解决这个问题。官方只建议在大于 1 TB 的情况时再考虑;
数据库表的列数和行的大小
MySQL 硬编码表的列数限制:一个表中不得超过 4096 个列。InnoDB 表额外限制不允许超过 1017 个列。
最终,最大表列数应该取决于:
最大的行数(限制了列的数量和大小);
Functional Keys:使用隐藏的虚拟生成列实现,因此也要考虑它的大小;
值得注意的是,表的最大行大小不取决于表的最大大小!
哪怕存储引擎能够放的下更大的行大小,实际上 MySQL 也限制了表的最大行的总大小为 65535 bytes;
注:其中 BLOB 和 TEXT 这种大数据类型,MySQL 直接使用指针存储(指针指向另一个文件中,专门用于存储此类数据)。
因此 BLOB 和 TEXT 总是仅占用一行 9~12 bytes 的大小。
在这个前提基础上,还有一些规则会影响实际使用中的表的最大行的大小:
对于 InnoDB 引擎,存储在本地 database page 中的表,其最大大小略小于 page size 的一半;
注:可以通过设置
innodb_page_size来设置一个 page 的大小;不同的 storage format 使用不同大小的 page header 和 trailer data,也会影响最大行大小。
举例说明:
xxxxxxxxxxCREATE TABLE t (a VARCHAR(10000), b VARCHAR(10000), c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000), f VARCHAR(10000), g VARCHAR(6000)) ENGINE=InnoDB CHARACTER SET latin1; 上面这个表默认 row format 是 dynamic 的,一行长度为 66000 bytes,超过限制,因此无法创建成功;
下面这个表用 MyISAM 引擎也是一样不允许(MySQL 规定)。
xxxxxxxxxxCREATE TABLE t (a VARCHAR(10000), b VARCHAR(10000), c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000), f VARCHAR(10000), g VARCHAR(6000)) ENGINE=MyISAM CHARACTER SET latin1;由于 BLOB 和 TEXT 采用指针存储,因此这么定义又没问题(InnoDB 同理):
xxxxxxxxxxCREATE TABLE t (a VARCHAR(10000), b VARCHAR(10000), c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000), f VARCHAR(10000), g TEXT(6000)) ENGINE=MyISAM CHARACTER SET latin1;还需要注意,NOT NULL 这类限定词也会占用一行中的空间(通常是每个字段 1 byte)。
这种不行:
xxxxxxxxxxCREATE TABLE t2 (c1 VARCHAR(65535) NOT NULL) ENGINE = InnoDB CHARACTER SET latin1; 但这种(65533)可以:
xxxxxxxxxxCREATE TABLE t1 (c1 VARCHAR(32765) NOT NULL, c2 VARCHAR(32766) NOT NULL) ENGINE = InnoDB CHARACTER SET latin1;
5.6 InnoDB 表优化
5.6.1 InnoDB 存储效率优化
MySQL 支持使用
OPTIMIZE TABLE <table>优化较大的表,来 reorganize、compact 碎片化的空间;这个步骤的原理是,将数据从原表中 copy 出来,并且重建索引,减小 tablespace 中的 inner fragementation。
和主键优化一样,如果主键较长,可能导致构建索引时浪费空间;
如果是 long 数据,则可以考虑自增主键;
如果是 varchar 数据,则可以考虑前缀索引;
建议就使用
VARCHAR来存储长度可变的字符串,而不是CHAR,因为后者存在内部碎片(尤其是存在 NULL 的情况)。只有明确这个数据有固定的长度(例如学号始终只有 11 位)时才使用CHAR;如果表很大,并且含有大量重复的字符串、数值接近或重复的数值数据类型,那么考虑使用
COMPRESSEDrow format。但是注意是读写性能换空间;只有当空间很大,需要牺牲性能来节省空间时,才选择
COMPRESSED行格式;
5.6.2 InnoDB 事务优化
MySQL 默认
AUTOCOMMIT=1,意味着即便是每条普通的 SQL 也会创建一个单独的事务并提交(哪怕只读),这可能在一个繁忙的数据库中形成性能瓶颈;如果需要配置的话,可以 CLI 或建库脚本中
SET AUTOCOMMIT = 0;手动管理、人为划分事务边界。即便使用
AUTOCOMMIT,实际上 InnoDB 可能针对简单的只读(SELECT)事务,会进行一些优化;
避免在 插入/删除/更新 大量表记录 后执行 rollback;
如果需要回滚一个大的事务(尤其是发现一个大事务很卡,准备手动 rollback 它),意味着要重新读并执行 undo log,可能需要消耗比它本身耗时更长的时间来完成,恶化数据库的性能;
而且直接 kill 是没有用的,因为重启后还会恢复 undo/redo;
因此,一个大的事务本身就不合适,需要拆成若干适当大小的事务;
避免使用长期的事务(例如一次执行 2 h);
因为在 READ COMMITTED 或 REPEATABLE READ 中,两个事务可能操作了更多的相同记录的数据,就需要锁/MVCC 做更多的事情(例如读旧的值、更新值),进一步影响性能;
长期的含写事务会导致接下来的事务没法利用 Covering Index 来加速查询;
注:所谓 Covering Index,就是说不必查询表文件,单靠查询索引文件即可完成。它不是一个专门的索引数据结构,而是查询请求和当前索引匹配的现象。覆盖索引的好处,一是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的 IO 操作;二是不必回表;
但是 Covering Index 不能在有修改操作的事务正在执行时使用,因为修改过程中需要重构索引。
适当增大 buffer pool 大小(参见下文),可以减少写磁盘的频率,减小 disk I/O;
设置
innodb_change_buffering=all,减少更新删除的刷盘次数;
对于 InnoDB 只读事务优化(InnoDB 自动对这些只读事务优化,我们只需要知道如何让 InnoDB 知道就行):
使用
START TRANSACTION READ ONLY开始的事务;开启了
AUTOCOMMIT并且是一条单独SELECT语句;
因此能作为只读事务时,就标记
READ ONLY,以方便优化。
5.6.3 InnoDB 载入大量数据时优化
建议关闭
AUTOCOMMIT,因为不然每次执行后都会 commit 并且进行 log flush;xxxxxxxxxxSET autocommit=0;-- ... SQL import statements ...COMMIT;如果表中有次级索引的键被
UNIQUE修饰,可以考虑关闭 uniqueness checks(SET unique_checks=0;),最后再打开。但是需要确保确实没有重复的键;因为 MySQL 可以将修改写入 change buffer 并批量写,而不需要频繁的 disk I/O;
同样地,如果确定确保了插入数据的外键关联,也可以关闭外键检查:
SET foreign_key_checks=0;(通用)使用 multi-row
INSERT语法,能降低通信开销;xxxxxxxxxxINSERT INTO yourtable VALUES (1,2), (5,5), ...;如果向有自增主键的表导入数据,可以考虑设置
innodb_autoinc_lock_mode为 2(interleaved)而不是 1(consecutive);
5.6.4 InnoDB 查询优化
和主键优化一样,对最重要、查询热点的、时间关键路径上的列设定主键;
和主键优化一样,不用选一个很长的列作索引;
不要对太多列建立次级索引(secondary index),因为一次查询最多只能用到一个;
和 组合索引 一样,建议用到多个时组合索引,而不是各自建立索引;
和 “数据大小” 的优化一样,建表时尽量使用 NOT NULL;
InnoDB 内部也会对单个只读查询的事务优化,见前文。
5.6.5 InnoDB Disk I/O 优化
注意:不应该首先考虑对 InnoDB 的 disk I/O 优化。当你很好地遵循了数据库设计原则、tuning operations 后,性能瓶颈仍然在 disk I/O,例如性能很慢但 CPU 占用小于 70%,可以再考虑下面的优化:
适当提升 buffer pool 的大小:设置
innodb_buffer_pool_size,减小对硬盘读写次数;调整刷盘方法:设置
innodb_flush_method为O_DSYNC来延迟刷盘;配置刷盘阈值(fsync):设置
innodb_fsync_threshold。例如当多个 MySQL 使用同一存储设备时减小这个阈值可能提升性能;考虑选择固态,而不是机械磁盘(rotational storage)来增大随机写速率;
如果 MySQL 的吞吐量因为 InnoDB 事务的 checkpoint 而周期性降低,考虑增大
innodb_io_capacity(提升刷盘频率,avoiding the backlog of work that can cause dips in throughput);
5.6.6 InnoDB DDL 操作优化
使用
TRUNCATE TABLE而不是DELETE FROM *,因为后者还是需要一条条删除;如果有外键关联,可能 truncate 也不快,这个时候考虑先 drop 再 create;
由于 InnoDB 使用了聚簇索引,修改主键可能造成大量的重建操作。因此设计主键时就要避免修改操作;
5.7 MEMORY 表优化
对于不重要的、经常访问的、只读的、很少更新的数据,考虑存放在 MEMORY 表(
ENGINE=MEMORY);Memory 表使用和 MyISAM 一样的锁机制,因此在有读有写的场景下的性能甚至比不上 InnoDB;
另外,如果数据大小超过 Buffer Pool,还会发生换入换出,进一步降低性能;
根据经常查询的 pattern(单独判等还是范围查找)来选择合适的索引(B-Tree Index / Hash Index);在创建索引时,可以指定
USING BTREE或USING HASH;
5.8 Buffering and Caching
InnoDB 维护了一个称为 “buffer pool” 的存储区域,来在内存中缓存数据和索引。
InnoDB 在管理 buffer pool 的策略上使用了 LRU Algorithm,确保热点数据驻留在内存中:
新加入的 page 放在 LRU list 尾部
后
在严格的 LRU 配置下这些总不被访问的数据会被 “age out”,或者作为 cache evict 的首选对象;
对 InnoDB Buffer Pool 进行优化:
设置
innodb_buffer_pool_size(操作总是以 chunck 为单位);buffer chunck 大小
innodb_buffer_pool_chunk_size默认 128 MB。Buffer Pool 的大小总是需要满足:
innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances的整数倍;使用多个 buffer pool 实例(提升并发性能):设置
innodb_buffer_pool_instances;同样注意 buffer pool size 满足的整数倍关系,最好确保每个 pool 实例大小 1 GB;
默认 1,最大 64。pool size 总大小不足 1 GB 时该项无效;
设置 buffer pool 的预取(prefetch):根据程序的局部性原理,InnoDB 会异步作 page 预取(read-ahead),主要有两种形式:
Linear read-ahead:顺序预取(预取下一个相邻页);
Random read-ahead:根据 pool 中已有的的 page,在合适的 cadidates 中随机选取;
您可以
SHOW ENGINE INNODB STATUS检查 read ahead 的有效性,并且 tuninginnodb_random_read_ahead;设置 buffer pool 的 flushing 策略:
在 MySQL 8.0 中,buffer pool 的 flushing 工作交给 page cleaner threads 完成;
线程数量由
innodb_page_cleaners控制(默认为 4)。当 threads 数量少于 pool instances 数量时,自动设置 threads 数量与其相等;flushing 的阈值由
innodb_max_dirty_pages_pct_lwm控制,当 dirty page 比例超过阈值时 flush(默认 10%;0 表示禁用 early flushing);
buffer pool 的备份和恢复策略:
为了加速启动时 buffer pool cache 的 warmup 过程,InnoDB 在关闭前事先保存一些热点 page 并在启动时恢复。可以通过 tuning
innodb_buffer_pool_dump_pct来获得更好的性能;
Chapter 6. 数据库备份与恢复
回忆为什么需要备份数据库?
预防错误:system crashes (系统错误), hardware failures (硬件错误), or users deleting data by mistake (人为错误).
准备升级:as a safeguard before upgrading a MySQL installation;
准备从节点:为 replicas 创建提供原数据;
这些是我们之前提到的 Fault Recovery Mechanism(redo/undo)解决不了的。
如何备份?
逻辑备份 / 物理备份?全量备份 / 增量备份?
如何创建备份格式?(SQL/CSV 等等)
恢复方法如何?
备份时是否做调度(深夜进行?)、是否压缩、是否加密?
能否从被破坏的表中恢复出来?
6.1 备份和恢复的类型
物理备份:consist of raw copies of the directories and files that store database contents.
This type of backup is suitable for large, important databases that need to be recovered quickly when problems occur.
优点:速度快、备份和恢复简单;
缺点:不能改动数据库引擎,甚至小版本都需要一致;
适用场景:数据量极大的场景;
逻辑备份:save information represented as logical database structure (CREATE DATABASE, CREATE TABLE statements) and content (INSERT statements or delimited-text files).
This type of backup is suitable for smaller amounts of data where you might edit the data values or table structure, or recreate the data on a different machine architecture.
优点:只需要关系型数据库,大部分都可以转移;
缺点:备份和恢复的速度较慢、备份文件的存储效率不高;
适用场景:数据量不大的场景;
在线备份:take place while the MySQL server is running so that the database information can be obtained from the server.
优势:对用户、业务影响小,可用性好;
缺点:但是需要有复杂的、恰当的锁机制来确保数据一致性(The MySQL Enterprise Backup product does such locking automatically);
离线备份:take place while the server is stopped.
Clients can be affected adversely because the server is unavailable during backup. For that reason, such backups are often taken from a replica that can be taken offline without harming availability.
The backup procedure is simpler because there is no possibility of interference from client activity.
无论是备份时,还是恢复时,都有上述的讨论。
二者差别也被称为 “hot backups vs cold backups”;
Note
折中方案:a “warm” backup is one where the server remains running but locked against modifying data while you access database files externally(server 正在运行,但只允许读操作).
补充:
Customers of MySQL Enterprise Edition can use the MySQL Enterprise Backup product to do physical backups of entire instances or selected databases, tables, or both.
This product includes features for incremental and compressed backups.
And InnoDB tables are copied using a hot backup mechanism.
(Ideally, the InnoDB tables should represent a substantial majority of the data.)
Tables from other storage engines are copied using a warm backup mechanism.
本地备份:备份操作机器和 server 运行的机器是同一台;
远程备份:与本地备份相反,备份操作的机器和 server 运行的机器不是同一台(例如远程的 mysqldump);
但是:
使用
mysqldump的 SQL output(逻辑备份)存放在调用的 client 侧,Delimited-Text output(文本形式)存放在 server 侧;大多数情况下物理备份放在 server 侧;
快照备份(snapshot backup):使用特殊的文件系统,允许使用 logical copy(Copy On Write 延迟复制);
MySQL 自己不支持对文件系统快照,需要使用第三方解决方案。
全量备份:includes all data managed by a MySQL server at a given point in time.
增量备份:consists of the changes made to the data during a given time span (from one point in time to another).
通过 enable server 的 binary log(bin log)来让 MySQL 记录 data changes;
备份调度:对自动化备份至关重要;
备份压缩:减小备份带来的空间开销;
备份加密:提升对未授权访问 backed-up data 的安全防护;
这三个功能在 MySQL 社区版中都没有。
6.2 实践
使用 mysqldump 进行逻辑备份。对 InnoDB(支持事务)表,可以通过传入 --single-transaction 来实现无需加锁的 online backup.
如果进行物理备份:
如果是 MyISAM 表,需要停止 server / 给表加读锁(read lock 禁止写),然后 flush 对应的表(落盘,让所有 active index pages 写入磁盘),最后复制文件(
*.myd, *.myi, *.sdi);对于 InnoDB 表这么做不行,因为它存在 cache buffer pool,数据也许不会刷盘。这会导致数据不一致性;
如何使用 bin log 完成增量备份?
使用 FLUSH LOG 或 mysqldump --flush-logs 向文件中写入自从上一次备份结束后更改的信息。
使用 SHOW BINARY LOGS 查看当前哪些增量日志文件;
使用 SHOW MASTER STATUS 查看当前正在向哪个增量日志文件写;
使用 mysqlbinlog <binlog> 读未加密的 bin log 内容;
使用 mysqlbinlog --read-from-remote-server --host=host_name --port=3306 --user=root --password --ssl-mode=required binlog_files 读加密的 bin log 内容;
使用主从备份(using replicas):
适用场景:单机备份仍然有性能问题。此时可以考虑建立 replication 做备份;
官方文档说:
如果要备份副本,无论选择哪种备份方法,都应在备份副本数据库时,备份其连接元数据存储库(connection metadata repository)和应用程序元数据存储库。
在恢复副本数据后,总是需要恢复这些元信息。例如如果 replica 正在复制 LOAD DATA 语句,则还应备份目录中存在的任何
SQL_LOAD-*文件。replica 需要这些文件来恢复任何中断的 LOAD DATA 操作。
恢复被破坏的表:
对 MyISAM 表,只需要执行 REPAIR TABLE / myisamchk -r 就能解决 99.9% 的问题;
使用第三方工具做 snapshot 备份,例如 LVM、ZFS;
6.3 备份和恢复的策略
现在我们讨论更多的故障种类中,MySQL 现在可以进行的恢复机制。
对于 事务崩溃 / 系统崩溃 / 掉电,我们假设重启后磁盘没有问题,那么:MySQL 使用 redo log 和 undo log 找到 “已提交未刷盘事务” 重做刷盘、“未提交暂时刷盘事务” 撤销动作;
对于 文件系统崩溃 / 硬件(如磁盘)故障,我们假设重启后数据没法恢复,那么需要 主从备份/异地容灾的机制,并且重新格式化磁盘、安装新的文件系统,看看能否解决问题,并从其他物理结点恢复。
对于第二种情况,MySQL 没法完全帮我们恢复数据,因此我们需要一些策略来主动备份数据。大致的策略可以是 对数据库表周期性自动化备份。举个例子:
在星期天下午 13 点进行一次全量备份:
xxxxxxxxxxmysqldump --all-databases --master-data --single-transaction > backup_sunday_1_PM.sql在执行这个全量备份时,需要对所有 tables 上读锁。
为了方便和性能起见,全量备份虽然必要,但不应该频繁。因此接下来利用增量备份(需要启动时
--log-bin或者通过配置 enable bin log)自动完成;能在数据库目录中看到
*-bin.0000xxx/index的名称格式的文件,它们就是 bin log;为了节省空间,可以时不时清空这些 log(建议放到之前的全量文件中):
xxxxxxxxxxmysqldump --single-transaction --flush-logs --master-data=2 \--all-databases --delete-master-logs > backup_sunday_1_PM.sql假设在星期三早上 8 点,数据库崩溃,那么我们进行下面的恢复过程:
先恢复星期天创建的全量备份:
xxxxxxxxxxmysql < backup_sunday_1_PM.sql现在数据库所有信息全部恢复到星期天下午 13 点的状态(如果期间做过 bin log 删除,那么可能更新一点);
恢复从上次创建全量备份以后的增量备份文件,例如:
xxxxxxxxxxmysqlbinlog gbichot2-bin.000007 gbichot2-bin.000008 | mysql# 不应该使用多个 mysql connections 分别加入,可能会出问题,因为可能第一个文件有 CREATE TEMPORARY TABLE# mysqlbinlog gbichot2-bin.000007 | mysql# mysqlbinlog gbichot2-bin.000008 | mysql如果是硬盘损坏丢失了部分的 bin log,则数据就真的丢了。但如果我们一开始指定的 bin log 使用异地容灾的思想,记录在其他物理节点上,那么数据的丢失就可以避免了。
总结,定期使用全量(mysqldump)和增量(FLUSH LOGS / mysqladmin flush-logs + enable bin log)备份,其中全量备份的频率小一点,并且可以考虑异地容灾。
Chapter 7. 数据库分区
分区不等于分表!
对 MySQL 引擎 InnoDB 和 NDB 都支持分区。
本质上是将表拆成不同粒度的集合,每一块可以单独处理以提升查询速度。
分区的方式被称为 “partitioning function”,可以是用户指定的,也可以内置 hash / 线性 hash、分区列表,等等。
分区方式可以是:
Horiztonal Partitioning:different rows of a table may be assigned to different physical partitions;
到 2024 年为止,MySQL 没有计划支持 Vertical Partitioning;
因为意义不大,真要这么做,不如拆成两张表。
分区的好处:
让一张表中可以放更多数据,不受磁盘和文件系统的限制,成为一种可能。
可以便捷地、高效地清除某个分区中的所有无用数据、添加新数据(尤其是表很大的时候);
因为通常放在不同的地方,用指针管理?
某些查询能借助分区被极大地优化(例如
WHERE选择的都在某个分区内,会由 Query Plan 识别);这被称为 Partition Puring:“cutting away” of unneeded partitions is known as pruning;
MySQL 还支持显式按分区查询,如:
SELECT * FROM t PARTITION (p0,p1) WHERE c < 5;不光
SELECT,修改操作也能受益。显式使用被称为 Partition Selection;
7.1 Types of Partitioning
Horizontal Partitioning 主要可以被分为 4 类:
7.1.1 RANGE Partitioning
RANGE partitioning: 根据记录列在某一范围内的值为依据分区;
举例:
xxxxxxxxxxCREATE TABLE members ( firstname VARCHAR(25) NOT NULL, lastname VARCHAR(25) NOT NULL, username VARCHAR(16) NOT NULL, email VARCHAR(35), joined DATE NOT NULL ) -- 按时间年份范围分区(LESS THEN 中的值还需要升序排列,因为单边限制)-- 为何只支持单边限制?-- 首先考虑用户制定的可能不是连续区域、可能会重叠-- 便于用户修改(例如需要删除一个分区或添加一个分区)PARTITION BY RANGE( YEAR(joined) ) ( PARTITION p0 VALUES LESS THAN (1960), PARTITION p1 VALUES LESS THAN (1970), PARTITION p2 VALUES LESS THAN (1980), PARTITION p3 VALUES LESS THAN (1990), -- MAXVALUE 确保分区取遍 PARTITION p4 VALUES LESS THAN MAXVALUE );如果希望按时间戳范围,可以用类似 UNIX_TIMESTAMP('2008-01-01 00:00:00') 的方式转换成整型,然后使用 UNIX_TIMESTAMP(<col>) 做 range partitioning;
其中,RANGE partitioning 如果按 Column 分区(就是加上 COLUMNS),不仅可以不用整型,而且还允许多列分区:
xxxxxxxxxxCREATE TABLE rcx ( a INT, b INT, c CHAR(3), d INT, renewal DATE) -- 按 Column 分区,可以不使用整型PARTITION BY RANGE COLUMNS(a,d,c) ( PARTITION p0 VALUES LESS THAN (5,10,'ggg'), PARTITION p1 VALUES LESS THAN (10,20,'mmm'), PARTITION p2 VALUES LESS THAN (15,30,'sss'), PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE) );-- 例如可以不需要转成时间戳:PARTITION BY RANGE COLUMNS(renewal) ( PARTITION pWeek_1 VALUES LESS THAN('2010-02-09'), PARTITION pWeek_2 VALUES LESS THAN('2010-02-15'), PARTITION pWeek_3 VALUES LESS THAN('2010-02-22'), PARTITION pWeek_4 VALUES LESS THAN('2010-03-01') );其中建议确定数据是线序的再这么建立,不然会对 MySQL 存储引擎的记录比较造成疑惑。
但如果按照 Column 分区,只接受 column 名称,而不能是表达式。好处就是能不用整型、接受多列。
7.1.2 LISTING Partitioning
LIST partitioning: 与按范围分区类似,只是分区的选择基于与一组离散值之一相匹配的列。
考虑实际应用,对下面的雇员表:
xxxxxxxxxxCREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT, store_id INT );按雇员的不同地区分区:
xxxxxxxxxx-- 加上PARTITION BY LIST(store_id) ( PARTITION pNorth VALUES IN (3,5,6,9,17), PARTITION pEast VALUES IN (1,2,10,11,19,20), PARTITION pWest VALUES IN (4,12,13,14,18), PARTITION pCentral VALUES IN (7,8,15,16));问题是,如果插入的一些记录不属于这些定义的列表内,那么就无法插入(报错)。如果:
不想报错:插入时加入
IGNORE:INSERT IGNORE INTO h2 VALUES (2, 5), (6, 10), (7, 5), (3, 1), (1, 9);想其他值全部归到一个单独分区内:不行。there is no “catch-all” such as MAXVALUE;
因此,我们建议对某个固定的枚举量的列来这么做 LIST partitioning;
同样,LIST 分区也可以用 COLUMNS 来不使用整型。
其中,RANGE 和 LIST 分区,如果指定 COLUMNS(表示按 Column 分),则都支持不按非整型数据(如日期、字符串)类型来分区。例外如下:
但是
DECIMAL / FLOAT之类的浮点数类型;与
DATE / DATETIME相关但不是的类型;TEXT / BLOB不支持(CHAR, VARCHAR, BINARY, VARBINARY都支持);
7.1.3 HASH Paritioning
HASH partitioning: 使用这种类型的分区时,分区的选择基于用户定义的表达式(某种方式计算要插入到表中的行中的列值)返回的值。
用户可以指定在 MySQL 中产生非负整数的所有非负整数表达式来作为 hash 函数。
举例:
xxxxxxxxxxCREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT, store_id INT ) PARTITION BY HASH(store_id) PARTITIONS 4;但需要考虑数据散列均衡,例如下面的例子:
xxxxxxxxxxCREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01’, separated DATE NOT NULL DEFAULT '9999-12-31’, job_code INT, store_id INT ) PARTITION BY HASH(YEAR(hired)) PARTITIONS 4;这比较奇怪:按插入年份 hash,可能全年的雇员全部被放到一个分区中,短时间内没有很好的散列效果;
但是这么做的意图大多是为了加快查找,那么为何不将 YEAR 和 MONTH 一起 hash 呢?所以这种写法比较少。
在这种分区方法中,还支持另一种算法:Linear Hash。
它和普通散列的区别是,普通散列使用的只是散列函数值的模数,而 linear hash 采用 linear powers-of-two algorithm(线性二幂次算法);
优势是分布地更均匀(?)
算法如下:
xxxxxxxxxxprocedure power_of_two()// Find the next power of 2 greater than num;V := POWER(2, CEILING(LOG(2, num)));N := F(column_list) & (V - 1);while N |= num: V <- V >> 1; # V /= 2 N <- N & (V - 1);使用如下:
xxxxxxxxxxCREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01’, separated DATE NOT NULL DEFAULT '9999-12-31’, job_code INT, store_id INT )-- 这里加上 LINEAR 表示使用 linear hashPARTITION BY LINEAR HASH(YEAR(hired)) PARTITIONS 4;7.1.4 KEY Partitioning
KEY partitioning: 这种类型的分区与 HASH 分区类似,只是只提供一个或多个要评估的列,MySQL 服务器提供自己的散列函数。
这些列可以包含整数以外的值(就像 RANGE 和 LIST 的
COLUMNS修饰一样),因为无论列的数据类型如何,MySQL 提供的散列函数都能保证得到整数结果。
注意,KEY() 可以为空!MySQL 一般会默认主键。
举例:
xxxxxxxxxxCREATE TABLE members ( firstname VARCHAR(25) NOT NULL, lastname VARCHAR(25) NOT NULL, username VARCHAR(16) NOT NULL, email VARCHAR(35), joined DATE NOT NULL )PARTITION BY KEY(joined) PARTITIONS 6;其实本质上还是 hash partitioning,只不过这个 hash 函数交给 MySQL 实现。
同样可以用 LINEAR KEY 来指定 “线性的”(分布更均匀,但计算量更大);
7.2 Subpartitioning
可以按照不同维度来切分表。
xxxxxxxxxxCREATE TABLE ts (id INT, purchased DATE) -- 先按年份 用范围分区PARTITION BY RANGE( YEAR(purchased) ) -- 在上面分区的基础上,分区内继续按天用 hash 分区-- 共 3x2 = 6 个分区SUBPARTITION BY HASH( TO_DAYS(purchased) ) ( PARTITION p0 VALUES LESS THAN (1990) ( SUBPARTITION s0, SUBPARTITION s1 ), PARTITION p1 VALUES LESS THAN (2000) ( SUBPARTITION s2, SUBPARTITION s3 ), PARTITION p2 VALUES LESS THAN MAXVALUE ( SUBPARTITION s4, SUBPARTITION s5 ) );如果不需要子分区名字,也可以不指定:
xxxxxxxxxxCREATE TABLE ts (id INT, purchased DATE) PARTITION BY RANGE( YEAR(purchased) ) SUBPARTITION BY HASH( TO_DAYS(purchased) ) SUBPARTITIONS 2 ( PARTITION p0 VALUES LESS THAN (1990), PARTITION p1 VALUES LESS THAN (2000), PARTITION p2 VALUES LESS THAN MAXVALUE );7.3 How About NULL in Partitions?
如果分区后插入的依据列的值是 NULL 会出现什么?
我们知道,NULL 数据列在任意判断语句中都会返回 TRUE,因此:
以 RANGE partitioning 为例,依据列为
NULL的一定会被放入当前 RANGE 的最低一档(因为判断一定返回TRUE);因此 如果插入
NULL的数据比较多,那么可能造成分区效果不好。以 LIST partitioning 为例,需要显式指定
NULL在哪个列表内,否则会报错(这里能区分出来!);以 HASH / KEY partitioning 为例,它们会把
NULL和0看成等价的东西,也就是(0, 'sth')和(NULL, 'others')一定在一个分区(如果以第一个列为 HASH/KEY 分区依据);
7.4 Partitioning Management
在后期修改表的分区时,会比较耗时,因为不同分区确实可能在不同物理位置,需要物理上的转移过程。
完全修改、追加、覆盖。
re-organize 整个表的分区和完全修改一样非常耗时;
注意,对于 LIST partitioning 而言,ADD 追加的新 list 中,如果有重复元素则会报错。需要 REORGANIZE 来覆盖前面的定义。
而且需要考虑到分区(尤其是 RANGE/LIST)的实际含义(例如时间代表了特定历史阶段),那么应该按照这些含义来分,使得一次查询尽可能落在一个分区内,方便 Query Plan 进行优化。
7.5 分区与表 的交换
允许一个表的某一分区在另一张表中维护。
如果有些时候,需要一个表和另一个表中的某个分区的内容交换,可以使用:
xxxxxxxxxxALTER TABLE pt EXCHANGE PARTITION p WITH TABLE nt;但是要注意一些显然的条件:
被交换的表自己不能分区;
被交换的表不能是临时表;
被交换的表和被交换分区必须完全相等;
被交换的表和被交换分区必须有相同的 row format(
INFORMATION_SCHEMA.INNODB_TABLES查询);被交换的表:不能有外键关联、不能有不符合交换入的分区条件;
注意,如果交换的表中有些记录不符合交换入的分区条件,则会报错。如果仍然希望继续插入,则在上面的语句中追加 WITHOUT VALIDATION;
Chapter 8. NoSQL
8.1 Why we need it?
为什么需要 Not-Only SQL?
数据量太大;
MySQL 不是可以分区吗?
Partition 不能解决问题。超过 10 M 条数据后性能不佳;
如果拆表,不容易保存数据一致性;
非结构化数据难以存放在 SQL 中。尤其是基于文档(document)、基于图(graph)、基于文本的;
关系型数据库在大量数据存储和处理过程中存在劣势:
支持的数据大小级别 GB;
通常难以应对没有预先定义的 schema 的情况;
难以 scaling,scaling 不是线性的;
虽然 NoSQL 能保证大量非结构化数据的存储性能,但规范上来说不需要保证 ACID 事务特性(可能仅有最终一致性等 Weak Consistency Model)。
8.2 MongoDB
一个基于文档的(document-based)数据库。有几个概念:
document:文档,通常以非结构化的文本或二进制信息组成,相当于一条数据记录;
collection:一组文档的集合,相当于关系型数据库的表,但是是 schema-free 的形式;
在同一个 collection 中多个 document 有默认拥有特殊键
_id在 collection 中的唯一属性;因为是 schema-free 的,所以没有 “主键” 的说法。
database:由多个 collections 组成的数据结构。每个 database 可以有独立的权限、可以存放在不同物理介质上;
8.2.1 Definitions
Document
一个 simple document 可以包括一个或多个键值对(类似 JSON),但不以 MySQL 中的 Blob 相同方式存储。
注意 MongoDB 的 type-sensitive 和 case-sensitive 的;
Key 在同一个 document 中不允许重复;
Key 中不能包括
'\0';.、(space) 开头的字符只能用在一些特殊属性中;_开头的字符表示应该是保留字;
注意,我们也不能只用一个 collection,例如:
xxxxxxxxxx{ "name" : "John Doe", "address" : { "street" : "123 Park Street", "city" : "Anytown", "state" : "NY" }, "order": [ { "orderId": 1, "orderItems": [{}] } ]}有几个问题:
这是不易于维护的,尤其是在一个 collection 中出现很多 nested document;
性能原因:通常情况下,解析一个 nested list of types 比解析 a list of collections 要慢;
管理同类数据更能利用 data locality,并且更容易创建索引;
Collection
命名规范:
collection name 不能为空;
不能用以
system开头的名称;用户创建的 collections 不能使用 reserved characters;
使用 sub-collections:
使用
.来在组织层面 subcollections,例如blog.authors和blog.posts,它们和blog没有关系,甚至blog可以不存在;
Database
有个实践经验和建议:建议将单个应用的数据都放在一个 database 中;
有几个保留数据库:
admin: This is the “root” database, in terms of authentication.local: This database will never be replicated and can be used to store any collections that should be local to a single server.config: When Mongo is being used in a sharded setup, the config database is used internally to store information about the shards.
8.2.2 Indexing
MongoDB 这类 NoSQL 如何建立索引?
Normal Index:一般索引可以直接用 CLI
<collection>.createIndex(boolFilterObject)来建立;注意
boolFilterObject用 0/1 标识是否索引,-1/1 表示是反序还是顺序;这样查询时同样使用 leftmost 来索引。注意设置索引时的考量(类似关系型数据库);
但是没有 static schema 怎么办?不相关的记录不加入索引就行!不需要报错。
Geospatial Indexing:地理索引(使用指定的 “坐标” 索引),会利用类似 R-Tree 的数据结构来计算不同 document 的指定属性中的点的具体情况(如距离)来索引;
能加速查找离指定数据最近的 N 个 document;
默认欧式坐标(flat plane);
8.2.3 Sharding
Reasons
考虑一种情况,当 MongoDB 的数据量很大的时候,我们需要将数据切片,并 scale out 到不同集群上去。
除此以外,还有哪些情况需要切片?
单机磁盘空间不够用:当前机器的存储空间即将耗尽;
I/O 不够用:当前用户数很大,我们需要将写操作分散到多台物理节点上以加速(上锁还是需要上锁的,只不过多个机器 Disk I/O 够用一些);
Memory 不够用:想把更多数据放在 memory 中;
这个将数据切片(把一个 Collection 中的 Documents 拆成多个 Chunks 负载在不同物理节点上)的动作在 MongoDB 中被称为 “Sharding”;

Shard & Chunks
MongoDB Sharding 非常类似 MySQL 的 Partition 机制。但二者有区别:
MySQL Partition 针对表进行,需要手动指定分区;
MongoDB Sharding 针对 Collection 进行,不受用户指定自动进行,因此又称 Autosharding;
它们二者的 Chuck/Partition 具体存在集群的哪里,都对用户透明。
例如在 MongoDB 中,多个 chunks 的查找工作是由 router 决定的,它会记住每个 chunk 存在集群的位置。
除了 router,MongoDB 还会为每个 shard server 分配合理数量的 chunks,确保每两个 shard server 存放 chunks 数量相差不超过 2(可以配置、可以关闭)。
为什么有些时候需要关闭?考虑数据的热点程度不一样,有些热点数据可能占用大小较小,但访问次数远高于其他数据,因此为了 CPU / Memory 负载均衡,这种情况下如果只是用 chunk 数量来决定分配显然是不合适的;
Shard Mechanism 如下:

主要关注 MongoDB 何时 split、sharding chunk 存放的位置,等等。
实际上当 MongoDB 插入一个数据后,生成的 _id 并不是自增键,而是类似 Java GUID 一样的随机标识数。
8.3 Neo4J
8.3.1 Definitions
一种图数据库,专门用来存储图(graph)数据结构。在这种需求下,使用传统的关系型数据库、基于文档的 NoSQL(例如 MongoDB)可能不再胜任。
例如,一个存在用户、订单、订单项、产品信息 4 个表的关系型数据库,如果想要找用户买过的产品详细信息 / 产品被哪些用户买过(查看实体 User 和实体 Product 间的相互关系),则至少需要进行 3 次 JOIN 操作。如果这种查询比较常见的话,性能问题就无法被忽视了。
再比如,如果想要存放两个人的 follow 关系。将用户信息、follow 信息放在两个表中,follow 信息记录 persion ID 和 friend ID(为了方便查找存在一倍数据冗余),
那么查找某人的好友,至少需要 2 次 JOIN 操作(先查用户的所有 Friend IDs,然后找这些 Friend IDs 对应的用户);
查找谁的好友是某人,同样至少需要 2 次 JOIN 操作(先查 follow 表中的所有 Friend ID 是指定用户的 Person IDs,再找这些 IDs 对应的用户);
查找好友的好友?那至少需要 3 次 JOIN 操作!找 N 轮好友的好友就要 N+1 次 JOIN 操作,这在频繁查询的场景下是不可接受的(JOIN 笛卡尔积再操作,两个表很大时
不可接受); 因此我们说 “关系型数据库中缺少表示相互关系的手段”。
那我们之前的基于文档的 NoSQL (MongoDB)能否解决问题?
我们以第一个例子为例,在 MongoDB 中可以有两种设计方法:一种,用户和订单、订单项全部嵌套在一起,放在一个 Document 中;另外一种用户和订单分开。这时如果要找用户购买的产品信息,就不需要 JOIN 了!
看起来这两种方法都成功解决了 JOIN 问题?那我如果想看产品被哪些用户买过呢?问题就又出现了!这次问题比关系型数据库还要难以解决(扫描全部用户的)。
那第二个例子呢?我们将朋友作为 ID 数组存储,会遇到相似的问题。找朋友关系变快了,但朋友的朋友还是很慢。
我们认识到,如果业务逻辑需要频繁使用实体间的相互关系时,无论是关系型数据库,还是基于文档的 NoSQL 都没法高效地解决问题。
因此人们提出了图数据库。
图数据结构主要存放一组结点和边(vertices & edges):
一个结点类就是面向对象设计中的 实体类(entity),它可以存放多种属性,结点可以基于这个类在图上存在多个实例。
每个结点间可以有各种有向边的关系,每条边可以用 Label 标识。
这种标识方式被称为 “Labeled Property Graph”;
图数据库主要是对事务操作进行了优化,能保证事务完整性(fully ACID compliant)。
它的架构一般可以分为 underlying storage 和 processing engine 两个部分。其中处理引擎类似 MySQL 的 QueryPlan,underlying storage 则是指令执行系统和文件管理系统;
8.3.2 Data Model
以 Neo4J 为例,一个图的表示、查询、修改方法都可以使用 Cypher 语言(内置)描述。
8.3.3 Storage Mechanism
使用类似邻接表的方式存储:
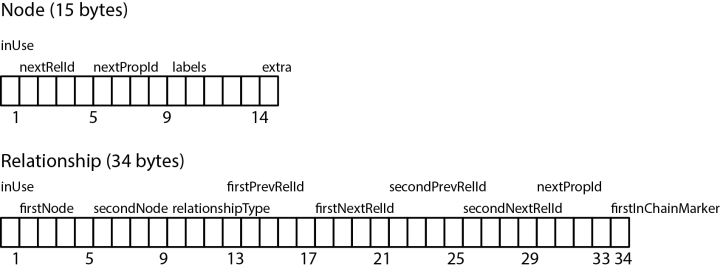
8.4 Log-Structured Database
注意到有些情况下,关系型数据库、基于文档或者图的数据库都没法高效解决 “数据热点和创建时间相关” 的数据的查询操作。例如,如果 MySQL 想要在大量数据情况下查找最近几次插入的数据,这个时候由于表中没有与创建时间相关的信息,因此比较麻烦(按时间分区?如果有其他分区需要呢,例如按用户名?创建子分区得不偿失)。
这个时候就需要日志结构型数据库(准确地说,是日志型键值存储系统)。
例如 LSM Tree(适用于写多读少场景,不再赘述)。
优点:
大幅度提高插入(修改、删除)性能;
内存写相当快,并且可以异步刷盘;
写放大率降低;
访问新数据更快,适合时序、实时存储;
数据热度分布和 level 相关;
缺点:
牺牲了读性能(一次可能访问多个层);
可能出现写性能尖峰(Compaction),并且存在写阻塞;
即便有 Bloom Filter,对非热点数据的查找可能会逐层叠加造成读性能问题;
适用场景:
热点键值数据的快速存储。存放在单机的文件系统中,不考虑分布式;
如果是很大量的数据(到了需要分布式的场景),因为存在读性能/写性能尖峰,对这种旧数据应该交给 MySQL / MongoDB 等数据库。
日志结构数据库中的读放大和写放大
读放大:(如果不使用 Bloom Filter)访问不存在日志结构数据库中的数据,或者 访问一个热度不高、时间比较久的数据时,都会导致 日志结构数据库找穿内存,向下访问多层 SSTable,触发多次 Disk I/O,显著降低查找性能;
写放大:“写放大” 指每次写都有可能触发日志型数据库的 compaction 机制,而 compaction 时可能会出现级联 compaction、merge 以及日志的垃圾回收,这时会导致写阻塞,出现写时延尖峰;
补充:“空间放大” 指在日志型数据库不做 compaction、不做 SSTable merge 以及不做 Append-Only Log 的 garbage collection 的前提下,由于 Append-Only 的性质会导致存储数据的日志文件不断增大,最终存储代价远远超过原数据本身;
8.5 Vector Database
8.5.1 Basic Concepts
Embeddings:对信息特征的数据形式的描述。例如一个 RGB 3 通道图片 224 x 224 x 3 数组被 flatten 后转为一个一维数组,这个一维数据可以是这个图片的 embedding;
如果是文本信息,我们可以有几种方法来 embedding:
one hot 编码:所有可能出现的单词各作为一个维度(表示 1w 个单词,向量就 1w 个维度)。好处是正交(单词间独立、没有相似性),坏处是稀疏、占用空间;
特征描述:使用不同特征作为维度(基向量),描述不同词汇;
这些可以被 embedding 的信息统称为 Content;
然后实际使用的方式如下:

其中,从 Content 中抽取 embeddings 的过程由 embedding model 完成(它可以是自己预训练出的,也可以是大语言模型等等)。
输出的向量数据再交给向量数据库存储和查找。
注意几个点:
Vector Database 通常是使用 Approximate Nearest Neighbor (ANN) search,在找近似的结果,而不是精确匹配;
Vector Database 在插入数据时就需要建立索引方便查找;
最终我们会发现,创建索引后,向量数据库实际上只需要索引了(一般不需要原向量进行比较)!
8.5.2 ANN Search Algorithms
在维度不匹配时使用随机矩阵进行 random projection;
向量量化:
可能原始向量的维度较高,在资源缺乏或者其他场景下应用价值不高,因此我们需要进行量化:
将原始向量切分为若干块,每一小段可以做聚类处理(例如
123 213 132可以划分到同一个 group 中);一个 group 对应一个 code,这样向量的复杂度就会下降,虽然精度也会下降,但客观上提升了向量处理的性能;

局部相似性 hashing(Locality-sensitive hashing):

HNSW(Hierarchical Navigable Small World):
8.5.3 Similarity Measurement
余弦相似度、欧式距离、曼哈顿距离、点积……
余弦相似度:度量向量空间中两个向量之间夹角的余弦值,使用向量点积和夹角余弦的关系计算。
它的范围在 -1 到 1 之间,其中 1 代表完全相同的向量,0 代表正交向量,-1 代表完全不同的向量。
欧氏距离:测量向量空间中两个向量之间的直线距离。通常可以用向量的二范式计算:
可以表征空间中两个向量之间的“距离”。它的范围从 0 到无穷大,其中 0 代表相同的矢量,数值越大代表矢量越不相同。
曼哈顿距离:相当于向量的无穷范数,
8.6 Timeseries Database
数据存储根据时间作出优化。
数据会源源不断地来,因此每个数据都需要有过期时间;
格式非常简单(不存在表和表间的关联,大多数是监控数据),不仅可以存 raw,还可以存 delta;
所有数据都带时间戳,可以带前缀(相同的 timestamp
_time)存储,减小存储开销;
InfluxDB 的概念:
一个 Point 就是一个包含 series key、field value 和一个 timestamp 的结构;
时序键(series key):一组时序就是共享 measurement(
_measurement), tag set, 和 field key 的集合。
带有
_开头的,都是系统保留的字段,也就是一定会有的一个列,反之都是用户自定义的字段。
_time:时间戳,数据对应的时间,因为可能同一个时间会接收到很多数据,所以很可能同一个时 间接收到很多数据,所以时间戳不能唯一的标识。时间戳非常准确,精确到纳秒级别。
_measurement:起一个名字,一个统称,这个表格在干啥。census 就是调查种群数量。这里我们 发现它是共享的,所以存储的时候会优化,只存储一次。
_field:存储的是 key,比如下表里面存储的就是某个物种的名字;和_value构成键值对。Field 可以 作为筛选的依据,得到一个 Field Set。
_value:存储的是 value,类型可以是 strings, floats, integers, or booleans,之所以不能是别的,是 因为如果是复杂的数据类型转换会耽误时间,效率降低,所以就只能存这些基础的数据类型。Series:measurement, tag set, 和field key都相同的点集合。
Point:一个数据点,带有时间戳的数据点。E.g.
2019-08-18T00:00:00Z census ants 30 portland mullenBucket:存储桶,归属于一个组织,存储相对应的数据点集合。
Organization:组织,里面有一组用户,里面有若干个bucket。
注意到 InfluxDB 的一些注意事项:
fields 不会作为索引,因为它很容易变化。因此如果以这列做索引,则会出现全表扫描的问题;
tags 会作为索引;
和 LSM Tree 类似,支持 Append-Only,严格限制 update 和 delete;
没有 ID 的概念,因为很少有拿单条记录的情况,通常是取一个数据集;
不存储除了 timestamp 外完全相同的数据(只存变化),因为信息熵的冗余问题;
整个数据库只保证最终一致性(可能存在 missing update 的问题);
Quiz:如何判断将数据存为 Field 还是 Tag?
在 InfluxDB 中,决定将数据存储为
field还是tag主要取决于数据的查询模式和使用场景。对于服务器的 CPU 占用率和内存占用率,应该存储为field,原因如下:
CPU 和内存占用率是数值数据
field用于存储数值类型的数据(如浮动点数或整数),并且这些数据通常是变化的;CPU 占用率和内存占用率通常会随着时间变化,具有浮动的特性,因此它们应当存储在
field中,方便进行聚合(如平均值、最大值等)、筛选和排序等操作。
Tag 的作用
tag主要用于存储具有高基数(不同值的数量非常多)的分类数据,通常是维度字段,作为索引使用。
CPU 占用率和内存占用率不是具有高基数的分类数据,而是时间序列的连续数值,因此它们不适合作为
tag存储。tag存储的字段通常用于区分不同的数据系列,比如服务器的名称、数据中心的 ID 或操作系统类型等。
查询性能
tag字段可以用于快速的查询过滤,因为它们是索引的。而field不会被索引,查询时需要扫描所有的field数据。存储数值数据(如 CPU 和内存占用率)在
field中,而不是在tag中,有助于避免因tag的高基数带来的查询性能问题。结论:服务器的 CPU 占用率和内存占用率应该存储为
field,因为它们是数值数据,且不会用作分类维度进行查询过滤。而tag应用于具有分类属性的数据,能够高效地进行维度查询。
InfluxDB 存储引擎一般要写入几步:
Write Ahead Log (WAL);
Cache;
Time-Structed Merge Tree (TSM);
Time Series Index (TSI);
InfluxDB 中的索引比关系型数据的索引(指定列、指定升降序、指定索引数据结构 等等)简单多了,只需要拿着 series key 索引即可。
另外,InfluxDB 有一套自己的文件系统管理方式。TSM 和 WAL 需要放到两个地方,保证异地容灾。
还有,InfluxDB 和 MongoDB 一样,使用 Shards(分裂方法、管理方法都类似)来管理大量文件。不过 InfluxDB 会根据过期时间范围构建 shard group;
shard group 可以 precreation、compaction 过期删除等动作;
InfluxDB compacts shards at regular intervals to compress time series data and optimize disk usage.
InfluxDB uses the following four compaction levels:
Level 1 (L1): InfluxDB flushes all newly written data held in an in-memory cache to disk.
Level 2 (L2): InfluxDB compacts up to eight L1-compacted files into one or more L2 files by combining multiple blocks containing the same series into fewer blocks in one or more new files.
Level 3 (L3): InfluxDB iterates over L2-compacted file blocks (over a certain size) and combines multiple blocks containing the same series into one block in a new file.
Level 4 (L4): Full compaction—InfluxDB iterates over L3-compacted file blocks and combines multiple blocks containing the same series into one block in a new file.
Chapter 9. Concurrency Control
9.1 Thread in Java
9.1.1 Usage
默认读者已经在 ICS 中学习了很详细的关于 thread 和 process 的知识,并且学会在 C/C++ 中使用线程和进程。
我们本节的目的是在 Java 中使用线程。两种方法:
使用
RunnableInterface:重写
public void run()方法;将这个类的实例作为
Thread类型的构造参数。构造完成后启动Thread#start()即可;
继承于
ThreadClass;重写
public void run()方法;直接启动:
Thread#start();
注意,我们需要特别处理 InterruptedException:
Java 多线程程序中,我们应该总是考虑这种 exception。这意味着外部有人正在希望以一种优雅的方式结束当前线程(就是对当前线程对象
Thread#interrupt()),并且可能正在通过Thread#join()等待;不应该在捕获这个异常的时候直接抛出另外一种异常(混淆原因),或者直接忽略(外部线程可能正在等待结束!);
根据方法自身的含义,一般有两种解决方案:
继续向上传播这个异常(当你的方法本身就是一个耗时操作 / 网络操作或者其他情况);
捕获这个异常、设置当前线程被 interrupted 的 flag(方便 log 溯源):
Thread.currentThread.interrupt(),并且准备结束;
然后处理当前类中需要回收 / 处理的资源。无论是哪一种方法,都需要遵循当前方法的语义:“调用它出现
InterruptException这种情况是否合理?”
9.1.2 Synchronized Methods
Java 线程中的设定和 C/C++ 是类似的,它也会共享线程间的资源,不过 Java 没有指针,只是通过引用共享的。因此会遇到和 C/C++ 一样的问题。
就以共享静态变量为例,多线程同时操作共享静态变量会导致未定义的行为(race condition)。
在 C/C++ 中,一般会通过设立临界区(信号量 semaphore)或互斥锁(mutex)来锁定共享变量,确保同一时间只有一个/指定数量的线程可以访问。
在 Java 中,提供了一种修饰方法的关键字 synchronized,其作用是:
被该关键字修饰的方法,其所在的类型的任意一个对象,只能被一个线程调用被这个关键字修饰的方法。
也就是说,相当于在这个方法的类上设一个互斥锁(被称为 intrinsic lock 固有锁,或者 monitor lock),把这个类中所有被
synchroized修饰的方法锁住;当一个线程退出了一个对象的 synchronized 方法,则会与这个对象其他的 synchronized 方法建立一个 happens-before relationship,以确保对象被使用的状态能被所有线程知道;
如果 synchronized 修饰在静态方法上,那么锁住的就是与 intrinsic lock 关联的 class 实例,而不是它的实例的实例。也就是对这个类中静态域的访问会被控制,需要与实例方法的 synchronized 区分开。
Java 甚至支持到 statement 细粒度的 synchronized:
xxxxxxxxxxpublic void addName(String name) { // 这里保护实例属性的并发访问(this) // 如果需要保护静态成员,则需要将关键字定义在静态方法上 synchronized(this) { lastName = name; nameCount++; } nameList.add(name); }9.1.3 Reentrant Synchronization
Java 中提供了一类可重入锁,可以让获得锁的同一个线程多次访问临界资源:
xxxxxxxxxx// 注意,如果需要保护类的静态成员,则应该将锁也定义为静态成员Lock lock = new ReentrantLock();
lock.lock();try { //更新对象状态 //捕获异常,并在必须时恢复不变性条件} catch (Exception e) { e.printStackTrace();} finally { lock.unlock();}9.1.4 Atomic Access & Keyword volatile
Java 中原生的单步原子访问操作包含:
针对引用变量的读写、大多数基本类型的读 或 写(除了
long/double);被
volatile关键字修饰的所有变量的读 或 写(包括long和double);volatile的本质是,程序在访问一个被它修饰的变量后,会直接进入 main memory 读取,而不会使用寄存器 / 线程本地缓存;相当于告诉 JVM 这个变量可能会在当前线程的控制流以外的地方被更改。它会确保当一个线程修改了一个变量时,其他线程能够立即看到这个修改。
底层是通过禁止指令重排序和 memory barrier 等机制来实现的。
Java 的原子访问操作可以:
保证多线程操作一个数据时值不会错误的改变(写操作字节码指令会一次性执行完),降低 memory inconsistency 的风险;
保证各个线程总是能读到关于这个值最新情况(读操作字节码指令会读到最新的情况并且一次性执行完);
那么,为什么 Java 既然有内置 Atomic Classes、锁、synchronous 关键字等等同步机制,为什么还需要 volatile 关键字?你只需要记住这些:
volatile保证 Java 多线程对某个变量的读、写是及时的(不使用缓存、禁止指令乱序),一定能被下一条指令 / 其他线程感知到;其他的同步操作,保证 Java 代码片段执行期间的临界特性(不会有另一个线程同时执行相同代码);
为共享变量加锁(或者其他同步机制)之后,就不再需要
volatile关键字了(后者是前者的必要不充分条件);
因此,只有在没有多线程同步的需求(volatile 不保证同一线程对变量的一系列操作是原子的),但是又要保证对某一个变量的读和写是准确、及时的时候,可以使用 volatile 关键字,例如状态标志、简单的布尔变量等,这样不需要加锁,规避了死锁以及性能问题。
9.1.5 Dead Lock, Starvation, Live Lock
无论是死锁还是活锁,都是指多个线程之间因互相请求访问资源而导致程序无法继续执行的情况。
它们的不同点是:
对于死锁,它发生的情况是多个线程或进程在互相等待对方释放资源时,自己又不会主动释放自己占有的资源,导致程序永远无法继续的情况。
例如,假设一个程序的两个线程 A 和 B,A 先获得了一个资源 X 并给它上锁,B 获得了另一个资源 Y 也给它上了锁。但是接下来 B 需要资源 X 才能继续、A 又需要 Y 才能继续。所以二者相互等待对方释放资源锁,造成了死锁;
对于活锁,线程并不会阻塞在原地,而是反复地在释放资源和获取资源间横跳,这主要是因为程序有处理资源访问冲突的机制,但是两个存在活锁的线程相互处理访问冲突的时候又造成了访问冲突,也无法继续下去。
例如一个程序的线程 A 和 B,假设 A 先获得了一个资源 X 并给它上锁,B 获得了另一个资源 Y 也给它上了锁。A 想要获取资源 Y 的时候发现 B 占用了,于是 A 主动释放了资源 X 给 B,自己去获取资源 Y;但是此时 B 也主动释放了 Y 资源,去获取 X 资源,双方只是调换了资源持有的顺序,仍然无法继续执行。
线程饥饿是指,因为共享资源调度策略的问题,造成某些线程一直无法获得执行的机会而近乎停止执行,而另一些线程则一直占用共享资源不释放。
9.1.7 Immutable Objects
在很多实际情况下,不可变数据类型的好处:
复制构造时,不是引用传递,因此是深拷贝。这样使用起来和基本类型一样方便,但是又不用担心改错源数据(非引用链接);
确保数据在多线程情况下无需同步,线程安全!
不可变类和不可变对象(和 Python 思路相似)
不可变类的定义:一个类满足如下三个条件:
类型中的每个数据域都是 私有的、常量的(
private,final);每个数据域都只能通过
getter方法获取,不能有任何setter方法,并且没有“返回值是指向可变数据域的引用”的getter方法;必须存在公有构造函数,并且构造函数内初始化各个数据域(常量只能这么做);
Object 基类继承函数
equals返回true当且仅当类中的每个数据域都相等;Object 基类继承函数
hashCode在类中的每个数据域都相等时,一定返回一样的值;Object 基类继承函数
toString最好包含 类名 和 每个数据域的名称和值;因此如果有一个类数据域都私有、没有修改器方法,但有一个方法:返回内部一个可变数据域的引用(例如数组),则这个类也是可变类;
9.1.8 High Level Concurrency Objects
Java 中包装了一些高级并发对象:
Lock Objects
Lock Objects:对常见的并发场景提供了简单的保护;
例如
ReentrantLock(可重入锁),可以使用
tryLock()获取锁、unlock()释放锁。和 Intrinsic Lock 机制很相似(包括持有规则、通过关联的 Condition 对象 notify/wait)相比更好的一点是 “允许 try”,也就是获取锁不成功的话还可以回到获取锁前的执行状态。
Executors
Executors:为启动、管理线程提供了更高级的 API,可以使用线程池机制为大规模并发应用提供支持;
将线程创建、管理的工作从应用业务逻辑中剥离。Java 中的 Executor 就是来包装这个的接口。
其中,有一些框架 / 库可以实现 Executor 接口。例如:
Thread Pools:线程池,最常见的对于 Executor 的 implementation;
Fork/Join:一个利用多处理器资源的 Executor 实现框架。
Executor 接口只有一个:
xxxxxxxxxxvoid execute(java.lang.Runnable runnable);不需要自行创建 Thread,而是将 Runnable 类放到 Executor 中,让它帮你启动和管理。
类似地,还有 ExecutorService 接口,提供了比 Executor 更灵活的线程提交方式:
xxxxxxxxxxpublic interface ExecutorService extends java.util.concurrent.Executor, java.lang.AutoCloseable;类似 Executor,不过它不仅仅允许你提交 Runnable 对象,还允许使用 Callable,并使用 Future<T> 来异步获取返回值,可以通过返回的 Future 对象了解、管理 Runnable/Callable 的执行状态:
xxxxxxxxxxFuture<?> submit(Runnable runnable);Future<T> submit(Runnable runnable, T t);Future<T> submit(Callable<T> callable);
// 同时启动多个 callable 对象List<Future<T>> invokeAll(Collection<? extends Callable<T>> collection) throws InterruptedException;xxxxxxxxxx// 等待终止boolean awaitTermination(long l, TimeUnit timeUnit) throws InterruptedException;在 ExecutorService 基础上继续包装 ScheduledExecutorService,允许对线程启动提供调度 delay 的时间:
xxxxxxxxxxScheduledFuture<V> schedule(Callable<V> callable, long l, TimeUnit timeUnit);ScheduledFuture<?> schedule(Runnable runnable, long l, TimeUnit timeUnit);其中,如果 Executor 底层采用 Thread Pools,则大多数用 fixed thread pool 的策略(同时最大只有指定的线程数正在执行)。使用 fixed thread pool 的好处是,使用它的应用可以 degraded gracefully;
使用
newFixedThreadPool创建固定的线程数的线程池;使用
newSingleThreadExecutor单个线程实例的 executor,一次执行一个线程;使用
newCachedThreadPool创建可动态调整线程数的线程池,可以应对多个短期 tasks;newScheduledThreadPool创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代 Timer 类;
而 Fork/Join 框架是针对 ExecutorService 接口的实现。它可以充分利用多处理器的优势,为那些可以拆成小块递归的任务设计,例如:
xxxxxxxxxxif (my portion of the work is small enough) do the work directly else split my work into two pieces invoke the two pieces and wait for the results 在 ForkJoinTask 子类(RecursiveTask 有返回值、RecursiveAction 无返回值)中定义这些任务。
Concurrent Collections
Concurrent Collections:更容易地管理大规模数据,减少 synchronization 次数;
Atomic Variables
Atomic Variables:针对变量粒度的同步机制,可以在一定程度上避免 data inconsistency;
All classes have get and set methods that work like reads and writes on volatile variables
Virtual Threads
Java 中是一类轻量级线程解决方案。让线程创建、调度、管理的开销最小化。
Virtual Threads 是 Java Thread 的实例,这与任何 OS thread 是相互独立的。
当 virtual threads 内部调用了阻塞的 I/O 操作后,会立即被 JVM 挂起;
virtual threads 有一个有限的 call stack,并且只能执行一个 HTTP client 请求 / JDBC 查询。这对一些异步的耗时任务比较合适,但是不适合 CPU intensive tasks;
xxxxxxxxxxThread virtualThread = Thread.ofVirtual().start(() -> { // Code to be executed by the virtual thread});所以 Virtual Threads 不是说会比普通线程更快,而是说比普通线程更具可扩展性(provide scale),这在高并发、每次请求处理耗时的服务器网络应用中能提升吞吐量。
ThreadLocalRandom:为多线程提供高效的伪随机数生成方案;
Chapter 10. Memory Caching
10.1 Background
为什么需要缓存?数据库里面有 buffer、ORM 映射里面也有 buffer 作为缓冲区,那为什么要缓存呢?
因为上面说的这两个缓存都不是开发者可以控制的,完全取决于它们自身的算法或逻辑,没法手动编码控制数据的 deactivate / update;
不仅仅是关系型数据库,像文件系统、网页静态数据、NoSQL 数据库数据等等也都要缓存(它们可能不是面向对象的结构化数据),而且有时还希望主动地提前进行缓存(例如双十一前将预计忙碌的页面事先缓存)。
因此对于读多的数据,比较好的方法就是先缓存起来,而且最好引入负责维护缓存的机制。
Java 网络应用中,在内存中的缓存一般可以有几种方法:
10.2 Memcached
Memcached:一个开源高性能的分布式内存对象缓存系统。
通过减少数据库加载操作来达到加速 dynamic web application 的效果;
针对大小较小的随机数据(字符串、对象)的 in-memory KVS,缓存数据库调用结果、API 调用、页面渲染;
架构简单(client-server,总之就是简单的 KV store system),支持多种语言 API,因此快速部署;
缺点:频繁写操作的数据/对象,不适宜放到
Memcached中;
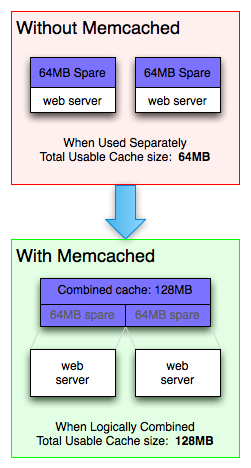
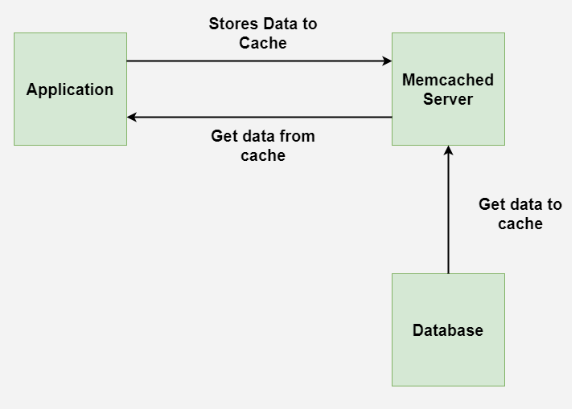
10.3 Distributed KV Store
那么 Memcached 如何设计来高效地利用内存?
首先 Memcached 是分布式的缓存 KVS,必然会存在多个 node 用于存放 cache data;
如果插入一个缓存的键值,那么如何决定缓存的位置?是否直接能用普通 hash 来决定?不行,因为如果分布式的 node servers 的数量改变,难不成还要改变 cache 的位置(涉及大量缓存数据迁移)?
所以我们需要一种算法,能计算出一个要缓存的键值对究竟放在哪台 server、哪个位置,并且在动态的环境中(例如 caching servers 的数量改变)仍然能高效地找到并取出之前缓存的数据。
一种解决方案是:一致性哈希(Consistent Hashing);consistent hashing 可以这么实现:
我们先按照常用的 hash 算法将 Key hash 到
将机器的唯一标识(例如
MAC/IP/HOSTNAME等信息)以及需要缓存的 KV 都 hash 到环上;于是就能判断信息究竟放在哪一台服务器上了:按顺时针方向,所有对象 hash 的位置距离最近的机器 hash 点就是要存的机器,如下图所示:
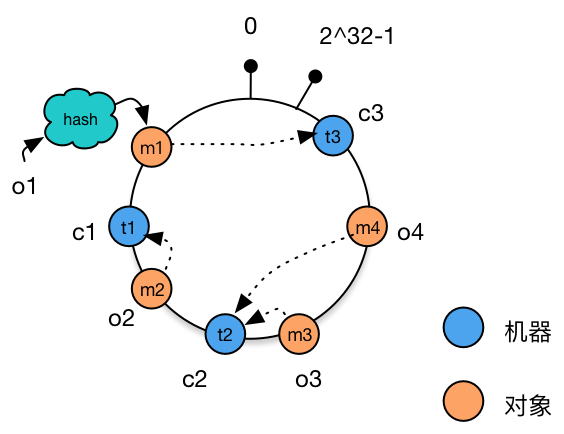
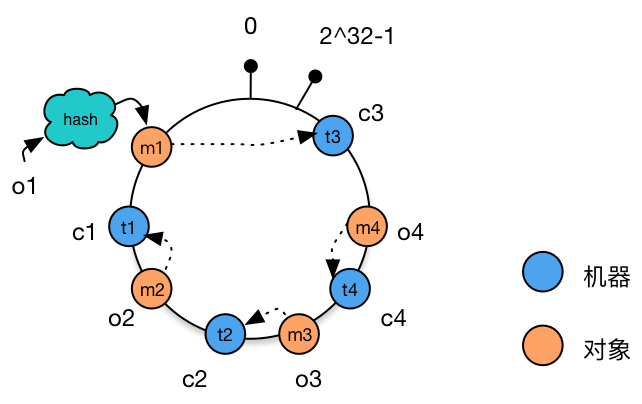
当有机器(
t4)加入分布式集群后,t3 - t4间的缓存将转移至t4上(少量数据交换);反之,有机器(
t4)从分布式集群中离线后,t3 - t4间的缓存将重新转移至t2;
这样的方案能在分布式场景下尽可能减少缓存失效和变动的比例;
但这种方案仍然存在问题:当集群中的节点数量较少时,可能会出现节点在哈希空间中分布不平衡的问题(hash 环的倾斜和负载不均),甚至引发雪崩问题(最多数据的 A 故障,全转移给 B,然后 B 故障,并重复下去,造成整个分布式集群崩溃)。
解决 hash 环倾斜的问题的方案之一就是引入 “虚拟节点”(相当于给机器 hash 点创建 “软链接”),将 virtual nodes 和 real nodes 的映射关系记录在 Hash Ring 中;
上面解决方案的具体实现被称为 “Chord 算法”;
10.4 Redis
NoSQL(Not Only SQL)用于存储非结构化数据,不保证 ACID 事务特性(仅有最终一致性等 Weak Consistency Model)。
Redis(Remote Dictionary Server)就是一类基于内存的键值型 NoSQL,不保证数据一致性,但可以保证性能。
一种 KVStore System,可以方便的存放非结构化数据,这对于缓存各异性数据非常有帮助;
Handle 网络请求多线程。处理指令单线程,单个指令具有原子性;
低延迟,利用 I/O Multiplexing 在单线程中处理多个请求;
支持数据持久化;
支持主从集群(从备份,读写分离)和分片集群(数据拆分,存储上限提高);
10.4.1 为何需要?
持久化在磁盘上的关系型数据库在存储关系数据、处理事务的多数场合下都非常得力,但免不了存在一些问题。
例如,在电商、文章档案等网页应用中,常常是读请求远多于写请求,即便 MySQL 有 cache buffer pool(InnoDB),在大量数据查询的场合下也会出现频繁的 cache evict,究其原因就是 cache working space 太小了。
人们发现只是读请求造成的 Disk I/O 是可以避免的——通过将数据托管到一个更大的内存空间(这段内存空间可以不连续、甚至可以不在单个物理节点上,由一个程序来管理它)中缓存起来,可以有效提升这些应用的处理效率和吞吐量。
结论 1:在庞大数据量的应用场景下,读多写少、数据时间局部性强的应用访问模式可以通过外置的内存缓冲区统一进行缓存,来提升整体性能和接口承载量。这就是 Redis 要解决的需求痛点。
10.4.2 缓存读写策略
旁路缓存模式(Cache Aside Pattern):同时维护数据库、缓存,二者中的数据存在强一致性;
read:使用上面统一的缓存读策略;
write:不存在 write cache hit + no-write-allocate。立即写回数据库,并拒绝缓存。清空写这个数据的缓存信息(使用不缓存手段消除数据不一致性,注意保证顺序先更新磁盘再删除缓存);
为什么不采用上述的写缓存策略,而是拒绝缓存?因为考虑到多次盲写的问题。
读写穿透模式(Read/Write Through Pattern):视缓存为主要存储手段,二者中的数据也存在强一致性;
read:使用上面统一的读策略;
write:write-through + write-allocate;
异步缓存写入模式(Write Behind Pattern):针对读写穿透模式的改进,牺牲一部分数据一致性换取更高的吞吐量;
read:使用上面统一的读策略;
write: write-back(优化,不使用 dirty-bit,而是异步更新到数据库);
结论 2:常用的缓存读写策略有很多种,不过依赖它们制定的缓存模式常见的有 3 种,分别是 旁路缓存、读写穿透、异步缓存;
10.4.3 缓存 Evict 策略
不同内存型数据库的缓存淘汰策略不尽相同。下面以 Redis 为例介绍它的 cache evict 方案:
首先,Redis 正常不会主动 evict 数据项,而是先通过数据过期的方式腾出内存空间:
过期时间:对每个数据项可以设置 TTL(Time-To-Live),表示数据过期时间。过期的数据自动被清空;
定期清理:Redis 可以配置扫描过期数据的频率,扫描过程称为 Garbage Collection(GC);
随机选取:由于 Redis 管理的缓冲区很大,因此每次 GC 一般不会扫描全表,而是随机选取一部分进行回收;
惰性删除:某些键值可能概率原因一直无法被选中删除,因此一旦有查询找到该数据,发现该数据过期后立即删除(被动);
在此基础上,如果:
有些键值始终没被查询,且一直没有被随机选取清理(躲过了定期清理和惰性删除);
过多的键值没有设置过期时间;
数据工作集(working set)进一步增大;
导致内存空间还是没法及时腾出,那么 Redis 就会采取主动 evict 的方案。
结论 3: Redis 对于缓存使用率过高的解决方案是 数据过期 + 主动 evict。其中数据过期依赖 “定时清理” 和 “惰性删除”,主动 evict 依赖 8 种 evict 策略。
10.4.4 缓存击穿 & 缓存雪崩
结论 4:“一直查询不存在的数据” 或者 “某个热点数据被清理” 都会造成缓存击穿、“一批热点数据同时过期”、“内存数据库宕机” 都可能造成缓存雪崩。对应的解决方案是 “添加无效值缓存”、“延长热点数据 TTL”、“随机化批量缓存 TTL”,以及 “适当的缓存持久化”。
Chapter 11. Full-text Searching
数据库中存放字符串一般使用 CHAR(N) 或 VARCHAR(N),前者整齐,后者由 offset 的偏移量指定。
也会存为 TEXT / BLOB 此时文字专门存在此表以外的结构并使用指针指向它。
如果我们希望在数据库的所有字符串中找到含有单词 Great 的。这样我们会发现,在上面的结构中查找方法(例如使用 LIKE)相当慢(需要扫描所有记录,而且每个记录,都要匹配一次,而且结构不同,难以缓存,等等)。
那如果我们一开始就将关键词做成一张关系表(bid - cid - keyword),将表中的关键字和它位于的关联对象映射起来呢?
但是问题是如果一个记录中的关键字很多,那么记录数就会爆炸。
于是人们想出了使用 Keyword 作为键(查找依据),将它们出现的位置作为其他字段(反向查询)。这就是全文搜索。
11.1 Lucene
11.1.1 Concepts
Apache Lucene 是一个高性能可扩展的信息提取(Information Retrieval 全文搜索)库。
用于处理非结构化数据(如大量字符串)的全文检索;
Lucene 会从各种非结构化数据源收集数据并建立索引。
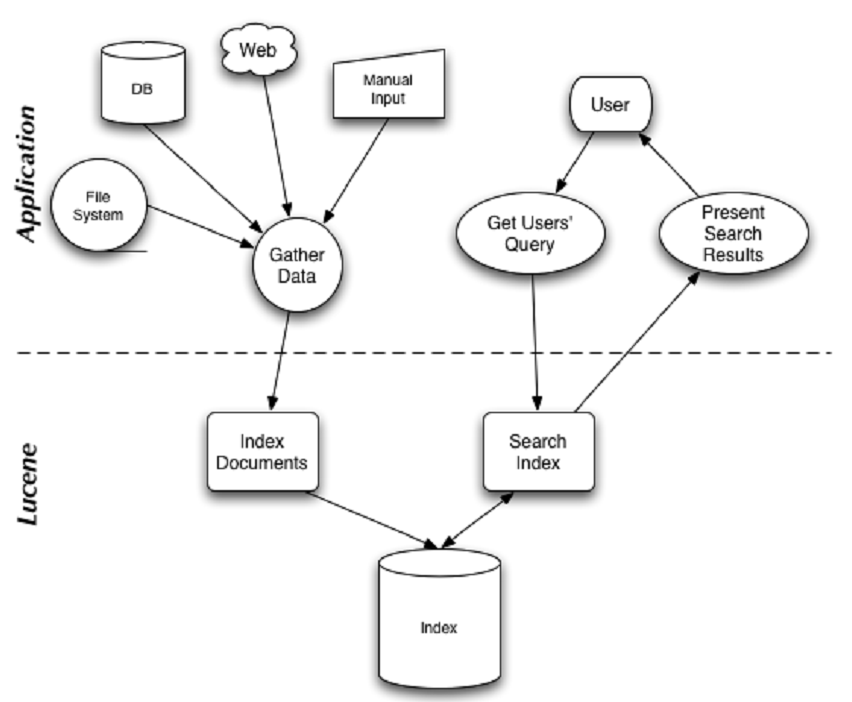
因此可以说高效、跨引用 Indexing 是搜索引擎的核心。你可以将 index 想象成能够提供对于存储的非结构化词语的快速随机访问。
最基本的查询方法是,顺序地从头到尾扫描所有文件,匹配给定的词或短语。
缺点明显:效率低下。
我们的目标就是:尽量消除耗时的顺序搜索的过程。
因此我们引入反向索引。针对字符串的多种属性(field)建立索引:
subject、modified 信息、content(剔除停用词 stop word,保留可能作为搜索关键词的)、pub month、title、category、author 等等(url 仅存储、不索引);
其中 subject 可以向量化,用来检查它与其他记录的相似性;
11.1.2 Metrics
其中衡量查找的指标:
precision(准确率,negative 尽可能小);
recall(召回率,positive 尽可能全);
query speed;
Support for single and multi term queries, phrase queries, wildcards, result ranking, and sorting;
11.1.3 Core Classes
Lucene 的核心索引类如下:
analyzer:定义了一组类型,用于将 document 中的字符串解析为TokenStream以及一组 token 属性。并基于停用词(StopAnalyzer)或一般语法(StandardAnalyzer)进行词干化、去除停用词等文本处理操作;codecs:定义了一些编解码器,提供了对于 index structure 的编解码的抽象以及实现;Document:定义了索引时一个文档的抽象。文档通常由一组字段( Field )组成,每个字段包含了文档的一部分信息,如标题、正文、作者等。因此Document可以用于将文本数据添加到索引;Field:对文档的一个字段或属性的抽象。它包含了字段的名称、值以及用于指定如何处理该字段的配置选项。字段可以是文本、数字、日期等不同类型的数据,根据需要进行索引和检索;IndexWriter:索引创建和维护的核心类。它负责将文档添加到索引、更新索引、删除文档以及优化索引等操作。IndexWriter是在索引建立和更新过程中的主要接口之一;Directory:索引文件的存储和管理抽象。定义了索引文件的位置和访问方式,使得索引可以被持久化存储和检索。它可以是基于文件系统的目录,也可以是内存中的数据结构。
所以总的来说,整体过程就是:
第一部分(建立索引):获取文档、创建文档对象、分析文档(parse text)、创建索引;
第二部分(进行查询):创建查询、从索引库中搜索、渲染结果。
11.1.4 Searching Procedure
获取文档(信息采集):
对于互联网上网页,可以使用工具将网页抓取到本地生成
html文件;数据库中的数据,可以直接连接数据库读取表中的数据;
文件系统中的某个文件,可以通过 I/O 操作读取文件的内容;
创建文档:
建立
Document中的Field,便于之后的索引工作;每个 Document 可以有多个 Field,同一个 Document 可以有相同的 Field(域名和域值都相同);
分析文档:解析 Field 中的内容,使用
Analyzer剔除停用词、解析语法转化为 Tokens;创建反向索引:也就是建立
KEYWORD -> LinkedList<Document ID>的映射(可以称为 “倒排表”);
与此同时,用户(可以是自然人或被调用的程序)可以对索引库进行查询:
创建查询:指定要查询关键字、要搜索的 Field 文档域等,方便查询对象生成具体的查询语法;
举例:
name:phone AND Huawei,表示搜索在namefield 中找内容同时出现了phone和Huawei的文档。从索引库中搜索 & 呈现:
根据查询语法在倒排索引表中找出对应搜索词的索引,以及关联的 document 链表;
对查询到的 document 求集合运算,得到结果的 document 标识;
获取结果的 document 中对应的 field 数据,返回呈现给用户;
11.1.5 Java Example
我们以代码为例讲述索引流程:
xxxxxxxxxxpublic void test() throw Exception { // 1. 采集数据 MyDao myDao = new myDaoImpl(); List<MyModel> modelList = myDao.queryModelList(); // 2. 创建Document文档对象 List<Document> documents = new ArrayList<Document>(); for (MyModel model : modelList) { Document document = new Document(); // Document文档中添加Field域 // Store.YES:表示存储到文档域中 document.add(new TextField("id", model.getId(), Field.Store.YES)); // 商品名称 document.add(new TextField("name", model.getName(), Field.Store.YES)); // 商品价格 document.add(new TextField("price", model.getPrice().toString(), Field.Store.YES)); // 品牌名称 document.add(new TextField("brandName", model.getBrandName(), Field.Store.YES)); // 分类名称 document.add(new TextField("categoryName", model.getCategoryName(), Field.Store.YES)); // 图片地址 document.add(new TextField("image", model.getImage(), Field.Store.YES)); // 把Document放到list中 documents.add(document); } // 3. 创建Analyzer分词器,分析文档,对文档进行分词 Analyzer analyzer = new StandardAnalyzer(); // 4. 创建Directory对象,声明索引库的位置 Directory directory = FSDirectory.open(Paths.get("/home/test/")); // 5. 创建IndexWriteConfig对象,写入索引需要的配置 IndexWriterConfig config = new IndexWriterConfig(analyzer); // 6.创建IndexWriter写入对象 IndexWriter indexWriter = new IndexWriter(directory, config); // 7.写入到索引库,通过IndexWriter添加文档对象document for (Document doc : documents) { indexWriter.addDocument(doc); } // 8.释放资源 indexWriter.close();}最终 Lucene 会在 /home/test/ 下生成若干索引文件,我们可以使用 Lucene 自带的图形化解析工具 Luke 查看。
而查询的代码过程:
xxxxxxxxxxpublic void testIndexSearch() throws Exception { // 1. 创建Query搜索对象 // 创建分词器 Analyzer analyzer = new StandardAnalyzer(); // 创建搜索解析器,第一个参数:默认Field域,第二个参数:分词器 QueryParser queryParser = new QueryParser("brandName", analyzer); // 创建搜索对象 Query query = queryParser.parse("name:手机 AND 华为"); // 2. 创建Directory流对象,声明索引库位置 Directory directory = FSDirectory.open(Paths.get("E:\\dir")); // 3. 创建索引读取对象IndexReader IndexReader reader = DirectoryReader.open(directory); // 4. 创建索引搜索对象 IndexSearcher searcher = new IndexSearcher(reader); // 5. 使用索引搜索对象,执行搜索,返回结果集TopDocs // 第一个参数:搜索对象,第二个参数:返回的数据条数,指定查询结果最顶部的n条数据返回 TopDocs topDocs = searcher.search(query, 10); System.out.println("查询到的数据总条数是:" + topDocs.totalHits); // 获取查询结果集 ScoreDoc[] docs = topDocs.scoreDocs; // 6. 解析结果集 for (ScoreDoc scoreDoc : docs) { // 获取文档 int docID = scoreDoc.doc; Document doc = searcher.doc(docID); System.out.println("============================="); System.out.println("docID:" + docID); System.out.println("id:" + doc.get("id")); System.out.println("name:" + doc.get("name")); System.out.println("price:" + doc.get("price")); System.out.println("brandName:" + doc.get("brandName")); System.out.println("image:" + doc.get("image")); } // 7. 释放资源 reader.close();}11.1.6 Field 域类型
是否分词(tokenized):是否作分词处理,即将Field值进行分词,分词的目的是为了索引;
比如:商品名称、商品描述等,这些内容用户要输入关键字搜索,由于搜索的内容格式大、内容多需要 分词后将语汇单元建立索引;
而比如:商品id、订单号、身份证号等,不需要分词;
是否索引(indexed):指将 Field 分词后的词或整个 Field 值进行索引,存储到索引域,索引的目的是为了搜索;
比如:商品名称、商品描述分析后进行索引,订单号、身份证号不用分词但也要索引,这些将来都要作为查询条件;
图片路径、文件路径等,不用作为查询条件的不用索引;
是否存储(stored):将 Field 值存储在文档域中,存储在文档域中的 Field 才可以从 Document 中获取;
比如:商品名称、订单号,凡是将来要从 Document 中获取的 Field 都要存储;
图片路径、文件路径等,不用作为查询条件的不用索引;
11.1.7 维护索引
创建(之前提过):
IndexWriter#addDocument(Document);修改:
IndexWriter#updateDocument(Term, newDocument);使用
Term对象,筛选符合的Document;删除:
IndexWrite#deleteDocuments(Term);
11.1.8 Tokenism & Analyzers
Analyzer 的分词化过程:
将 Document 中 Field 的 value 值切分成一个一个的 tokens;
过滤:包括去除标点符号过滤、停用词(stop words)过滤、大写转小写、词的形还原(复数形式转成单数形参、过去式转成现在式)等;
Analyzer 使用时机:
建立索引时:针对有需要分词的 document 传入
IndexWriterConfig,对其进行分词化并且作为索引存入索引库;搜索时:用户传入关键字查询指令时(传入
QueryParser),先分词为关键字,再去倒排索引表中查找;
内置分词器:
StandardAnalyzer:标准分词器,可以对用英文进行分词,对中文是单字分词;WhitespaceAnalyzer:仅去除空白字符;SimpleAnalyzer:将除了字母以外的符号全部去除,并且将所有字母变为小写,需要注意的是这个分词器同样把数字也去除了,同样不支持中文;CJKAnalyzer:支持中日韩文字,对中文是二分法分词,去掉空格,去掉标点符号;
11.1.9 Advanced Search
仅文本:
xxxxxxxxxxQueryParser queryParser = new QueryParser("brandName", analyzer);Query query = queryParser.parse("name:华为手机");数值范围:
xxxxxxxxxxQuery query = FloatPoint.newRangeQuery("price", 100, 1000);针对 Term 搜索(精确搜索):
xxxxxxxxxx// 使用 Term 相对于 QueryParser 可以减少解析成本Term term = new Term("name", "123");Query query = new TermQuery(term);针对 Term 文本前缀:
xxxxxxxxxxTerm term = new Term("name", "Huawei");Query query = new PrefixQuery(term);Wildcard 匹配:
xxxxxxxxxxTerm term = new Term("name", "?uawei*");Query query = new WildcardQuery(term);模糊匹配(只是相似,不要求准确包含):
xxxxxxxxxxTerm term = new Term("name", "huwei");Query query = new FuzzyQuery(term);向量搜索(KNN 算法):
xxxxxxxxxx// 需要本身是 KNN field// document.addField(new KnnVectorField(“field”, float[] vector))Query query = new KnnVectorQuery(“field”, float[] vector, int topK);组合搜索:
xxxxxxxxxxQuery query1 = FloatPoint.newRangeQuery("price", 100, 1000);QueryParser queryParser = new QueryParser("name", analyzer);Query query2 = queryParser.parse("华为手机");BooleanQuery.Builder builder = new BooleanQuery.Builder();builder.add(new BooleanClause(query1, BooleanClause.Occur.MUST));builder.add(new BooleanClause(query2, BooleanClause.Occur.MUST_NOT));
11.1.10 Similarity Sort
Lucene 会在检索时实时地为搜索关键字和已有关键字的相关程度打分:
计算出词(Term)的权重;
根据词的权重值,计算文档相关度得分;
索引的最小单位是一个分词(Term,就是常说的 token)。Term 对文档的重要性称为权重,影响 Term 权重有两个因素:
Term Frequency (
tf): 指此 Term 在此文档中出现了多少次。tf越大说明越重要。 词 (Term) 在文档中出现的次数越多,说明此词对该文档越重要,如“Lucene”这个词,在文档中出现的次数很多,说明该文档主要就是讲Lucene技术的;Document Frequency (
df): 指有多少文档包含次 Term。df越大说明越不重要。 因为它更有可能是接近停用词的含义;或者说有越多的文档包含此词,说明太普通,不足以区分这些文档,因而重要性越低;
我们可以人为地更改 Lucene 内部计算权重的逻辑,进而影响相关度的排序结果。例如,数据记录有一列是专门描述 feature 程度的因子(可能是广告因子),我希望在原始查询的基础上,考虑新的相关度为 原相关度 + 0.7 * feature 因子数,那么:
xxxxxxxxxxQuery originalQuery = new BooleanQuery.Builder() .add(new TermQuery(new Term("body", "apache")), Occur.SHOULD) .add(new TermQuery(new Term("body", "lucene")), Occur.SHOULD) .build(); Query featureQuery = FeatureField.newSaturationQuery("features", "pagerank"); Query query = new BooleanQuery.Builder() .add(originalQuery, Occur.MUST) .add(new BoostQuery(featureQuery, 0.7f), Occur.SHOULD) .build();
Chapter 12. RESTful Web Service
Web Service 可以提供跨硬件、操作系统、编程语言和应用程序实现真正互操作性的机会。
但是 IPC/RPC 好像也能跨硬件/OS/App 交互?所以提供 IPC/RPC 的应用能否称为一个 web service?
能跨语言交流吗?能在广域网上部署吗?
先进行一个说文解字:
web:通过网络协议访问。这比一般的 IPC/RPC 的访问能力更强,因为网络协议更加严格,针对网络传输进行了优化;
services:与实现无关的接口,供 client 使用;Services 解决的是异构的问题(操作系统、编程语言的差异),比如客户端是 C# 开发的,服务端是 Java 开发的,那为了方便他们之间的交互,我们需要在已有的网络协议(HTTP/SMTP/FTP 等)基础上定义一系列用于应用信息交换的格式 / 协议。
如何实现一个 Web Service?人们想出了一些协议来实现上述对于 web service 的愿望。
12.1 SOAP & WSDL
SOAP: Simple Object Access Protocol,是一种基于 XML 格式的协议,它针对 API 纯文本化传递。
这种协议下,暴露接口的方式是借助一种 XML 格式文件,被称为 WSDL(Web Service Description Language,网络服务描述语言),它是一种 Web XML 的规范,相当于一个“菜单”,目的就是用通用格式(XML)告诉不同种类的 client,这个服务可以使用哪些方法。
注意,WSDL 只是一种描述方式,不和 SOAP 强绑定。
而 client 请求的消息就要遵循 SOAP 这个协议,向提供服务的 server 发送一个请求的 XML 信息。
这样做就能真正实现 “platform independent data exchange”;
注:WSDL 文件不需要自己写,通过工具生成。会根据接口、参数类型、参数顺序、接口返回的参数类型,全部用 XML 来表述出来;
Service Bindings:就是服务的具体实现形式,比如我们的服务可以支持 HTTP/SMTP/FTP 这 3 个协议,就说明这个 web service 有 3 个 bindings。
就是说 bindings 是服务在应用层协议上的具体实现。
举个例子:假设一个 Java 程序需要访问一个 C# 程序监听的服务。主要需要以下步骤:
Java Client 将 C# Server 提供的 WSDL 文件取回(请求方法、文件位置由 SOAP 协议规定);
Java Client 的 SOAP 框架根据 WSDL 文件生成一个本语言的 Method Interface;
Java Client 的用户代码进行 Java 自己的 Method Invocation;
Java SOAP 框架中的通信 Proxy Class 拦截这个 Java Method Invocation,将它按照 SOAP 规定翻译为 XML 文本,向 C# server 发送;
C# Server 接收到 XML 信息被 C# 的 SOAP 框架的 Proxy Class 拦截,翻译为具体在 C# 中的调用逻辑。产生结果后用类似的方法转为 XML 消息传递给 Java Client;
Java Client 侧的 SOAP 框架接收到 XML 回复,根据 SOAP 将其转为 Java 中的返回结果,然后 Java Client 代码从 Proxy Class 中得到最终结果;
SOAP 的优点和缺陷:
SOAP 的好处是,支持多种安全机制,如数字签名和加密,以确保消息传递的安全性;
坏处:
很明显,传输途中需要多次编解码,并且 XML 格式消息存储效率低(冗长、同量级下信息量少),传输效率低,而且还会借助其他的协议(HTTP/SMTP)来实现传递,性能不佳;
需要外挂 WSDL 文件;
客户端、服务端和 API 耦合,一旦 API 发生变化(比如方法参数个数改变),那么 WSDL 文件就要发生变化,服务端客户端代码都需要重新生成;
12.2 RESTful Web Service
12.2.1 Definitions
于是我们想,如果用 “数据驱动” 的传递方法会不会更加高效?
所谓的 “数据驱动”,就是针对数据资源的请求。我们把服务类型、参数传递,这类信息全部变成 “数据资源”,把调用方法蕴含在 HTTP 方法中。
例如获取订单信息,就是 GET 特定 path 下的某个文件,删除书籍也是 DELETE 特定 path 下的某个文件,修改库存是 POST 特定路径下的某个资源。
这样既可以完成跨语言提供服务的需求,又能规避 SOAP 传输不高效的问题(只要我们事先有个 API 文档描述服务和这个 “特定 path” 的对应关系)。
因为我们借助 HTTP 的请求头 + 请求体,可以直接传输纯数据而不需要借助 XML 文本描述它。
并且 server 永远基于数据,返回还是一种数据(所以大多数情况下可以是函数式的、stateless 的)。
这种面向数据资源的思路,就是 RESTful 的思想。
注:2000 年的时候,有个人在他的博士论文中提出了一套软件架构的设计风格(不是标准 / 协议,只是一组设计风格、共同约定),它主要用于 web service 的实现中。这个人就是 Roy Thomas Fielding。
基于这个风格设计的软件不仅仅可以实现上述 Web Service 的要求、规避 SOAP 的缺陷,还能使应用开发更简洁,更有层次,更易于实现缓存等机制(和 SOAP 相比)。
这个设计风格也被命名为 “表述性状态转移”(REpresentational State Transfer,REST)的架构风格。满足这个架构风格的接口设计就被称为 RESTful API。
所谓 “表述性”:
所有的数据都是资源(既然是资源,就可以通过统一资源标识符(URI)来描述,这个 URI 就是我们前面说的 “特定的 path”);
这个 URI 和资源的对应关系就是用 API 文档进行表述并约定;
每一个资源都可以有不同的表现方式、有独有的 URI;
所谓 “状态”:指的是客户端的状态,客户端维护自己的状态,服务器是无状态的。
所谓 “状态转移”:指的是客户端的状态可以在调用接口的过程中发生转移;
12.2.2 Principles of REST
那么 REST 的这个 “风格” 的特征是什么?或者说它的 “共同约定” 是什么?
REST 架构的 6 个限制条件,又称为 RESTful 6 大原则:
客户端-服务端分离(解耦);
无状态的(Stateless):服务端不保存客户端状态,客户端保存状态信息每次请求携带状态信息;
可缓存性(Cacheability) :服务端需回复是否可以缓存以让客户端甄别是否缓存提高效率;
统一接口(Uniform Interface):通过一定原则设计接口降低耦合,简化系统架构,这是 RESTful 设计的基本出发点;
这组接口就是针对资源的操作,包括获取、创建、修改、删除。
恰好对应了 HTTP 协议提供的 GET、POST、PUT 和 DELETE 方法。
注意,REST 原则强烈不建议接口动作与资源访问标识符混合使用。
REST 认为,URI指向资源、以资源为基础,应该以名词标识,真正的动作应该从 HTTP 的请求动作上识别。
注 1: Universal Resource Identifier 统一资源标志符,用来标识抽象或物理资源的一个紧凑字符串。URI 包括 URL(Locator)和 URN(Navigator);
注 2:一个资源可以是文本(通常以 JSON / HTML / XML 为载体)、二进制流等其他任何数据(一般从数据库中拿到的);
分层系统(Layered System):客户端对服务端的情况无感,无法直接知道连接的到终端还是中间设备,分层允许灵活地部署服务端项目;
按需代码(Code-On-Demand,可选):允许我们灵活的发送一些看似特殊的代码给客户端例如 JavaScript 代码。
当然,RESTful API 也是有缺陷的,例如过于重视资源的作用,导致一些与资源关系不大的场合(例如聊天服务器、通信服务器)如果使用 RESTful Web Service 则反而加重了开发负担。
12.2.3 Design Standards of RESTful API
如果想要自己设计一个 RESTful API,那么就要遵循以上的约定。
资源的 URI path 是需要认真考虑的,而 RESTful 对 path 的设计做了一些规范,通常一个 RESTful API 的 path 组成如下:
xxxxxxxxxx/{version}/{resources}/{resource_id}
version:API 版本号,有些版本号放置在头信息中也可以,通过控制版本号有利于应用迭代;resources:资源,RESTful API 推荐用小写英文单词的复数形式;resource_id:资源的 id,访问或操作该资源;
当然,有时候可能资源级别较大,其下还可细分很多子资源也可以灵活设计 URL 的 path,例如:
xxxxxxxxxx/{version}/{resources}/{resource_id}/{subresources}/{subresource_id}此外,有时可能增删改查无法满足业务要求,可以在 URL 末尾加上 action,例如
xxxxxxxxxx/{version}/{resources}/{resource_id}/action其中 action 就是对资源的操作。
从大体样式了解 URL 路径组成之后,对于 RESTful API 的 URL 具体设计的规范如下:
不用大写字母,所有单词使用英文且小写;
连字符用中杠
"-"而不用下杠"_";正确使用
"/"表示层级关系,URL的层级不要过深,并且越靠前的层级应该相对越稳定;结尾不要包含正斜杠分隔符
"/";URL中不出现动词,用请求方式表示动作;
资源表示用复数不要用单数;
不要使用文件扩展名;
此外,在 RESTful API 中,不同的 HTTP 请求方法有各自的含义,这里就展示 GET,POST,PUT,DELETE 几种请求 API 的设计与含义分析。针对不同操作,具体的含义如下:
xxxxxxxxxxGET /collection: 从服务器查询资源的列表(数组)GET /collection/resource: 从服务器查询单个资源POST /collection: 在服务器创建新的资源PUT /collection/resource: 更新服务器资源DELETE /collection/resource: 从服务器删除资源在非 RESTful 风格的 API 中,我们通常使用 GET 请求和 POST 请求完成增删改查以及其他操作,查询和删除一般使用 GET 方式请求,更新和插入一般使用 POST 请求。从请求方式上无法知道 API 具体是干嘛的,所有在 URL 上都会有操作的动词来表示 API 进行的动作,例如:query,add,update,delete 等等。
而 RESTful 风格的 API 则要求在 URL 上都以名词的方式出现,从几种请求方式上就可以看出想要进行的操作,这点与非 RESTful 风格的 API 形成鲜明对比。
在谈及 GET,POST,PUT,DELETE 的时候,就必须提一下接口的安全性和幂等性,其中安全性是指方法不会修改资源状态,即读的为安全的,写的操作为非安全的。而幂等性的意思是操作一次和操作多次的最终效果相同,客户端重复调用也只返回同一个结果。
| HTTP Method | 安全性 | 幂等性 | 解释 |
|---|---|---|---|
| GET | 安全 | 幂等 | 读操作(安全),查询多次结果一致 |
| POST | 非安全 | 非幂等 | 写操作(非安全),每次插入后与上次的结果不一样 |
| PUT | 非安全 | 幂等 | 写操作(非安全),插入相同数据多次结果一致 |
| DELETE | 非安全 | 幂等 | 写操作(非安全),删除相同数据多次结果一致 |
12.3 Conclusion
总而言之,使用 Web Service 有下述优缺点:
优点:
跨平台,基于 XML,JSON 等等;
自描述:WSDL 就是一个自描述文件;而 RESTful API 使用针对资源的描述方法;
模块化良好:不需要关系具体的实现;
区域访问性质广,可以穿透防火墙;
缺陷:
编码的效率低,不适合 stand-alone 应用,SOAP 显然比之间 RPC 效率低,而 REST 传递的是纯数据,也需要编解码消耗资源;
性能不佳。和 stand-alone 应用不同,中间存在数据序列化和反序列化;
更需要保证安全性:跨越地域广,容易受到 man-in-the-middle-attack;
Chapter 13. Revisit: Microservices
如果应用中的所有接口都封装为 RESTful Web Service,那么这个系统是否是微服务呢?
微服务的定义:Microservices are a modern approach to software whereby application code is delivered in small, manageable pieces, independent of others.
微服务的优点:Their small scale and relative isolation can lead to many additional benefits, such as easier maintenance, improved productivity, greater fault tolerance, better business alignment, and more.
微服务是一种软件架构风格。专注于单一职责的小型业务为基础,组成复杂大型应用。
需要解决的问题:服务拆分、远程调用(RPC)、服务治理(可用性与调度)、请求路由、身份认证、配置管 理、分布式事务(一致性问题)、异步通信……
特征:粒度小,团队自治,服务自治;
优点:
易于维护、单服务开发便捷;
系统耦合性低、更强的 fault tolerance;
业务对齐(business alignment),即业务战略、目标、流程和组织结构与信息技术架构和资源之间的协调和整合;
缺点:
跨模块开发难度大;
部署成本高,定位故障点难度增大(必须要建立完善的链路追踪机制、指标监控体系);
模块增多导致系统整体的稳定性下降;
牺牲了系统性能;
对比而言,单体架构:
优点:架构简单、部署成本低(适用于开发功能相对简单、规模较小的项目);
缺点:团队协作成本高,系统发布效率低、系统可用性差(软件可靠性差);
13.1 注册中心 & 微服务网关
在微服务架构中,规避微服务间直接远程调用缺陷的一种方式就是引入注册中心机制,借鉴发布-订阅模式,引入注册中心后的主要步骤如下:
服务发布者向注册中心注册服务信息(提供何种服务,即 topic,还有地址在哪里);
服务订阅者向注册中心订阅感兴趣的服务。此时注册中心可以将当前可用的发布者信息告诉订阅者;
订阅者(或者注册中心)可以进行负载均衡,选择一个发布者向其请求服务(远程调用)。
由于我们利用了发布-订阅模式,所以即便是已经获取服务列表的订阅者,也能从注册中心实时获取当前发布者的可用情况。
微服务网关:
请求路由(路径针对什么微服务?);
转发(帮忙将 HTTP 请求 forward 给某个动态地址的实例);
身份校验(检查请求的
Authorization是否合法);
13.2 微服务雪崩
在微服务相互调用中,服务提供者出现故障或阻塞。并且:
服务调用者没有做好异常处理,导致自身故障;
或者访问连接一直保持 / 请求速度大于处理速率,致使请求不断堆积在 tomcat 中导致资源耗尽;
最终,调用链中的所有服务级联失败,导致整个集群故障。
解决微服务雪崩的思路主要如下:
尝试避免出现故障 / 阻塞;
保证代码的健壮性;
保证网络畅通;
能应对较高的并发请求;
微服务保护:保护服务提供方;
局部出现故障 / 阻塞后,及时做好预备方案(积极有效的错误处理);
微服务保护:保护服务调用方;
13.3 微服务保护
为了应对微服务雪崩,我们有许多解决方案。其中,微服务保护是在业务逻辑代码层面以外的一种重要方案。
微服务保护有以下一些思路:
请求限流:保护服务提供方。限制访问微服务的请求的并发量,避免服务因流量激增出现故障(应对访问模式:spike 型);
线程隔离(舱壁模式):保护服务消费方。通过限定每个业务能使用的线程数量而将故障业务隔离,避免故障扩散;
快速失败 和 服务熔断:
快速失败:给业务编写一个调用失败时的处理的逻辑,称为
fallback。当调用出现故障(比如无线程可用)时,按照失败处理逻辑执行业务并返回,而不是直接抛出异常;由断路器统计请求的异常比例或慢调用比例,如果超出阈值,则认为某个微服务业务所对应的所有实例都不可用,熔断该业务,则拦截该接口的请求。熔断期间,所有请求均
fallback为快速失败逻辑;
Chapter 14. HTAP
14.1 Business Logic
Hybrid Transactional/Analytical Processing,或者说 “混合事务分析处理”,它在正常业务应用的时候,分为两个部分:
Online Transaction Processing (OLTP),在线事务处理。类似订单提交的业务;
需要低延迟、高并发、单次数据量小;
Online Analytical Processing (OLAP),在线分析处理。类似双十一结束后需要统计消费信息;
允许高延迟、低并发(做统计的人大部分是内部人员),但需要处理大量数据;
在这两种应用场景下,我们发现 OLTP 适合按行存储数据记录,OLAP 适合按列存储数据记录;
因此需要看业务逻辑中哪种业务比较多,就用何种存储方法。
另外,如果行列都存,则需要花费两倍存储空间,会引入空间浪费、数据一致型问题。
能不能让一种 Database 做行列数据转换,让它既对于 OLTP 友好,又对 OLAP 友好?
一种思路是进行 Vertical Partition,给 Columns 分组,不同的组可以使用不同数据表示方式(行/列),这种方法在 MySQL 中不计划支持,但是 LSM Tree 可以支持:

再回过头看 LSM-Tree 的缺陷,由于写阻塞的存在,实际上对于 OLTP 的业务支持不足。
由于牺牲了读性能,所以对于 OLAP 的支持也不足。
14.2 Solutions
首先为了解决写阻塞对于 OLTP 的影响,我们可以在数据源和 LSM Tree 间设置收集分发层(Collectors,例如 Apache Flink);

收集分发层能完成两个作用:
写阻塞时缓存数据,作为 short path 降低时延;
定期将缓存的数据持久化到 LSM-Tree 中,相当于为 LSM-Tree 留出写时延的时间;
采用中心化设计:master 主从备份、向 master 提供 collector 的空间占用、剩余内存情况,进行负载均衡;
其次,为了解决读性能对于 OLAP 的影响,考虑向 LSM-Tree 中添加列式存储,便于分类压缩、对内存友好。
总结一下:

其实在关系型数据库 MySQL、基于文档型的 NoSQL MongoDB 中也有类似的方案确保对于 OLAP 和 OLTP 的良好支持。
Chapter 15. Data Lake
15.1 Concepts
考虑一种 OLAP 的场景:从很多类型的数据库、很多类型的数据表(多元数据)中抽取出有价值的内容,按照同一种方式存储,方便分析。
主要进行 3 个步骤(ETL):Extract(多元数据抽取)、Transfer(单位转换、数据清洗)、Load(加载到内存);
处理的性能代价很大,可以先存起来,用到的时候再做(Lazy Process)。
这就是数据湖(Data Lake)的理念。我们将未经处理的多元数据可以直接以原始的格式 存放到数据湖中(肯定需要包含 metadata 以供检索操作等等),需要时再取出处理。
A data lake is a centralized repository designed to store, process, and secure large amounts of structured, semistructured, and unstructured data(可以包含结构、非结构、半结构化数据). It can store data in its native format and process any variety of it, ignoring size limits.
因此,我们需要一个很强的数据接入能力(ingest!例如 flink),并且对上提供一体化的查询功能(用户一个 SQL 可以转换到底层不同类型的数据库的数据查询);
parquet 数据格式几乎所有主流数据库都支持。可以将底层数据都转换成 parquet 格式,方便上层数据处理程序分析。
data lake 的一个实现产品是 delta lake;
我们区分一下 data lake 和 data warehouse 的概念:
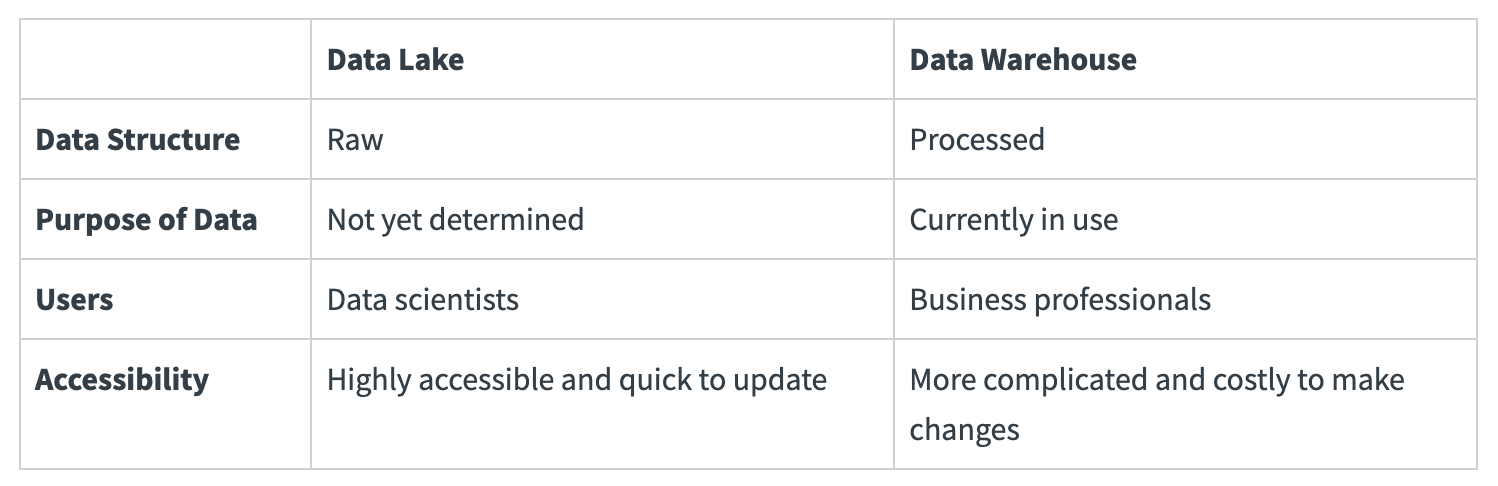
"Not Yet Determined":类似 OS 日志,可能这个数据只是记录一下,没有故障的话可能根本不会用上,不确定要怎么用,也就是现在用不上的数据。不会做 ETL 3 步;
| 数据湖 | 数据仓库 |
|---|---|
| 能处理所有类型的数据,如结构化数据,非结构化数据,半结构化数据等,数据的类型依赖于数据源系统的原始数据格式。 | 只能处理结构化数据进行处理,而且这些数据必须与数据仓库事先定义的模型吻合。 |
| 读取的时候设计 schema,存储原始原始数据 | 写入时设计数据仓库,存储处理后的原始数据 |
| 拥有足够强的计算能力用于处理和分析所有类型的数据,分析后的数据会被存储起来供用户使用。 | 处理结构化数据,将它们或者转化为多维数据,或者转换为报表,以满足后续的高级报表及数据分析需求。 |
| 数据湖通常包含更多的相关的信息,这些信息有很高概率会被访问,并且能够为企业挖掘新的运营需求。 | 数据仓库通常用于存储和维护长期数据,因此数据可以按需访问。 |
数据湖与数据仓库的差别很明显。 然而,在企业中两者的作用是互补的,不应认为数据湖的出现是为了取代数据仓库,毕竟两者的作用是截然不同的
数据价值性:数仓中保存的都是结构化处理后的数据,而数据湖中可以保存原始数据也可以保存结构化处理后的数据,保证用户能获取到各个阶段的数据。因为数据的价值跟不同的业务和用户强相关,有可能对于 A 用户没有意义的数据,但是对于 B 用户来说意义巨大,所以都需要保存在数据湖中。
数据实时性:数据湖支持对实时和高速数据流执行 ETL 功能,这有助于将来自 IoT 设备的传感器数据与其他数据源一起融合到数据湖中。形象的来看,数据湖架构保证了多个数据源的集成,并且不限制 schema,保证了数据的精确度。数据湖可以满足实时分析的需要,同时也可以作为数据仓库满足批处理数据挖掘的需要。数据湖还为数据科学家从数据中发现更多的灵感提供了可能。
数据保真性:数据湖中对于业务系统中的数据都会存储一份“一模一样”的完整拷贝。与数据仓库不同的地方在于,数据湖中必须要保存一份原始数据,无论是数据格式、数据模式、数据内容都不应该被修改。在这方面,数据湖强调的是对于业务数据“原汁原味”的保存。同时,数据湖应该能够存储任意类型/格式的数据。
数据灵活性:数据湖提供灵活的,面向任务的数据绑定,不需要提前定义数据模型,"写入型 schema" 和"读取型 schema",其实本质上来讲是数据 schema 的设计发生在哪个阶段的问题。对于任何数据应用来说,其实 schema 的设计都是必不可少的,即使是 MongoDB 等一些强调“不需要固定 schema”的数据库,其最佳实践里依然建议记录尽量采用相同/相似的结构。
15.2 Evolution History
首先是 以 HDFS 为核心存储,以 MapReduce 为基本计算模型;
批处理(batch layer,处理已经准备好的非流式数据):例如分布式存储红楼梦,批处理数人物出场数;
随着互联网的发展,HDFS 批处理无法满足实时性要求高的场景(流式数据),因此产生了 lambda 架构 “流批一体”(batch layer + real-time layer 全部汇总到 server layer/backend):
流式处理(real-time layer,实时处理当前数据流的内容);
人们发现,如果加大流计算的并发性和 time window(每 20 ms 批量处理所有数据);于是将 batch layer 和 real-time layer 统一到一起了!
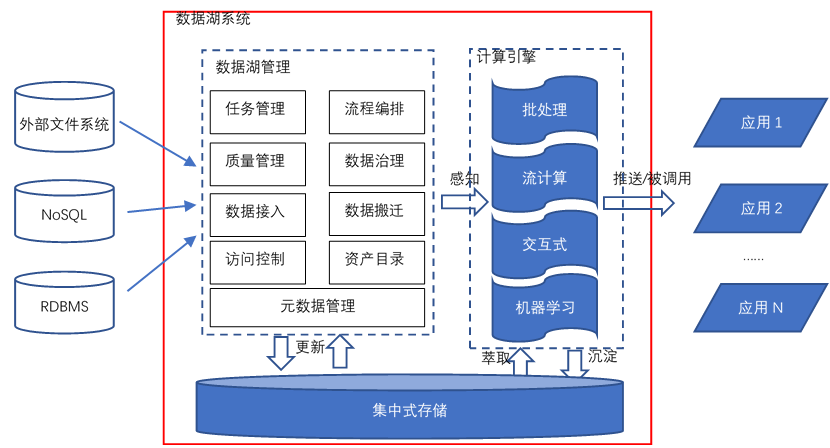
“萃取” 说明在需要的时候才 ETL(而不是在 “更新” 这步做);
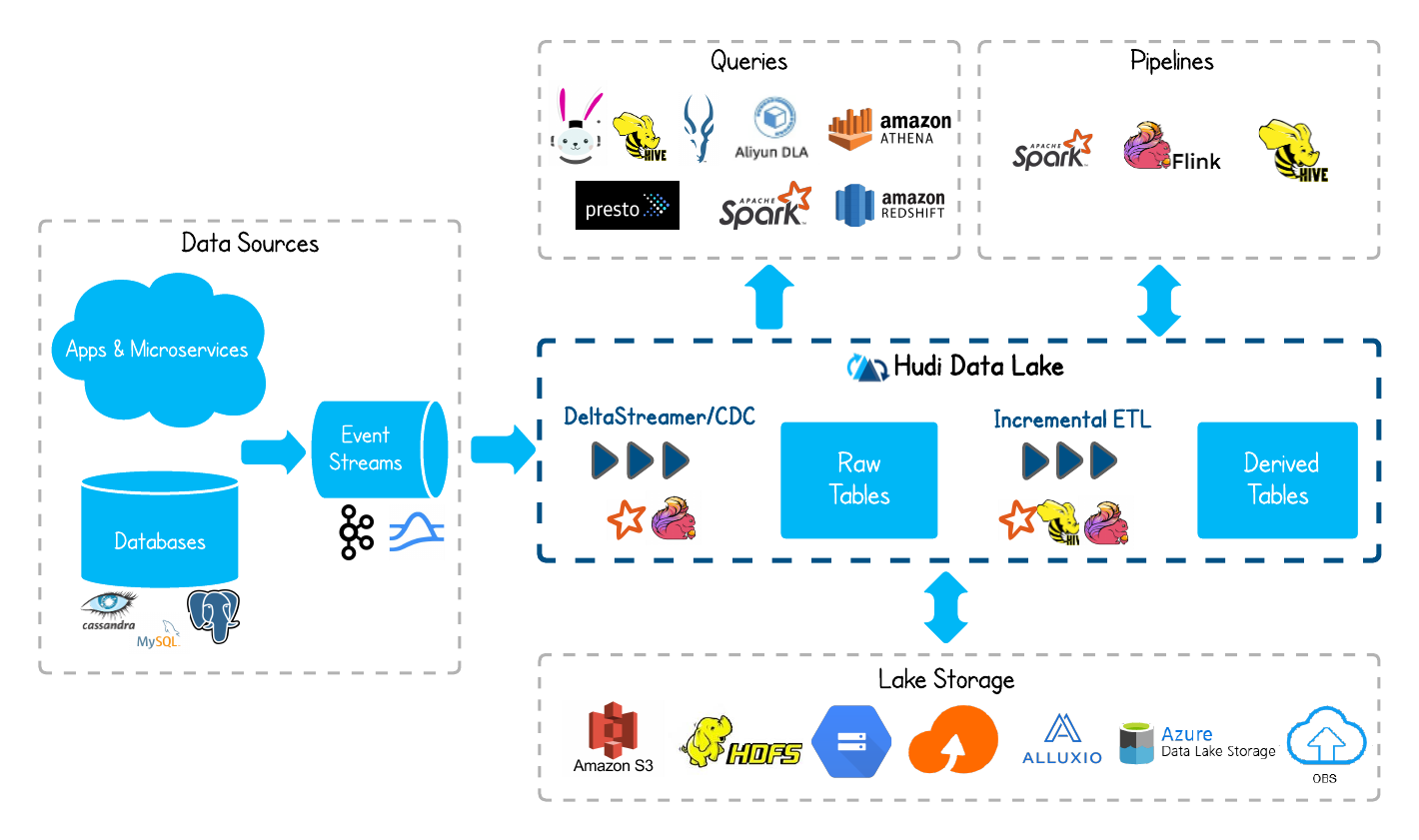
15.3 Data Source 从哪来?
边缘计算服务:物联网设备 -> 边缘计算节点 -> 云数据中心;
没有持久化服务带来的问题:设备移动性(云边融合的数据存储服务,数据存放在各个边缘结点中,很乱)、数据丢失问题;
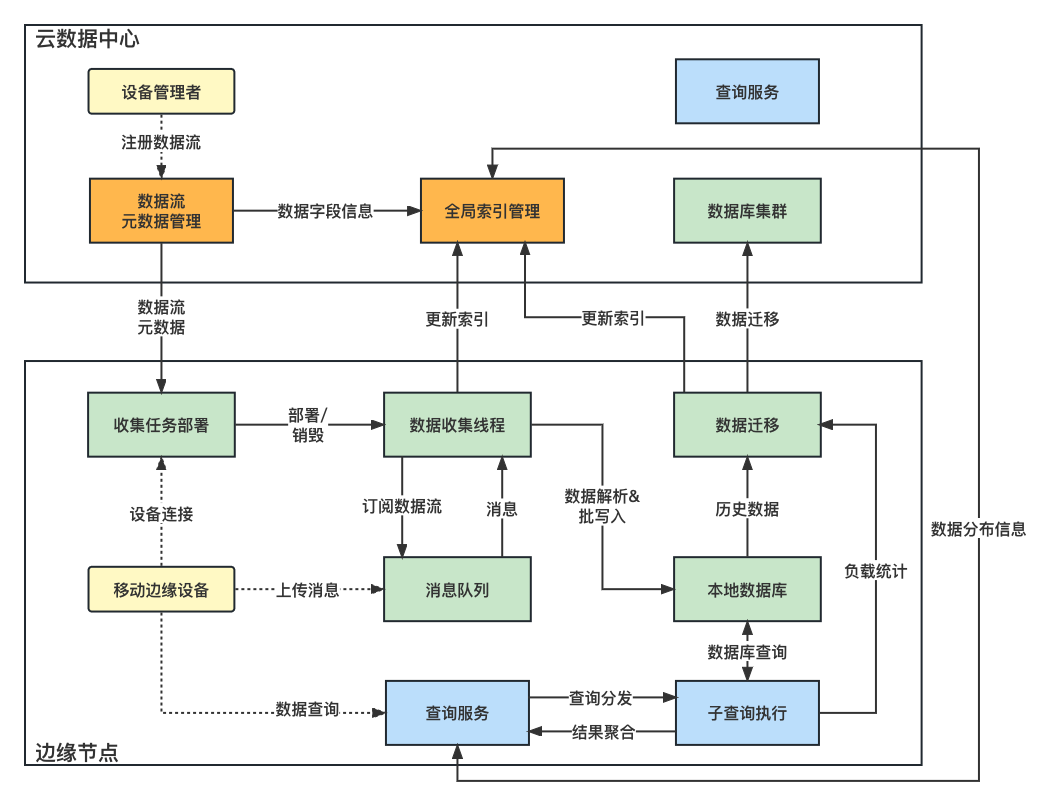
怎么定位数据、怎么做并行分析和优化:
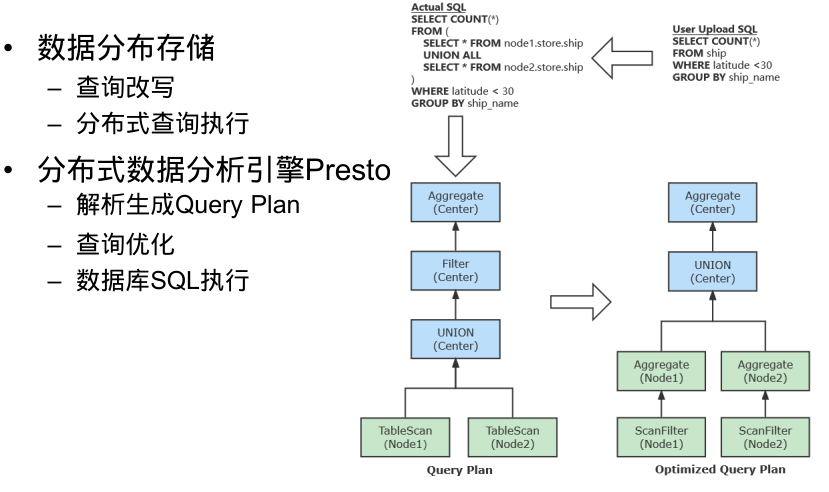
Chapter 16. Cluster
16.1 Why Cluster?
需要高性能、高可用性、高并发性;
有许多用户,可能在许多不同的地方(高性能)、 系统是长时间运行的,不能中断服务(可靠性)、 每秒处理大量事务、 用户数量和系统负载可能会增加、 代表可观的商业价值(比如支付系统是一个很关键的系统,因此为了保证支付的可靠性,很可能需要把常规的业务服务和支付服务分开,保证安全和可靠性)、 由多人操作和管理;
16.2 Load Balance
一般有 3 种方法:
round robin;
优点:算法简单,普通情况下还能保证负载效果;
缺点:
没有考虑到每个请求的处理时长,可能总是将耗时更长的服务负载给特定服务器,可能负载不均;
仅适用于 stateless 的情况,session 需要额外管理;
least connection;
优点:考虑到了请求时长的问题,充分利用了服务器资源;
缺点:session 需要额外管理;
ip-hash;
优点:确保了 session 粘滞性,只要请求的 IP 不变,集群中处理用户请求的机器就不会变;
缺点:负载效果不好。可能一段时间内只有特定的用户在高频请求;并且 session 对 IP 依赖较强,如果用户更改 IP 将无法维持 session;
补充:集群中的 session 维护
除了 load balancer 使用 IP-hash 的负载策略,还有哪些方法可以在集群中维护 session?
用一台单独的服务器,例如 redis,存储用户的 session,这样的话所有的机器只需要在集群里面的 redis 服务器里面拿就可以找到用户的 session。此外,这种方法后端应用服务器重启之后,用户的 session 不会丢失;
后端服务器间建立通信(不合适,因为会造成模块化的破坏);
16.3 MySQL 集群和 Nginx Load Balance Policies
16.4 Proxy & Reverse Proxy
反向代理,指的是代理外网用户的请求到内部的指定的服务器,并将数据返回给用户的一种方式;客户端不直接与后端服务器进行通信,而是与反向代理服务器进行通信,隐藏了后端服务器的 IP 地址。
反向代理的主要作用是提供负载均衡和高可用性。
负载均衡:Nginx可以将传入的请求分发给多个后端服务器,以平衡服务器的负载,提高系统性能和可靠性;
缓存功能:Nginx可以缓存静态文件或动态页面,减轻服务器的负载,提高响应速度;
动静分离:将动态生成的内容(如 PHP、Python、Node.js 等)和静态资源(如 HTML、CSS、JavaScript、图片、视频等)分别存放在不同的服务器或路径上;
多站点代理:Nginx可以代理多个域名或虚拟主机,将不同的请求转发到不同的后端服务器上,实现多个站点的共享端口;
Chapter 17. Cloud Computing & Edge Computing
网格计算:人人为我,我为人人;
云计算:计算资源以服务形式暴露在互联网上;
常见云计算暴露的形式:
SaaS(Software as a Service):虚拟机资源 + 运行环境 + 软件层;即云端已经将操作系统到运行环境到软件的客户端都已经搭建好了,使用方不需要安装任何环境或软件,只需要访问客户端就能直接使用;
PaaS(Platform as a Service):虚拟机资源 + 运行环境。利用云端搭建好操作系统或软件层面的如数据库、中间件等供用户使用,使得用户无需关注底层的基础设施和运行环境,只需要利用这些环境运行自己的应用和数据;
IaaS(Infrastructure as a Service)虚拟机/云服务器资源;
dSaaS(data Storage as a Service):云盘网盘;
云计算的特点:
灵活定价(长期 / 短期租用);
弹性扩容;
快速供给(就像 serverless);
高级虚拟化;
17.1 MapReduce
更详细信息参见 Chapter 19;
我们需要在云上进行作业调度,考虑简单的情况:批处理形式(回忆数据湖)。这个时候 MapReduce 应运而生;

注意到,reduce 开展工作之前,所有的统计工作是都必须完成的,否则就会出错。而不是说来一点处理一点,所有的数据在这里是成批流动的。
Map Reduce 中的 Map 定义是:把输入映射成输出,每个机器不会管别的输入,只会管自己的输入部分,把输入结果产生中间结果。Reduce 负责合并的部分,把所有的中间结果合并,得到最终的输出。

17.2 Distributed File System
17.3 Google BigTable: KV Store 鼻祖
针对极大量的、结构化 / 半结构化的数据的分布式存储系统。
去除了表和表间的外键关联、加强了单个表的存储、索引能力;
引入 column family:像二级分类一样,比如你有十个字段,我们分为 3+3+4,3、3、4 就分别成为列族;schema 可以适当宽松;
基于时间戳的数据存储;
17.4 Summary: Components of Cloud OS
现在我们总结一下,云上的操作系统应该具备的组件:
文件系统:Distributed File System(如 GFS);
任务调度:如 MapReduce;
数据存储:KV Store(如 BigTable);
内存管理:和具体项目有关。例如 GaussDB 将 RDMA 和硬件的特性相结合;
其中,Hadoop 框架就是对上述部分组件的开源实现。我们后面介绍。
17.5 Definitions of Edge Computing
定义:在网络的边缘,临近数据源的地方,来进行数据的处理,是一种优化云计算系统的方式。
与云计算的区别:
In the cloud computing paradigm, most of the computations happen in the cloud, which means data and requests are processed in the centralized cloud.
In the edge computing paradigm, not only data but also operations applied on the data should be cached at the edge.

主要考虑到的就是:
网络连接可能不是持续稳定的,你的数据未必都能发到云里面去,到达核心的云服务器;
通信的带宽可能是受限的,如果大家同时发送,可能很快都占满了;
通常情况下,由于:
为了充分利用端侧计算资源;
或者需要更低的延迟、隐私要求(例如实时视频处理);
或者智能家居需要处理海量的数据,向云端传输处理不现实;
我们会进行 cloud offloading(计算迁移:把计算从云端迁移到边缘端);但这会引入一些问题:
The data at the edge node should be synchronized with the cloud;
Another issue involves the collaboration of multiple edges when a user moves from one edge node to another;
于是人们提出了云边融合计算(Cloud-Terminal Fusion Computing)的理念;存在 Cloud Servers、Mobile Edge Computing Servers(MEC)、Mobile Devices (Edge Devices);
因此我们可以考虑实际情况进行 Local Execution / Full offloading / Partial offloading;
Chapter 18. GraphQL
18.1 为什么需要 GraphQL?
在开发互联网应用时,必然会遇到 Client 和 Server 的通信的处理问题。我们之前介绍过 REST 方案,是 C/S、B/S 通信中最流行的选型。在 REST 中,所有概念都是在可以通过 URL 可访问的资源这个概念周围演化而来的,操作就是对这些资源的 CRUD(按 URL 设计 API);
但 REST 也有问题。在一个 RESTful 架构下,因为后端开发人员定义在各个 URL 的资源上返回的数据,而不是前端开发人员来提出数据需求,使得按需获取数据会非常困难。经常前端需要请求一个资源中所有的信息,即便只需要其中的一部分数据。这个问题被称之为过度获取(overfetching)。最恶劣的场景下,一个客户端应用不得不请求多个而不是一个资源,这通常会发起多个网络请求。这不仅会造成过度获取的问题,也会造成瀑布式的网络请求(waterfall network requests)。
于是,人们为了让客户端只请求其需要的数据——不多也不少,一切在客户端的主导下,一次只需要发起一个请求,因此 GraphQL 作为一种标准,也是 REST 的替代方案,应运而生。
也就是说,客户端可以按需描述需要的数据,让后端处理后返回。这可以极大地减少数据传输量。
但 GraphQL 也有问题:
后端实现难以优化,前端过来的一次请求可能会导致后端的 n 次数据库查询,要保证接口效率就不得不设计一系列数据库缓存机制;
其次依此还可以延伸出安全问题,即使只是一次请求也有可能可以爬取整个数据库,针对这个问题的安全防范措施不同于传统方式;
18.2 GraphQL Grammar
GraphQL 不与任何特定数据库或存储引擎绑定。重要的是在其上抽象的查询语义。
现在来看 GraphQL 的查询和更改语法。
定义类型和枚举:
xxxxxxxxxxtype Query {me: User}type User {id: ID! # !: Not nullname: Stringfriends: [User] # Listtest: [String!]! # Not-null list of not-null string}enum Episode {NEWHOPEEMPIREJEDI}GraphQL 存在内置类型
Object(所有定义的结构的基类)、String / Int / Float / Boolean / ID(内置标量类型);其中ID的序列化方法和 String 相同,通常用作 cache key,但不是 human-readable 的;此外还可以进行
interface、implements、union(联合类型)等等的定义,和 typescript 很类似,不再赘述(区别是缺少分号);
定义文档 和 注释(二者同 python):
xxxxxxxxxx"""A character from the Star Wars universe"""type Character {"The name of the character."name: String!# This is a comment for testtest: Float}查询字段(field):
xxxxxxxxxx# 指定操作类型、操作名称,它们都可以省略(默认 query 操作类型)# 从 root object 开始,找其中的 hero fieldquery HeroNameAndFriends {# 已定义对当前接口的请求的类型就是 Userhero {# 指定取出对象的 namename# 还可以指定查找 Object 类型的字段# 例如这里查找数组中每个元素friends {name}}}除了 query 类型,还有 mutation、subscription 类型;
给定参数查询:
xxxxxxxxxxquery {hero(episode: EMPIRE) {name}# 指定别名(alias)heroAlias: hero(episode: JEDI) {name}}给定查询变量:
xxxxxxxxxxquery HeroNameAndFriends($episode: Episode = JEDI) {hero(episode: $episode) {namefriends {name}}}分段(提取公共部分简化查询):
xxxxxxxxxxquery {leftComparison: hero(episode: EMPIRE) {...comparisonFields}rightComparison: hero(episode: JEDI) {...comparisonFields}}fragment comparisonFields on Character {nameappearsInfriends {name}}分段内仍然可以使用外部变量:
xxxxxxxxxxquery HeroComparison($first: Int = 3) {leftComparison: hero(episode: EMPIRE) {...comparisonFields}rightComparison: hero(episode: JEDI) {...comparisonFields}}fragment comparisonFields on Character {namefriendsConnection(first: $first) {totalCountedges {node {name}}}}
18.3 GraphQL with Spring Boot
引入依赖:
xxxxxxxxxxdependecies { implementation 'org.springframework.boot:spring-boot-starter-graphql'}例如查询书籍,在 *.qgls / *.graphqls 文件中先定义 SDL(或者说 schema):
xxxxxxxxxx# 第一个 Query 类型会被作为查询 root Object field 的默认类型type Query {bookById(id: ID): Book}type Book {id: IDname: StringpageCount: Intauthor: Author}type Author {id: IDfirstName: StringlastName: String}
注意,Spring Boot 会自动在 src/main/resources/graphql 目录下扫描 *.qgls / *.graphqls;
当然我们可以在 application.yaml/properties 中配置 spring.graphql.schema.locations 来指定扫描位置;
再在前端定义查询语句:
xxxxxxxxxxquery bookDetails {bookById(id: "book-1") {idnamepageCountauthor {firstNamelastName}}}
对应的后端处理接口:
xxxxxxxxxxpublic class BookController { // 定义 Query 中的查询接口 public Book bookById( String id) { return Book.getById(id); } // 定义 schema 中的其他类型的解析方法 public Author author(Book book) { return Author.getById(book.authorId()); }}
Chapter 19. Hadoop
和上一章说的一样,云上的操作系统应该具备的组件:分布式文件系统(如 GFS)、任务调度(如 MapReduce)、数据存储(BigTable/LSM Tree)、内存管理(Various);
社区中有一个开源的对于以上全套技术的开源实现,它就是 Hadoop,能够完成一些常用的分布式计算任务。Hadoop 包含几个模块:
Hadoop Common(通用工具模块);
Hadoop Distributed FS(HDFS):回忆 CSE,它完全借鉴了 GFS 的实现;
NameNode = master, DataNode = chunk server;
Hadoop YARN:一个作业调度、集群资源管理框架;
Hadoop MapReduce:基于 Hadoop YARN 构建的,并行数据处理调度系统;
Hadoop Storage: Hadoop 存储系统提供了多种实现,满足不同需求:
HBase:一个基于 HDFS 的、针对 NoSQL 表的分布式列式存储系统;
Hadoop Ozone:针对 Hadoop 的对象存储系统;
Hive / Pig / ...:基于 HDFS 的数据处理/分析系统(定位:数据仓库);
MapReduce 1.0:
input split(shards):每个 mapper 输入若干个 input split;
Job Tracker(Master):资源管理、任务调度;
heartbeat:必须内嵌在正常执行的程序内。可以由 MapReduce 框架管理。master 判断心跳断开的依据是,指定时间内心跳次数少于某个阈值。
Mapper 输出的 intermediate files 需要是经过排序的、按照 reducers 数量进行分区;
The total number of partitions is the same as the number of reduce tasks for the job
Combiner 可有可无,主要是进行 local aggregations(reducers 则是做 global aggregations),因此 combiners 可以转化为程序内部的 aggregation 算法;
Reducer 也可以没有,取决于应用场景;
Reducer 主要有 3 个阶段:
Shuffle、Sort:此阶段 reducers 会从 mappers 相关的 partition 中通过 HTTP 取出数据;同时进行 merge sort;
Reduce:在 reduce 后结果不一定是有序的。
如何确定 Mapper 和 Reducer 的数量?
Mapper 的数量可以参考 input 的量来确定。例如对于统计多个文件单词数的场景,mapper 数量最好和 file blocks(shards)的数量一致。不过需要考虑物理节点的具体性能(常见的布置方法在 10~100 个 mappers 为宜);
Reducer 的数量:0.95 或者 1.75
0.95:希望各个容器间进程切换开销小一点,因为当前节点的处理能力比较弱;
1.75:希望充分利用 I/O Block 期间空闲的 CPU 资源,加快切换速度,最大化利用节点计算资源;
MapReduce 的实例如下:
我们注意到,MapReduce 重度依赖 Disk I/O 操作,会有性能问题。当然,人们也有在内存中操作的想法,这就是后来的 Spark 框架。
人们对 MapReduce 进行改进,于是出现了 MapReduce 2.0(YARN)。它的思路是将之前统一的 “资源管理”、“任务调度” 这两个任务分开:
使用全局的资源管理器(Global RM);
应用粒度级别的 Master(Application Master);
这里一个 Application 可以是一个 Job,也可以是一个 computing graph(计算图,通常是 DAG);具体流程如下:
Decentralized Application Master 比 MapReduce 1.0 中的 JobTracker 的可用性更强;
这同时解决了性能瓶颈(RM 的工作负载并不高,不需要关系容器存活情况)以及可用性问题。
Chapter 20. Spark
20.1 Overview
内存中进行分布式计算和大规模数据分析的框架,性能较好(会比 Hadoop 性能好两三个数量级)。
但内存不够的话也会发送频繁 swap,造成性能下降;
支持 Batch + Streaming data;
支持 SQL 直接操作;
支持机器学习、数据处理;
数据结构更简单(因为不需要考虑磁盘中的结构),处理更方便;
使用 scala 编写;
换出策略:LRU(remove)/ Swap(to disk);
xxxxxxxxxx// stage 1lines = spark.textFile(“hdfs://...”)errors = lines.filter(_.startsWith(“ERROR”))messages = errors.map(_.split(‘\t’)(2))// Stage 的 lazy execution// 具体是否真的是 cache 到内存里,还是得看当前的内存使用情况(spark 仍有可能 swap 掉)// 因此这里的 cache 是一种 “愿望”cachedMsgs = messages.cache()
// stage 2// reduce & action:如果没有 count 这一步,那么之前 spark 只会建立计算图,然后 lazy execution// 但是有 count 这个 action 就会立即开始计算cachedMsgs.filter(_.contains(“foo”)).countcachedMsgs.filter(_.contains(“bar”)).count20.2 Spark Components
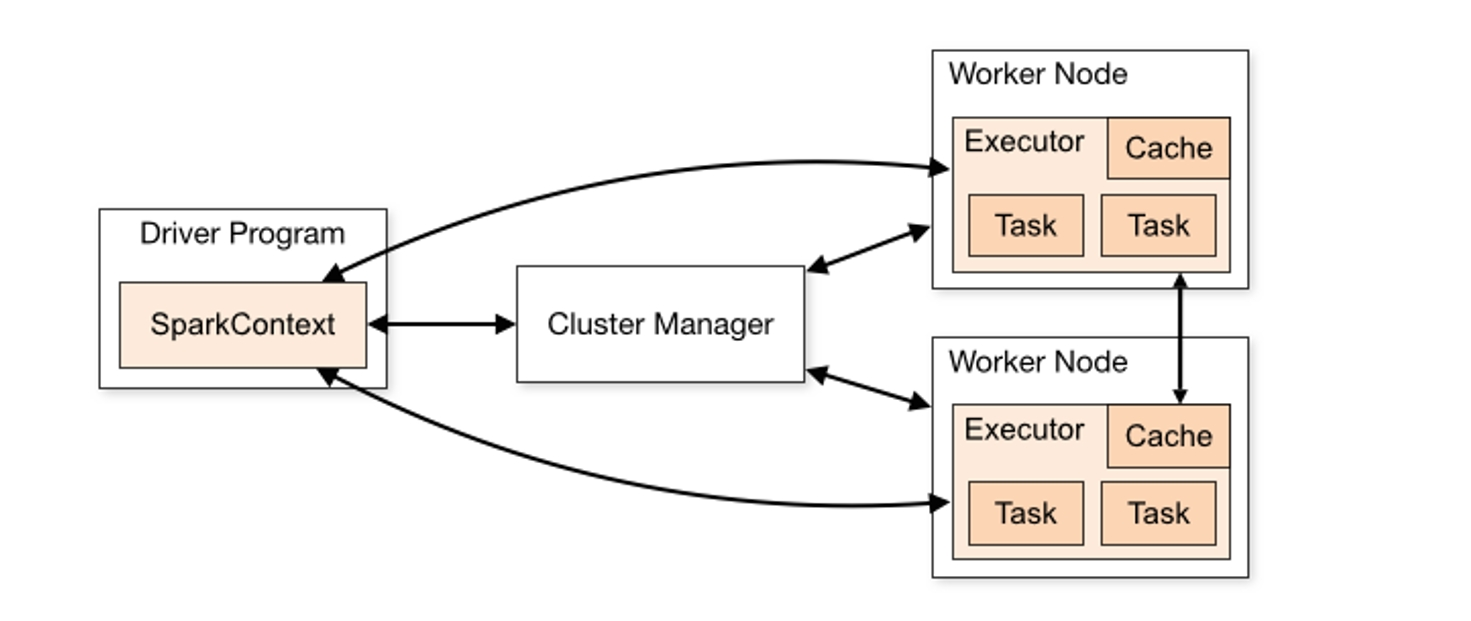
| Term | Meaning |
|---|---|
| Application | Spark 应用程序,由集群上的一个 Driver 节点和多个 Executor 节点组成。 |
| Driver Program | 主应用程序,该进程运行应用的 main() 方法并且创建 SparkContext |
| Cluster Manager | 集群资源管理器,Spark 可以运行在多种集群管理器上,包括 Hadoop YARN、Apache Mesos、Standalone。 |
| Worker Node | 执行计算任务的工作节点 |
| Executor | 位于工作节点上的应用进程,负责执行计算任务并且将输出数据保存到内存或者磁盘中 |
| Task | 被发送到 Executor 中的工作单元 |
| Job | 多个并行执行的 Task,合起来就叫做一个 Job |
执行过程:
用户程序创建
SparkContext后,它会连接到集群资源管理器,集群资源管理器会为用户程序分配计算资源,并启动 Executor;SparkContext是 Spark 应用程序执行的入口,任何 Spark 应用程序最重要的一个步骤就是生成SparkContext对象。SparkContext允许 Spark 应用程序通过资源管理器访问 Spark 集群;
Driver 将计算程序划分为不同的执行阶段和多个 Task,之后将 Task 发送给 Executor;
Executor 负责执行 Task,并将执行状态汇报给 Driver,同时也会将当前节点资源的使用情况汇报给集群资源管理器。
20.3 Spark RDD (Resilient Distributed Dataset)
20.3.1 Definitions
Spark 的基础数据结构,RDD 具有不可修改的特性(immutable,线程安全,集群中方便安全地并行使用)。
Resilient(弹性):RDD 之间会形成有向无环图(DAG),即计算图(回忆 CSE 的计算图的定义),如果 RDD 丢失了或者失效了,可以从父 RDD 重新计算得到(re-execution - fault tolerance);
Distributed(分布式):RDD 的数据是以逻辑分区的形式分布在集群的不同节点的;
Dataset(数据集):即 RDD 存储的数据记录,可以从外部数据生成 RDD,例如 JSON 文件,CSV 文件,文本文件,数据库等。
20.3.2 RDD Operations
RDD 操作分为两类:transformation 和 action。
transformation:对 RDD 进行转换,返回一个新的 RDD,但是不会立即执行,只有遇到 action 操作时才会执行;
举例:map/filter 就是典型的 transformation 操作。
action:对 RDD 进行计算,返回一个结果或者将结果保存到外部存储系统中。
举例:reduce 就是典型的 action 操作;
Spark 中,所有的 transformation 操作都是 lazy 的,也就是说,只有当 action 操作发生时,才会触发 transformation 操作的执行。
为什么每个 stage 中的 transformation 操作是 lazy 的?
我们刚才说 RDD 是不能修改的,是只读的。transformation 的结果是一个新的 RDD,那就是说你在执行这个 transformation 之后,一定会生成新的 RDD,它就会占内存。但是这个 RDD 什么时候被会被用到?不知道,因为你的 driver 最后一定是想得到一个值,那既然不知道,你为什么先让他把内存先占着(不需要先存空间占用很大的中间结果),你应该一直到最后他要做一个 action,要得到一个值的时候,这时候才要迫不得已往前去推(使用之前构建的 computing graph),他是经历了哪些 transformation 得到了,再把前面的 transformation 都做一遍,这样的话我们可以以最节省的方式去使用内存。
20.3.3 RDD Partition
在一个文件读入 Spark 并创建 RDD 后,会立即进行 partition(根据集群数量,方便并行运算)。
RDD 分区的好处有哪些?
要知道分区的好处,我们先了解一下 Spark 中的 Shuffle。
在 Spark 中,某些特定的操作会触发 shuffle 动作(例如数据 JOIN)。shuffle 则作为一种针对数据的重分布操作,让数据得以在不同的 executors 间传递,获取必要的计算信息。
但是 shuffle 操作有个致命的问题是性能开销很大:包括大量 disk I/O、data serialization、network I/O(计算机系统中最慢的 3 巨头它都有)。
现在假设程序在内存中持有一个非常大的用户信息表 (UserID,UserInfo) ,其中 UserInfo 包含用户订阅的主题列表;另外有一个很小的表,记录过去 5 分钟里在网页上点击过链接的事件,键值对为 (UserID, LinkInfo),现在我们需要程序周期性地将这两个表合并、查询。
如果没有 partition,那么我们是不知道数据主键是如何分布在集群的各个机器上的(例如如果想找 A 开头的,已分区的数据可以很快确定在某些机器中,而未分区则无法做到)。而且 userData 需要周期性进行 hash 和 shuffle,即使可能并没有发生变化。
而如果 partition(hash 分区)了,那么 JOIN 可以利用这个信息,在 userData 不改变时直接取数据,无需再 shuffle,节省大量资源,如下左图:
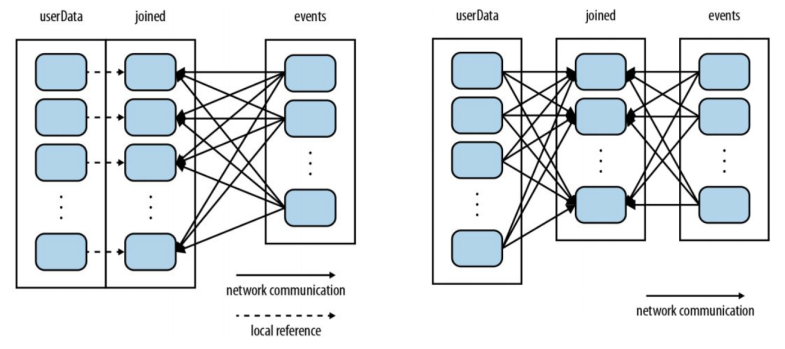
20.3.4 RDD Dependencies
我们发现,在像上面的计算过程中,JOIN 操作依赖于 userData 和 events 的数据,这就是 RDD 间的依赖关系。我们通过分析它们的依赖关系能够方便优化。
Narrow Dependency:每个父 RDD(计算图上游 RDD)的 partition 最多被子 RDD 的一个 partition 使用,这种依赖关系称为窄依赖。窄依赖的 RDD 可以并行计算,不需要 shuffle;
Wide Dependency:每个父 RDD 的 partition 可能被子 RDD 的多个 partition 使用,这种依赖关系称为宽依赖。宽依赖的 RDD 需要 shuffle 操作;
窄依赖的好处:
窄依赖只需计算丢失 RDD 的父分区,不同节点间可以并行计算,能更有效地进行节点的恢复(可以进行流水线化)。
宽依赖中,重算的子 RDD 分区往往来源自多个父 RDD 分区,其中只有一部分数据用于恢复,造成了不必要的冗余,甚至需要整体重新计算。
宽依赖往往意味着需要 shuffle(这是由业务逻辑决定的),而 shuffle 操作在分布式系统中意味着多个结点的数据传输;
有了宽依赖和窄依赖,我们可以在此基础上建立 code stage(即:划分 stage 的依据是计算图中的宽依赖和窄依赖):
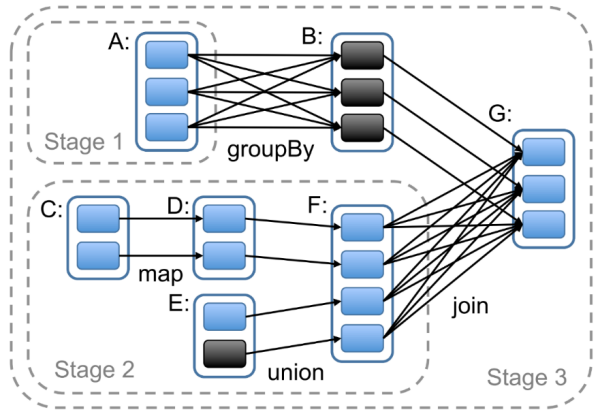
如上图的例子,实线方框表示 RDD,实心矩形表示分区(黑色表示该分区被缓存);
每个阶段 stage 内部尽可能多地包含一组具有窄依赖关系的 transformations 操作;以便将它们流水线并行化(pipeline),到最后一次性并行地做,不用占据内存空间,效率高;
stage 边界有两种情况:一是宽依赖上的 Shuffle 操作;二是已缓存分区;
碰到边界,这个 stage 就要真正执行了;
这样的好处就是只有在 F 要被使用的那一刻,而且需要被宽依赖的使用的那一刻,我们才去创建f。在此之前无论是 C/D/E/F 四个当中哪一个都在内存里是不存在,因此节省了空间;
20.4 Spark's Usage
20.5 流式处理 & 批处理 & 流批一体架构
流处理:对数据进行实时处理的方式,数据会以流的形式不断地产生和处理。流处理可以快速响应数据的变化,及时地进行数据处理和分析,适用于需要实时处理数据的场景。
优点:
实时性:数据在产生的时候就立即被处理,能及时反馈结果。
高效性:不间断接受新数据并进行处理,因此可以更加高效利用硬件资源。
缺点:
数据突发性:因为流式数据具有不可预测性,可能会突然出现突发的高峰,会导致系统压力急剧增加。
处理复杂度高:实时处理可能需要更高的处理能力和更复杂的算法。
批处理:对数据进行离线处理的方式,数据会按照一定的时间间隔或者数据量进行批量处理。批处理可以对大量数据进行高效处理和分析,适用于需要对历史数据进行分析和挖掘的场景。
优点:
处理复杂度低:通常不需要考虑数据的顺序、时间窗口等因素。
容错性高:数据多批次集中处理,通常一条数据的失败不会影响后续数据的处理,也可以采用多种容错机制来确保任务正确完成。
缺点:
响应速度慢:由于批处理是周期性执行,不能及时响应数据变化。
处理结果滞后:由于批处理是周期性执行,在某些场景下可能会出现数据结果滞后的情况。
以前很多系统的架构都是采用的 Lambda 架构,它将所有的数据分成了三个层次:批处理层、服务层和速率层,每个层次都有自己的功能和目的。
批处理层:负责离线计算和历史数据的存储。
服务层:负责在线查询和实时数据的处理。
速率层:负责对实时数据进行快速的处理和查询。
这样可以方便完成 HTAP(混合事务处理)的业务逻辑。但是这导致了一些问题:
资源浪费:一般来说,白天是流计算的高峰期,此时需要更多的计算资源,相对来说,批计算就没有严格的限制,可以选择凌晨或者白天任意时刻,但是,流计算和批计算的资源无法进行混合调度,无法对资源进行错峰使用,这就会导致资源的浪费。
成本高:流计算和批计算使用的是不同的技术,意味着需要维护两套代码,不论是学习成本还是维护成本都会更高。
数据一致性:两套平台都是不一样的,可能会导致数据不一致的问题。
Chapter 21. Storm
Storm 就是一类比较经典的流式处理框架。

它的基本框架如下:
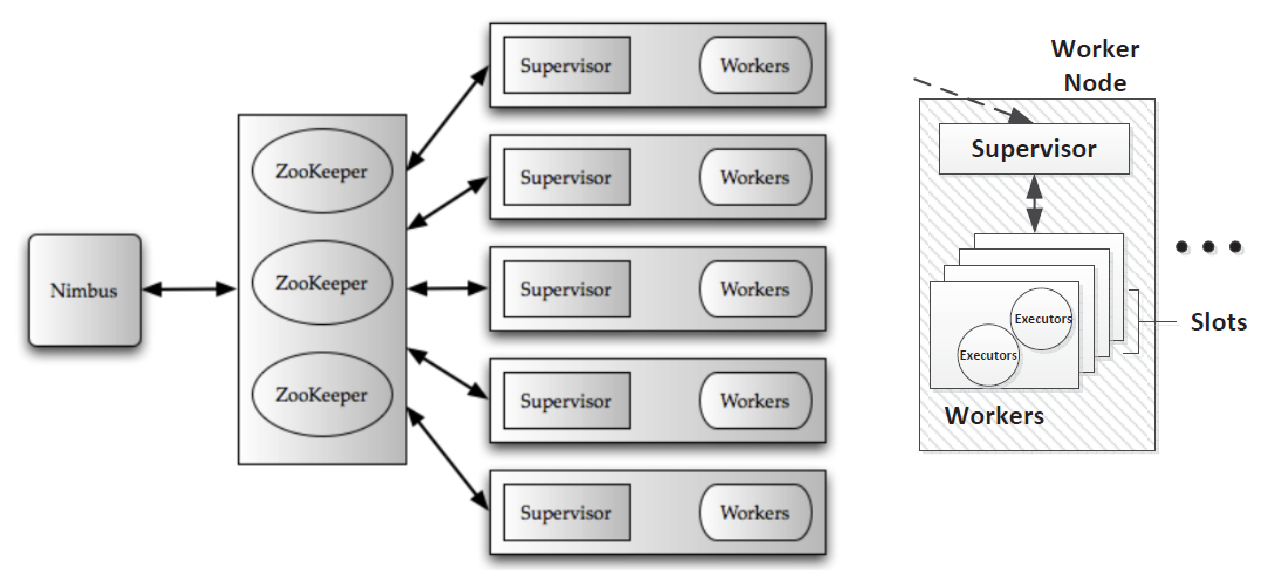
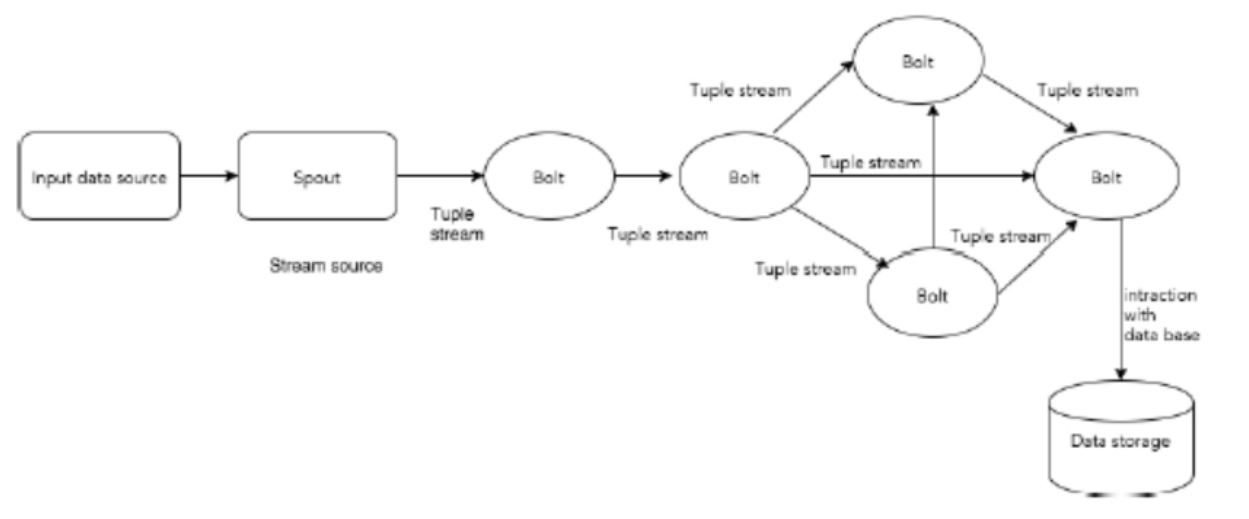

举例:"Twitter 分析"的输入来自 Twitter 流 API。 Spout 将使用 Twitter 流 API 读取用户的推文,并以元组流的形式输出。 来自 spout 的单个元组将具有 twitter 用户名和单个 tweet 作为逗号分隔值。 然后,这组元组将被转发到 Bolt,Bolt 会将推文拆分为单个单词,计算字数,并将信息保存到配置的数据源中。 现在,我们可以通过查询数据源轻松获得结果;
也就是说,微观上是批处理,宏观上是流处理;
Chapter 22. HDFS
学习类比 GFS。
22.1 Definitions
22.1.1 Design Assumptions: environments
文件本身很大(例如 large web index);
failures 很常见(成百上千台机器,出错是普遍而不可避免的);
文件写的方式大多数是 Append-Only 的(随机写的情况相当少);
更激进地,我们希望只写一次(Streaming Data Access,流式数据访问);
workload 大部分是 sequential read(large read streams);
设计需求:scalable、data-intensive、fault-tolerant、high performance;
Commodity Hardware:用一大堆廉价的硬件,并不需要非常昂贵的、高可靠的硬件。
HDFS 不适合应用于:
Low-latency data access: HDFS 只针对 throughput 优化,多副本写会影响系统性能;
Lots of small files:因为 NameNode 在内存中保存 metadata,因此在一个结点上存储的文件总数是有限的;
另外每个 block 的大小不会太小,存储小文件对空间利用率不高;
为什么文件使用比较大的 large chunks 作为文件存储基本单位?
减小网络交流频率:网络通信开销大,通过增大 chunks 牺牲一部分 utilizations 换取更少次数的请求(而且 workload 的大部分文件都很大);
提升可连接的 TCP 数量上限:更小的 blocks 分散在更多的机器上,需要维持的 TCP 连接更多,实际能连接的能力就下降了;
减小 metadata 的大小,以便 master node 可以将信息存在内存中,加快访问速率;
随机写、多写者(多写者不支持,因为只保证最终一致性);
22.1.2 Architecture
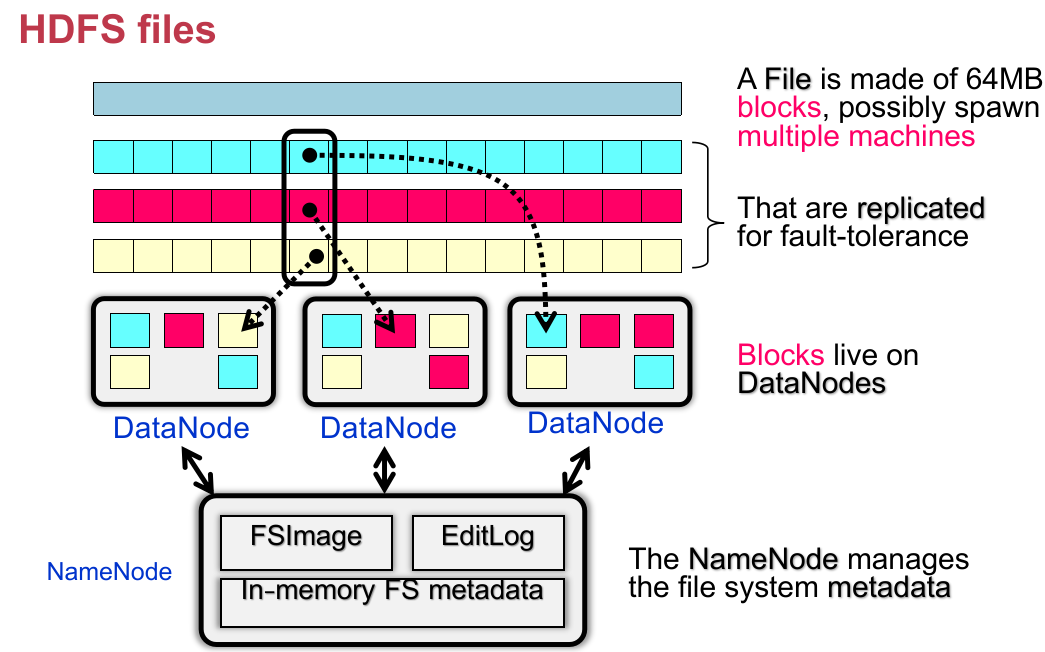
注意 GFS 只是把 NameNode 的称呼换成 Master,DataNode 换成 chunk server;
一个 NameNode 管理多个 DataNode 的 chunks,把文件映射到 chunks 中;
DataNode 提供固定大小的数据存储空间,并且可以提供 replication & backup(异地亲和性和容灾措施);
Hadoop Rack Awareness 进一步确保异地亲和,让不同的 replicas 尽量分布在不同的机架上。
但同时会造成网络开销的增大;
DataNode 自启动后,会一直向 NameNode 发送心跳信息 blocks report(包括 blocks 使用情况等等);
NameNode 接收到后,认为这个 DataNode 加入集群;
GFS 还有更多的机制:
每个 chunk 有 32 位校验和;
NameNode 会在创建时为每个 chunk 创建一个全局唯一的 64 位整型 ID;
热点数据会存更多的 replicas(scalable replicas);
Comparison between Improved NFS & HDFS
使用相当大的 chunks 来直接存放文件(每个 block/chunk 的大小可以自行设置);
huge chunks 会做 replications 来保证 fault tolerance 和 high performance;
GFS 只使用 1 个 master node:可以保证设计简单,同时有多种方式保证安全和可用性;
"file-chunks" map 建立在 master 的内存中(用 operation log 持久化保证数据安全);
而 "chunk ID - chunk" map 可以不需要 log 放在内存中,然后在 startup 时询问 chunk servers 建立起来就行;
优势有很多:
"file-chunks" map 本身是 hotspot,这样能极大优化性能;
更简单的数据一致性的管理;
master 控制整个映射机制,确保数据最新;
Interaction Model
只有需要 meta-data 时与 master 交互,其余时候直接与 chunk server 交互,不会造成 master node 拥塞
这也是设置 1 个 master node 的原因之一;
No Cache: client/server 都是这样。这是由 design assumptions 决定的。workload 中大多数是超大文件,用到 cache 的机会很少;
Client 也可以 cache meta-data,进一步减轻 master node 的负担;
Interface
不完全支持 POSIX API;
基本操作:
create/delete/open/close/read/write;额外操作(基于应用场景作出优化):
snapshot/append;不支持的操作:
link, symlink, rename;原因:这些操作在 failure 时需要保证一致性,需要花精力处理这些问题。而目前分布式事务实际上没法解决所有问题,所以就干脆不用了;
22.2 Operations
22.2.1 Reading a file in GFS
Client 联系 NameNode、获取文件的 Metadata(哪些 chunks/blocks?);
获取文件的每个 blocks/chunks 的具体位置(多个 replicas 的位置可选);
从 DataNode 获取任意一个中获取 chunk/block;
22.2.2 Writing a file in GFS
特点:
(原理复杂)more complex, because we need to deal with the consistency issue(应对两个 client 改一个文件的问题);
adopts a relaxed consistency model(后面讨论 “relaxed consistency model”);
方法的实现高效简单;
设计目标:
仅保证最终一致性;
减少与 NameNode 的交互(不然 NameNode 就会成为瓶颈);
为了保证一致性、消除并发写冲突,需要在同一组 replicas 中选一个 DataNode 作为 a single primary(leader)来统一协调写操作。有两个问题:
NameNode 如何选择一个 primary?这个 primary 不能持久,因为每台机器都有可能故障,而是定期随机地在每组 replicas 中通过给予 “a chunk lease”(租约)来选 primary,在这些 replicas 中只有这个 DataNode 才能修改 chunk(并且心跳连接);
允许允许续租机制;
更改 primary 后,NameNode 会通过更新(增加)chunk version 并通知 replicas 来完成。
因此写操作分为以下几个阶段:
phase 1 传输数据(Data Flow):
Client App 会得到一个要修改数据所保存的 replicas list,然后向最近的 DataNode 传输数据,并且采用 pipeline forwarding 的方法向其他 replicas list 中的 DataNode 传递;
不关心顺序、不存在写冲突,只管数据传递,解决性能、吞吐量;
注意:这种 pipeline forwarding 的效率优于从单个机器上并行传数据(由于一台机器的网络带宽上限),可以自己画图理解。
DataNode 在收到数据后不会保存,而是放在内存中(memory cache);
phase 2 写数据(Control Flow):
Client App 等待 replicas list 中的 DataNode 回复确认(ACK)后,再向 Primary Node 传递写请求;
Primary Node 再串行向各个剩余 replicas 中下达将刚刚 cache memory 中收到的数据修改落盘;
The primary is responsible for serialization of writes (applying then forwarding);
并且利用 NameNode 管理的 chunk version 判断 replicas 中是否有过时数据、是否应该覆盖等等。
由 Primary Node 关心写顺序,解决写冲突、一致性问题;
当 Primary Node 获得所有 replicas 的修改确认后,再向 Client App 发送确认回复;
总之,写操作对 atomic append 非常友好:Append 写法总是能保证最终一致性(哪个行数多哪个新,不需要考虑覆盖问题),因此 HDFS 的 weak consistency model 是有效的;
22.3 Features
22.3.1 Safe Mode
所有 DataNode 都会向 NameNode 后发送 Blocks Report。我们定义一份数据(block/chunk)的 replicas 满足最小的要求时称为 “safely replicated”;
我们可以配置 HDFS 的 NameNode,在启动后/热插拔 DataNode 后,只有当至少一定比例的 DataNode 的 chunks 都是 safely replicated,才会退出这个模式,向外提供服务(一般耗时 30s 左右)。
之前 block 第一次被写的时候不是已经写了满足要求的副本数目了,为什么现在启动了还要做这个检查?
因为这次启动不一定启动了之前的所有 DataNode;
也正因如此,HDFS 支持对于 DataNode 的 “热插拔”,一个 DataNode 加入和离开集群时,不需要人为额外的操作,只需要等待 NameNode 接收 Blocks Report 后统筹 Replicas 就行。
22.3.2 Rack Awareness
之前我们介绍到 HDFS 使用机架感知作为依据来存放 replicas,它的原理是什么?
它利用了网络拓扑结构间的网络距离:
在海量数据处理中,主要限制原因之一是节点之间数据的传输速率,即带宽。因此,将两个节点之间的带宽作为两个节点之间的距离的衡量标准。
Hadoop 为此采用了一个简单的方法:把网络看作一棵树,两个节点之间的距离是他们到最近共同祖先的距离总和。该树中的层次是没有预先设定的, 但是相对与数据中心,机架和正在运行的节点,通常可以设定等级。具体想法是针对以下每个常见,可用带宽依次递减:
同一节点上的进程;
同一机架上的不同节点;
同一数据中心中不同机架上的节点;
不同数据中心的节点。
因此 HDFS 在创建 replicas 时,可以指定 replicas 存放的策略。我们以 replica=3 的情况为例:
第一份 replica:如果写请求方所在机器是其中一个 datanode,则直接存放在本地,否则随机在集群中选择一个 datanode;
第二份 replica:第二个副本存放于不同第一个副本的所在的机架;
第三份 replica:第三个副本存放于第二个副本所在的机架,但是属于不同的节点;HDFS 同时会利用机架感知来改进数据的可靠性、可用性和网络带宽的利用率。通过一个机架感知的过程,NameNode 可以确定每一个 DataNode 所属的机架 ID;
22.3.3 Robustness & Fault Tolerance
DataNode Failure:通过心跳 blocks report 感知,NameNode 会维护文件 replicas 动态的稳定(re-replication);
Sudden high demand:此时 NameNode 协调 data rebalancing,动态创建更多的 replicas 应对
Data Intergrity:数据可能因为硬件/软件等偶然原因错误,使用 block checksum 校验,不对的话从其他 replicas 中恢复;
Metadata Disk Failure:这类数据损坏会导致整个 HDFS 实例故障。所以 HDFS 使用 FsImage 和 EditLog(HDFS 的核心文件),类似于 shadow backup 和 redo log,并且可以维护多份。每次更新数据时同步更新这些文件。它们还会支持 checkpoint 和 snapshot,允许在故障发生时回滚到前面一个正确的状态。
每次 NameNode 启动后会选择最近的持久化的 FsImage 和 EditLog 来使用。
Chapter 23. HBase
其实是 Google Big Table 的开源实现版本。就像 HDFS 和 GFS 的关系。
HBase 是面向列存的、分布式的数据存储系统(基于 HDFS);
关系型数据库(如 MySQL)一般不做垂直分区。
关系型做分布式的问题是,有两个巨大的表,如果我们没有外键关联,那无所谓;但是如果存在了外键关联,如何划分就是一个大问题——否则如果切分得不好,你在做 JOIN 的时候,某台机器可能要和很多其他机器通信,就很慢。
HBase 术语:
表:HBase 表由多行组成。
行:HBase 中的一行由一个行键和一列或多列与之相关的值组成。
行在存储时按照行键的字母顺序排序。
因此,行键的设计非常重要。我们的目标是以相关行彼此靠近的方式存储数据。
常见的行键模式是网站域名。如果你的行键是域名,你可能应该反向存储它们(org.apache.www、org.apache.mail、org.apache.jira)。这样,所有 Apache 域名在表中就会彼此靠近,而不是根据子域的首字母分散存放。
HBase 的版本:
{行、列、版本}元组精确地指定了 HBase 中的一个单元格。在这种情况下,单元格的行和列是相同的,但单元格地址仅在版本维度上有所不同,这样的单元格数量可能是无限的;HBase 版本维度是按递减顺序存储的,因此从存储文件中读取时,首先会找到最新的值。
指定要存储的版本数量给定列要存储的最大版本数量是列模式的一部分,可在创建表时通过
HColumnDescriptor.DEFAULT_VERSIONS指定,或通过 alter 命令指定;列: HBase 中的列由一个列族和一个列限定符组成,它们之间用:(冒号)字符分隔;
列族: 通常出于性能考虑,列族会将一组列及其值物理上放在一起;
每个列族都有一组存储属性,例如其值是否应缓存在内存中、数据压缩方式或行键编码方式等;
表中的每一行都有相同的列族,但某一行可能不会在某个列族中存储任何内容。
列限定符: 列限定符被添加到列族中,为给定数据提供索引。
在给定列族内容的情况下,列限定符可能是 content:html,也可能是 content:pdf。虽然列族在创建表格时是固定的,但列修饰符是可变的,不同行之间可能会有很大差异。
单元格:单元格是行、列族和列修饰符的组合,包含一个值和一个时间戳,时间戳代表值的版本。
时间戳:每个值旁边都写有一个时间戳,它是值的特定版本的标识符。默认情况下,时间戳代表写入数据时 RegionServer 上的时间,但您也可以在向单元格输入数据时指定不同的时间戳值。
面向列存、基于 HDFS:
如果我有一个巨大的表,在 HBase 眼里,我先将其切成三块,比如每块 100GB,这些信息会记录到 metadata 中;然后它们落到 HDFS 里面,每块继续切,切成 block;
所以实际上我们可以看到这里是两层;第一层的原因是为了加速搜索(水平分区),比如我有一个 key,我按照 key 的范围做了一个分解:1-1000,1001-2000,2001-inf,这样我就可以快速定位到这个 key 在哪个块里面,然后再去找这个块里面的数据;
当然元数据的表可能也会变得很大,所以也需要切。所以用户查找就变成了:
先去 root 表里面找到这个表的元数据在哪个 region 里面(region 就是你对表水平分区产生的结果,开始的时候一个表只有一个 region,后来会慢慢变多);
然后去这个 region 里面找到这个 key 在哪个 region 里面;
然后去这个 region 里面找到这个 key 在哪个 block 里面;
带版本的:
就刚才讲到如果我把这个数据表只是把外键关联去掉,那我带来了一个问题,是它的数据表达能力会变弱,那于是怎么办? hbase 就说我让你有几点可以变得跟关型数据库不一样,你的表达能力会变强。
其中有一点就是我在这个维度上就像三维的一样,我在这个维度上允许你做多个版本的存储,比如有一行。对一个字段,可以记 5 个不同时间版本的值,就相当于是一个三维立体的结构。这个就是以关系型数据库不能去表达的。
那而且它支持这个 cell 可以说有五个版本,旁边的这个 cell 就只有两个版本。而且大家的版本是靠时间戳来的,所以是可以对齐的。
也就是说我想去看一下某一个时间戳下这个数据是什么样,我们就去找每一个 cell 在靠近这个时间戳的时候它的值是什么。尽管你有5个时间戳,你有2个时间戳,我找最靠近你这个时间戳,我就只能知道整个这张表所有的 cell 在这一个时间戳上它的值是什么。
所有操作必须全部用主键来。这里的键必须十个有意义的键。
所有的行都是按照主键排序的(存的是字节码,按照字节排序)。
列族到底是什么?多个列键(column keys)可以组织成 column families(列族)。 column family 是访问控制(access control)的基本单位。列键的格式:
family:qualifier,其中 family 必须为可打印的(printable)字 符串,但 qualifier(修饰符)可以为任意字符串。例如,WebTable 中有一个 column family 是语言(language),用来标记每个网页分别是用什么语言写的。在这个 column family 中我们只用了一个列键,其中存储的是每种语言的 ID。
WebTable 中的另一个 column family 是 anchor,在这个 family 中每一个列键都表示一 个独立的 anchor,如图 1 所示,其中的修饰符(qualifier)是引用这个网页的 anchor 名字,对应的数据项内容是链接的文本(link text)。列族也满足连续存储,一个列族里面的列放在一起。
总体来说,HBase 的表在概念上长这样:
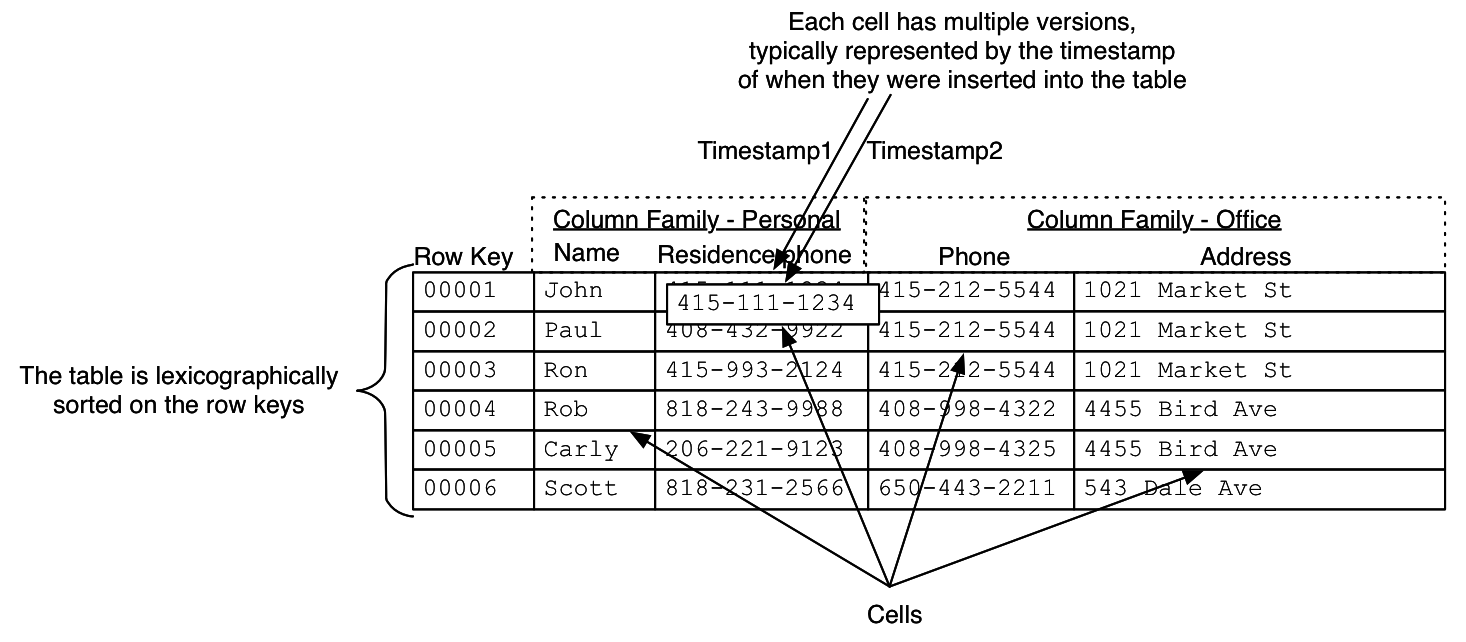
物理存储上长这样:

Q&A:
为什么说 HBase 是一个稀疏的表?
首先因为它灵活的 schema。No Fixed Columns: In HBase, there is no strict schema for the columns of a row. Each row can have a different set of columns, and columns can be added or omitted dynamically.
其次是它的列族的机制。A row in HBase can have multiple column families, and each column family can contain a different set of columns. Not every row will have data for every column family or every column within a family, so empty or non-existent columns are not stored.
然后是它的多版本时间戳的存储方式。在上面的概念图上我们可以看到,多个版本下,每个 cell 其实不一定存在值(还没有设置),这些空的地方在 HBase 中并不占用存储空间,或者说实际上并不存在。因此 HBase 是稀疏的表。
使用列族的好处是什么?
Efficient Storage and Retrieval:数据局部性、Data within a column family is stored together on disk、减少磁盘 I/O 次数;便于压缩;
Flexibility in Schema Design: Unlike relational databases, HBase has a flexible schema, where each row can have different sets of columns. Column families can evolve over time, allowing you to add new columns as your application needs change without affecting the overall structure of the data store.
Scalability: Efficient Region Distribution, Column Family Isolation (helps to scale HBase by distributing read and write loads across different regions or servers)
Optimized for Write-Heavy Workloads: HBase uses an append-only approach (writes are added as new versions of cells), column families can be tuned to optimize for write-heavy workloads, with faster data insertion and minimal disruption to other column families.
Chapter 24. Hive
Hive 是一个建立在 Hadoop 之上的数据仓库工具,它允许用户使用类似 SQL 的语言(称为 HiveQL)进行数据查询和分析。
HiveQL 遵循 SQL 标准,但支持不全,并且和 Hibernate SQL 的语法不一样。
24.1 Definitions & Meanings
Hive 的定位:Hive 是一个数据仓库工具,它的设计目标是简化 Hadoop 上的数据处理和分析,可以将结构化的数据文件映射为一张数据库表,并提供 HiveSQL 查询功能;
其本质是将 SQL 转换为 MapReduce/Spark 的任务进行运算,底层由 HDFS 来提供数据的存储,说白了 Hive 可以理解为一个将 SQL 转换 MapReduce/Spark 的任务的工具;
使用 Hive 的原因:学习 MapReduce 的成本比较高、项目周期要求太短、MapReduce 如果要实现复杂的查询逻辑开发的难度是比较大的(太底层了)。 而如果使用 Hive,简单的语句能够提高快速开发的能力;
24.2 特性 & 与关系型数据库比较
对应的问题,例如:大数据场景下,都是用 SQL 存,那为什么不直接用 MySQL 这种关系型数据库呢?
在大数据场景中,Hive 和 MySQL 等关系型数据库用于不同的目的,它们的优势在不同的情况下发挥得淋漓尽致。下面将详细介绍在处理大规模数据时,为什么 Hive 往往比 MySQL 更受青睐。
A. Scalability and Performance
Hive 建立在 Hadoop 之上,可在多台机器上扩展。它允许您通过将数据分布到机器集群中来存储和处理 PB 级的数据。
与关系型数据库 MySQL 对比:MySQL 通常是为事务性工作负载设计的,最适合较小的数据集(尽管它可以通过分片和复制进行扩展)。它不是为高效处理大规模数据而设计的,不方便扩容(GB 级别,而且有表大小限制,再大通常就需要分表,这也是 MongoDB 出现的原因之一)。
总结一下 Hive 的主要优势: Hive 可以处理 MySQL 难以管理的海量数据集,而 MySQL 在大数据处理的水平扩展性(Horizontal Scalability)方面存在固有的局限性。
B. Data Model
Hive 使用 schema-on-read 模型,即在查询数据时应用模式。这种灵活性允许处理非结构化或半结构化数据(如 JSON、Parquet、Avro)。
而 MySQL 使用的是 schema-on-write 模型,即数据在插入数据库之前必须符合严格的模式。
Hive 的主要优势: Hive 可以处理更多样、更复杂的数据类型,尤其是大数据应用中使用的数据类型,这些数据可能是非结构化或半结构化的(日志、传感器数据等)。
C. Concurrency and Transaction (OLTP) Support
MySQL 专为事务性工作负载(OLTP)设计,具有 ACID 特性(原子性、一致性、隔离性、持久性),可确保并发访问和操作过程中的数据一致性。
Hive 最初是为重度读取、面向批处理的工作负载而设计的,并不支持 ACID 事务。不过,随着最近的改进(例如 Hive 3.x 中的 ACID 事务),Hive 增加了对更好地处理事务一致性的支持,但在 OLTP 场景中,它仍不能直接替代 MySQL。
Hive 的主要优势: 虽然 Hive 在事务处理能力方面正在迎头赶上,但它仍主要用于大规模批量数据处理,而非实时事务一致性,因此 MySQL 是 OLTP 的更好选择。
D. Data Processing Type
Hive 通常用于 batch processing 和 analytics。它利用了 Hadoop 的 MapReduce 框架,该框架专为分布式并行数据处理而设计。这使得 Hive 能够以分布式方式高效处理庞大的数据集。因此 Hive 非常适合对大量数据进行复杂查询,并生成报告或汇总。
MySQL 是为实时事务处理(OLTP)而设计的,通常以单节点事务方式运行,并没有针对分布式并行数据处理进行优化,因此适用于需要即时数据更新和低延迟查询的应用程序。
因此总的来说,如果目标是为 long run batch processing 和 analytics,在多个节点上并行执行对海量数据集的查询,那么 Hive 比 MySQL 更为适合,后者在处理此类工作负载时会非常吃力——如果不对架构进行重大调整(如 sharding、cluster),MySQL 就无法高效地执行查询。
E. Data Storage
Hive 通常将数据存储在 HDFS(Hadoop 分布式文件系统)等分布式文件系统或云存储(如 Amazon S3、Azure Blob)中。HDFS 针对存储大型文件进行了优化,可确保高吞吐量和容错性。
Hive 首先是同时支持列式存储和行式存储,可以在建表的语句中看到(请回想 OLAP 和 OLTP 的相关内容,为什么 OLAP 适合列存)。
此外,Hive 的文件存储有一批文件格式:
TextFile(行存储,默认表
raw使用);SequenceFile(行存储);
RCFile(Record Columnar File):是一种列存储 (混合) 数据结构,专为基于 MapReduce 的数据仓库系统而设计。
RCFile 将表数据存储在由二进制键/值对组成的扁平文件中。它首先将行横向分割成行拆分,然后以列的方式对每个行拆分进行纵向分割(Column Groups,类似 HBase 中的列族)。
RCFile 将 row splits 的 meta-data 作为记录的 key part 存储,将 row splits 中的所有数据作为 value part 存储。
因此 RCFile 结合了行存储和列存储的优点,满足了快速数据加载和查询处理、有效利用存储空间以及适应高动态工作负载模式的需求。
作为行存储,RCFile 保证同一行中的数据位于同一节点。作为列存储,RCFile 可以利用列数据压缩,跳过不必要的列读取。
ORCFile(Optimized Row Columnar):一种列存储数据结构,每一批 row data 组成一个 group 称为 stripe(默认 250 MB,额外的辅助信息,例如 stripe 大小,存放在文件 footer 区域);
footer 区域的 postscript 保存了文件的压缩率、文件中所有 stripes 的索引列表、列数据类型等信息;
Avro File(列存储);
Parquet (Apache):列存储数据结构,每个 column 中的数据放在一起,使用 row groups 集合 column 的一部分数据。也是数据库支持格式的事实标准。比如说我们现在有 a 类型的数据库和 b 类型数据库,大家如果想交互,可以全部都转成它这一种格式;
Hive 支持压缩(LZO, lossless data compression、Gzip、Bzip2)。
MySQL 则可以通过插件的形式支持 Parquet File 的导入导出。
总结一下,Hive 的使用场景:
Massive Datasets: If you're dealing with very large datasets (terabytes or petabytes) that need distributed storage and parallel processing.
Batch Analytics: If your goal is to run complex queries for analytics or ETL jobs over large datasets, where low-latency transactions are not critical.
Cost-Effective, Scalable Infrastructure: If you need to scale across many machines or leverage low-cost infrastructure.
Hadoop Ecosystem Integration: If you are working within a Hadoop ecosystem and need integration with tools like Spark, HBase, or MapReduce.
MySQL 的使用场景:
Transactional Systems (OLTP): When you need real-time transaction processing with ACID guarantees (e.g., financial applications, e-commerce systems).
Smaller Datasets: For smaller datasets (relative to big data systems) that don’t require distributed storage.
Low-Latency, Interactive Queries: If your application requires quick responses to queries and high concurrency (e.g., user-facing applications like web apps or small business systems).
24.3 再谈数据湖、数据仓库
我们发现,Hive 实际上是一个数据仓库,但是却使用 schema-on-read 模型,这说明 Hive 会像数据湖一样,先把原始数据保存起来。只有当使用 SQL 查询时才会尝试构建一个 schema。
因此 Hive 是一种混合系统(Hybrid System):
对于某些用例(如 batch processing and BI 商业智能 workloads),它的功能与数据仓库类似,因为它能对大型数据集进行类似 SQL 的查询。
对于其他用例(如大数据存储和 exploratory analysis),由于采用了模式读取方法,它的行为类似于数据湖。
数据仓库里的数据是文件格式区别的,数据湖可以翻译不同格式的数据,就是直接把数据湖作为数据仓库,都可以用 SQL 方式访问数据湖;
介于前两种之间,当数据的使用高于一定频率时移动到数据仓库里,即热数据存在数据仓库里,可以提高处理这些数据时的效率,并且还支持非 SQL 的查询方式,这种架构也称湖仓一体 (lakehouse);
Chapter 25. Flink
25.1 Scene
Flink 要处理流式数据。所谓的流式数据,就是我们看到有很多的事件不断发生,以某种时序被处理系统接收到。
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
其中 Streams:
bounded and unbounded streams;
real-time and recorded streams
recorded:如果处理速度没有那么快,我就在 flink 前面加一层 kafka 消息队列,存在 topic 里面;
Flink 要做哪些事情?
考虑数据传输中存在的问题:
分布式场景下,如何将数据按照一定的规则,放到不同的节点上面去计算?
大部分涉及流处理的业务有顺序需求:如果放上去了,考虑乱序问题(不同节点的网络状况不同);
有些业务逻辑需要考虑状态需求:假如现在有两个产生事件的源,我们想在处理时将它们要隔离开来,也即这两个源在处理的时候,我要知道它们的上一个事件,要与之关联。就是说所有操作必须是有状态的;
注意,我们之前讨论 Hadoop、Spark、Storm 的时候都是不关注状态的(stateless);
25.2 The States of Flink
为了处理状态的需求,Flink 引入状态的概念。状态可以用对象保存,每个 field 和 variable 可以用键值存储起来(注意落盘)。
周期异步 snaphsot:第一个不能影响到现在的这个事件的处理的这个流,所以他要去异步的做,就是比如说隔一段时间做一下,而且就是你前端正在改修改,后端慢慢去往里写,不一定说我要前端停一下,让他先到后端,写完之后再说。你前端继续执行前端一端执行他的状态,一边去做这个备份。
增量 checkpoints;
键值可以使用类似 IP Hash 方法来确保放在某个特定机器上处理。
25.3 Watermarks of Flink
为了处理顺序问题,Flink 引入水位线的概念。
如果我是 8 点到 9 点的数据,一个时间窗去处理, 9 点到 10 点一个时间窗去处理,但是在这个 9 点零二分的时候来了一个 9 点的数据,因为网络传输延迟。最简单的解决方案就是提供一个你可以接受的延迟时间,比如我定义九点零五分为 DDL,他在他九点零二分来的,那他仍然可以当成这个时间窗户数据处理。
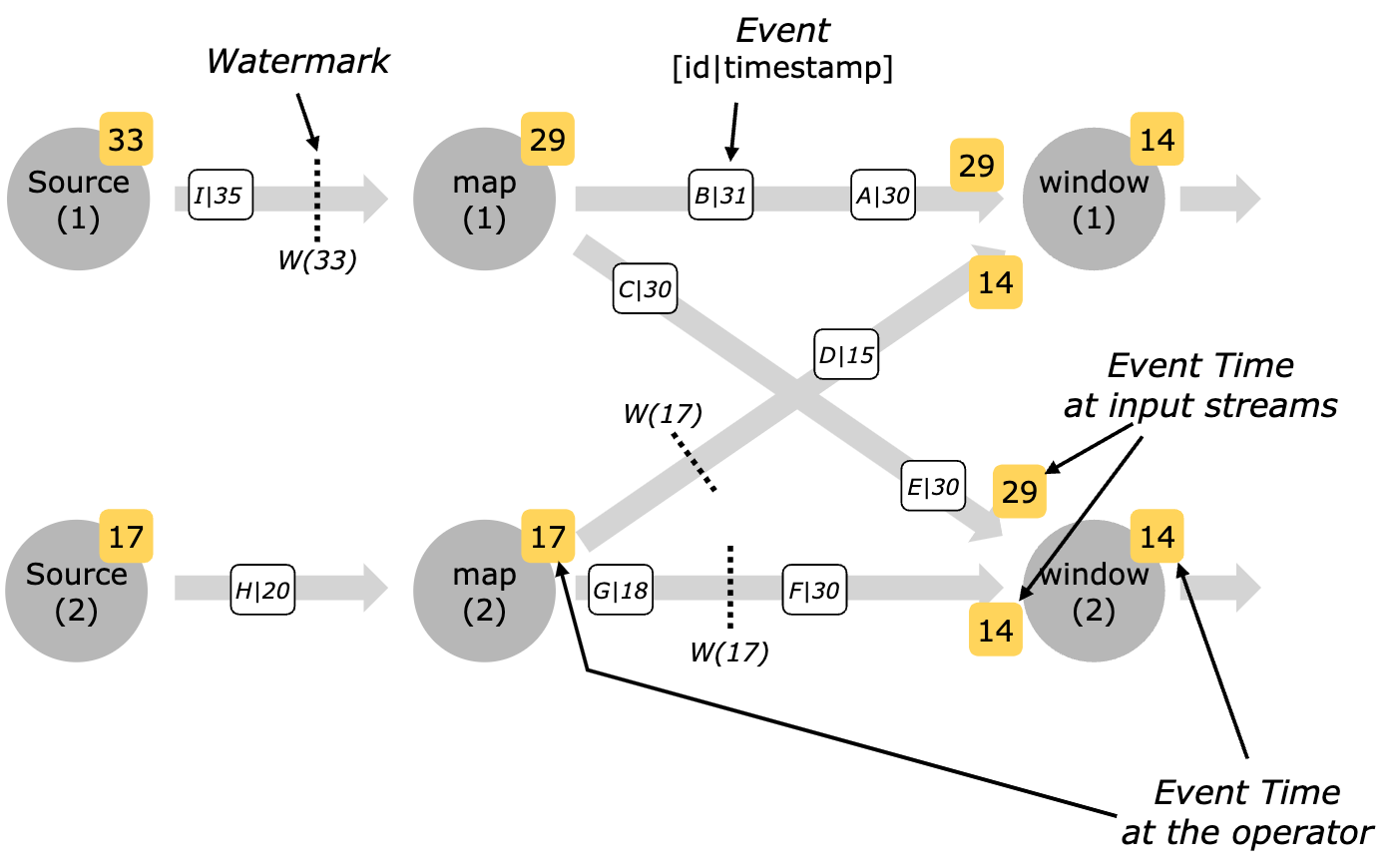
窗口机制:
窗口机制有两种,一种是上面这个时间窗口,比如说每 30 秒我处理一下这个窗口里的所有的数据,还有一个是数据驱动,就是我数个数,每 3 个事件我就处理一下。
总的来说就是我们拿窗口里的数据去做批处理,每一个批处理完之后紧跟着处理下一批。从宏观上看,于是它就是流式的数据处理了。
总结:我们是要靠这种时间戳加水位线的这种方式在告诉每一个算子过来的事件,它们的先后顺序什么样,你应该怎么把它组织到你这样的一个时间窗里面,在这个时间窗里激发对所有的时间的处理。
25.4 The Architecture of Flink
Flink 的状态是要频繁的使用内存的,而且他这个就是我们刚刚看到的,就是所谓的状态,是指你在每一次你的逻辑在处理这个事件的时候,在拿到事件的信息之后,你这个逻辑程序还要去读一下状态,才能知道怎么处理这个事件,而这个状态就在内存或硬盘上。
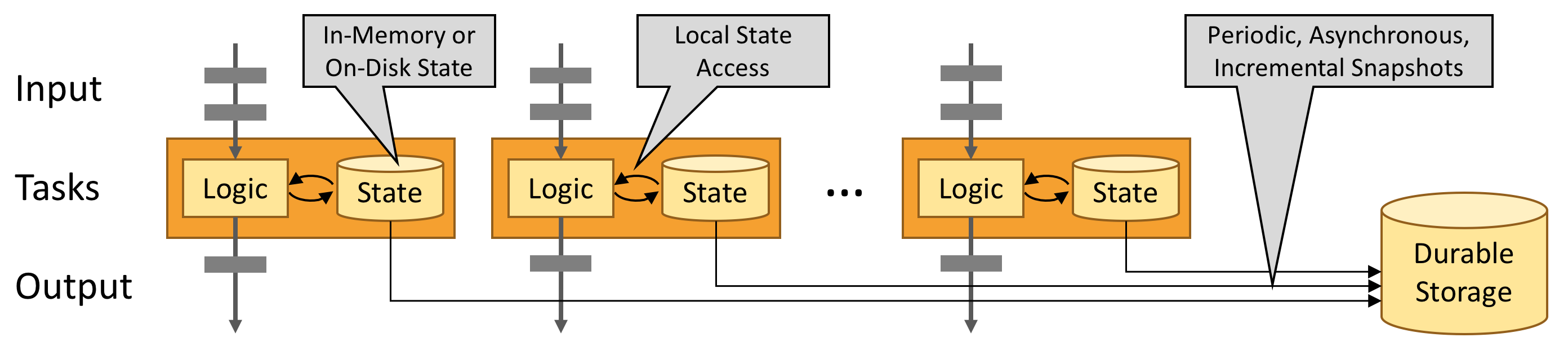
Chapter 26. AI
26.1 Full-Connected NN
神经网络结构类型
前馈神经网络:训练中有反馈信号,但分类过程中数据仅能向前传递,直至输出层,层间没有向后的反馈信号;
反馈神经网络:从输出到输入具有反馈连接的神经网络,远复杂于前馈神经网络;
自组织网络:自动寻找样本中的内在规律和本质属性,自组织、自适应地改变网络参数、结构;
输入权重、偏置量、激活函数、输出;
输入层:用于输入信息,例如对于输入图像大小
输出层:这里我们只讨论图像分类问题(classification)。分类问题比较常用的输出方式是 One-Hot Encoding(独热编码),输出向量长度为分类种类,每个位置代表唯一一种分类(0/1)。这样做的好处是两两分类正交(无关)。如果假设有关,则可能与实际情况不符,造成模型拟合效果不佳;
隐藏层:学习过程中自动捕获数据中的特征,转换为模型参数(激活函数的权重参数)。参数没有实际意义。
全连接层:该一层的每个神经元与前一层每个神经元都有权重连接;
为什么批量输入数据点?有什么好处?
GPU/CPU 核数比较多:一次算一个和算多个的速度是一样的。可以充分利用计算资源;
批量输入后再修正(反馈)比单个输入的效率更高、效果更好(多个值的损失值进行反馈不容易出现偶然性);
为什么使用 Sigmoid 为分类问题的激活函数?
便于拟合阶跃函数(step function),性质类似。零点附近梯度大、两端位于 0-1 间;
便于求导(梯度);
可以作为基,线性组合来描述其他函数的特征;
为什么分类问题最后一层激活函数使用 softmax?
可以让向量的各项介于 0~1 间,并且总和为 1;
可以借助指数函数特性(
其导数有很好的性质,方便计算交叉熵损失函数;
补充:常见的激活函数:
线性函数('purelin'):
S Shape('logsig'):
Threshhold Function:
Two Pole S Shape('tansig'):
ReLU(Rectified Linear Unit):
反向传播(BP):利用输出误差估计 输出层的直接前导层的误差,再用此误差估计更前一层误差,如此反传下去,获得所有层的误差估计;(信号正向传播、误差反向传播)。反向传播更新参数的过程就是学习的过程:
梯度消失:
以 Softmax 为例,交叉熵损失函数(
由于 Sigmoid 函数的导数
26.2 分类神经网络构建
xxxxxxxxxxmodel = Sequential([ # 输入为 28x28 二维矩阵(1 通道 28x28 灰度图) # 32 为单位批量计算 # 本质上不是神经网络的一部分 Input(shape=(28, 28, ), batch_size=32), # 展平为 784x1 向量,这里就是输入层 # 由于 batch size 是 32,因此输入的是二维矩阵 32 x 784 # 实际上还需要有偏置量,所以真正给到下一层的数据是 32 x 785 Flatten(), # 隐含层 A:128 个神经元组成的全连接层,使用 ReLU 激活函数 # 输出 32 x 128 Dense(128, activation='relu'), # 隐含层 B:随机丢失输入数据的 20% 的信息 # 相当于把图片遮起来一块让模型识别。 # 1. 防止过拟合,提升模型泛化性 # 2. 这样训练出的模型不会过分关注某个局部特征,而是在更加全局的角度考量 Dropout(0.2), # 输出层:10 个神经元组成的全连接层,可以代表 0-9 数字的 One-Hot Encoding # 输出 32 x 10 Dense(10, activation='softmax')])
model.compile(optimizer='adam', # 损失函数使用稀疏分类的交叉熵损失函数 loss='sparse_categorical_crossentropy', metrics=['accuracy'])26.3 CNN
改进:在之前的全连接神经网络中,输入数据的每个分量都可以互换(输入分量彼此没有关联),因为每一层的全连接会把信息无差别地传播到下一层;这会导致一些问题:
对于图像数据,模型应该充分利用其中的内在属性。如果使用全连接的方式学习会导致在复杂的图形中的学习效果不佳;
全连接网络本身会产生大量的参数。这里对于
我们在图像识别中,希望按照 “边缘 -> 形状 -> 形状间的关系” 这个过程来识别,充分利用图像性质;
数学层面,我们可以使用 核(Kernel)作为这样局部特征的提取工具。人们发现,如果使用 卷积核 来迭代计算图片像素,可以提取出图片的某些特征(数学原因);然后特征与特征之间的组合可以用卷积的移动过程来匹配;提取出图不同特征的称为 channel;
在特征的搜索从局部向全局的转变过程中,需要观察的图片范围逐步增大,但是如果核也随之增大,则会导致参数量 fallback 到全连接网络。所以我们应该缩放减小全图的大小,方便一个核可以观察到更大范围的图片的信息。这个过程被称为 池化(Pooling);
池化方法:
最大值池化:以
平均值池化,操作方法和最大值池化类似,不过代表的值从最大值变成平均值;
卷积核的大小一般是奇数,因为需要一个中央像素作为输出;
一般还需要卷积填充,因为卷积核本身有大小,并且卷积步长不一定为 1,这两种因素都会造成卷积核生成的矩阵缩小。为了防止每一层都会缩小,我们在计算前向图片外围追加若干层全 0 像素作为 填充(padding);
卷积核的深度需要与输入图像的深度一致。例如存在透明度的 PNG 图片(
例子:
xxxxxxxxxxmodel = keras.Sequential( [ # 这个时候因为有二维卷积,因此不必再 flatten Input(shape=(28, 28, 1), batch_size=32), # 二维卷积,32 个卷积核 3x3,激活函数 ReLU Conv2D(32, kernel_size=(3, 3), activation="relu"), # 二维 2x2 最大值池化,图片缩小 2 倍 MaxPooling2D(pool_size=(2, 2)), Conv2D(64, kernel_size=(3, 3), activation="relu"), MaxPooling2D(pool_size=(2, 2)), # 展平,方便之后转为 one-hot encoding Flatten(), Dropout(0.5), Dense(num_classes, activation="softmax"), ])26.4 TLP
word -> vector
语料库、语料清洗、预处理;
26.5 RNN & LSTM
Recurrent Neutral Network
之前时间节点的模型输出作为下一轮模型的输入数据。
Long-Term Dependencies:但如果用前面所有时间的输入,效果又不是很好(参数量非常大)。能否只考虑之前一定时间范围内的参数,该扔的扔掉(不对后面有很大影响)?
适用场景:自然语言处理、时序数据预测;
26.6 ChatGPT & Transformer
Input -> [多头注意力层 -> 前溃网络层 ] 编码器 -> 重复 -> 特征值 -> 解码器 -> Output;